K8s为什么需要calico? calico 原理深入理解.
文章目录
- 为什么需要calico?
-
- -网络插件”千千万”,为何k8s要用calico
-
- calico的架构
- calico Pod 跨node通信
- tunl0 的作用?
- 为什么所有pod的默认网关都是`169.254.1.1` ?
- 什么是ARP 代理?
- jksj BGP模式的calico工作原理
- calico BGP 模式的限制
- Calico 的IPIP 模式解决了什么问题?
- jksj IPIP模式的calico工作原理
- IPIP封包模式
- IPIP网络模型
- 模拟 calico 数据流向图
- 在calico眼里节点是什么角色?
- calico 的Node-to-Node Mesh 模式和Route Reflector 的模式区别与使用场景?
- ipvs 模式下主机上的kube-ipvs0设备是什么?
- Calico 日志如何查看?
- calico的运行模式是什么?如何确定?
- calico Node A 的POD ping Node B的POD
- 容器世界的veth pari性能损耗
-
- 参考
为什么需要calico?
Status: Not Started
Tags: 网络, 面试
-网络插件”千千万”,为何k8s要用calico
Calico作为容器网络方案和我们前面介绍的那些方案最大的不同是它没有采用overlay网络做报文的转发,而是提供了纯3层的网络模型.
三层通信模型表示每个容器都通过IP直接通信,中间通过路由转发找到对方。在这个过程中,容器所在的节点类似于传统的路由器,提供了路由查找的功能。要想路由能够正常工作,每个容器所在的主机节点扮演了虚拟路由器(vRouter)的功能,而且这些vRouter必须有某种方法,能够知道整个集群的路由信息。(必须开启内核ip forward )
Calico是一个基于BGP的纯三层的数据中心网络方案(也支持overlay网络),并且与Kubernetes、OpenStack、AWS、GCE等IaaS和容器平台有良好的集成。
Calico的设计比较新颖,*之前提到flannel的host-gw模式之所以不能跨二层网络,是因为它只能修改主机的路由,Calico把改路由表的做法换成了标准的BGP路由协议。*相当于在每个节点上模拟出一个额外的路由器,由于采用的是标准协议,Calico模拟路由器的路由表信息可以被传播到网络的其他路由设备中,这样就实现了在三层网络上的高速跨节点网络。
calico的架构
Calico组件主要架构由Felix、Confd、BIRD组成:
- Felix是负责Calico Node运行并作为每个节点Endpoint端点的守护程序,它负责管理当前主机中的Pod信息,与集群etcd服务交换集群Pod信息,并组合路由信息和ACL策略。
- Confd是负责存储集群etcd生成的Calico配置信息,提供给BIRD层运行时使用。
- **BIRD(BIRD Internet Routing Daemon)是核心组件,**Calico中的BIRD特指BIRD Client和BIRD Route Reflector,负责主动读取Felix在本机上设置的路由信息,并通过BGP广播协议在数据中心中进行分发路由。
calico Pod 跨node通信

1、 ping 数据包从pod1从容器的eth0发出后,发现目标ip不是一个子网,所以直接走网关出去
2、pod 的网关是169.254.1.1
3、对网关IP发起ARP请求,谁是169.254.1.1?mac地址是?发现是一个全E的MAC地址
[root@node2 ~]#arping 169.254.1.1
ARPING 169.254.1.1 from 10.244.104.5 eth0
Unicast reply from 169.254.1.1 [EE:EE:EE:EE:EE:EE] 0.540ms
Unicast reply from 169.254.1.1 [EE:EE:EE:EE:EE:EE] 0.550ms
Unicast reply from 169.254.1.1 [EE:EE:EE:EE:EE:EE] 0.540ms
4、node1的 veth pari 端calixxx收到 这个ARP 请求。通过开启网卡的代理 ARP 功能直接把自己的 MAC 地址返回给 pod1。
pod1中的mac 和calixx的mac都是全e,通过在宿主机上查询ARP表得知需要转达到哪个calixxx
可以看下面的抓包数据。
5、pod1 发送目的地址为pod2的IP 数据包(1-4主要是构造二层包)
6、不在一个子网,本地无法处理,数据包查找本地路由表,匹配到如下路由表:
10.244.136.0/26 via 10.50.10.33 dev tunl0 proto bird onlink
经过tunl0封包之后转发到10.50.10.33 也就是master3
此时IP数据报中Inner IP Header的IP:10.244.166.179 --> 10.244.136.13, OuterIP Header:10.50.10.34 → 10.50.10.33
7、tunl0收到数据包之后会按照ipip协议规范对进来的IP数据包封装一层外层IP头,外层IP的目的ip地址根据6步骤中的路由设置目的ip为网关10.50.10.33,外层IP的源ip地址为本node的ip 10.50.10.34。此时IP数据报变为:
Outer IP Header的IP:10.50.10.34 --> 10.50.10.33;
Inner IP Header的IP:10.244.166.179 --> 10.244.136.13。
tunl0把接收到的数据包封装成ipip报文直接发给tcp/ip协议栈。
8、tcp/ip协议栈根据ipip报文的目的地址和系统路由表(如果在一个子网就不需要),知道目的地址为10.50.10.33的数据报需要通过node master3 的eth0发送。
这一步对我的环境来说只直接二层转发因为是在同一个子网,不需要route
9、数据最终到达master3上的路由
10.244.136.13 dev cali3461c4b49f0 scope link
8、此时消息转发到了master3的veth pair calixxx端的设备,这个设备和容器另外一段的veth pair进行通信

容器内部的arp表
arp -a
gateway (169.254.1.1) at ee:ee:ee:ee:ee:ee [ether] on eth0
tunl0 的作用?
bird的主要作用是生成路由表,通过路由表将数据转发到tunl0设备
TUN 设备是一种工作在三层(Network Layer)的虚拟网络设备。TUN 设备的功能非常简单,即:在操作系统内核和用户应用程序之间传递 IP 包。
Calico 使用的这个 tunl0 设备,是一个 IP 隧道(IP tunnel)设备。
IP 包进入 IP 隧道设备之后,就会被 Linux 内核的 IPIP 驱动接管。IPIP 驱动会将这个 IP 包直接封装在一个宿主机网络的 IP 包中
calico在使用ipip模式之后,每个node上会自动添加一个tunl0网卡,用于IPIP协议的支持。
这个设备的作用就是解封包
node1上的tunl0设备
ip -d link show tunl0
5: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0 promiscuity 0
ipip remote any local any ttl inherit nopmtudisc addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
master3上的tunl0设备
ip -d link show tunl0
2: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0 promiscuity 0
ipip remote any local any ttl inherit nopmtudisc addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
pod内部的流量就会引导到特殊的网关169.254.1.1,从而引流到主机的 tunl0网络设备上,最终将二三层流量全部转换成三层流量来转发
宿主机开启了ip_forward,因此可以在主机中通过路由表,将二层的流程转换成三层流量发送到其它主机上
同时,在主机上通过开启 代理 ARP 功能 来实现 ARP 应答,使得 ARP 广播被抑制在主机上,抑制了广播风暴,也不会有 ARP 表膨胀的问题。
为什么所有pod的默认网关都是169.254.1.1 ?
这个 MAC 地址应该是 Calico 硬塞进去的,而且还能响应 ARP。
# nsenter -n -t 17717 这一步是通过docker inspect获取到pod的ip,然后使用nsenter命令进入pod的network namespace
[root@node2 ~]#
[root@node2 ~]#ip r
default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link
[root@node2 ~]#ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
4: eth0@if16: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP group default
link/ether 1a:de:a2:53:ea:e4 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.244.104.5/32 scope global eth0
valid_lft forever preferred_lft forever
[root@node2 ~]#arping 169.254.1.1
ARPING 169.254.1.1 from 10.244.104.5 eth0
Unicast reply from 169.254.1.1 [EE:EE:EE:EE:EE:EE] 0.560ms
Unicast reply from 169.254.1.1 [EE:EE:EE:EE:EE:EE] 0.545ms
Unicast reply from 169.254.1.1 [EE:EE:EE:EE:EE:EE] 0.548ms
Unicast reply from 169.254.1.1 [EE:EE:EE:EE:EE:EE] 0.560ms
什么是ARP 代理?
当arp请求目标网段的时候,网关收到ARP请求之后会用自己的MAC地址返回给请求者。k8中arp代理功能在calixxx 所在宿主机上开启.

一般的三层数据报文:
SRCIP DESTIP SRCMAC DESTMAC
这里destmac不适用目标pod ip对应的mac而是使用网关的mac
linux下这个参数控制器开启
cat /proc/sys/net/ipv4/conf/calid9939bd081c/proxy_arp
1
- Calico 通过一个巧妙的方法将 workload 的所有流量引导到一个特殊的网关 169.254.1.1,从而引流到主机的 calixxx 网络设备上,最终将二三层流量全部转换成三层流量来转发。
- 在主机上通过开启代理 ARP 功能来实现 ARP 应答,使得 ARP 广播被抑制在主机上,抑制了广播风暴,也不会有 ARP 表膨胀的问题。
jksj BGP模式的calico工作原理

calico BGP 模式的限制
BGP模式和flannel 的host-gateway模式类似需要保证集群node几点的二层互通,即再一个子网中。
如果node1的ip是 192.168.1.2
node2的ip是 192.168.2.2
两个node不在一个子网中。
如果此时container1访问container4.
Calico会在node1的宿主机上添加如下一条route
10.233.2.0/16 via 192.168.2.2 eth0
上面这条规则里的下一跳地址是 192.168.2.2,可是它对应的 Node 2 跟 Node 1 却根本不在一个子网里,没办法通过二层网络把 IP 包发送到下一跳地址。
此时就是IPIP模式登场了
Calico 的IPIP 模式解决了什么问题?
这也是目前我的环境CNI的工作方式,从Calico 3.x开始,默认配置使用的是IPIP模式这种Overlay的传输方案而非BGP。
上面calico BGP 模式的限制中通道的node1上的那条路由信息,在IPIP模式时候是这样的
10.233.2.0/16 via 192.168.2.2 dev tunl0 proto bird onlin
下一跳还是node2的ip但是网络设备变成了tunl0
jksj IPIP模式的calico工作原理

IPIP封包模式
OuterIP 是node1 -》 master3
IP Header是 pod1 -》 pod2

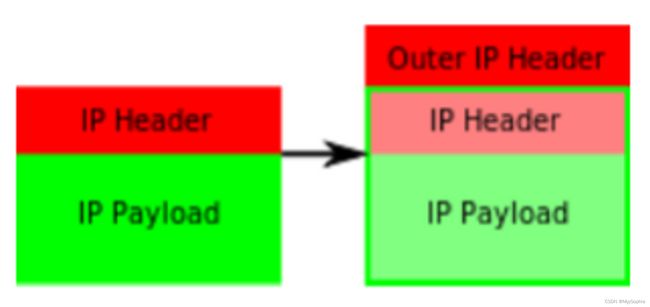
IPIP网络模型
tunl0是linux支持的隧道设备接口,当有这个接口时,出这个主机的IP包就会本封装成IPIP报文。同样的,当有数据进来时也会通过该接口解封IPIP报文。

模拟 calico 数据流向图
图中的tap设备veth pair宿主机端的设备,另一端就是pod中veth1设备
如下图
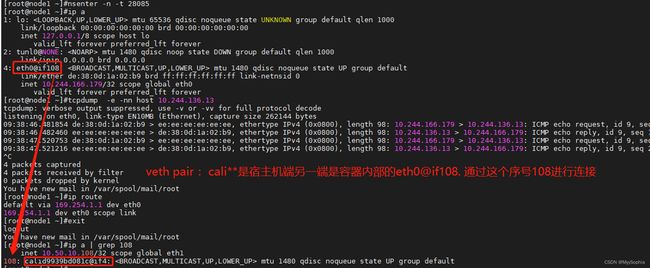
其中cali的mac是全e.
![]()
在calico眼里节点是什么角色?
Calico 项目实际上将集群里的所有节点,都当作是边界路由器来处理,它们一起组成了一个全连通的网络,互相之间通过 BGP 协议交换路由规则。这些节点,我们称为 BGP Peer。
calico 的Node-to-Node Mesh 模式和Route Reflector 的模式区别与使用场景?
前者每台宿主机上的 BGP Client 都需要跟其他所有节点的 BGP Client 进行通信以便交换路由信息。但是,随着节点数量 N 的增加,这些连接的数量就会以 N²的规模快速增长,从而给集群本身的网络带来巨大的压力。推荐少于 100 个节点的集群里
Route Reflector 的模式 时Calico 会指定一个或者几个专门的节点,来负责跟所有节点建立 BGP 连接从而学习到全局的路由规则。而其他节点,只需要跟这几个专门的节点交换路由信息,就可以获得整个集群的路由规则信息了。大规模集群推荐使用, kubeasz安装支持该模式
ipvs 模式下主机上的kube-ipvs0设备是什么?
kube-proxy首先会创建一个dummy虚拟网卡kube-ipvs0,然后把所有的Service IP添加到kube-ipvs0中。正式因为这个虚拟设备的存在ping svcIP 才有回应。如果是iptables mode svcip ping不通,因为没有设备响应。
Calico 日志如何查看?
calico一般是以daemonset的形式存在,可以进入到容器中。calico 的log在
/var/log/calico/cnicni.log
calico的运行模式是什么?如何确定?
进入到容器中,calico中用环境变量CALICO_IPV4POOL_IPIP来标识是否开启IPinIP Mode. 如果该变量的值为Always那么就是开启IPIP,如果关闭需要设置为Never。
$ k exec -it calico-node-9twcw -n kube-system -- bash
Defaulted container "calico-node" out of: calico-node, upgrade-ipam (init), install-cni (init), flexvol-driver (init)
[root@master2 /]#
[root@master2 /]#
[root@master2 /]# env
....
CALICO_IPV4POOL_IPIP=Always
calico Node A 的POD ping Node B的POD
tcpdump 抓包
- -n
- -e 输出链路层数据
- -i 网络接口
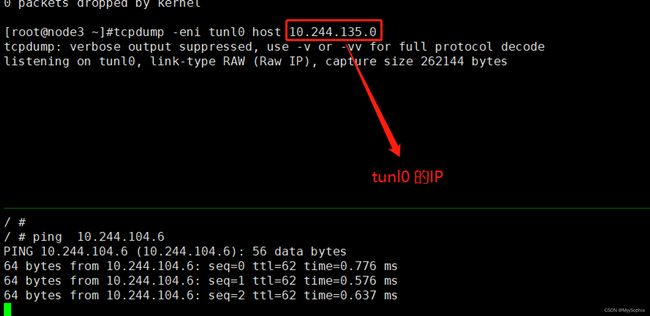
疑问为何要在宿主机上的eth1抓包呢?在主机上抓取POD IP能抓到吗?在tunl0上能抓到吗?
在pod内部可以抓到吗?
node A上的抓包

Node A上POD的抓包
POD 内部抓包看不到IPIP 的封包,pod内部就好像有个隧道和另外一个pod直连。其实tunl0做了很多事情。

再深刻理解下这个图:

Node A 的tunl0 抓包
抓不到包
容器世界的veth pari性能损耗
容器使用的网络技术中基本都是通过veth-pair把容器和外界连通起来的,然后外面或者通过直接路由(BGP)或者通过overlay(vxlan、IPinIP等)的方式再出宿主机。
而仅仅veth-pair就会造成10%的网络延迟(QPS大约减少5%),这是因为虽然 veth 是一个虚拟的网络接口,但是在接收数据包的操作上,这个虚拟接口和真实的网路接口并没有太大的区别。这里除了没有硬件中断的处理,其他操作都差不多,特别是软中断(softirq)的处理部分其实就和真实的网络接口是一样的.**在对外发送数据的时候,peer veth 接口都会 raise softirq 来完成一次收包操作,这样就会带来数据包处理的额外开销。**如果要减小容器网络延时,就可以给容器配置 ipvlan/macvlan 的网络接口来替代 veth 网络接口。Ipvlan/macvlan 直接在物理网络接口上虚拟出接口,在发送对外数据包的时候可以直接通过物理接口完成,没有节点内部类似 veth 的那种 softirq 的开销。**容器使用 ipvlan/maclan 的网络接口,它的网络延时可以非常接近物理网络接口的延时。**对于延时敏感的应用程序,我们可以考虑使用 ipvlan/macvlan 网络接口的容器。不过,由于 ipvlan/macvlan 网络接口直接挂载在物理网络接口上,对于需要使用 iptables 规则的容器,比如 Kubernetes 里使用 service 的容器,就不能工作了。这就需要你结合实际应用的需求做个判断,再选择合适的方案。
参考
http://www.asznl.com/post/83
Calico 网络通信原理揭秘
**calico ipip协议**
Route Reflector 的模式 calico Router reflection(RR) 模式介绍及部署 – 云原生实验室 - Kubernetes|Docker|Istio|Envoy|Hugo|Golang|云原生 (icloudnative.io)
**calico架构**
calico 深入理解