北邮国院物联网 Microprocessor 微处理器笔记
Introduction-随便聊
嵌入式系统是什么?专用的计算机系统。为专门功能可能对计算机架构,外设等做出一些取舍。
通常的限制:Cost(比如大量部署传感器节点),Size and weight limits(特定应用场景,比如下水道流量检测系统,需要体积小的节点),Power and energy limits(比如部署在极端环境下,喜马拉雅山顶采集节点,不方便去充电),Environment(防水,防高温等)
MCU MPU两种嵌入式系统区别:focus on 控制 还是 处理。控制比如点灯,机械臂,电机这些都是。处理比如摄像头采集到的数据进行图像处理。
编程语言:靠近计算机底层,主要使用汇编和c。
OS:嵌入式系统里不一定有操作系统结构。操作系统这个东西说白了就是更好地帮助管理计算机资源调度用的。现在我们来分析一下我们lab2的代码主函数:
void main(){
//background
while(1){
}
}
void IRQ_Handler(){
//interrupt handler function, frontground
}
后台部分:一个循环,重复去执行要做的任务。
这种方法乍一看也没啥问题。但是想想这样的计算机能做什么,只能按顺序执行一遍又一遍所有任务,甚至没法变顺序。
前台部分:中断处理,我们lab2里的uart_rx_isr函数,一般也用IRQ_Handler(实际上如果对lab2里的uart_rx_isr溯源一下,就会发现其实他也是被IRQ_Handler调用的,这个方法在启动对应中断时,触发中断就会自动调用)。
前后台合起来的系统还是一个裸机无os系统,只不过加了中断之后允许我们用中断的任务去打断后台轮询,改变一下执行顺序。比如串口中断发个数过来,CPU把手头后台的事情放下,去处理一下前台中断,处理完了再回来。
我们课程仅限于裸机开发的内容。
计算机系统简要介绍
Von Neumann Architecture
运算器控制器 (合在CPU中) 存储器 main memory 输入设备输出设备 IO,以及三条传输总线:数据,控制,地址 data bus / control bus / address bus.
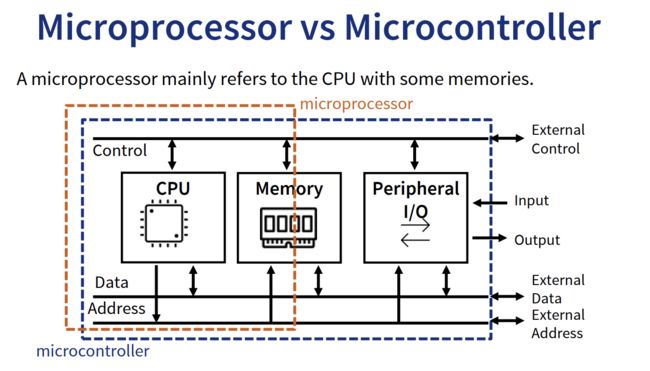
前面介绍过MPU重点在于数据计算处理,MCU则是控制,因此MPU不需要一些外设去控制外接的组件。
Harvard Architecture
和冯诺依曼区别就是在于指令和数据分开存储。这样寻指取指取数效率高。
Stored Program Concept
主要两个部分:RAM存储程序和数据,ROM存储不变只读的程序和数据。
cpu执行指令就是三个步骤的重复执行:fetch decode execute 取指解码执行
assembly
如果高级语言相当于人话翻译给计算机,汇编语言相当于计算机语言翻译给我们。更贴近底层,因此运行效率也更高,而且可以直接操作硬件。
ADD r3, r1, r2 ;r3 = r1 + r2
SUB r3, r0, r3
MOV r2, r1 ;r2 = r1
; 是注释。变量r123是寄存器register,是可以操纵硬件的部分,我们可以通过对其赋值来操作硬件。
高级语言通过 compiler 翻译为汇编语言,汇编语言通过 assembler翻译为二进制机器语言。
ARM架构
ARM是一个指令集,前面讲的几个汇编指令这些都算做指令。
ARM公司有意思的地方是,他们不做ARM设备,他们只设计指令集架构,然后授权(知识产权核,IP核)给其他半导体厂商做。
A:application,主打高性能,手机电脑有许多就是ARM架构的。
R:realtime,主打实时,比如车联网对实时性要求很高。
M:microcontroller,应用于小型嵌入式系统,我们使用的板子。
m系列有m0到m7(简单说就是性能逐渐增加?),而且向下兼容即m7兼容m0~m6.
SoC
我们的板子上有一个黑色的小芯片,上面写着stm32blabla一串字符。这个就是整个板子的核心,相当于囊括了上文提到的计算机架构的芯片结构,system on chips。

设计soc规则:首先选用IP核,设计ARM处理器,外加一系列存储、IO外设结构,全部集成在黑芯片上。
ARM处理器 processor 是 architecture 的具体涵盖,多了很多新内容比如定时器。
我们主要学习m4架构。

只看非optional大概了解即可,处理器核访问代码,数据接口。
register
前面我们已经简单介绍了register。事实上如果想对内存中数据做处理,也要先拿到处理器核中的寄存器里做运算,然后返回回去。
arm register 如下:
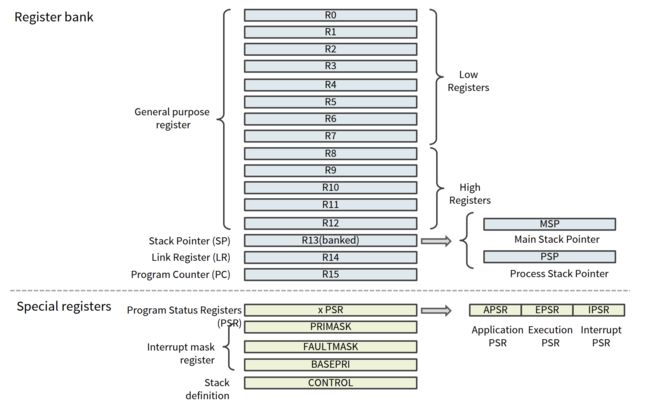
通用寄存器:临时变量,可以存储计算数据之类的。
SP:栈顶指针寄存器,指向栈顶。
LR:函数返回用,保存返回地址。比如要调用函数了,把PC的值存入LR,然后PC跳转到函数起始位置;函数返回的时候LR的值还给PC。
PC:指向程序当前执行到的位置(下一个要执行的指令的地址)程序计数器。每条指令取了之后PC自动加一条指令,比如32位指令集PC+=4B。
PSR系列是状态寄存器,指明当前程序状态。比如当前是用户模式还是内核模式?IPSR指明当前是否允许中断?等。
xPSR包括:
- APSR:计算用,如标志是否进位,结果是否为0,是否为负,是否溢出等。
- IPSR:中断处理相关。
- EPSR:执行相关,指明指令集,中断是否继续等信息。

Memory Map
m4有4g的内存空间默认映射到一片空间中,用户也可以根据自己喜好修改。有存储代码的code region,存储数据的sram region,存储外设的peripheral region,external ram region,external device region,Internal Private Peripheral Bus (PPB)。

Bit-band Operations
位带操作。
如果我们要读写32位数据中的某一位,比如第三位(从左往右是31:0,第三位是右边第4个),有的寄存器允许我们直接获取r[3],但是大多数是不允许直接获取的。
如何处理?如果写入1,那么r|0000 0000 0000 0000 0000 0000 0000 1000.
如果写入0,那么 r & 1111 1111 1111 1111 1111 1111 1111 0111.
读取:看 r & 0000 0000 0000 0000 0000 0000 0000 1000 结果是否为0.
这样很麻烦,比如我们要给0x2000 0000处的数据第3位写1,详细汇编代码:

LDR是把后面的数据加载到前面的寄存器中,[R1]是把R1的值当做一个地址,取得其中存储的数据。
这样挺麻烦的,但是因为有内存映射我们可以直接写入和获取“位带别名地址”中的数据。

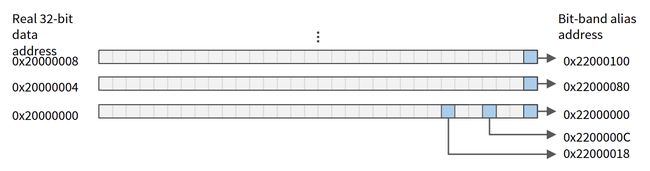
0x2000 0000处的第0位到第31位分别是:
0x2200 0000
0x2200 0004
0x2200 0008
0x2200 000c……
0x2200 007c
所以直接获取,修改0x2200 000c的数据即可。
0x2000 0000映射到0x2200 0000是 sram 区域映射,0x4000 0000映射到0x4200 0000是外设 peripheral 区域映射。
操作更快,指令更少,而且只访问一位更安全,比如刚取出0x2000 0000的32位数据,这时候中断修改了0x2000 0000的数据,这时我们取得的数据就是旧的错误数据了,修改完第3位再写回去,相当于中断白改了。
Program Image
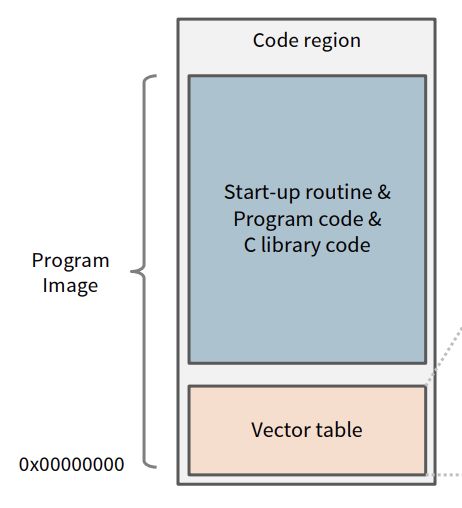
vector:向量表,存储比如main堆栈的地址(MSP),异常的地址等信息。
start-up:板子上电或rst时的启动代码。
program code:我们烧进去的程序代码。
c lib code:库函数代码。
复位时,先读取 msp 地址找到 main 在哪。然后读取 reset vector 执行 BIOS 初始化代码,再开始读取第一条,第二条指令……

Endianness
两种存储规范。
比如十进制数字,1234,一千二百三十四。然后我们记录到数据库中,地址从低到高存储为4321,权值大的位1存在地址最高处,这就是大端存储 Big endian。否则,权值大的位存在地址低处,1234地址从低到高,就是小端存储 Little endian。m4两种方法都支持。
术语“little endian(小端)”和“big endian(大端)”出自Jonathan Swift的《格列佛游记》(Gulliver’s Trabels)一书,其中交战的两个派别无法就应该从哪一端(小端还是大端)打开一个半熟的鸡蛋达成一致。
一下是Jonathan Swift在1726年关于大小端之争历史的描述:
“…下面要告诉你的是,Lilliput和Blefuscu这两大强国在过去36个月里一直在苦战。战争开始是由于以下的原因:我们大家都认为,吃鸡蛋前,原始的方法是打破鸡蛋较大的一端,可是当今皇帝的祖父小时候吃鸡蛋,一次按古法打鸡蛋是碰巧将一个手指弄破了,因此他的父亲,当时的皇帝,就下了一道敕令,命令全体臣民吃鸡蛋时打破鸡蛋较小的一端,违令者重罚。老百姓们对这项命令极为反感。历史告诉我们,由此曾发生过六次叛乱,其中一个皇帝送了命,另一个丢了王位。这些叛乱大多都是由Blefuscu的国王大臣们煽动起来的。叛乱平息后,流亡的人总是逃到那个帝国去寻救避难。据估计,先后几次有11000人情愿受死也不肯去打破鸡蛋较小的一端。关于这一争端,曾出版过几百本大部著作,不过大端派的书一直是受禁的,法律也规定该派的任何人不得做官。”(此段译文摘自网上蒋剑锋译的 《格列佛游记》第一卷第4章。)
在他那个时代,Swift是在讽刺英国(Lilliput)和法国(Blefuscu)之间的持续的冲突。Danny Cohen,一位网络协议的早期开创者,第一次使用这两个术语来指代字节顺序,后来这个术语被广泛接纳了.
大端、小端基础知识 - 知乎 (zhihu.com)
Instruction Set
指令集。早期arm指令集32位,性能好能实现的功能强大。但是太长了处理效率低。
thumb-1 指令集16位,处理效率高了,性能也降了。早期arm架构如果是支持两种指令集的,就要频繁切换模式,效率低。
后来thumb-2指令集包含早期16位和新的32位,和arm指令集的混合指令集性能没减太多,代码量和处理效率还高了。
Assembly
汇编语法。
顺序结构
label ; 可省略,用于跳转到此位置
助记符 operand1, operand2, … ; Comments
MOV r1, #0x01 ; 数据0x01放入r1
MOV r1, #'A' ; 数据A的ascii码放入r1
MOV R0, R1 ; move R1 into R0
MOVS R0, R1 ; move R1 into R0, 并且更新APSR的状态
LDR R1, [R0] ; R0存的是一个地址值如0x2000 0000, 这个指令是取出R0代表的地址中的数据存入R1
STR R1, [R0] ; 写回去
LDR R0, =0x12345678 ; Set R0 to 0x12345678
; 等效于:
; LDR R0, [PC, #offset]
; ...
; DCD 0x12345678
; 也就是先在文档末尾的一条指令里写入数据0x12345678,然后编译器自动计算PC+多少offset到达DCD的位置,把其值返给R0
; DCD是声明一个字 32bit,DCB是声明一个Byte
; 如果多个数值的声明可以用标签声明
LDR R3, =MY_NUMBER
ALIGN 4 ; 字要先用这个声明,代表停止长度
MY_NUMBER DCD 0x2000ABCC
HELLO_TEXT DCB “Hello\n”, 0 ; Null terminated string
LDRB R1, [R0] ; B: 只写8位,就是说R0地址处的数据写入R1后,R1高24位清零
SDRH R1, [R0] ; H: 只写16位
LDRSH R1, [R0] ; 视作signed有符号数,写16位
LDRB R0, [R1, #0x3] ; 从R1+3读取一个字节给R0
LDR R3, [R0, R2, LSL #2] ; 从R0+(R2<<2)读取一个字节给R3
LDR R0, [R1], #4 ; 赋完值后,令R1=R1+4
ADD R0, R0, R1
ADDS R0, R0, R1 ; 加完更新APSR状态,比如有溢出或者进位则更新
ADC R0, R1, R2 ; R1+R2还要+APSR的carry位
; SUB SBC类似
MUL R0, R1, R2
UDIV R0, R1, R2
SDIV R0, R1, R2 ; signed
例题:应该是因为有可能减成负的所以signed
指令有1字长,半字长的。hw1是指明功能用的,hw2是一些拓展比如立即数。

地址从低到高分别是:4F F0 0A 00 0A 68 10 44……
PC每次取到半个字 hw,就+2B跳转到下一个hw。
选择结构
CMP R0, R1 ; 相当于if,比较后更新APSR。EQ= LT< GT> LE<= GE >=
BEQ BRANCH_1 ; B是跳转,BL是跳转到函数执行完后返回,BX是根据地址最低位判断目标地址是arm还是thumb在决定跳转到整字还是半字。bx操作数不能是立即数,必须是寄存器
B BRANCH_2
BRANCH_1
...
B IFEND ; 不写这个就继续执行BRANCH_2了,像switch的break
BRANCH_2
...
B IFEND
循环结构
WHILE_BEGIN
UDIV R2, R0, R1 ; R2 = n / x
MUL R3, R2, R1 ; R3 = R2 * x
CMP R0, R3 ; n == (n / x) * x
BEQ WHILE_END
SUBS R1, R1, #1 ; x--
B WHILE_BEGIN ; loop back
WHILE_END
Stack
内存中有一片内存空间类似栈的数据结构。SP指针指向栈顶。
这个栈地址是从高到低的,也就是存入数据 SP–,取出数据 SP++,类似一个翻转过来的,倒着的书堆。
满堆栈:sp指针指向最后一个栈顶数据。
空堆栈:指向最后一个数据的下一个要放入数据的空位置。
我们的课程中使用空堆栈,指向下一个空位置,存数据就先存入再SP-4,取数据就先SP+4再出栈。不过这两条指令都不需要我们手动执行,有专门的指令:
PUSH {R0, R4-R7} ; Push r0, r4, r5, r6, r7
POP {R2-R3, R5} ; Pop to r2, r3, r5。入栈出栈顺序不是按照书写顺序而是自动根据寄存器地址,高地址值给高地址寄存器
存入5个数据和取出3个数据。
Functions
BL先保存当前PC值到LR,然后PC跳转到函数地址,
BX LR跳转到LR中的地址用于函数返回。
Architecture Procedure Call Standard (AAPCS) :规范定义哪些寄存器主函数和函数通用,哪些是独有的。
arm AAPCS规定:r0-r3是通用寄存器(类似全局变量),但main和函数的R4 – R8, R10-R11不通用(类似临时变量,到了函数里这些值就变了,不是原函数的),要压入栈保存。函数调用和返回的时候要保存和恢复通用寄存器值。这些由调用原函数的子函数 callee-procedure 执行。
简单的参数的函数调用:传参给R0-R3作为函数参数,R4-R11压入栈,然后跳转到函数处。

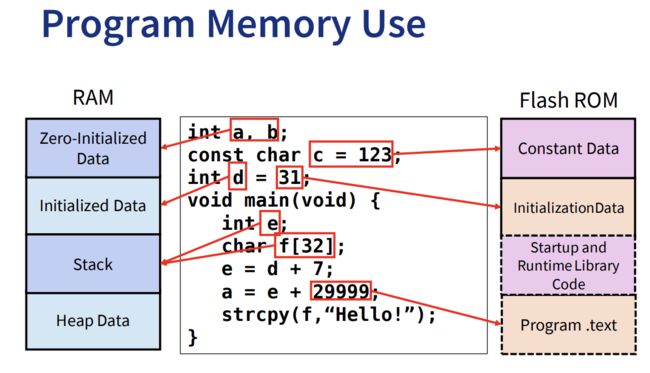
Program Memory Use
ROM里都是只读数据,比如常量常数。
const, static, volatile
貌似是不会过多涉及具体代码实现的部分,就先简单介绍一下了。
const 就是定义常量变量,定义后无法再次修改。
static 通常定义静态函数,静态函数里的值是通用的,也就是每次调用该函数其值都是接着上次调用该函数的值继续。
volatile:一个在嵌入式里挺重要的东西,软考题里出现过几次。大概就是禁止编译器优化该变量来防止不必要的错误。
比如编译器优化num变量,这样每次修改num变量的值的时候都不会立刻写入内存中,可能会先把修改时的值写入寄存器,函数返回时写回内存。
现在比如我们在main中num+=5, 修改值后的num暂时存在寄存器里。然后我们调用中断,从内存中读取当前num的值并+1.但是内存中值还没改,还是原值。返回后,main再把自己手中的num值写回内存,最后内存中num值只+5,而不是我们期望的+6.
volatile 声明后的变量不会做这样的优化,值改变了就立刻写回内存,虽然可能效率低但是安全。
Interrupts
比如我们程序的逻辑是按键按下的时候点亮小灯。第一种做法是 Polling 轮询,一直看:按键按下了吗?没有。按下了吗?没。按下了吗?……
这样主要是效率低浪费CPU资源,如果为了节约资源轮询间隔大了,又不能及时响应。
中断允许CPU专心处理background的事情,触发中断的时候先放下后台处理前台。对于无os的裸机也能实现简单的多线程切换。
异常处理流程
-
结束当前正在执行的指令。
-
当前模式寄存器值压栈保存。

-
切换模式。
-
PC LR更新(根据异常处理器提供的值)。PC去查中断向量表,看要跳到哪里,EXC_RETURN Code赋值给LR。
-
更新IPSR状态。
-
开始执行异常代码。
-
退出,BX LR把 EXC_RETURN Code 值返回给PC。
-
出栈。
Timing
中断执行也是耗时的,需要一定的时间保存源程序状态,执行中断,恢复。
FMax_Int:最大中断执行频率,即:单位时间内最多执行几次中断。
F_CPU:CPU频率,即:单位时间内CPU有多少次指令周期。
C_ISR:执行中断内容需要多少周期。
C_Overhd:中断保存、恢复数据等准备工作用多少周期。
中断一次执行所需周期:C_Overhd+C_ISR
因此, F M a x _ I n t = F C P U / ( C I S R + C O v e r h d ) F_{Max\_Int=}F_{CPU}/(C_{ISR}+C_{Overhd}) FMax_Int=FCPU/(CISR+COverhd)
U_int:中断处理实际消耗的利用率,上面那个毕竟是最大值。
U i n t = F I n t / F M a x _ I n t U_{int}=F_{Int}/F_{Max\_Int} Uint=FInt/FMax_Int
中断执行速度(和频率一样):F_Int
非中断执行速度:(1-U_Int)*F_Int
GPIO
General Purpose Input Output,
Memory-Mapped IO
把设备,控制等寄存器映射到内存里。好处就是访问设备方式和内存一样,也不用设计复杂的IO电路,便捷;缺点在于占用了内存空间。
Peripheral-Mapped IO
IO有一块专门的存储区域,和内存不一样,也有专门的不同的电路指令去访问IO。好处就是节省内存空间,也能清晰的知道什么时候发生IO了;缺点在于开发、设计上的造价增加。
GPIO
通用IO可以判断引脚高低电平,可以给引脚赋值高低电平进行控制。
stm32有几组GPIO,每个有16个Pin,可以配置为input output pullin pullup等模式,以及定时器、串口、中断等功能。
什么是上下拉模式?如果不设置为上下拉,引脚浮空的时候(没有设置输入为高或低电平的时候)浮空引脚可能收到电磁波干扰等等问题导致输入状态不确定,有0有1的,容易造成错误。
下拉:三极管控制默认接地,无输入的时候默认低电平。
上拉:三极管控制默认接Vdd 芯片工作电压。
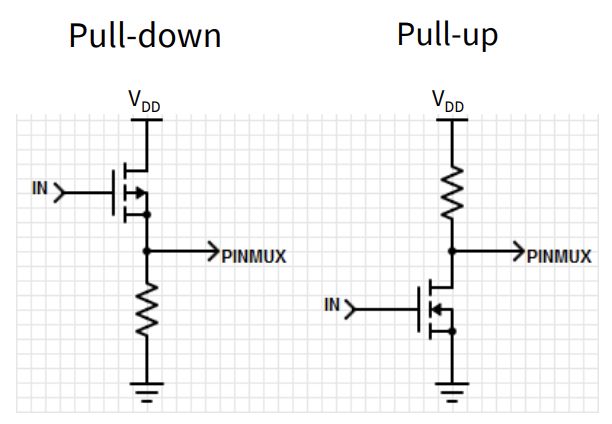
大多数引脚是这两个功能都有的,我们初始化GPIO的时候选用一个,寄存器根据值控制接通相应电路。
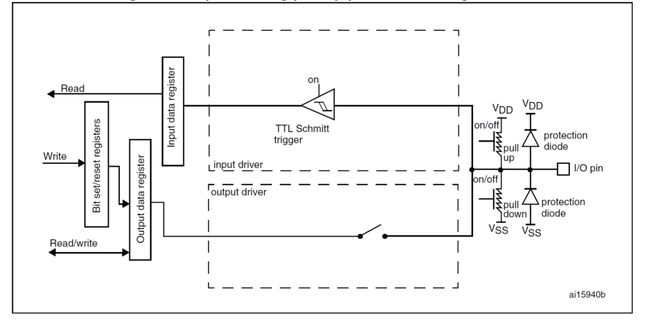
输入输出信号真的可以被称为“信号”。输入规定为0-0.5视作低电平,0.5-Vdd视作高电平,范围以外的值无效。输出电流也只有5mA左右是没有能力直接驱动一些设备的,我们可以通过一些电路比如三极管,放大器等,电路接收到信号得知”需要输出驱动电流了“然后输出大电流。
Control
每个GPIO口有:
4 * 32bit configuration registers: 配置相关信息,比如in/out,上啦下拉,开漏输出或推挽输出,输出频率等。
- 推挽输出 push-pull:能输出高低电平。
- 开漏输出 open-drain:没有能力输出高电平,想输出高电平需要设置上拉电路来输出。
2 * 32bit data registers: 输入输出数据寄存器。
1 * 32bit set/reset registers: 设置或复位寄存器。
1 * 32bit locking registers: 锁定寄存器。
2 * 32bit alternate function selection register.
Mode
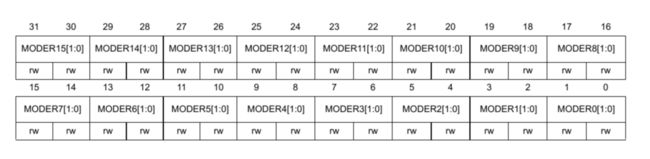
如图,32个Pin,每个两位来设置4种模式(in out 可选 模拟)。
Pull
只有3种模式(无pull,上拉,下拉)。

data
输入输出数据寄存器分开的。

CMSIS
先说一下考试定义:
CMSIS transforms memory mapped registers into C structs
#define PORT0 ((struct PORT*)0x2000030)
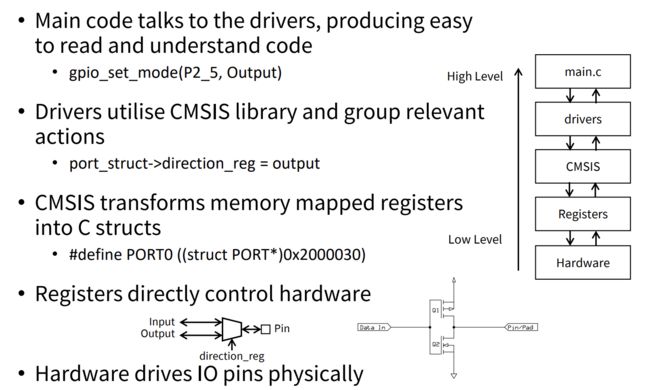
再说一下和一些嵌入式前辈讨论的理解,以下内容不许考试写:
李肯老师:arm-M推出的一系列API和软件组件,包括核心功能、DSP库、RTOS支持和调试接口等。
李肯老师:如果芯片厂不想再多一层,CMSIS就够用;但有的厂商会再在上面封一层,可能叫driver层。
李肯老师:另外CMSIS有个限定,就是ARM的ARM Cortex-M处理器;虽然它很常见,但并不是所有的处理器都是这个内核;这个需要注意。
榊:这种与内核相关的文件,比如启动文件,内核文件是CMSIS规定。
榊:对比STM32F103和GD32E23的启动文件,我们会发现是一样的:
榊:而芯片厂商要做的是根据这个arm规定的接口二次开发库函数。

李肯老师c站账号:架构师李肯的博客_CSDN博客-程序人生,粉丝福利领域博主
榊老师c站账号:风正豪的博客_CSDN博客-C语言,MSP430F5529,Linux领域博主
平时李肯老师的交流群会讨论很多嵌入式相关问题,欢迎有兴趣的同学来学习[Doge]
以上内容感兴趣的看个乐呵。
例:
typedef enum {
Reset, //!< Resets the pin-mode to the default value.
Input, //!< Sets the pin as an input with no pull-up or pull-down.
Output, //!< Sets the pin as a low impedance output.
PullUp, //!< Enables the internal pull-up resistor and sets as input.
PullDown //!< Enables the internal pull-down resistor and sets as input.
} PinMode;
gpio_set_mode(P1_10, Input);
gpio_set_mode(P2_8, Output);
int PBstatus=gpio_get(P1_10);
gpio_set(P2_8, 1);
以上代码是老师提供的driver,大意就是选定pin,传入特定参数,即可设置模式,设置输出。
感兴趣可以看看我的这篇文章,如果使用arm定义的cmsis直接去开发也是可以的:
STM32 学习笔记_4 GPIO:LED,蜂鸣器,按键,传感器的使用_灰海宽松的博客-CSDN博客
#include "stm32f10x.h"
int main(void){
/* 控制gpio需要三个步骤:开启rcc时钟,初始化,输入输出函数控制 */
RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA,ENABLE);
GPIO_InitTypeDef GPIO_InitStructure;
GPIO_InitStructure.GPIO_Mode=GPIO_Mode_Out_PP;
GPIO_InitStructure.GPIO_Pin=GPIO_Pin_0;
GPIO_InitStructure.GPIO_Speed=GPIO_Speed_50MHz;
GPIO_Init(GPIOA, &GPIO_InitStructure);
GPIO_SetBits(GPIOA,GPIO_Pin_0);
while(1){}
}
drivers二次开发,可以帮助简化。
当然这一段都是题外话了。考试就理解为“cmsis是变量宏定义直接映射到寄存器上;drivers是对其添加进一步行为”即可。
Serial Communication
串口通信,一种发送消息的通信方式。
串,指的是发数据的方式:一位一位串行发,并行是可能有多路通道,每路同时发一个数据,多路同时到达。
串口通信有单工 Simplex,半双工 Half Duplex,全双工 Full Duplex。
两种传输方式:同步 Synchronous,共用一个时钟;异步 Asynchronous,有各自的时钟。
同步很简单,发送方接收方比如都规定时钟信号下降沿收发。

异步:需要通过异步通讯协议 Asynchronous Comm. Protocol 来协调。

1位起始位标志开始传输,7/8/9位数据位,1位可选奇偶校验位,1位停止位。
RT两方需要有相同的波特率。
当然这只是最简单的串口通信因为只有双方。如果更多方通信我们需要校验地址来判断是哪个发给哪个;数据需要更复杂的校验方式。
异步通信不需要同步时钟之类电路,开销小,但是开发起来难度大一些因为需要起始结束位啥的。
RS232
异步通信,Reversed Polarity 标准电压(-3-15是1,315是0.还有一些其他标准比如TTL是+5为1,-5为0.)
发送数据有两种类型,ascii码和二进制,都得转化为二进制传输。
uart
针对stm32f401.
全双工异步串口。
为了处理RT缓冲数据(因为发收数据需要时间)我们可以通过缓冲区数组,头指针表示已经发到的位置,尾指针表示要发的数据的结尾。增加新数据,尾指针++;发一个数据,头指针++直到碰到尾。
原来发送方一直是发高电平,start frame 起始帧是1帧低电平来表示开始发数据了。
如何判断是1帧低电平?通过在这一帧里多次采样判断是不是真的是一帧低电平。
为什么多次采样?因为异步两个信号有一定的偏移,多次采样准,能确定是不是真的一整帧都低电平。
采样是有一定采样率的,不是说真的能像模拟信号一样一直采。
采样率 oversampling=16: 这个是最大可以达到的采样频率而不是真的一帧采了16次。

接收方首先第一次检测到0位,开始怀疑:有可能是串口有消息。这是start frame的第一次采样。
然后每隔一帧检测一次,3 5 7检测3次,如果2个都是0,说明确实有可能。
然后连着检测8910,如果还是2个0,说明确实是start frame。
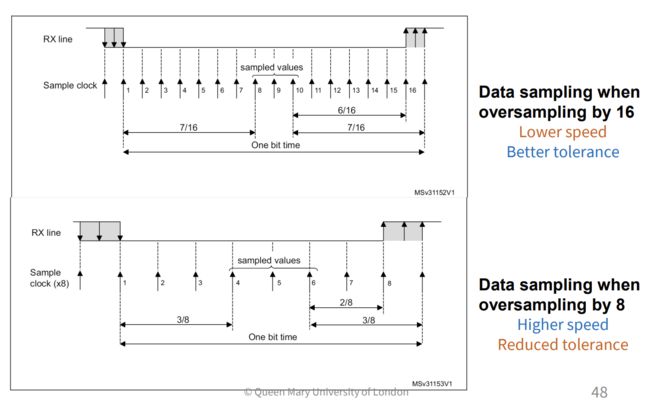
8采样率因为采样间隔长了,更容易碰到左右边界的高电平,所以容错率低。但是速度更快。
计算
波特率计算:
T x / R x ( b a u d ) = f P C L K 8 ∗ ( 2 − O V E R 8 ) ∗ U S A R T D I V T_x/R_x(baud)=\frac{f_{PCLK}}{8*(2-OVER8)*USARTDIV} Tx/Rx(baud)=8∗(2−OVER8)∗USARTDIVfPCLK
OVER8是过采样率,fPCLK是时钟频率。
USARTDIV是一个浮点数
USARTDIV浮点数怎么存储?通过算法转化为十六进制。

小数部分用一个16进制位表示,比如例1是C也就是12,转换后即为12/16也就是0.75.
例2转换为一位16进制,就是0.62*16约等于10也就是A。
整数部分直接转换十六进制即可,例2的25转为19,例1的27转为1B。
然后整数小数部分拼接起来(最多3个整数位,1个小数位,32位寄存器)。
Timer
想让程序定时运行,比如led 1s闪烁一次。如何做到?
第一种方法是愚蠢的delay延时,我自己估算一下:嗯,delay(2000)差不多1s。然后在程序中delay,点亮,delay,熄灭……
太浪费资源了。
第二种方法,32是有定时器中断的。
定时器中断大概原理是,32上有时钟晶振按固定频率周期输出0101010……定时器里有一个cnt,收到一个时钟晶振就++。
我们可以设置定时器溢出值,比如溢出值是1000,cnt加到1000会自动触发定时器中断。然后归0,继续++。

执行周期数量:1+1+1+1+(0xFFFFFFFF一直-1-1-1直到变为0x00FFFFFF的循环次数)+(r0+1的执行次数,1次)
定时器也有一些扩展方法,比如我们可以设定++还是–;可以设定信号源是时钟或者外部输入的方波信号;可以读取计数值……
我们课件常用方法好像是–到0触发中断,然后恢复初值。

PWM
PWM这个东西是什么?
PWM(Pulse Width Modulation)脉冲宽度调制,在具有惯性的系统中,可以通过对一系列脉冲的宽度进行调制,来等效地获得所需要的模拟参量,常应用于电机控速等领域。
就好比说,你骑自行车速度只能是100和0,模拟电信号只能输出高低。
但是呢,你骑自行车是有惯性的,以100速度蹬一脚,以0速度蹬1脚,100速度蹬一脚……
整体来看你的自行车平均速度是50(我们假设加速度不需要时间哈)
这个应用场景有很多,比如设定led闪烁频率:高低高低高低……,因为频率极高,我们肉眼看不出来在闪,给我们呈现的视觉效果就是以一半的亮度在亮。高低低高低低就是1/3亮度。
比如电机通过这个方式调速度。
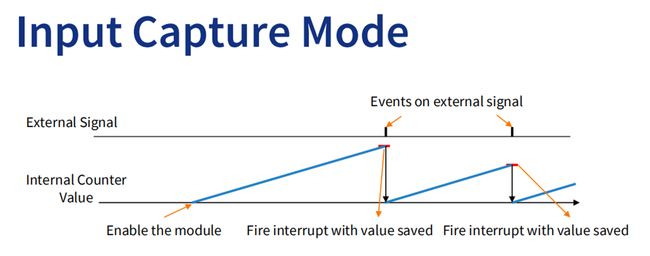
那么他有什么应用场景。第一,输入捕获 Input capture。
对于一个这种有惯性的系统,我们也可以反过来读取其波形来判断其速度。比如电机放一个转速检测传感器,把输入波形作为定时器的时钟源信号,定时器一直++:检测上升下降沿时记录cnt值,通过差值比较计算时间间隔。
第二,输出比较 output compare。
定时器一直++,与预先设定好的阈值比较,如果相等触发中断输出。
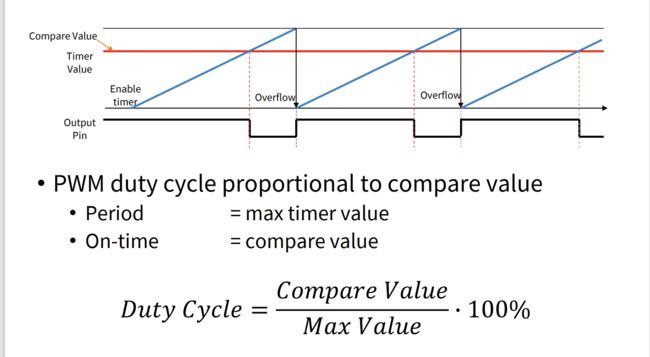
这就是PWM。占空比相当好算。
Low Power Timer
我们目前假设的是CPU一直运作的,只是在后台和前台之间切换。有一种低功耗定时器使得没有发生定时器中断的时候CPU被置为低功耗状态,只有发生定时器中断的时候才启动。(使用 __WFI() wait for instruction 指令)

SysTick
M系列自带的一个系统时钟,使用处理器时钟或者参考时钟作为时钟源。
有四位寄存器:
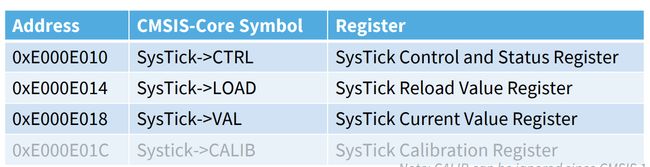
每次赋值是load,一直–到0时重新load赋值。ctrl是控制启用系统时钟。这个是CMSIS有提供的数据结构和相关操作函数的时钟处理部分。

init 参数是中断间隔的毫秒数。timer_set_callback() 里跟一个可以是自己定义的函数,使得触发定时器中断时该函数被执行。以上代码意思是每隔100ms LED灯翻转一次,且 CPU 常态下处于低功耗状态。
I2C
连接多个模块的传输方案:I2C,使用两根总线。

两根总线分别是时钟总线 SCL 和数据总线 SDA。
通信过程
现在我们串一遍I2C上一个模块(master)要给另一个模块(slave)发消息的过程。

- MCU 使用一定的方法标识自己开始传输了。
- MCU 发送 LCD slave 的地址+一位读写位,其他模块接收到发现地址不是自己的,就不做处理。
- LCD 接收到后知道目标是自己,于是返回 ack。
- MCU 收到 ACK 后发送一帧数据。
- 发送完 MCU 等着 ACK,收到 ACK 后继续发送下一帧数据。
- 一直发送到发送停止位 stop 结束。

数据长度可以设置,比如789.
总线上的器件是开漏输出的半双工通信。
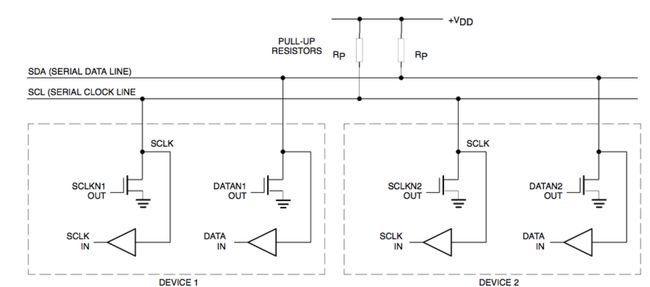
默认总线是上拉电阻拉成高电平。
当器件输出 out 为低电平时,总线导通到接地,总线被拉低(整条总线都被拉低)。江协科技老师举的例子很好,就像公交车上的一根横杆,有人拉住横杆拽下来,整条横杆都被拉低了,其他人都知道“横杆被一个人拉低了,说明有人正在使用总线”。
然后是总线传输数据的方式,SCL SDA 两根总线在何种情况下表示 start stop 0 1 bit?

首先都是 SCL 为高电平时 SDA 的数值才有意义。
SDA 从高到低,表示 start 位。从低到高,表示 stop 位。
start 位后,SDA 高电平表示1,低电平表示0.
发送完 1byte 数据后,总线保持拉高状态。如果接收方把总线拉低了,发送方发现总线1→0了(不是发送方自己拉的,是接收方给他拉下来的,但是发送方能察觉到),说明接收方成功接收了并且拉了拉总线以示“收到”。如果 SDA 还是保持在高电平,说明接收方没有成功收到或者成功发送 ACK。
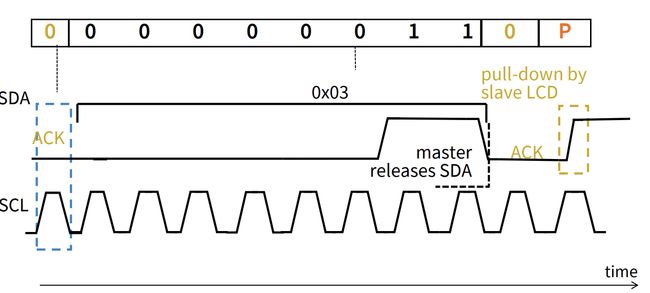
问题处理
I2C 是一种很简单的主从通信协议了,但是局限性也很多,比如7 bit 的地址线只允许 2^7 个设备;一次顶多两个设备主从通信;一个设备的快慢会影响到整条总线的通信等。
问题1:从设备处理速度太慢了,赶不及在下一个时钟周期接收新数据帧怎么办?
方法:clock stretching, 拉低一段时间 SCL 假装下一个时钟周期还没到。

问题2:多个设备同时发数据冲突了怎么办?
方法:Bus Aribitation,前面我们知道总线被一个设备拉低了,所有设备都能接收到总线拉低的信号。因此如果两个设备同时开始发信息,前面数据一致都无所谓,等到第一次数据不一致的时候,一个设备发送数据0,一个发送数据1,这时 SDA 总线被 DATA2 的0拉低了。

发送 DATA1 数据的设备就明白了:有人同时在和我一起发数据,因此总线不是我预期的1而是被他拉低为0了。那我 quit,你发吧。然后就只有 DATA2 发送的数据了。
问题3:以上发送的数据每次都是 1byte 8bits 很正好。那如果要发送的地址不是 8bits 呢?
方法:少于 8bits 用一些固定的额外的 start 位填充,多于 8bits 的地址用两个 bytes,不够的也是用额外的 start 位填充。

问题3:如果我 master 发完数据,想紧接着再收数据,变成 slave,可行吗?
方法:通过一个 sr 信号,也就是 repeat start 重发 start 位,来标识自己是 read 而不再是 write 了重新开始通信。

编址格式
slave 地址编址有一些固定格式。

0000 000 0:广播,对所有 slave 结点讲话。如果 slave 无视(NACK),就不会参与广播。如果返回 ACK 就参与进来了。不过多个 slave 都返回 ACK 的话 master 是不知道都有谁回应了的。
第二个 byte 发送一些行为相关,比如:start,clear,reset software
编程应用
slave mode:
- I2C 设备默认工作在 slave mode。
- 外设时钟在 I2C_CR2 寄存器中编程。频率介于 2kHz~100kHz。
- 硬件自动等待发过来的 start 和 addr 信息。
- 如果 addr 信息和 OAR1 中存储的地址相同,说明目标是自己。如果 ACK 位为1,则发送 ack pulse。
- 设置 ADDR 位,1表示匹配。
- 如果 ITEVFEN 就是中断事件 flag 为1,则生成中断。
- TRA 位标明 slave 是 R 还是 T 模式(收 or 发)。
- BTF 位标识收没收完。


这么说起来还是有点混乱 I2C 到底经历了哪些才顺利发送了数据?
首先,从主模式的概念。master 主模式驱动时钟信号,发起传输;slave 从模式响应传输。
主模式
发送:
所有 EV 事件都会拉低 SCL,直到相应软件序列执行完成。
S:start 事件。比如CR2 寄存器中设置外设时钟,配置时钟寄存器,上升时钟寄存器,使能 CR1 来启用时钟,CR1 中设置 start 位,等待总线被拉低表示就绪,发送启动信号,并切换为主模式。
EV5:启动事件成功进行,设置 SB 寄存器=1. SB 寄存器=1后才可以进行地址阶段,执行完地址阶段会自动清除 SB 和 EV5 事件。
Address:地址阶段。传输7位地址+1位读写位,然后等待从机的 ack。收到 ack 进入 EV6.
EV6:设置 addr 位=1代表地址阶段顺利执行, master 收到 ack了。清除 EV6 后自动进入 EV8.
EV8:设置 TxE ,准备写入主机要传入的数据。TxE 表示数据寄存器为空可以写入。每次数据写入 DR 都会清空 TxE 和 EV8 事件。写完数据数据传过去了,主机收到 ack 后继续传输。以 BTF=1 表示数据传输的结尾。
void i2c_write(uint8_t address, uint8_t *buffer, int buff_len) {
int i = 0;
// Send in sequence: Start bit, Contents of buffer 0..buff_len, Stop
while (((I2C1->SR2>>1)&1)); // wait until I2C1 is not busy anymore
I2C_GenerateSTART(I2C1, ENABLE); // Send I2C1 START condition
// wait for I2C1 EV5 --> Slave has acknowledged start condition
while (!I2C_CheckEvent(I2C1, I2C_EVENT_MASTER_MODE_SELECT));
// Send slave Address for write then wait for EV6
I2C_Send7bitAddress(I2C1, address, I2C_Direction_Transmitter);
while (!I2C_CheckEvent(I2C1, I2C_EVENT_MASTER_TRANSMITTER_MODE_SELECTED));
while (i < buff_len){
I2C_SendData(I2C1, buffer[i]); // send data then wait for EV8_2
while (!I2C_CheckEvent(I2C1, I2C_EVENT_MASTER_BYTE_TRANSMITTED));
i++;
}
I2C_GenerateSTOP(I2C1, ENABLE); // send stop bit
}

接收:
前面和 master transmit 都一样。
TxE 改为 RxE 了,=1标识接收到了数据。
master 自己设置 stop 事件后(发送 NACK)停止接收。
void i2c_read(uint8_t address, uint8_t *buffer, int buff_len) {
int i = 0;
// Start bit, Contents of buffer from 0..buff_len, sending a NACK
// for the last item and an ACK otherwise, Stop bit
I2C_GenerateSTART(I2C1, ENABLE);
while(!I2C_CheckEvent(I2C1, I2C_EVENT_MASTER_MODE_SELECT)); //EV5
// Send slave Address for write then wait for EV6
I2C_Send7bitAddress(I2C1, address, I2C_Direction_Receiver);
while (!I2C_CheckEvent(I2C1, I2C_EVENT_MASTER_RECEIVER_MODE_SELECTED));
I2C_AcknowledgeConfig(I2C1, ENABLE); // going to send ACK
while (i < buff_len - 1){
while (!I2C_CheckEvent(I2C1, I2C_EVENT_MASTER_BYTE_RECEIVED)); //EV7
buffer[i] = I2C_ReceiveData(I2C1); // get data byte
i++;
}
I2C_AcknowledgeConfig(I2C1, DISABLE); // going to send NACK
while (!I2C_CheckEvent(I2C1, I2C_EVENT_MASTER_BYTE_RECEIVED)); //EV7
buffer[i] = I2C_ReceiveData(I2C1); // get the last byte
I2C_GenerateSTOP(I2C1, ENABLE); // send stop
}
从模式

发送:
start 启动事件由 master 发起。从机校验地址并决定是否发送 ack 位。
EV1:设置 addr 位表示地址匹配。
EV3-1:设置 TxE 位,开始传入数据。一直到主机返回 NACK 表示不想再要数据了,或者 AF=1 说明 ack 失败了为止。

接收:
前面到 EV1 和 slave transmit 都一样。
- 数据从 DR 寄存器中读。
- 读入一个 byte 后,如果 ack 位已经设置,则返回 ack 信息。
- RxE 位是接收数据的状态寄存器。
- 主机生成停止条件时停止。
异常情况:
总线错误,NACK,仲裁失败,时钟异常超时。
