学习mysql
Mysql
- SQL语言的规则与规范
-
- SQL大小写规范
- 注释
- 数据导入指令
- 基本的SELECT语句
-
- SELECT.
- 列的别名
- 去掉重复行
- 空值参与运算
- 着重号(当有表名是关键字时)
- 显示表结构
- where
- 运算符
-
- 算术运算符
- 比较运算
-
- 符号性运算符
- 非符号形运算符
-
- 空运算符
- 非空运算符
- 最小值运算符
- 最大值运算符
- BETWEEN AND运算符
- IN运算符
- LIKE运算符
- 转义代替符
- 正则
- 逻辑运算符
- 排序
- 分页
- 多表查询
-
- 内连接
- 外连接
- UNION的使用
- 日期和时间函数
- 流程处理函数
- 密码加密
- 聚合函数
-
- GROUP BY
- 子查询
-
- EXISTS 与 NOT EXISTS关键字
- 创建和管理
-
- 创建数据库
- 使用数据库
- 修改数据库
- 创建表
-
- 创建方式2
- 修改表
-
- 追加一个列
- 修改一个列
-
- 重命名一个列
- 删除一个列
- 重命名表
- 删除表
- 清空表
- 插入数据
-
- 将查询结果插入到表中
- 更新数据
- 删除数据
SQL语言的规则与规范
SQL大小写规范
字符串型和日期时间类型的数据可以使用单引号(' ')表示
列的别名,尽量使用双引号(" "),而且不建议省略as
注释
可以使用如下格式的注释结构
单行注释:#注释文字(MySQL特有的方式)
单行注释:-- 注释文字(--后面必须包含一个空格。)
多行注释:/* 注释文字 */
数据导入指令
这个代码必须在终端里面执行,在可视化界面执行无效.
具体语法 source 具体路径
mysql> source d:\mysqldb.sql
基本的SELECT语句
SELECT.
SELECT 1; #返回列名为1,数值为1的表
SELECT 9/2; #返回列民4.5,数值为4.5的表
# 查询 departments 里面所有列的数据
SELECT *
FROM departments;
- 选择特定的列:
# 选择显示 department_id ,location_id
SELECT department_id, location_id
FROM departments;
列的别名
- 重命名 可以用
AS也可以用空格 ,如果新名字需要打引号最好打双引号( " ") (oracle里面会报错)
# 给last_name 给一个新的名字name ,commission_pct 新的名字comn
SELECT last_name AS name, commission_pct comm
FROM employees;
去掉重复行
- 利用
DISTINCT(distinct)
# 取除 employee department_id 重复的值
SELECT DISTINCT department_id
FROM employees;
空值参与运算
所有运算符或列值遇到null值,运算的结果都为null
# 这里写一个试试看
SELECT NULL *1; # 返回空的名字为NULL*1 值为null的表
着重号(当有表名是关键字时)
# 当有order 数据表时
mysql> SELECT * FROM ORDER; # 返回错误信息
# 利用着重号 ` `
mysql> SELECT * FROM `ORDER`; # 返回正确
显示表结构
# 显示表的结构
DESCRIBE employees;
或
DESC employees;
where
语法:
SELECT 字段1,字段2
FROM 表名
WHERE 过滤条件
- 只返回满足条件的语句
# 例如只返回department_id 为90 的信息
SELECT employee_id, last_name, job_id, department_id
FROM employees
WHERE department_id = 90 ;
运算符
算术运算符
加+、减-、乘*、除/(DIV)和取模%(MOD)运算
# 加减数字
mysql> SELECT 100, 100 + 0, 100 - 0, 100 + 50, 100 + 50 -30, 100 + 35.5, 100 - 35.5
FROM dual;
+-----+---------+---------+----------+--------------+------------+------------+
| 100 | 100 + 0 | 100 - 0 | 100 + 50 | 100 + 50 -30 | 100 + 35.5 | 100 - 35.5 |
+-----+---------+---------+----------+--------------+------------+------------+
| 100 | 100 | 100 | 150 | 120 | 135.5 | 64.5 |
+-----+---------+---------+----------+--------------+------------+------------+
1 row in set (0.00 sec)
# 乘除数字
+-----+---------+-----------+-----------+---------+-----------------+---------+-------+
| 100 | 100 * 1 | 100 * 1.0 | 100 / 1.0 | 100 / 2 | 100 + 2 * 5 / 2 | 100 /3 | 100 DIV 0|
+-----+---------+-----------+-----------+---------+-----------------+---------+-------+
| 100 | 100 | 100.0 | 100.0000 | 50.0000 | 105.0000 | 33.3333 | NULL |
+-----+---------+-----------+-----------+---------+-----------------+---------+-------+
1 row in set (0.00 sec)
- 模运算
#筛选出employee_id是偶数的员工
SELECT * FROM employees
WHERE employee_id MOD 2 = 0;
比较运算
符号性运算符
就举例几个不常见或易错的(大于小于就不说了)
- 安全等于:
<=>(这个使用与当为空的时候可以利用) - 不等于:
!=或者<> - 等于 :
=(这里不是==)
SELECT 1 = '1'; # 返回是真则为1
# 当有数值等于的时候会吧字符串转换为0
SELECT 0 = 'abc'; # 返回是1
非符号形运算符
空运算符
mysql> SELECT NULL IS NULL, ISNULL(NULL), ISNULL('a'), 1 IS NULL;
+--------------+--------------+-------------+-----------+
| NULL IS NULL | ISNULL(NULL) | ISNULL('a') | 1 IS NULL |
+--------------+--------------+-------------+-----------+
| 1 | 1 | 0 | 0 |
+--------------+--------------+-------------+-----------+
1 row in set (0.00 sec)
#查询commission_pct等于NULL。比较如下的四种写法
SELECT employee_id,commission_pct FROM employees WHERE commission_pct IS NULL;
SELECT employee_id,commission_pct FROM employees WHERE commission_pct <=> NULL;
SELECT employee_id,commission_pct FROM employees WHERE ISNULL(commission_pct);
SELECT employee_id,commission_pct FROM employees WHERE commission_pct = NULL;# 这个是有问题的
非空运算符
IS NOT NULL
mysql> SELECT NULL IS NOT NULL, 'a' IS NOT NULL, 1 IS NOT NULL;
+------------------+-----------------+---------------+
| NULL IS NOT NULL | 'a' IS NOT NULL | 1 IS NOT NULL |
+------------------+-----------------+---------------+
| 0 | 1 | 1 |
+------------------+-----------------+---------------+
1 row in set (0.01 sec)
#cmmission_pct不等于NULL。比较如下的三种写法
SELECT employee_id,commission_pct FROM employees WHERE NOT commission_pct <=> NULL;
SELECT employee_id,commission_pct FROM employees WHERE NOT ISNULL(commission_pct);
SELECT employee_id,commission_pct FROM employees WHERE commission_pct IS NOT NULL;
最小值运算符
LEAST(值1,值2,...,值n)
mysql> SELECT LEAST (1,0,2), LEAST('b','a','c'), LEAST(1,NULL,2);
+---------------+--------------------+-----------------+
| LEAST (1,0,2) | LEAST('b','a','c') | LEAST(1,NULL,2) |
+---------------+--------------------+-----------------+
| 0 | a | NULL |
+---------------+--------------------+-----------------+
1 row in set (0.00 sec)
最大值运算符
GREATEST(值1,值2,...,值n)
mysql> SELECT GREATEST(1,0,2), GREATEST('b','a','c'), GREATEST(1,NULL,2);
+-----------------+-----------------------+--------------------+
| GREATEST(1,0,2) | GREATEST('b','a','c') | GREATEST(1,NULL,2) |
+-----------------+-----------------------+--------------------+
| 2 | c | NULL |
+-----------------+-----------------------+--------------------+
1 row in set (0.00 sec)
BETWEEN AND运算符
在小的num 和大的num 之间
mysql> SELECT 1 BETWEEN 0 AND 1, 10 BETWEEN 11 AND 12, 'b' BETWEEN 'a' AND 'c';
+-------------------+----------------------+-------------------------+
| 1 BETWEEN 0 AND 1 | 10 BETWEEN 11 AND 12 | 'b' BETWEEN 'a' AND 'c' |
+-------------------+----------------------+-------------------------+
| 1 | 0 | 1 |
+-------------------+----------------------+-------------------------+
1 row in set (0.00 sec)
# 查询 工资在2500到3500 之间的员工
SELECT last_name, salary
FROM employees
WHERE salary BETWEEN 2500 AND 3500;
IN运算符
是否在之内
mysql> SELECT 'a' IN ('a','b','c'), 1 IN (2,3), NULL IN ('a','b'), 'a' IN ('a', NULL);
+----------------------+------------+-------------------+--------------------+
| 'a' IN ('a','b','c') | 1 IN (2,3) | NULL IN ('a','b') | 'a' IN ('a', NULL) |
+----------------------+------------+-------------------+--------------------+
| 1 | 0 | NULL | 1 |
+----------------------+------------+-------------------+--------------------+
# 查询 是100,101,201的id
SELECT last_name, salary
FROM employees
WHERE manager_id IN (100, 101, 201);
LIKE运算符
模糊查询
- LIKE运算符通常使用如下通配符:
%:匹配0个或多个字符。
_:只能匹配一个字符。
# 查询first_name 是S开头的
SELECT first_name
FROM employees
WHERE first_name LIKE 'S%';
# 查询第二个字母是o的last_name
SELECT last_name
FROM employees
WHERE last_name LIKE '_o%';
转义代替符
ESCAPE保持原来的含义
其实可以用\ 这个也是转义
SELECT job_id
FROM jobs
WHERE job_id LIKE ‘IT\_%‘;
如果使用\表示转义,要省略ESCAPE。如果不是\,则要加上ESCAPE。
# 这里利用$ 进行转义
SELECT job_id
FROM jobs
WHERE job_id LIKE ‘IT$_%‘ escape ‘$‘;
正则
REGEXP算符
正则在学python时候用过去了解一下
mysql> SELECT 'atguigu' REGEXP 'gu.gu', 'atguigu' REGEXP '[ab]';
+--------------------------+-------------------------+
| 'atguigu' REGEXP 'gu.gu' | 'atguigu' REGEXP '[ab]' |
+--------------------------+-------------------------+
| 1 | 1 |
+--------------------------+-------------------------+
1 row in set (0.00 sec)
逻辑运算符

- 尝试一个and
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary >=10000
AND job_id LIKE '%MAN%';
#查询基本薪资不在9000-12000之间的员工编号和基本薪资
SELECT employee_id,salary FROM employees
WHERE NOT (salary >= 9000 AND salary <= 12000);
SELECT employee_id,salary FROM employees
WHERE salary <9000 OR salary > 12000;
SELECT employee_id,salary FROM employees
WHERE salary NOT BETWEEN 9000 AND 12000;
and 的优先级比or 高
比如 a事件 AND b事件 OR c 事件 AND d 事件
a 和 b 事件先判断 然后是 c 和d 事件 在判断 最后是 此两个事件的or运算
排序
- 单列排序
按照 hire_date 排序
SELECT last_name, job_id, department_id, hire_date
FROM employees
ORDER BY hire_date ;
使用 DESC 降序
SELECT last_name, job_id, department_id, hire_date
FROM employees
ORDER BY hire_date DESC ;
- 多列排序
首先按照department_id 在按照salary排序
SELECT last_name, department_id, salary
FROM employees
ORDER BY department_id, salary DESC;
分页
- 利用limit 来实现分页
--前10条记录:
SELECT * FROM 表名 LIMIT 0,10;
或者
SELECT * FROM 表名 LIMIT 10;
--第11至20条记录:
SELECT * FROM 表名 LIMIT 10,10;
--第21至30条记录:
SELECT * FROM 表名 LIMIT 20,10;
多表查询
#案例:查询员工的姓名及其部门名称
SELECT last_name, department_name
FROM employees, departments
WHERE employees.department_id = departments.department_id;
注意:区分重复的列名
- 多个表中有相同列时,必须在列名之前加上表名前缀。
- 在不同表中具有相同列名的列可以用 表名 加以区分。
SELECT employees.last_name, departments.department_name,employees.department_id
FROM employees, departments
WHERE employees.department_id = departments.department_id;
表的别名
- 使用别名可以简化查询。
- 列名前使用表名前缀可以提高查询效率。
SELECT e.employee_id, e.last_name, e.department_id,
d.department_id, d.location_id
FROM employees e , departments d
WHERE e.department_id = d.department_id;
内连接
SELECT字段列表
FROMA表INNERJOINB表ON关联条件
WHERE等其他子句;
- 例如
SELECT e.employee_id, e.last_name, e.department_id,
d.department_id, d.location_id
FROM employees e JOIN departments d
ON (e.department_id = d.department_id);
外连接
- 语法
#实现查询结果是A
SELECT 字段列表
FROM A表 LEFT JOIN B表
ON 关联条件
WHERE 等其他子句;
- 举例:
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
LEFT OUTER JOIN departments d
ON (e.department_id = d.department_id) ;
RIGHT OUTER JOIN 右外连接
UNION的使用
合并查询结果 利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并
时,两个表对应的列数和数据类型必须相同,并且相互对应。各个SELECT语句之间使用UNION或UNION
ALL关键字分隔。
语法格式:
SELECT column,... FROM table1
UNION [ALL]
SELECT column,... FROM table2


- 举例:查询部门编号>90或邮箱包含a的员工信息
#方式1
SELECT * FROM employees WHERE email LIKE '%a%' OR department_id>90;
#方式2
SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id>90;
- 举例:查询中国用户中男性的信息以及美国用户中年男性的用户信息
SELECT id,cname FROM t_chinamale WHERE csex='男'
UNION ALL
SELECT id,tname FROM t_usmale WHERE tGender='male';
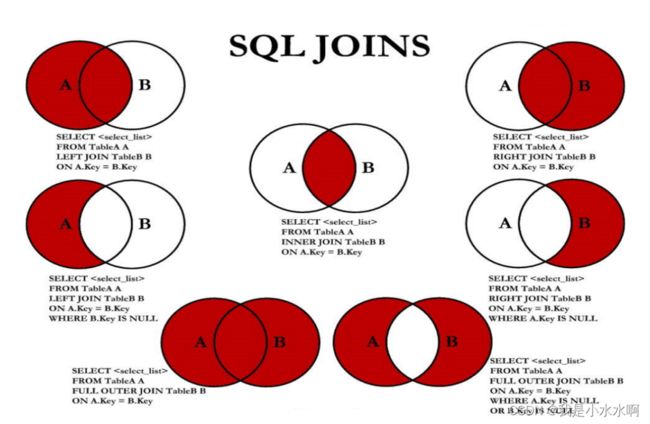
代码实现
#中图:内连接 A∩B
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`;
#左上图:左外连接
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`;
#右上图:右外连接
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
#左中图:A - A∩B
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
#右中图:B-A∩B
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
图:满外连接
# 左中图 + 右上图 A∪B
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL #没有去重操作,效率高
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
#右下图
#左中图 + 右中图 A ∪B- A∩B 或者 (A - A∩B) ∪ (B - A∩B)
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
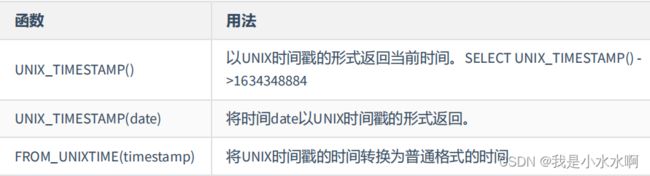
日期和时间函数


流程处理函数
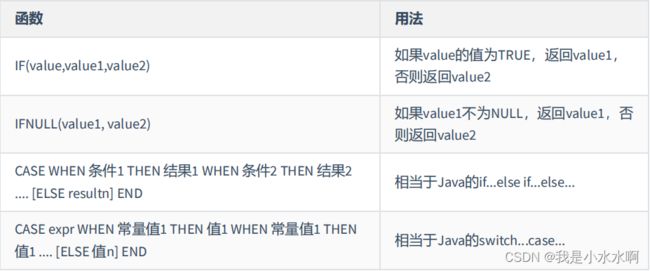
SELECT IF(1 > 0,'正确','错误')
->正确
SELECT IFNULL(null,'Hello Word')
->Hello Word
// 只会保留一个其中一个成立就推出了
SELECT CASE
WHEN 1 > 0
THEN '1 > 0'
WHEN 2 > 0
THEN '2 > 0'
ELSE '3 > 0'
END
->1 > 0
SELECT CASE 1
WHEN 1 THEN '我是1'
WHEN 2 THEN '我是2'
ELSE '你是谁'
// 根据工资获得名称
SELECT employee_id,salary, CASE WHEN salary>=15000 THEN '高薪'
WHEN salary>=10000 THEN '潜力股'
WHEN salary>=8000 THEN '屌丝'
ELSE '草根' END "描述"
FROM employees;
密码加密

聚合函数
聚合函数类型
AVG()
SUM()
MAX()
MIN()
COUNT()
可以对数值型数据使用AVG 和 SUM 函数,可以对任意数据类型的数据使用 MIN 和 MAX 函数。
SELECT AVG(salary), MAX(salary),MIN(salary), SUM(salary)
FROM employees
WHERE job_id LIKE '%REP%';
COUNT(*)返回表中记录总数,适用于任意数据类型。
SELECT COUNT(*)
FROM employees
WHERE department_id = 50;
COUNT(expr) 返回expr不为空的记录总数
用count(*),count(1),count(列名)谁最好
最好用前面两个
GROUP BY
SELECT department_id dept_id, job_id, SUM(salary)
FROM employees
GROUP BY department_id, job_id
HAVING MAX(salary)>10000 ;
子查询

#方式一:
SELECT salary
FROM employees
WHERE last_name = 'Abel';
SELECT last_name,salary
FROM employees
WHERE salary > 11000;
#方式二:自连接
SELECT e2.last_name,e2.salary
FROM employees e1,employees e2
WHERE e1.last_name = 'Abel'
AND e1.`salary` < e2.`salary`
查询平均工资最低的部门id
#方式1:
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) = (
SELECT MIN(avg_sal)
FROM (
SELECT AVG(salary) avg_sal
FROM employees
GROUP BY department_id
) dept_avg_sal
)
#方式2:
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) <= ALL (
SELECT AVG(salary) avg_sal
FROM employees
GROUP BY department_id
)
EXISTS 与 NOT EXISTS关键字
题目:查询公司管理者的employee_id,last_name,job_id,department_id信息
方式一:
SELECT employee_id, last_name, job_id, department_id
FROM employees e1
WHERE EXISTS ( SELECT *
FROM employees e2
WHERE e2.manager_id =
e1.employee_id);
方式二:自连接
SELECT DISTINCT e1.employee_id, e1.last_name, e1.job_id, e1.department_id
FROM employees e1 JOIN employees e2
WHERE e1.employee_id = e2.manager_id;
创建和管理
创建数据库
方式1:创建数据库
CREATE DATABASE 数据库名;
方式2:创建数据库并指定字符集
CREATE DATABASE 数据库名 CHARACTER SET 字符集;
方式3:判断数据库是否已经存在,不存在则创建数据库( 推荐 )
CREATE DATABASE IF NOT EXISTS 数据库名;
使用数据库
查看当前所有的数据库
SHOW DATABASES; #有一个S,代表多个数据库
查看当前正在使用的数据库
SELECT DATABASE(); #使用的一个 mysql 中的全局函数
查看指定库下所有的表
SHOW TABLES FROM 数据库名;
查看数据库的创建信息
SHOW CREATE DATABASE 数据库名;
修改数据库
更改数据库字符集
ALTER DATABASE 数据库名 CHARACTER SET 字符集; #比如:gbk、utf8等
删除指定的数据库
DROP DATABASE 数据库名;
删除指定的数据库( 推荐 )
DROP DATABASE IF EXISTS 数据库名;
创建表
CREATE TABLE [IF NOT EXISTS] 表名(
字段1, 数据类型 [约束条件] [默认值],
字段2, 数据类型 [约束条件] [默认值],
字段3, 数据类型 [约束条件] [默认值],
……
[表约束条件]
);
# 举一个例子
-- 创建表
CREATE TABLE emp (
-- int类型
emp_id INT,
-- 最多保存20个中英文字符
emp_name VARCHAR(20),
-- 总位数不超过15位
salary DOUBLE,
-- 日期类型
birthday DATE
);
# 查看表结构
DESC emp;
# 创建表举例2:
CREATE TABLE dept(
-- int类型,自增
deptno INT(2) AUTO_INCREMENT,
dname VARCHAR(14),
loc VARCHAR(13),
-- 主键
PRIMARY KEY (deptno)
);
创建方式2
指定的列和子查询中的列要一一对应
通过列名和默认值定义列
CREATE TABLE emp1 AS SELECT * FROM employees; # 数据和结果都拷贝过来了
CREATE TABLE emp2 AS SELECT * FROM employees WHERE 1=2; -- 创建的emp2是空表
# 可以选择一些数据进行存储
CREATE TABLE dept80
AS
SELECT employee_id, last_name, salary*12 ANNSAL, hire_date
FROM employees
WHERE department_id = 80;
查看表结构:
SHOW CREATE TABLE 表名\G
修改表
追加一个列
ALTER TABLE 表名 ADD 【COLUMN】 字段名 字段类型 【FIRST|AFTER 字段名】;
# 举例
ALTER TABLE dept80
ADD job_id varchar(15);
修改一个列
ALTER TABLE 表名 MODIFY 【COLUMN】 字段名1 字段类型 【DEFAULT 默认值】【FIRST|AFTER 字段名2】;
# 举例:
ALTER TABLE dept80
MODIFY salary double(9,2) default 1000;
重命名一个列
ALTER TABLE 表名 CHANGE 【column】 列名 新列名 新数据类型;
举例:
ALTER TABLE dept80
CHANGE department_name dept_name varchar(15);
删除一个列
ALTER TABLE 表名 DROP 【COLUMN】字段名
举例:
ALTER TABLE dept80
DROP COLUMN job_id;
重命名表
方式yi:
RENAME TABLE emp
TO myemp;
方式2:
ALTER table dept
RENAME [TO] detail_dept; -- [TO]可以省略
删除表
DROP TABLE [IF EXISTS] 数据表1 [, 数据表2, …, 数据表n];
DROP TABLE dept80;
DROP TABLE 语句不能回滚
清空表
TRUNCATE TABLE detail_dept; # 清空detail_dept 表
## TRUNCATE语句不能回滚,而使用 DELETE 语句删除数据,可以回滚
DELETE FROM emp2;
#TRUNCATE TABLE emp2;
SELECT * FROM emp2;
ROLLBACK;
SELECT * FROM emp2;
插入数据
解决方式:使用 INSERT 语句向表中插入数据。
INSERT INTO 表名
VALUES (value1,value2,....);
举例:
INSERT INTO departments
VALUES (70, 'Pub', 100, 1700);
为表的指定字段插入数据:(可以指定数据)
INSERT INTO 表名(column1 [, column2, …, columnn])
VALUES (value1 [,value2, …, valuen]);
同时插入多条记录:
INSERT INTO table_name
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
举例:
mysql> INSERT INTO emp(emp_id,emp_name)
-> VALUES (1001,'shkstart'),
-> (1002,'atguigu'),
-> (1003,'Tom');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
将查询结果插入到表中
INSERT INTO 目标表名
(tar_column1 [, tar_column2, …, tar_columnn])
SELECT
(src_column1 [, src_column2, …, src_columnn])
FROM 源表名
[WHERE condition]
举例:
INSERT INTO emp2
SELECT *
FROM employees
WHERE department_id = 90;
更新数据
使用 UPDATE 语句更新数据。语法如下:
UPDATE table_name
SET column1=value1, column2=value2, … , column=valuen
[WHERE condition]
举例:
UPDATE employees
SET department_id = 70
WHERE employee_id = 113;
删除数据
使用 DELETE 语句从表中删除数据
DELETE FROM table_name [WHERE <condition>];
使用 WHERE 子句删除指定的记录。
DELETE FROM departments
WHERE department_name = 'Finance';