app爬虫(1)谷歌Nexus6P获取root
面试了一圈爬虫,人均手撕淘宝抖音,无奈pc网页爬虫只能作为其中一项基础,还要能反编译,逆向app,只好再舍弃点头发,硬刚下去。
app爬虫和初学编程一样,配置环境就能难到一半人,想fiddler直接改代理中间人转发抓包,no!app各种检测,一个https的CA证书就治住了,但有个神器叫Edxposed,各种模块,大学时候用它抢红包,防撤回各种炫,没想到以后还会再见面。想抓到https的包就需要它,首先需要root,为了爬虫事业,买了谷歌亲儿子nexus6p
网上搜root教程,各种玄乎的教程,要下什么zip包再刷进去,根本不行,都是学会1+1后解微分方程的那种教程,总之各种报错,各种装不上,最后直接到官网看,立马成功,要学东西还得看官方的教程。本人写个保姆级教程,方便查阅
准备root
一,准备材料:
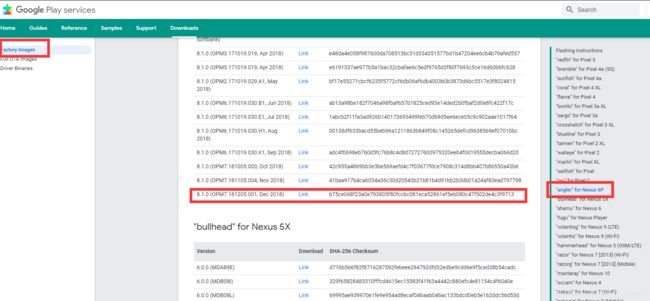
1.官方nexus6P刷机包,要线刷完整包,别下错了
https://developers.google.com/android/ota#angler
2.magisk包又叫面具,root用
官网版:https://magisk.download/
最新版:https://github.com/topjohnwu/Magisk/releases

3.platform-tools,刷机执行命令行,下载适合自己环境的
https://developer.android.com/studio/releases/platform-tools
二,刷机,为了同步一下boot.img文件,打补丁用
1.下载好刷机包,解压,里面的zip文件都解压
2.手机打开调试,cmd进入platform-tools
3.adb命令:
adb reboot bootloader
确保连上你的手机:
fastboot devices
解锁:
fastboot flashing unlock
开机验证是否解锁
解锁进入boot
adb reboot bootloader
fastboot flash bootloader bootloader-angler-angler-03.54.img
fastboot flash radio radio-angler-angler-03.61.img
fastboot reboot-bootloader
fastboot flash recovery recovery.img
fastboot flash boot boot.img
fastboot flash system system.img
fastboot flash vendor vendor.img
可能会用
fastboot flash cache cache.img
fastboot flash userdata userdata.img
无cache和userdata:
fastboot format userdata
fastboot format cache
完成刷机
三,做补丁
1.手机安装magisk的apk文件,将刷机包的boot.img文件拷贝入手机Download文件夹
2.进入点击安装,下一步,选择并修补一个文件,选择boot.img文件,点开始,等待结束

3.手机magisk软件对boot.img打完补丁会生成一个新的img文件,再传入电脑线刷
四,刷入补丁
电脑cmd用adb命令刷入这个文件
adb reboot bootloader
fastboot flash boot magisk_patched-22100_iVD4B.img
重启完成root
验证root:
wifi密码查看器,应用会申请root权限,有授予到就成功了
安装Edxposed
https://blog.coderstory.cn/guide-install-edxposed/
下载Edxposed
fastboot flash recovery twrp-3.7.0_9-0-angler.img