云原生监控——VictoriaMetrics
1.简介
VictoriaMetrics是一个快速高效且可扩展的监控解决方案和时序数据库,可以作为Prometheus的长期远端存储,具备的特性有:
- 支持prometheus查询api,同时实现了一个metricsql 查询语言
- 支持全局查询视图,支持多prometheus 实例写数据到VictoriaMetrics,然后提供一个统一的查询
- 支持集群
- 高性能
- 支持多种协议,包括influxdb line协议,prometheus metrics,graphite ,prometheus远端写api,opentsdb http协议等
- 高压缩比
2.整体架构
VictoriaMetrics的集群主要由vmstorage、vminsert、vmselect等三部分组成,其中,vmstorage 负责提供数据存储服务; vminsert 是数据存储 vmstorage 的代理,使用一致性hash算法进行写入分片; vmselect 负责数据查询,根据输入的查询条件从 vmstorage 中查询数据。
VictoriaMetrics的这个三个组件每个组件都可以单独进行扩展,并运行在大多数合适软件上。vmstorage采用shared-nothing架构,优点是 vmstorage的节点相互之间无感知,相互之间无需通信,不共享任何数据,增加了集群的可用性、简化了集群的运维和集群的扩展。
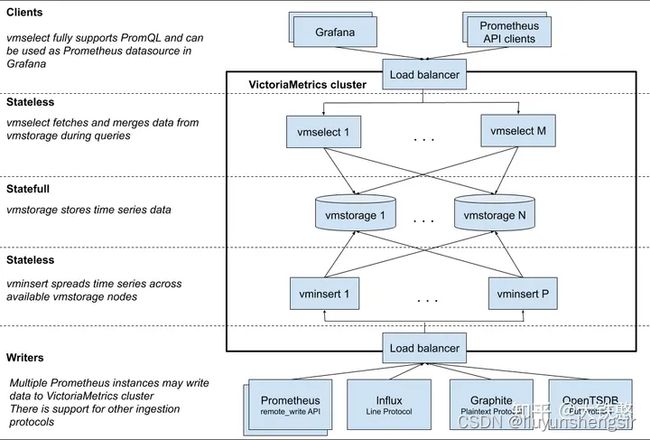
2.1 VictoriaMetrics 集群由以下服务组成:
-
vmstorage,存储原始数据并返回给定标签过滤器的给定时间范围内的查询数据;
-
vminsert,接受接收的数据,并根据 “度量名称及其所有标签” 计算出的哈希值,在 vmstorage 节点之间传播数据;
-
vmselect,通过从所有配置的 vmstorage 节点获取所需数据来执行传入查询。
每个服务可以独立扩展,并且可以在最合适的硬件上运行。Vmstorage 节点不了解彼此,不相互通信,也不共享任何数据。这是一个无共享架构,它提高了群集可用性,简化了群集维护和群集扩展。
2.2 VictoriaMetrics 在开源层面,提供以下组件:
-
vmui:负责 vm 页面展示,提供数据查询、指标与基数查询、查询分析、链路分析、job 分析面板等功能;
-
vmagent:负责数据采集、重新标记和过滤收集,并通过 Prometheus 协议将数据存储到 VictoriaMetrics 或其他支持 Prometheus 协议的存储系统中。支持按时间和标签聚合样本后同时复制多个远程存储系统,且能在传输故障时缓存数据,等待恢复后继续传输;支持抓取暴露数百万时间序列的目标与写入多个租户中;支持 kafka 读写;
-
vminsert:负责数据插入,支持不同格式、不同租户的数据;
-
vmstorage:负责数据存储,具有高压缩率、低资源消耗、高性能的特点;
-
vmselect:负责数据查询,支持数据统一查询与多租户数据隔离查询;
-
vmalert:负责告警,和 Prometheus 一样支持纪录、告警两种规则配置与发送告警通知,允许在注解中使用 Go 模板来格式化数据、迭代或执行表达式,支持跨租户发送警报和记录规则
-
vmbackup:负责数据备份,支持增量备份和全量备份,可以做到每小时、每天、每周和每月备份,支持本地存储、GCS、Azure Blob 存储、S3 存储、任何与 S3 兼容的存储;
-
vmrestore:负责数据还原,支持随时中断与自动从断点恢复。
3.能力
3.1. 保存
VictoriaMetrics 使用 “-retentionPeriod”命令行标志进行配置,该标志采用一个数字,后跟一个时间单位字符 “-h(ours)、d(ays)、w(eeks)、y(ears)”。如果未指定时间单位,则假定为月。例如,“-retentionPeriod=3” 表示数据将存储 3 个月,然后删除。默认保留期为一个月。
3.2. 数据删除
VictoriaMetrics 除了支持配置定时过期外,还支持手动进行数据删除操作,使用 “http://:8428/api/v1/admin/tsdb/delete_series?match[]=
3.3. 强制合并
VictoriaMetrics 会在后台以每个月为一个分区的形式进行数据压缩,以保持良好的性能。可以使用 “http://victoriametrics:8428/internal/force_merge?partition_prefix=YYYY_MM” 进行强制数据压缩,会以异步的形式,立马返回请求结果,并在后台执行数据压缩任务。当需要立即删除数据的时候,可以使用强制合并触发数据删除。
3.4. 数据导入、导出
VictoriaMetrics 支持使用专属 Agent 接口导入数据:
1.Prometheus remote_write API
2.DataDog submit metrics API
3.Graphite plaintext protocol
4.OpenTSDB telnet put protocol
5.OpenTSDB http api/put protocol
支持使用 VictoriaMetrics 统一接口导入数据:
1./api/v1/import,导出 json 格式;
2./api/v1/import/csv,导出 csv 格式;
3./api/v1/import/native,导出二进制格式。
相对的,也可以使用导出接口导出数据:
1./api/v1/export,导出 json 格式;
2./api/v1/export/csv,导出 csv 格式;
3./api/v1/export/native,导出二进制格式。
VictoriaMetrics 接口侧,在导入、导出接口中,数据格式保持一致,可以直接使用导出的数据进行数据导入。
3.5. 消除重复数据
VictoriaMetrics 会根据 “-dedup.minScrapeInterval” 配置的值进行去重,只留下一个原始样本,保留配置周期中时间戳最大的数据。比如 “-dedup.minScrapeInterval=60s”,将会保留 60s 间隔中最大时间戳的单个原始样本。如果时间戳一致的情况下,随机保留数据。
多个相同配置的 vmagent 或 Prometheus 实例将数据写入同一 VictoriaMetrics 实例,则消除重复数据可减少磁盘空间的使用。
3.6. 存储
VictoriaMetrics 将以类似 MergeTree 的数据结构存储时间序列数据。插入时,VictoriaMetrics 累积最多 1s 的数据,并将其转储到磁盘上的 “←storageDataPath>/data/small/YYYY_MM/” 子目录,形成具有以下名称模式的 part:“rowsCount_blocksCount_minTimestamp_maxTimestamp”。每个 part 由两个 “列” 组成:值和时间戳。这些是经过排序和压缩的原始时间序列值。此外,part 包含索引文件,用于在值和时间戳文件中搜索特定 series。
part 会定期合并为较大的 part,生成的部分在 “<-storageDataPath>/data/{small,big}/YYYY_MM/tmp” 子目录下构造。当生成的 part 完成后,它将自动从 tmp 移动到自己的子目录,而源部分将自动删除。最终结果是,源部分被 ”<-storageDataPath>/data/{small,big}/YYYY_MM/“ 目录中的单个较大部分替换。
如果 part 的摘要大小超过可用磁盘空间,VictoriaMetrics 不会合并部件。这可以防止合并过程中出现潜在的磁盘空间不足错误。在可用磁盘空间不足的情况下,part 的数量可能会随着时间的推移而显著增加。这增加了数据查询期间的开销,因为 VictoriaMetrics 每次请求都需要从更多的部分读取数据。这就是为什么建议在 “-storageDataPath” 命令行标志指示的目录下至少有 20% 的可用磁盘空间。
有关合并过程的信息支持在 Grafana 仪表板中查看。
合并过程提高了压缩率,并使磁盘上的部件数量保持相对较低。执行合并过程的好处如下:
-
它提高了查询性能,因为每次查询都会检查较少的部分;
-
它减少了数据文件的数量,因为每个部分都包含固定数量的文件。
存储或是合并,都不会只保存部分 part,part 会以数据整体的形式,要么被全部保存成功,要么全部失败。part 是不可变的。
3.7. 监控
VictoriaMetrics 在 “/metrics” 页面以 Prometheus exposion 格式导出内部度量。这些指标可以通过 vmagent 或 Prometheus 获取。或者,当 “-selfScrapeInterval” 命令行标志设置为持续时间大于 0 时,单节点 VictoriaMetrics 可以自抓取度量。
VictoriaMetrics 在 “/api/v1/status/active_queries“ 页面上公开当前正在运行的查询及其执行时间。
VictoriaMetrics 在 ”/api/v1/status/top_queries” 页面上公开了执行时间最长的查询。
3.8. TSDB 状态
VictoriaMetrics 以类似于 Prometheus 的方式在 “/api/v1/status/TSDB“ 页面返回 TSDB 统计信息:
-
topN=N,其中 N 是响应数量。默认情况下,返回前 10 个;
-
date=YYYY-MM-DD,其中 YYYY-MM-DD 是收集统计数据的日期。默认情况下,收集当天的统计数据;
-
focusLabel=LABEL_NAME,返回 seriesCountByFocusLabelValue 列表中给定 LABEL_NAME 的时间序列数最多的标签值;
-
match[]=SELECTOR,其中 SELECTOR 是一个任意时间序列选择器,用于在统计计算期间考虑序列。默认情况下,将考虑所有系列;
-
extra_label=LABEL=VALUE,拓展标签筛选。
3.9. 推指标
当出现无法拉取指标的场景下,VictoriaMetrics 支持以 Prometheus 数据格式的方式,通过 push 模式进行指标推送:
-
-pushmetrics.url,推送地址,比如”-pushmetrics.url=http://victoria-metrics:8428/api/v1/import/prometheus“;
-
-pushmetrics.extraLabel,拓展标签,支持以 label=“value” 的形式给 push 数据增加标签;
-
-pushmetrics.interval,push 周期,默认 10s。
3.10. 缓存
VictoriaMetrics 使用各种内部缓存。在正常关机期间(例如,当 VictoriaMetrics 通过发送 SIGINT 信号停止时),这些缓存存储到 “<-storageDataPath>/cache” 目录中。缓存将在下次 VictoriaMetrics 启动时读取。有时需要在下次启动时删除这些缓存。这可以通过在重启 VictoriaMetrics 之前将 reset_cache_on_startup 文件放置在“<-storageDataPath>/cache” 目录中来执行。
VictoriaMetrics 使用各种内存缓存来加快数据摄取和查询性能。每种类型缓存指标可以在 “/metrics” 页面导出:
-
vm_cache_size_bytes,实际缓存大小;
-
vm_cache_size_max_bytes,缓存大小限制;
-
vm_cache_requests_total,对缓存的请求数;
-
vm_cache_misses_total,缓存未命中数;
-
vm_cache_entries,缓存中的条目数。
支持在 Grafana 仪表板上查看缓存指标,面板显示了每种类型缓存的当前内存使用情况,以及缓存命中率。如果命中率接近 100%,则缓存效率已经很高,不需要任何调整。
3.11. 其他
支持众多 Prometheus 具备的功能,比如 Prometheus 的标签重写、联邦等功能。
4. Prometheus 对比
优势:
-
性能优势。在相同配置、采集压力的情况下,相比使用 Prometheus,存储空间最多可减少 7 倍,磁盘读写峰值最多可减少 3-4 倍,内存使用最多减少 7 倍;
-
更优秀的横向拓展、高可用方案。VictoriaMetrics 集群模式,通过组件化各个能力,进行功能层面的架构解耦。由于负责读写的 vmselect、vminsert 组件都是无状态组件,可以灵活根据读写压力,进行组件的横向扩缩容;负责存储的 vmstorage 组件虽然是有状态组件,但是当存储压力增加时,同样支持横向扩容,扩容后只需要更新上下游的 vmselect、vminsert 组件配置并重启,即可提升 VictoriaMetrics 集群存储能力;采集压力的时候,可以利用扩容 vmagent 与 vmagent 的采集分组能力,进行分散压力采集;
-
数据多租户能力。VictoriaMetrics 支持把不同类型的数据分别放到不同的租户里,每个租户通过 accountID 或 accountID:projectID 的形式,在请求的 url 里做区分。租户的数量不影响性能,主要取决于所有租户的活跃总时间序列,每个租户的数据都均匀分布在后端 vmstorage 存储,但是不支持跨租户进行数据查询。
缺点:
-
没有类似 Prometheus 的 WAL 日志,突然故障可能会丢失部分数据。Prometheus 在接收到数据的时候,会先把数据写入内存,定期再写入磁盘。为了防止写入磁盘前数据丢失,还会再写入内存的同时简单的写入 WAL 文件里,当出现故障时,就可以通过 WAL 快速恢复当前状态。而 VictoriaMetrics 则在写入过程中,使用 Go 的 chan 作为数据缓存队列,多协程实现数据处理、压缩、存储等操作,故障下存在缓存数据丢失的情况;
-
为了更大程度优化存储,会选择丢失部分数据精度。Vmstorage 组件支持配置精度保存范围(1-64,64 表示不丢失),以此在数据读写过程中,提升速度。
5.安装
使用 helm 进行 VictoriaMetrics 集群模式的部署。
安装 helm,添加 chart helm 仓库:
helm repo add vm https://victoriametrics.github.io/helm-charts/
helm repo update
导出配置文件,并进行部署配置:
helm show values vm/victoria-metrics-cluster > values.yaml
可以使用以下命令进行配置检查:
helm install victoria-metrics vm/victoria-metrics-cluster -f values.yaml -n victoria-metrics --debug --dry-run
根据配置文件部署 victoria-metrics-cluster:
helm install victoria-metrics vm/victoria-metrics-cluster -f values.yaml -n victoria-metrics
6.使用
调整 victoria-metrics-victoria-metrics-cluster-vminsert 的 service 与 victoria-metrics-victoria-metrics-cluster-vmselect 的 service,从 ClusterIP 模式改成 NodePort 模式,提供对外访问能力。修改现有 Prometheus 的配置,增加:
remote_write:
- url: http://cluster-vminsert:8480/insert/0/prometheus/api/v1/write
queue_config:
max_samples_per_send: 10000
capacity: 20000
max_shards: 30
把 Prometheus 的数据,写入 VictoriaMetrics,通过 VictoriaMetrics 的 UI 地址 ”http://IP:NodePort/select/0/vmui“,即可查看 Prometheus 采集到的数据了。

https://zhuanlan.zhihu.com/p/368912946
https://docs.victoriametrics.com/