用Python的requests库实现自动上传文件
女朋友下班后听她吐槽自己领导安排了一件又要让她加班的工作。大致任务是:在公司网址上为近10万客户上传签订的合同的基础信息并上传对应的资料附件。月底前必须完成,人工一天才传了1000左右,按这个节奏根本完不成。
为了不让她加班,这边写了一个小脚本来实现自动上传。
思路:抓取对应上传资料接口,分析出接口入参,通过读取Excel里的数据,用Python的requests库来调用接口传入实现。
准备工作
- 需安装Python的requests、xlrd库
pip install requests
pip install xlrd==1.2.0 # xlrd2.0.1版本以后不支持.xlsx格式
- 附件和客户资料汇总文档(已有,只需按接口上传格式整理下即可)
一、整理接口文档(F12或fiddler工具)
1.使用F12开发者工具或者fiddler工具(fiddler使用教程)抓取接口的URL、请求头、入参、出参
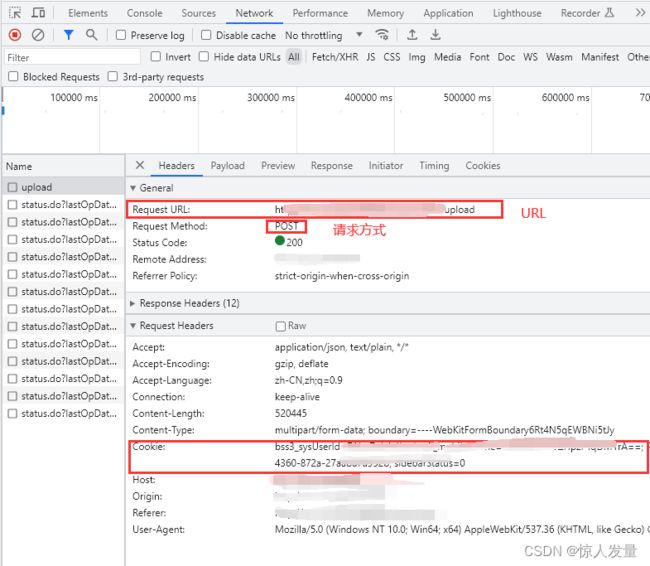
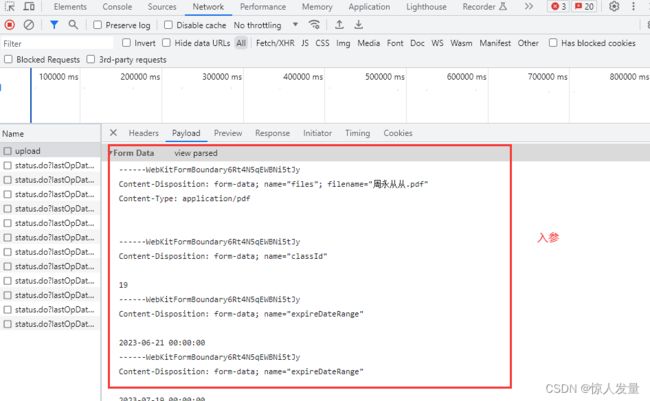
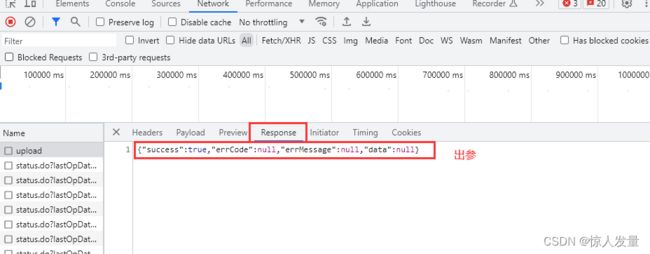
2.根据抓取的接口信息把需上传的信息整理成对应文档格式

二、编写脚本
1. 通过xlrd读取Excel
读取Excel数据,以标题作为字典的key,按每行数据拼接出入参数据,
返回格式[{“a”:“a值”,…},{“a”:“a值”,…},…]方便后续传参读取。
def get_data(self, file):
"""
读取Excel数据,以标题作为字典的key,按每行数据拼接出入参数据,
返回格式[{"a":"a值",....},{"a":"a值",....},....]
:param file: 文档
:return: [{"a":"a值",....},{"a":"a值",....},....]
"""
e = xlrd.open_workbook(file)
sheet = e.sheet_by_index(0)
lists = []
key = sheet.row_values(0)
for i in range(1, sheet.nrows):
value = sheet.row_values(i)
dic = {}
for j in range(sheet.ncols):
dic[key[j]] = value[j]
lists.append(dic)
return lists
2.读取Excel数据的附件名,判断对应路径是否存在对应附件。
判断是否对应附件存在,存在就返回:实际附件路径和附件名,否则返回:null
def get_file(self, files, path):
"""
通过附件名查看是否附件存在
:param files: 附件名
:param path: 附件存放路径
:return: 附件路径dirpath, 附件名flie_name
"""
dirpath, flie_name = '', ''
for dirpath, dirs, filenames in os.walk(path):
for v in range(len(filenames)):
if filenames[v].find(files) != -1:
flie_name = filenames[v]
break
else:
flie_name = 'null'
return dirpath, flie_name
3.编写调用上传接口
循环获取Excel文档里的参数,作为请求入参的data,读取附件内容并上传。
注意点:
①附件格式传入对应类型是不同的:jpg、jpeg、pdf、doc、docx、zip、rar
②如果接口需要cookie的获取、cookie有效期
if ext == '.jpg':
file_type = 'image/jpeg'
elif ext == '.jpeg':
file_type = 'image/jpeg'
elif ext == '.pdf':
file_type = 'application/pdf'
elif ext == '.doc':
file_type = 'application/msword'
elif ext == '.docx':
file_type = 'application/vnd.openxmlformats-officedocument.wordprocessingml.document'
elif ext == '.zip':
file_type = 'application/x-zip-compressed'
elif ext == '.rar':
file_type = 'application/octet-stream'
循环执行上传,最后判断下接口结果,并记录日志
def execute_api(self, url, file, path, cookie):
"""
通过requests调用API上传附件和对应信息
:param url: 接口地址
:param file: 汇总文件名
:param path: 资料附件存放路径
:param cookie: 有效的cookie
:return:
"""
lists = self.get_data(file)
for datas in lists:
custCode = datas['custCode']
files = datas['files']
del datas['files']
datas.update()
datas['classId'] = '19'
datas['sendSms'] = 'false'
datas['profileSource'] = '1'
dirpath, file_name = self.get_file(files, path)
results = ''
if file_name != 'null':
ext = os.path.splitext(file_name)[1]
if ext == '.jpg':
file_type = 'image/jpeg'
elif ext == '.jpeg':
file_type = 'image/jpeg'
elif ext == '.pdf':
file_type = 'application/pdf'
elif ext == '.doc':
file_type = 'application/msword'
elif ext == '.docx':
file_type = 'application/vnd.openxmlformats-officedocument.wordprocessingml.document'
elif ext == '.zip':
file_type = 'application/x-zip-compressed'
elif ext == '.rar':
file_type = 'application/octet-stream'
else:
file_type = ''
file_path = dirpath + file_name
headers = {
'Cookie': cookie}
result = self.s.post(url=url, data=datas, files={
"files": (file_name, open(file_path, "rb"), file_type)},
headers=headers)
results = result.text
else:
results = "文件不存在"
with open('err_log.txt', 'a', encoding='utf-8') as f:
f.write(f'{custCode}' + ',' + results + '\n')
ex = '"success":true'
if ex in results:
r = f'{custCode}:上传成功'
else:
r = f'{custCode}:上传失败'
print(r + ',' + results)
with open('log.txt', 'a', encoding='utf-8') as f:
f.write(r + '\n')
全部源码代码
# -*- coding: utf-8 -*-
import os
import requests
import xlrd
class Test:
def __init__(self):
self.s = requests.session()
def get_data(self, file):
"""
读取Excel数据,以标题作为字典的key,按每行数据拼接出入参数据,
返回格式[{"a":"a值",....},{"a":"a值",....},....]
:param file: 文档
:return: [{"a":"a值",....},{"a":"a值",....},....]
"""
e = xlrd.open_workbook(file)
sheet = e.sheet_by_index(0)
lists = []
key = sheet.row_values(0)
for i in range(1, sheet.nrows):
value = sheet.row_values(i)
dic = {}
for j in range(sheet.ncols):
dic[key[j]] = value[j]
lists.append(dic)
return lists
def get_file(self, files, path):
"""
通过附件名查看是否附件存在
:param files: 附件名
:param path: 附件存放路径
:return: 附件路径dirpath, 附件名flie_name
"""
dirpath, flie_name = '', ''
for dirpath, dirs, filenames in os.walk(path):
for v in range(len(filenames)):
if filenames[v].find(files) != -1:
flie_name = filenames[v]
break
else:
flie_name = 'null'
return dirpath, flie_name
def execute_api(self, url, file, path, cookie):
"""
通过requests调用API上传附件和对应信息
:param url: 接口地址
:param file: 汇总文件名
:param path: 资料附件存放路径
:param cookie: 有效的cookie
:return:
"""
lists = self.get_data(file)
for datas in lists:
custCode = datas['custCode']
files = datas['files']
del datas['files']
datas.update()
datas['classId'] = '19'
datas['sendSms'] = 'false'
datas['profileSource'] = '1'
dirpath, file_name = self.get_file(files, path)
results = ''
if file_name != 'null':
ext = os.path.splitext(file_name)[1]
if ext == '.jpg':
file_type = 'image/jpeg'
elif ext == '.jpeg':
file_type = 'image/jpeg'
elif ext == '.pdf':
file_type = 'application/pdf'
elif ext == '.doc':
file_type = 'application/msword'
elif ext == '.docx':
file_type = 'application/vnd.openxmlformats-officedocument.wordprocessingml.document'
elif ext == '.zip':
file_type = 'application/x-zip-compressed'
elif ext == '.rar':
file_type = 'application/octet-stream'
else:
file_type = ''
file_path = dirpath + file_name
headers = {
'Cookie': cookie}
result = self.s.post(url=url, data=datas, files={
"files": (file_name, open(file_path, "rb"), file_type)},
headers=headers)
results = result.text
else:
results = "文件不存在"
with open('err_log.txt', 'a', encoding='utf-8') as f:
f.write(f'{custCode}' + ',' + results + '\n')
ex = '"success":true'
if ex in results:
r = f'{custCode}:上传成功'
else:
r = f'{custCode}:上传失败'
# print(r + ',' + results)
with open('log.txt', 'a', encoding='utf-8') as f:
f.write(r + '\n')
def write_log(self, r):
"""
记录接口调用日志
:param r:
:return:
"""
with open('log.txt', 'a', encoding='utf-8') as f:
f.write(r + '\n')
if __name__ == '__main__':
t = Test()
# 上传文件接口地址
url = ''
# 合同提供资料汇总文件名
file = '提供资料模板.xlsx'
# 有效的cookie
cookie = ''
# 资料附件存放路径
path = r"D:\Projects\test\files\\"
t.execute_api(url, file, path, cookie)
最后,替换真实的URL、填充模板内容、cookie、附件存放路径,执行脚本,等待执行结束就行啦。