SpringBoot 整合 Elasticsearch (超详细)
SpringBoot 整合 Elasticsearch (超详细)
注意:
1、环境搭建
安装es
Elasticsearch 6.4.3 下载链接
为了方便,环境使用Windows
配置
解压后配置
- 找到config目录的
elasticsearch.yml 
分词器
-
默认的Es是不支持中文分词的,下载
ik分词器(下载的版本要与Es保持一致) -
Elasticsearch-ik 6.4.3 下载链接
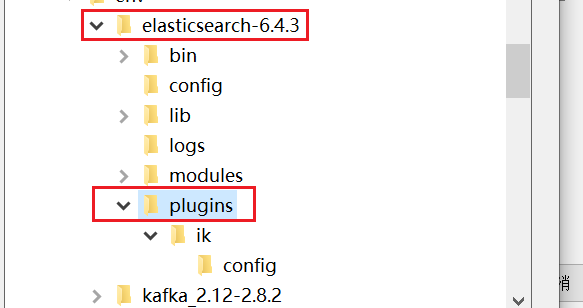
下图所示,解压后的分词器放在
plugins目录下,ik目录需要自己创建
启动
- 由于我是在
Windows环境下,找到bin目录的elasticsearch.bat双击即可。
命令测试
- 查看健康状态
- curl -X GET “localhost:9200/_cat/health?v“
- 查看所有节点
- curl -X GET “localhost:9200/_cat/nodes?v“
- 新建索引
- curl -X PUT “localhost:9200/test”
- ☀️ 查看索引
- curl -X GET “localhost:9200/_cat/indices?v”
- 删除索引
- curl -X DELETE “localhost:9200/test”
2、整合 Es
依赖 & 配置
- ❌ 我这里使用的是
SpringBoot 2.1.5.RELEASE,根据实际情况选择版本。
<dependency>
<groupId>org.springframework.datagroupId>
<artifactId>spring-data-elasticsearchartifactId>
<version>2.1.6.RELEASEversion>
dependency>
- ❓
yaml配置

- ❓
properties配置
spring.data.elasticsearch.cluster-name=community
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
启动项目:
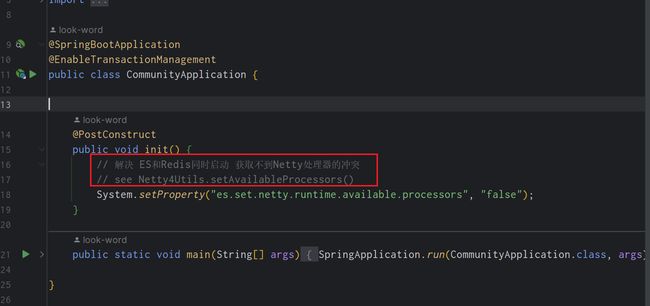
- ❌ 不出意外肯定会出意外

- ❓ 这个问题是由于Es底层的问题,这里就不展开解释,会提供思路,自行了解
解决办法:
3、使用
SpringBoot 整合 Elasticsearch视频教程
实体类
- ❌ 相信之前学过Jpa的同学,对于以下配置很熟悉。
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
// 指定Es 索引 类型 分片 备份
@Document(indexName = "discusspost", type = "_doc", shards = 6, replicas = 3)
@Data
public class DiscussPost implements Serializable {
private static final long serialVersionUID = 114809849189593294L;
// 标识主键
@Id
private Integer id;
// 对应文档类型
@Field(type = FieldType.Integer)
private Integer userId;
/**
* type 类型
* analyzer 存储解析器
* searchAnalyzer 查询解析器
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String title;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String content;
}
持久层
- ❌
ElasticsearchRepository里面有许多常用方法
@Repository
public interface DiscussPostRepository extends ElasticsearchRepository<DiscussPost, Integer> {
}
测试代码
- ❌ 查询数据层的代码就不展示了,我会在代码中说明
- 时间足够,建议把视频看完
/**
* @author : look-word
* 2022-11-03 18:56
**/
@SpringBootTest
@RunWith(SpringRunner.class)
public class ElasticSearchTest {
@Resource
private DiscussPostRepository discussPostRepository;
@Resource
private DiscussPostMapper discussPostMapper;
@Resource
private ElasticsearchTemplate elasticsearchTemplate;
@Test
public void testInsert() {
// 将查询的结果,同步到Es中
discussPostRepository.save(discussPostMapper.selectDiscussPostById(241));
}
@Test
public void testInsertAll() {
// 批量导入 discussPostRepository.saveAll()
discussPostRepository.saveAll(discussPostMapper.selectDiscussPosts(101, 0, 100));
}
/**
* 测试更新
*/
@Test
public void testUpdate() {
DiscussPost discussPost = discussPostMapper.selectDiscussPostById(241);
discussPost.setContent("我爱中华人民共和国,我是中国人");
discussPostRepository.save(discussPost);
}
/**
* 测试修改
*/
@Test
public void testDelete() {
discussPostRepository.deleteById(241);
}
/**
* 测试查询
*/
@Test
public void testSelect() {
// 构造查询条件
SearchQuery searchQuery = new NativeSearchQueryBuilder()
// (查询的值,查询字段1,查询字段1) 匹配title或者title里面是否含有互联网寒冬
.withQuery(QueryBuilders.multiMatchQuery("互联网寒冬", "title", "title"))
.withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC)) // 排序
.withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC))
.withPageable(PageRequest.of(0, 10)) // 分页
.withHighlightFields(
new HighlightBuilder.Field("title").preTags("").postTags(""),
new HighlightBuilder.Field("content").preTags("").postTags("")
).build(); //高亮
Page<DiscussPost> page = discussPostRepository.search(searchQuery);
page.get().forEach(System.out::println);
}
/**
* 测试查询高亮显示
*/
@Test
public void testSelectHighlight() {
// 构造查询条件
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.multiMatchQuery("互联网寒冬", "title", "content"))
.withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC)) // 排序
.withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC))
.withPageable(PageRequest.of(0, 10)) // 分页
.withHighlightFields(
new HighlightBuilder.Field("title").preTags("").postTags(""),
new HighlightBuilder.Field("content").preTags("").postTags("")
).build(); //高亮
Page<DiscussPost> page = elasticsearchTemplate.queryForPage(searchQuery, DiscussPost.class, new SearchResultMapper() {
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> aClass, Pageable pageable) {
SearchHits hits = response.getHits();
if (hits.getTotalHits() <= 0) {
return null;
}
List<DiscussPost> list = new ArrayList<>();
for (SearchHit hit : hits) {
DiscussPost post = new DiscussPost();
String id = hit.getSourceAsMap().get("id").toString();
post.setId(Integer.parseInt(id));
String userId = hit.getSourceAsMap().get("userId").toString();
post.setUserId(Integer.parseInt(userId));
String title = hit.getSourceAsMap().get("title").toString();
post.setTitle(title);
String content = hit.getSourceAsMap().get("content").toString();
post.setContent(content);
String type = hit.getSourceAsMap().get("type").toString();
post.setType(Integer.parseInt(type));
String status = hit.getSourceAsMap().get("status").toString();
post.setStatus(Integer.parseInt(status));
String createTime = hit.getSourceAsMap().get("createTime").toString();
post.setCreateTime(new Date(Long.parseLong(createTime)));
String commentCount = hit.getSourceAsMap().get("commentCount").toString();
post.setCommentCount(Integer.parseInt(commentCount));
String score = hit.getSourceAsMap().get("score").toString();
post.setScore(Double.parseDouble(score));
// 处理高亮
HighlightField titleField = hit.getHighlightFields().get("title");
// 页面有多个高亮字 只显示第一个
if (titleField != null) {
post.setTitle(titleField.getFragments()[0].toString());
}
HighlightField contentField = hit.getHighlightFields().get("content");
if (contentField != null) {
post.setTitle(contentField.getFragments()[0].toString());
}
list.add(post);
}
return new AggregatedPageImpl(list, pageable, hits.getTotalHits(), response.getAggregations(), response.getScrollId(), hits.getMaxScore());
}
});
page.get().forEach(System.out::println);
}
}