JS高级 之 RegExp - 正则表达式

目录
一、正则表达式
1. 概念
2. 创建
01 - 通过RegExp类来创建
02 - 通过字面量来创建
3. 使用方法
正则对象的实例方法
01 - exec
02 - test
字符串对象的实例方法
01 - match
02 - matchAll
04 - replaceAll
05 - search
06 - split
二、修饰符的使用
三、规则
规则 – 字符类(Character classes)
字符类
01 - \d
02 - \s
03 - \w
04 - .
反向类(Inverse classes)
规则 – 锚点(Anchors)
01 - ^ && $
02 - 词边界 \b
规则 – 转义字符
规则 – 集合(Sets)和范围(Ranges)
集合(Sets):
范围(Ranges):
匹配手机号码
排除范围
规则 – 量词(Quantifiers)
数量 {n}
缩写:
栗子一
栗子二
规则 – 贪婪( Greedy)和惰性( lazy)模式
贪婪模式 :
惰性模式 :
规则 – 捕获组(capturing group)
捕获组
命名组
非捕获组
或 or
四、常用正则
1. 去除字符串空格
2. 匹配手机号
3. 歌词解析
4. 时间格式化
一、正则表达式
1. 概念
正则表达式(英语:Regular Expression,常简写为regex、regexp或RE) :
- 又称正则表示式、正则表示法、规则表达式、常规表示法,是计算机科学的一个概念
- 正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串
- 许多程序设计语言都支持利用正则表达式进行字符串操作
简单概况:正则表达式是一种字符串匹配利器,可以帮助我们搜索、获取、替代字符串
2. 创建
正则表达式主要由两部分组成:模式(patterns)和修饰符(flags)
01 - 通过RegExp类来创建
// 创建正则
// 1> 匹配的规则pattern
// 2> 匹配的修饰符flags
const regex = new RegExp("abc", "ig")02 - 通过字面量来创建
// 创建正则
// 1> 匹配的规则pattern
// 2> 匹配的修饰符flags
const regex = /abc/ig3. 使用方法
正则对象的实例方法
01 - exec
exec : 一个在字符串中执行查找匹配的 RegExp 方法,它返回一个数组,未匹配到则返回 null
通俗的说 : 查找到匹配规则的字符串,并返回相关信息
// 正则 => 匹配abc 全局查找,不区分大小写
const regex = /abc/gi;
// 字符串
const message = 'abc fAbcdaBc cabc 123';
// const res = regex.exec(message);
// console.log(res);
/**
* 每次执行,会返回找到的第一个
* 再执行一次,会在原来基础上继续查找 => 前提是加上了全局查找修饰符g,否则永远找到第一个
*/
// ['abc', index: 0, input: 'abc fAbcdaBc cabc 123', groups: undefined]
console.log(regex.exec(message));
// ['Abc', index: 5, input: 'abc fAbcdaBc cabc 123', groups: undefined]
console.log(regex.exec(message));
// ['aBc', index: 9, input: 'abc fAbcdaBc cabc 123', groups: undefined]
console.log(regex.exec(message));
// ['abc', index: 14, input: 'abc fAbcdaBc cabc 123', groups: undefined]
console.log(regex.exec(message));
// null
console.log(regex.exec(message));02 - test
一个在字符串中测试是否匹配的 RegExp 方法,它返回 true 或 false
通俗的说 : 检测某一个字符串是否符合正则的规则
// 正则 => 匹配规则,是否以.()这些结尾
const reg = /\.(AMR|WAV|AWB|mp3|mp4)$/;
// 字符串
const str1 = 'abc.mp3';
const str2 = 'abc.mp4';
const str3 = 'abc.WAV';
const str4 = 'abc.mp6';
console.log(reg.test(str1)); // true
console.log(reg.test(str2)); // true
console.log(reg.test(str3)); // true
console.log(reg.test(str4)); // false字符串对象的实例方法
01 - match
一个在字符串中执行查找匹配的 String 方法,它返回一个数组,在未匹配到时会返回 null
通俗的说 : 检测某一个字符串是否符合正则的规则,返回查找到的数据
// 正则 => 匹配abc 全局查找,不区分大小写
const regex = /abc/gi;
// 字符串
const message = 'abc fAbcdaBc cabc 123';
/**
* 全局查找时,会把查找到的字符串返回数组
*/
// ['abc', 'Abc', 'aBc', 'abc']
console.log(message.match(regex));
// ['abc', 'Abc', 'aBc', 'abc']
console.log(message.match(regex));
// -------------------------------------------------------
// 正则 => 匹配abc ,不区分大小写
const regex1 = /abc/i;
// 字符串
const message1 = 'abc fAbcdaBc cabc 123';
/**
* 只会查找到第一个,不会继续往后查找
*/
// ['abc', index: 0, input: 'abc fAbcdaBc cabc 123', groups: undefined]
console.log(message1.match(regex1));
// ['abc', index: 0, input: 'abc fAbcdaBc cabc 123', groups: undefined]
console.log(message1.match(regex1));02 - matchAll
一个在字符串中执行查找所有匹配的 String 方法,它返回一个迭代器(iterator)
通俗的说 : 检测某一个字符串是否符合正则的规则,返回迭代器
// 正则 => 匹配abc 全局查找,不区分大小写
const regex = /abc/gi;
// 字符串
const message = 'abc fAbcdaBc cabc 123';
/**
* matchAll传入的正则修饰符必须加g,
* 必须为全局查找,否则会报错
*/
// 返回的是迭代器
const res = message.matchAll(regex);
// console.log(res.next()); // {value: Array(1), done: false}
// console.log(res.next()); // {value: Array(1), done: false}
// console.log(res.next()); // {value: Array(1), done: false}
// console.log(res.next()); // {value: Array(1), done: false}
// console.log(res.next()); // {value: undefined, done: true}
// console.log(res.next()); // {value: undefined, done: true}
// 迭代器可以使用for...of循环
for (const iterator of res) {
console.log(iterator);
}
/**
* ['abc', index: 0, input: 'abc fAbcdaBc cabc 123', groups: undefined]
* ['Abc', index: 5, input: 'abc fAbcdaBc cabc 123', groups: undefined]
* ['aBc', index: 9, input: 'abc fAbcdaBc cabc 123', groups: undefined]
* ['abc', index: 14, input: 'abc fAbcdaBc cabc 123', groups: undefined]
*/04 - replaceAll
查找到对应的字符串,并且使用新的字符串进行替代
// 字符串
const message = 'abc fAbcdaBc cabc 123';
// 必须全局查找,全部替换
console.log(message.replaceAll(/abc/gi, 'star')); // star fstardstar cstar 123
// 只替换第一个
console.log(message.replace(/abc/i, 'star')); // star fAbcdaBc cabc 123
// 替换全部
console.log(message.replace(/abc/gi, 'star')); // star fstardstar cstar 123将字符串中数字全部删除
// 字符串
const message = '1abc fAbcdaBc cabc 123';
console.log(message.replaceAll(/\d+/gi, '')); // abc fAbcdaBc cabc05 - search
一个在字符串中测试匹配的 String 方法,它返回匹配到的位置索引,或者在失败时返回-1
// 正则
const regex = /abc/gi;
// 字符串
const message = '1abc fAbcdaBc cabc 123';
// 只会找到第一个出现的位置
console.log(message.search(regex)); // 106 - split
一个使用正则表达式或者一个固定字符串分隔一个字符串,并将分隔后的子字符串存储到数组中的 String 方法
// 正则
const regex = /abc/i;
// 字符串
const message = '1abc fAbcdaBc cabc 123';
// 切割,碰到abc切一刀 => 全局切
console.log(message.split(regex)); // ['1', ' f', 'd', ' c', ' 123']二、修饰符的使用
常见的修饰符 :

三、规则
规则 – 字符类(Character classes)
字符类(Character classes) 是一个特殊的符号,匹配特定集中的任何符号

字符类
01 - \d
const str = '123fff456aaa5423g 2432sd';
const regex = /\d+/g;
console.log(str.match(regex)); // ['123', '456', '5423', '2432']02 - \s
const str = '1\n23 fff\t\v456aa\fa5423g 2432s\vd';
const regex = /\s+/g;
console.log(str.match(regex)); // ['\n', ' ', '\t\v', '\f', ' ', '\v']03 - \w
const str = '123 fff456aaa54 _23g_ 2432sd';
const regex = /\w+/g;
console.log(str.match(regex)); // ['123', 'fff456aaa54', '_23g_', '2432sd']04 - .
const str = '123 fff456aaa54 _23g_ 2432sd';
const regex = /.+/g;
// 全部匹配到
console.log(str.match(regex)); // ['123 fff456aaa54 _23g_ 2432sd']反向类(Inverse classes)
- \D 非数字:除 \d 以外的任何字符
- \S 非空格符号:除 \s 以外的任何字符
- \W 非单字字符:除 \w 以外的任何字符
规则 – 锚点(Anchors)
01 - ^ && $
符号 ^ 和符号 $ 在正则表达式中具有特殊的意义,它们被称为“锚点”。
符号 ^ : 匹配文本开头
符号 $ : 匹配文本末尾
const message = 'My name is stAr.';
// 字符串方法
console.log(message.startsWith('my')); // true
console.log(message.endsWith('star')); // false
// 已my开头
console.log(/^my/i.test(message)); // true
// 已star.开头
console.log(/star\.$/i.test(message)); // true
// 必须完全匹配coder
const re = /^coder$/;
const info = 'codaaaer';
console.log(re.test(info)); // false02 - 词边界 \b
词边界 \b 是一种检查,就像 ^ 和 $ 一样,它会检查字符串中的位置是否是词边界
会去寻找字母
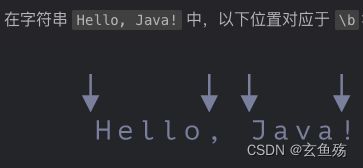
// 需求: name, name必须是一个单独的词
// 词边界
console.log(/\bname\b/i.test('My name is stAr.')); // true
console.log(/\bname\b/i.test('My namea is stAr.')); // false
// 词边界的应用
const infos = 'now time is 11:56, 12:00 eat food, number is 123:456';
const timeRe = /\b\d\d:\d\d\b/gi;
console.log(infos.match(timeRe)); // ['11:56', '12:00']const regex = /\b.+(tmall\.com|taobao\.com)(.+)*\b/gi;
const str1 = '今天我掏到了宝贝https://detail.tmall.com/trest/94dcW?id=1234&a=4-g&b=6.4.3,冲冲冲';
const str2 = '今天我掏到了宝贝,https://detail.taobao.com/trest/94d冲cWfd a冲冲冲';
const str3 = '今天我掏到了宝贝,https://detail.baidu.com/trest/94dcWfd a冲冲冲';
console.log(str1.match(regex)); // [ 'https://detail.tmall.com/trest/94dcW?id=1234&a=4-g&b=6.4.3' ]
console.log(str2.match(regex)); // [ 'https://detail.taobao.com/trest/94d冲cWfd a' ]
console.log(str3.match(regex)); // null规则 – 转义字符
如果要把特殊字符作为常规字符来使用,需要对其进行转义 => 只需要在它前面加个反斜杠
常见的需要转义的字符 :
- [] \ ^ $ . | ? * + ( )
- 斜杠符号 ‘/’ 并不是一个特殊符号,但是在字面量正则表达式中也需要转义
// 定义正则: 对.转义
const re = /\./gi;
const message = 'index.html';
console.log(message.match(re)); // .匹配文件名
const fileNames = ['abc.html', 'Home.jsx', 'index.html', 'index.js', 'util.js', 'format.js'];
const arr = fileNames.filter((item) => /\.jsx?$/.test(item));
console.log(arr); // ['Home.jsx', 'index.js', 'util.js', 'format.js']规则 – 集合(Sets)和范围(Ranges)
集合(Sets):
- 比如说,[eao] 意味着查找在 3 个字符 ‘a’、‘e’ 或者 `‘o’ 中的任意一个
范围(Ranges):
- 方括号也可以包含字符范围
- 比如说,[a-z] 会匹配从 a 到 z 范围内的字母,[0-5] 表示从 0 到 5 的数字
- [0-9A-F] 表示两个范围:它搜索一个字符,满足数字 0 到 9 或字母 A 到 F
- \d —— 和 [0-9] 相同
- \w —— 和 [a-zA-Z0-9_] 相同
匹配手机号码
/**
* 1 => 开头
* 第二位 3-9的范围
* 后面九位匹配数字
* 然后结尾
*/
const regex = /^1[3-9]\d{9}$/;
console.log(regex.test('13423231234')); // true
console.log(regex.test('a13423231234')); // false
console.log(regex.test('13423231234a')); // false
console.log(regex.test('12423231234')); // false排除范围
除了普通的范围匹配,还有类似 [^…] 的“排除”范围匹配
- [ ^0-9 ] : 表示匹配除了从 0 到 5 的数字
- [ ^a-z ] : 表示匹配除了从 a 到 z 范围内的字母
规则 – 量词(Quantifiers)
用来形容我们所需要的数量的词被称为量词( Quantifiers )
数量 {n}
- 确切的位数:{5}
- 某个范围的位数:{3,5}
缩写:
- + :代表“一个或多个”,相当于 {1,}
- ? :代表“零个或一个”,相当于 {0,1}。换句话说,它使得符号变得可选
- * :代表着“零个或多个”,相当于 {0,}。也就是说,这个字符可以多次出现或不出现
栗子一
// 栗子
const str = 'a b aa bb aaa bbb aaaa bbbb aaaaa bbbbb aaaaaa';
console.log(str.match(/a{3}/gi)); // ['aaa', 'aaa', 'aaa', 'aaa', 'aaa'] 匹配的是后面几个大于3个的a
console.log(str.match(/a{5,6}/gi)); // ['aaaaa', 'aaaaaa'] 匹配 5个a 或者 6个a栗子二
// 栗子 => 匹配标签
// 标签字符串
const htmlElement = '哈哈哈很我是标题
';
// 正则表达式
const regex = /<\/?[a-z][0-9a-z]*>/gi;
/**
* / => 有或者没有
* 第一个肯定是字母 => [a-z]
* 第二个可能是字母可能是数字,也可能没有 => [0-9a-z]*
* gi => 全局搜索,忽略大小写
*/
const res = htmlElement.match(regex);
console.log(res); // ['', '', '', '', '', '', '
', '']规则 – 贪婪( Greedy)和惰性( lazy)模式
需求:匹配下面字符串中所有使用《》包裹的内容
贪婪模式 :
默认情况下的匹配规则是查找到匹配的内容后,会继续向后查找,一直找到最后一个匹配的内容
const message = '我最喜欢的两本书: 《黄金时代》和《沉默的大多数》、《一只特立独行的猪》';
const regex = /《.+》/gi;
// 贪婪模式 : 没有分开,从最开始的《一直匹配到最后一个》
console.log(message.match(regex)); //['《黄金时代》和《沉默的大多数》、《一只特立独行的猪》']惰性模式 :
懒惰模式中的量词与贪婪模式中的是相反的
- 只要获取到对应的内容后,就不再继续向后匹配
- 可以在量词后面再加一个问号 ‘?’ 来启用它
- 所以匹配模式变为 *? 或 +?,甚至将 '?' 变为 ??
const message = '我最喜欢的两本书: 《黄金时代》和《沉默的大多数》、《一只特立独行的猪》';
const regex = /《.+?》/gi;
// 在量词后加一个 ? 号,开启惰性模式
console.log(message.match(regex)); // ['《黄金时代》', '《沉默的大多数》', '《一只特立独行的猪》']规则 – 捕获组(capturing group)
捕获组
捕获组 : 模式的一部分可以用括号括起来 (...),这称为“捕获组(capturing group)
这有两个作用:
- 它允许将匹配的一部分作为结果数组中的单独项
- 它将括号视为一个整体
方法 str.matchAll(regexp),返回迭代器对象后,遍历的结果 :
- 在索引 0 处:完全匹配。
- 在索引 1 处:第一个括号的内容。
- 在索引 2 处:第二个括号的内容
const message = '我最喜欢的两本书: 《黄金时代》和《沉默的大多数》、《一只特立独行的猪》';
/**
* 括号用来分组
* 这里分成了三个组
*/
const regex = /(《)(.+?)(》)/gi;
const res = message.matchAll(regex);
for (const iterator of res) {
console.log(iterator);
}
/**
* 0: "《黄金时代》" // 总的匹配结果
1: "《" // 第一个组
2: "黄金时代" // 第二个组
3: "》" // 第三个组
groups: undefined
index: 10
input: "我最喜欢的两本书: 《黄金时代》和《沉默的大多数》、《一只特立独行的猪》"
*/命名组
- 用数字记录组很困难
- 对于更复杂的模式,计算括号很不方便。有一个更好的选择:给括号起个名字
- 这是通过在开始括号之后立即放置 ?
来完成的
const message = '我最喜欢的两本书: 《黄金时代》和《沉默的大多数》、《一只特立独行的猪》';
/**
* 括号用来分组
* 这里分成了三个组
* 给三个组取了名字
*/
const regex = /(?《)(?.+?)(?》)/gi;
const res = message.matchAll(regex);
for (const iterator of res) {
console.log(iterator);
console.log(iterator.groups.content); // '黄金时代'
}
/**
* 0: "《黄金时代》"
1: "《"
2: "黄金时代"
3: "》"
groups: {firstIcon: '《', content: '黄金时代', lastIcon: '》'}
index: 10
input: "我最喜欢的两本书: 《黄金时代》和《沉默的大多数》、《一只特立独行的猪》" 非捕获组
- 有时我们需要括号才能正确应用量词,但我们不希望它们的内容出现在结果中。
- 可以通过在开头添加 ?: 来排除组
const message = '我最喜欢的两本书: 《黄金时代》和《沉默的大多数》、《一只特立独行的猪》';
/**
* 括号用来分组
* 这里分成了三个组
* 但是忽略了第一个组和第三个组
*/
const regex = /(?:《)(?.+?)(?:》)/gi;
const res = message.matchAll(regex);
for (const iterator of res) {
console.log(iterator);
console.log(iterator.groups.content); // '黄金时代'
}
/**
* 0: "《黄金时代》"
1: "黄金时代"
groups: {content: '黄金时代'}
index: 10
input: "我最喜欢的两本书: 《黄金时代》和《沉默的大多数》、《一只特立独行的猪》"
*/ 或 or
// 正则 => 匹配规则,是否以.()这些结尾
const reg = /\.(AMR|WAV|AWB|mp3|mp4)$/;
// 字符串
const str1 = 'abc.mp3';
const str2 = 'abc.mp4';
const str3 = 'abc.WAV';
const str4 = 'abc.mp6';
console.log(reg.test(str1)); // true
console.log(reg.test(str2)); // true
console.log(reg.test(str3)); // true
console.log(reg.test(str4)); // false四、常用正则
1. 去除字符串空格
首部 : str.replace( /^\s+/ , '' )
尾部 : str.replace( /\s+$/ , '' )
首尾部 : str.replace(/\s+$/g , '' )
全部 : str.replace(/\s/g , '' )
// 测试数组
const arr = [' adf', ' a d b ', ' a '];
const newArr = arr.map((item) => {
// 1. 字符串自带方法
// return item.trim();
// 2. 先去除首部,再去除尾部
// return item.replace(/^\s+/, '').replace(/\s+$/, '');
// 3. 去除首尾部
return item.replace(/^\s+|\s+$/g, '');
});
console.log(newArr); // ['adf', 'a d b', 'a']2. 匹配手机号
匹配 : regex = /^1[3-9]\d{9}$/
/**
* 1 => 开头
* 第二位 3-9的范围
* 后面九位匹配数字
* 然后结尾
*/
const regex = /^1[3-9]\d{9}$/;
console.log(regex.test('13423231234')); // true
console.log(regex.test('a13423231234')); // false
console.log(regex.test('13423231234a')); // false
console.log(regex.test('12423231234')); // false3. 歌词解析
匹配 : regex = /\[(?
\d{2}):(? \d{2})\.(?\d{2,3})\]/
// 歌词字符串
const lyricsStr =
'[00:00.000] 作词 : 许嵩\n[00:01.000] 作曲 : 许嵩\n[00:02.000] 编曲 : 许嵩\n[00:22.240]天空好想下雨\n[00:24.380]我好想住你隔壁\n[00:26.810]傻站在你家楼下\n[00:29.500]抬起头数乌云\n[00:31.160]如果场景里出现一架钢琴\n[00:33.640]我会唱歌给你听\n[00:35.900]哪怕好多盆水往下淋\n[00:41.060]夏天快要过去\n[00:43.340]请你少买冰淇淋\n[00:45.680]天凉就别穿短裙\n[00:47.830]别再那么淘气\n[00:50.060]如果有时不那么开心\n[00:52.470]我愿意将格洛米借给你\n[00:55.020]你其实明白我心意\n[00:58.290]为你唱这首歌没有什么风格\n[01:02.976]它仅仅代表着我想给你快乐\n[01:07.840]为你解冻冰河为你做一只扑火的飞蛾\n[01:12.998]没有什么事情是不值得\n[01:17.489]为你唱这首歌没有什么风格\n[01:21.998]它仅仅代表着我希望你快乐\n[01:26.688]为你辗转反侧为你放弃世界有何不可\n[01:32.328]夏末秋凉里带一点温热有换季的颜色\n[01:41.040]\n[01:57.908]天空好想下雨\n[01:59.378]我好想住你隔壁\n[02:02.296]傻站在你家楼下\n[02:03.846]抬起头数乌云\n[02:06.183]如果场景里出现一架钢琴\n[02:08.875]我会唱歌给你听\n[02:10.974]哪怕好多盆水往下淋\n[02:15.325]夏天快要过去\n[02:18.345]请你少买冰淇淋\n[02:21.484]天凉就别穿短裙\n[02:22.914]别再那么淘气\n[02:25.185]如果有时不那么开心\n[02:27.625]我愿意将格洛米借给你\n[02:30.015]你其实明白我心意\n[02:33.327]为你唱这首歌没有什么风格\n[02:37.976]它仅仅代表着我想给你快乐\n[02:42.835]为你解冻冰河为你做一只扑火的飞蛾\n[02:48.406]没有什么事情是不值得\n[02:52.416]为你唱这首歌没有什么风格\n[02:57.077]它仅仅代表着我希望你快乐\n[03:01.993]为你辗转反侧为你放弃世界有何不可\n[03:07.494]夏末秋凉里带一点温热\n[03:11.536]\n[03:20.924]为你解冻冰河为你做一只扑火的飞蛾\n[03:26.615]没有什么事情是不值得\n[03:30.525]为你唱这首歌没有什么风格\n[03:35.196]它仅仅代表着我希望你快乐\n[03:39.946]为你辗转反侧为你放弃世界有何不可\n[03:45.644]夏末秋凉里带一点温热有换季的颜色\n';
// 切割歌词
const lyricsSplit = lyricsStr.split('\n');
// 正则,匹配时间
const regex = /\[(?\d{2}):(?\d{2})\.(?\d{2,3})\]/;
// 解析后的歌词数组
const lyricsInfos = [];
for (const lyrics of lyricsSplit) {
// 拿到整体时间
const res = lyrics.match(regex);
if (!res) continue;
// 拿到分钟,转换为毫秒
const m = res[1] * 60 * 1000;
// 拿到秒钟,转换为毫秒
const s = res[2] * 1000;
// 拿到毫秒, 可能是2位数,可能是3位数
const ms = res[3].length === 3 ? res[3] * 1 : res[3] * 10;
const time = m + s + ms;
// 拿到内容
const content = lyrics.replace(regex, '').trim();
lyricsInfos.push({
time,
content
});
}
console.log(lyricsInfos); // [{time: 0, content: '作词 : 许嵩'} , ... , ...] 4. 时间格式化
时间戳 1659252290626 => 变为 2022-10-02 12:34:45
// timestamp: 1659252290626
// yyyy/MM/dd hh:mm:ss
// yyyy*MM*dd hh-mm-ss
function formatTime(timestamp, fmtString) {
// 1. 获取时间对象
const data = new Date(timestamp); // Wed Aug 24 2022 14:44:36 GMT+0800 (中国标准时间)
// 2. 时间转换
const dataO = {
// 匹配 yyyy => 年份
'y+': data.getFullYear(),
// 匹配 MM => 月份
'M+': data.getMonth() + 1,
// 匹配 dd => 日
'd+': data.getDate(),
// 匹配 hh => 时
'h+': data.getHours(),
// 匹配 mm => 分
'm+': data.getMinutes(),
// 匹配 ss => 秒
's+': data.getSeconds()
};
for (const key in dataO) {
// 拿到对应的正则字符串
const timeRegex = new RegExp(key, 'g');
// 看是否需要匹配
if (timeRegex.test(fmtString)) {
// 小于两位数的,用 0 在前方补齐
const value = ('' + dataO[key]).padStart(2, '0');
// 把匹配到的位置用数值来替换
fmtString = fmtString.replace(timeRegex, value);
}
}
return fmtString;
}
formatTime(new Date().getTime(), 'yyyy-MM-dd hh:mm:ss'); // 2022-08-24 15:18:33
formatTime(new Date().getTime(), 'yyyy/MM/dd hh-mm-ss'); // 2022/08/24 15-18-33
formatTime(new Date().getTime(), 'yyyy MM dd hh:mm:ss'); // 2022 08 24 15:18:33
formatTime(new Date().getTime(), 'hh:mm:ss yyyy-MM-dd '); // 15:18:33 2022-08-24