【数据结构】--并查集
目录
一、概念
编辑
二、应用场景--“连接”问题(属于同一Qu
三、实现思路
四、如何存储数据
五、定义接口
1.初始化(init)
2.其他
isSame()
六、抽象类
六、Quick Find【v1 所在集合的所有元素都指向 v2 的根节点】
1.Union
1.Union图解
2.注意点:
3.代码实现
2.find
1.find图解
2.代码实现
3.完整代码
七、(常用)Quick Union【v1 的根节点指向 v2 的根节点】
1.Union
1.注意点
2.Quick Union图解
3.代码实现
2.find
代码实现
3.完整代码
八、Quick Union的优化
1.简介
2.方案一:基于size的优化【元素少的树 嫁接到 元素多的树】
编辑
3.方案二:基于rank的优化【矮的树 嫁接到 高的树】
九、路径压缩(Path Compression)
1.什么是路径压缩?
2.代码实现
十、路径分裂(Path Spliting)
1.概念
2.代码实现
十一、路径减半(Path Halving)
1.概念
2.代码实现
十二、总结
一、概念
并查集(Disjoint Set)是一种可以动态维护若干个不重叠的集合,并支持合并与查询两种操作的一种数据结构。按照一般的思路,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中,这样时间复杂度就太高啦。而并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。
并查集支持查找一个元素所属的集合以及两个元素各自所属的集合的合并等运算,当给出两个元素的一个无序对(a,b)时,需要快速“合并” a 和 b 分别所在的集合,这期间需要反复“查找”某元素所在的集合。“并”、“查”和“集” 3 个字由此而来。在这种数据类型中,n个不同的元素被分为若干组。每组是一个集合,这种集合叫分离集合,称之为并查集。

二、应用场景--“连接”问题(属于同一Qu
并查集是一种非常精巧而实用的数据结构,它注意用于处理一些不相交集合的合并温问题。一些常见的用途有连通子图,求最小生成树Kruskal算法和求最近公共祖先(LCA)。
三、实现思路

四、如何存储数据
假设并查集处理的数据都是整型,那么可以用整型数组来存储数据。
- 数组索引代表元素值
- 索引对应的值代表这个元素的根节点
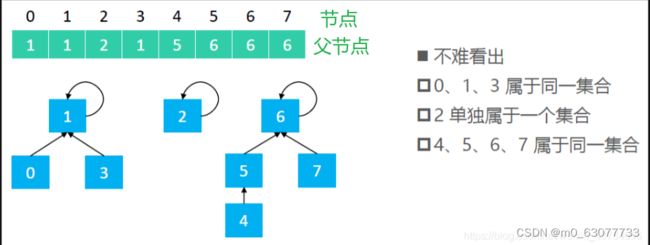
并查集是可以用数组实现的树形结构(二叉堆、优先级队列也是可以用数组实现的树形结构)
五、定义接口
1.初始化(init)
初始化时,每个元素各自属于一个单元素集合
private int[] parents;
public UnionFind(int capacity){
if(capacity < 0){
throw new IllegalArgumentException("capacity must >= 1");
}
parents = new int[capacity];
for (int i = 0; i < parents.length; i++) {
parents[i] = i;
}
}
2.其他
/**
* 查找v所属的集合(根结点)
*/
public abstract int find(int v);
/**
* 合并v1、v2所在的集合
*/
public abstract void union(int v1, int v2);
/**
* 检查v1、v2是否属于同一集合
*/
public boolean isSame(int v1, int v2);isSame()
public boolean isSame(int v1, int v2){
return find(v1) == find(v2);
}六、抽象类
这是个并查集的抽象类,后面的所有并查集都将继承它。
package union;
/**
* 这是个并查集的抽象类,后面的所有并查集都将继承它。
*/
public abstract class UnionFind {
// 初始一维数组存放父节点
protected int[] parents;
//初始化
public UnionFind(int capacity){
if (capacity<0){
throw new IllegalArgumentException("capacity must be >=1");
}
// 创建一个capacity的数组容量大小存放父节点
parents=new int[capacity];
//将初始化,自己作为父节点
for (int i=0;i=parents.length){
throw new IllegalArgumentException("v is out of bounds");
}
}
}
六、Quick Find【v1 所在集合的所有元素都指向 v2 的根节点】
1.Union
1.Union图解


2.注意点:
1)将v1的根节点修改成v2的根节点,同时要将v1的根节点的根节点全部修改为v2的根节点。
2)union 时间复杂度:O(n)
3)树的高度最高为2
3.代码实现
/**
* 将v1所在集合的所有元素都嫁接到v2的父节点上
* v1 v2 union(v1,v2)
* 0 4 4
* 1 2 3 0 1 2 3
*/
public void union(int v1, int v2){
int p1 = parents[v1];
int p2 = parents[v2];
for (int i = 0; i < parents.length; i++) {
if(parents[i] == p1){
//如果跟p1是同一个父节点,则将其父节点修改为p2的
parents[i] = p2;
}
}
}2.find
1.find图解

2.代码实现
/**
* 查找v所属的集合(根节点)
* @param v
* @return
*/
public int find(int v){
rangeCheck(v);
return parents[v];
}3.完整代码
UnionFind_QuickFind
package union;
/**
* 查找(Find)的时间复杂度:O(1)
* 合并(Union)的时间复杂度:O(n)
*/
public class UnionFind_QuickFind extends UnionFind{
public UnionFind_QuickFind(int capacity) {
super(capacity);
}
/**
* 查找v所属的集合(根节点)
* @param v
* @return
*/
public int find(int v){
rangeCheck(v);
return parents[v];
}
public void union(int v1,int v2){
// p1:表示v1的父节点
int p1=find(v1);
// p2:表示v2的父节点
int p2=find(v2);
if (p1==p2) return;
// 到此处则v1和v2不是同一个父节点
for (int i=0;i七、(常用)Quick Union【v1 的根节点指向 v2 的根节点】
1.Union
1.注意点
1)Quick Find 的
union(v1, v2):让 v1 所在集合的所有元素都指向 v2 的根节点。2)Quick Union 的
union(v1, v2):让 v1 的根节点指向 v2 的根节点 。(与Quick Find进行对比)3)树的最大高度超过2
2.Quick Union图解


3.代码实现
/**
* 将v1的根节点嫁接到v2的根节点上
*/
@Override
public void union(int v1, int v2) {
int p1=find(v1);
int p2=find(v2);
if (p1==p2){
return;
}
// 将p1指向p2的父节点【也就是p1的父节点为p2的父节点】
parents[p1]=p2;
}2.find

当当前节点值和父节点的值相等的时候,说明该节点是根节点【v==parents[i]】
代码实现
/**
* 通过parents链表不断向上查找,直到根节点
* @param v
* @return
*/
@Override
public int find(int v) {
rangeCheck(v);
//当v不跟父节点的值相等,则表示还未找到根节点
while (v!=parents[v]){
v=parents[v];
}
return v;
}3.完整代码
QuionFind_QuickUnion
package union;
/**
* 查找(Find)的时间复杂度:O(logn), 可以优化至 O(()), α() < 5
* 合并(Union)的时间复杂度:O(logn), 可以优化至 O(()), α() < 5
*/
public class QuionFind_QuickUnion extends UnionFind{
public QuionFind_QuickUnion(int capacity) {
super(capacity);
}
/**
* 将v1所在的根节点 嫁接到v2的根节点上
* @param v1
* @param v2
*/
@Override
public void union(int v1, int v2) {
int p1=find(v1);
int p2=find(v2);
if (p1==p2){
return;
}
// 将p1指向p2的父节点【也就是p1的父节点为p2的父节点】
parents[p1]=p2;
}
/**
* 通过parents链表不断向上查找,直到根节点
* @param v
* @return
*/
@Override
public int find(int v) {
rangeCheck(v);
//当v不跟父节点的值相等,则表示还未找到根节点
while (v!=parents[v]){
v=parents[v];
}
return v;
}
}
八、Quick Union的优化
1.简介

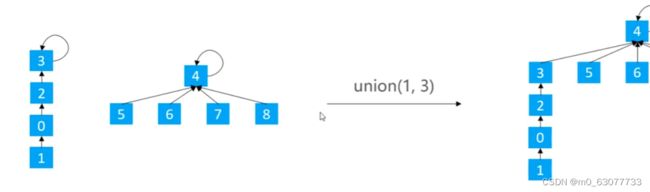
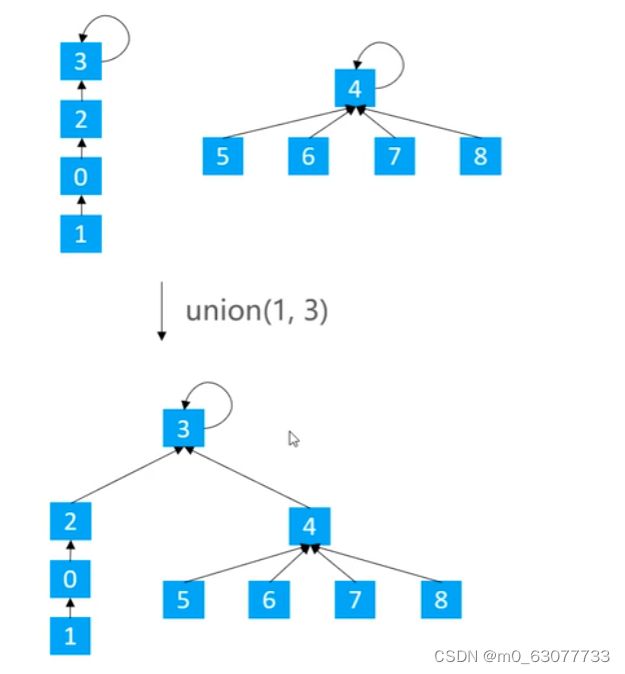
2.方案一:基于size的优化【元素少的树 嫁接到 元素多的树】
不是固定的让某一棵树嫁接到另一棵树,让元素少的树 嫁接到 元素多的树。
package union;
/**
* Quick Union--基于size的优化
*/
public class UnionFind_QuickUnion_Size extends UnionFind{
// 该数组存放以size[i]为根节点的节点个数
private int[] sizes;
public UnionFind_QuickUnion_Size(int capacity) {
super(capacity);
sizes=new int[capacity];
for (int i=0;iv2所在的树的长度,则将v2嫁接到v1上
parents[p2]=p1;
sizes[p1]+=sizes[p2];
}
}
/**
* 通过parents链表不断向上查找,直到根节点
* @param v
* @return
*/
@Override
public int find(int v) {
rangeCheck(v);
//当v不跟父节点的值相等,则表示还未找到根节点
while (v!=parents[v]){
v=parents[v];
}
return v;
}
}
3.方案二:基于rank的优化【矮的树 嫁接到 高的树】
package union;
/**
* Quick Union--基于rank的优化
*/
public class UnionFind_QuickUnion_Rank extends UnionFind{
// 该数组存放以rank[i]为存放高度
private int[] ranks;
public UnionFind_QuickUnion_Rank(int capacity) {
super(capacity);
ranks=new int[capacity];
for (int i=0;i ranks[p2]){
parents[p2] = p1;
}else{ // ranks[p1] == ranks[p2]
//谁嫁接谁都可以
parents[p1] = p2;//嫁接到p2
ranks[p2] += 1;
}
}
/**
* 通过parents链表不断向上查找,直到根节点
* @param v
* @return
*/
@Override
public int find(int v) {
rangeCheck(v);
//当v不跟父节点的值相等,则表示还未找到根节点
while (v!=parents[v]){
v=parents[v];
}
return v;
}
}
九、路径压缩(Path Compression)
虽然有了基于 rank 的优化,树会相对平衡一点,但是随着 union 次数的增多:树的高度依然会越来越高,导致 find 操作变慢,尤其是底层节点 (因为 find 是不断向上找到根节点) 。
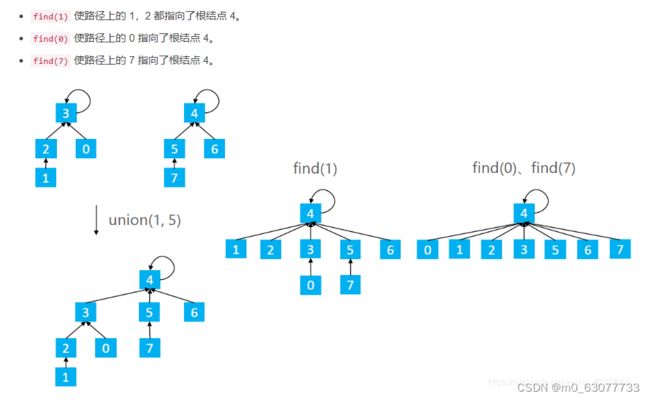
1.什么是路径压缩?
在 find 时使路径上的所有节点都指向根节点

2.代码实现
该类继承了 UnionFind_QU_R,表明它是在 Quick Union 的 rank 优化的基础上,再优化
package union;
/**
* Quick Union - 基于rank的优化 - 路径压缩(Path Compression)
*/
public class UnionFind_QuickUnion_rank_PathCompression extends UnionFind_QuickUnion_Rank{
public UnionFind_QuickUnion_rank_PathCompression(int capacity) {
super(capacity);
}
@Override
public int find(int v) { //v==1,parents[v]==2
rangeCheck(v);
if (parents[v]!=v){ //表示还没有找到根节点
parents[v]=find(parents[v]);//将根节点赋值
}
return parents[v];
}
}
十、路径分裂(Path Spliting)
1.概念
使路径上的每个节点都指向其祖父节点(parent的parent)

2.代码实现
该类继承了 UnionFind_QU_R,表明它是在 Quick Union 的 rank 优化的基础上
package union;
/**
* Quick Union - 基于rank的优化 - 路径分裂(Path Spliting)
*/
public class UnionFind_QuickUnion_rank_PathSpliting extends UnionFind_QuickUnion_Rank{
public UnionFind_QuickUnion_rank_PathSpliting(int capacity) {
super(capacity);
}
@Override
public int find(int v){
rangeCheck(v);
while(v != parents[v]){
// 将2保留下来,如果不保留,则2直接消失
int p = parents[v];
// parents[parents[v]]:找到v的祖父节点
parents[v] = parents[parents[v]];
v = p;
}
return parents[v];
}
}
十一、路径减半(Path Halving)
1.概念
使路径上每隔一个节点就指向其祖父节点(parent的parent)

2.代码实现
该类继承了 UnionFind_QU_R,表明它是在 Quick Union 的 rank 优化的基础上,再优化
package union;
/**
* Quick Union - 基于rank的优化 - 路径减半(Path Halving)
*/
public class UnionFind_QuickUnion_rank_PathHalving extends UnionFind_QuickUnion_Rank{
public UnionFind_QuickUnion_rank_PathHalving(int capacity) {
super(capacity);
}
@Override
public int find(int v){
rangeCheck(v);
while(v != parents[v]){
parents[v] = parents[parents[v]];
v = parents[v];
}
return v;
}
}
十二、总结
