Python-For-EEG基础代码讲解(1)
Python-For-EEG
我要演示脑电图信号的基本分析。
主题
1、基于时域分析,P300信号数据集
- Event-related potentials and 1-dimensional convolution(ERP,CNN)
- Long short-term memory(LSTM)
2、基于频域分析,DEAP和SSVEP数据集
- Spectral analysis and alpha asymmetry
- Canonical correlation analysis(CCA)
3、基于成分分析,运动想象数据集
- Event-related desynchronization(ERD)
数据集
所有数据集准备好
1. P300数据集
这是我个人的P300信号,我通过我的OpenBCI耳机在视觉上关注36个字母顺序的目标时获得的。当闪光灯在我所看的目标上闪烁时,在刺激开始后300ms会有一个信号上升。在数据集中,列是时间戳(128 samples per second), 16 channels of ‘Fp1’, ‘Fp2’, ‘F7’, ‘F3’, ‘F4’, ‘F8’, ‘C3’, ‘Cz’, ‘C4’, ‘T5’, ‘P3’, ‘P4’, ‘T6’, ‘POz’, ‘O1’, ‘O2’, 标记表示事件。标记格式将在笔记本中详细说明。
文件:p300-6trials-12rep-chaky.csv
2、DEAP和SSVEP数据集
ssvep数据集
在这里,我们记录了用户分别观看以6,10和15Hz闪烁的三个不同的圆圈。我们将使用滤波器组典型相关分析对信号进行分类。
文件:ssvep-10trials-3s-chaky-bigsquare.csv
DEAP 数据集
它基本上是一个数据集,关于参与者观看一些1分钟的情感视频,同时佩戴32个EEG通道。欲了解更多详情,请访问https://www.eecs.qmul.ac.uk/mmv/datasets/deap/
经过处理python版本DEAP数据
3、运动想象数据集
在这里,我们记录一个用户做想象中的左右运动。我们将探索与事件相关的去同步以解码类。
这里我们将演示处理脑电图信号的基本过程。为了简单起见,我们将处理一个相当简单的P300数据集。
我们还将访问事件相关电位和长短期记忆来解码信号。
注意:我们假设你对神经网络非常熟悉,所以我们将主要使用它,而不会有太多杂乱的解释。
导入基础包
import mne
from mne import create_info
from mne.io import RawArray
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, WeightedRandomSampler
cuda加速
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
加载数据
df = pd.read_csv("../data/p300-6trials-12rep-chaky.csv")
df.head()
#we don't need timestamps for modeling
df = df.drop(["timestamps"], axis=1)
df.columns = ['P4', 'Pz', 'P3', 'PO4', 'POz', 'PO3', 'O2', 'O1', 'Marker'] #channels named according to how we plug our eeg device
df.head()
让我们看看这个标记是如何生成的。格式如下:
- 0:不发生任何事情
— 1:表示非目标闪烁 - 2:闪光到目标
print(df['Marker'].unique())
基础背景
如果你对数据不了解,首先,你需要了解脑电图实验。
在类似脑电图的实验中,你通常有一个会话(session)。(a record)
您通常拥有的数据以(通道,样本)(channels, samples)的形式存在。
例如,如果你用16个通道记录脑电图,采样率为128赫兹,5秒长,那么你最终会得到一个(16,128 x 5)的会话,因为1秒将有128个样本,即根据定义。
我们记录的一个附加通道是“marker”。
“marker”是一种记录中的映射器,用于以后识别某些事情发生的时间。
具有3个EEG通道+标记的数据可能看起来像这样
[
.
.
.
[eeg_1, eeg_2, eeg_3, 0],
[eeg_1, eeg_2, eeg_3, 0],
[eeg_1, eeg_2, eeg_3, 0],
[eeg_1, eeg_2, eeg_3, 1], <----- Some event1, like flashes or images happen here:
[eeg_1, eeg_2, eeg_3, 0],
[eeg_1, eeg_2, eeg_3, 0],
[eeg_1, eeg_2, eeg_3, 0],
[eeg_1, eeg_2, eeg_3, 0],
[eeg_1, eeg_2, eeg_3, 0],
[eeg_1, eeg_2, eeg_3, 2], <----- Some event2 again but another target happen here:
[eeg_1, eeg_2, eeg_3, 0],
[eeg_1, eeg_2, eeg_3, 0],
[eeg_1, eeg_2, eeg_3, 0],
.
.
.
]
因此,我们感兴趣的是在事件显示一段时间后(可能在event1显示后3秒)检索所有样本,这个过程称为“epoching”。
数据转换为原始MNE对象
First we gonna use Python MNE as it provides many useful methods for achieving these tasks. So first, we gonna transform our pandas to mne type. Here is the function transforming df to raw mne.
首先,我们将使用Python MNE库,因为它为实现这些任务提供了许多有用的方法。首先,我们要把 pandas类型 数据 转换成 mne 类型。这是将df转换成raw的函数。
raw = df_to_raw(df)
以下是一些关于我的数据结构的简短总结:
https://mne.tools/stable/most_used_classes.html
- MNE.io.Raw
- MNE.io.Raw 是你的整个session。在这个类中,您可以为整个session执行预处理,如’ filter '。
- MNE.Epochs
- epoch是一个将整个session分割为较小窗口的方法。你可以按你喜欢的方式来epoching你的session。最常见的epoch是遵循
marker/event通道
3.MNE.Evoked
- Evoked是你从每个epochs得到的数据。你可以把epochs想象成 一系列的Evoked。
伪影移除
伪影是需要消除的噪音。频率受限伪影的两个例子是缓慢漂移和电源线噪声。下面我们将说明如何通过过滤来修复这些缺陷。
def df_to_raw(df):
sfreq = 125 #our OpenBCI headset sampling rate
ch_names = list(df.columns)
ch_types = ['eeg'] * (len(df.columns) - 1) + ['stim']
ten_twenty_montage = mne.channels.make_standard_montage('standard_1020')
df = df.T #mne looks at the tranpose() format
df[:-1] *= 1e-6 #convert from uVolts to Volts (mne assumes Volts data)
info = create_info(ch_names=ch_names, ch_types=ch_types, sfreq=sfreq)
raw = mne.io.RawArray(df, info)
raw.set_montage(ten_twenty_montage)
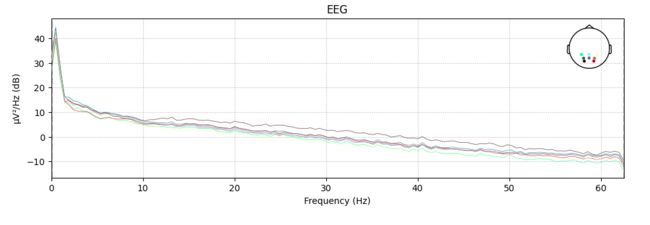
#try plotting the raw data of its power spectral density
raw.compute_psd().plot()
return raw
电源噪声
电源噪声是由电网产生的噪声。它由50Hz(或60Hz,取决于你的地理位置)的尖峰组成。一些峰值也可能出现在谐波频率,即电力线频率的整数倍,例如100Hz, 150Hz,…(或120Hz, 180Hz,…)。
去除220V交流电50Hz电源噪声。我们还将去除它的谐波,即100Hz, 150Hz等。由于我们的信号是62.5Hz(根据奈奎斯特定理是125Hz / 2),我们不需要运行谐波,而只需截取50Hz信号。
raw.notch_filter(50) #250/2 based on Nyquist Theorem
设置从49 - 51赫兹的带阻滤波器
FIR滤波器参数
设计一种单通、零相位、无因果带阻滤波器
-有窗时域设计(firwin)方法
-汉明窗口0.0194通带纹波和53 dB阻带衰减
—下带边缘:49.38
-低转换带宽:0.50 Hz (- 6db截止频率:49.12 Hz)
—上通带边缘:50.62 Hz
—上转换带宽:0.50 Hz (- 6db截止频率:50.88 Hz)
-过滤器长度:825个样本(6.600秒)
#可以看到50Hz噪声被移除了, yay!
raw.compute_psd().plot()

漂移移除
低频漂移通常在1Hz以下。此外,由于P300,可以安全地假设没有有用的数据超过40Hz。
raw.filter(1, 40)
raw.compute_psd().plot();
过滤1个连续段的原始数据
设置从1 - 40赫兹的带通滤波器
FIR滤波器参数
设计一种单通、零相位、非因果带通滤波器
-有窗时域设计(firwin)方法
-汉明窗口0.0194通带纹波和53 dB阻带衰减
—下通带边缘:1.00
-低转换带宽:1.00 Hz (- 6db截止频率:0.50 Hz)
—上通带边缘:40.00 Hz
—转换带宽上限:10.00 Hz (- 6db截止频率:45.00 Hz)
-过滤器长度:413个样本(3.304秒)
Epoching
epoch是在事件发生时只提取相关脑电数据的过程。在这里,我们将在事件开始前-0.1秒提取到事件开始后0.6秒。这里我们选择0.6秒,因为我们知道P300发生在300毫秒左右,所以它是一个很好的中间值。
from mne import Epochs, find_events
def getEpochs(raw, event_id, tmin, tmax, picks):
#epoching
events = find_events(raw)
epochs = Epochs(raw, events=events, event_id=event_id,
tmin=tmin, tmax=tmax, baseline=None, preload=True,verbose=False, picks=picks) #8 channels
print('sample drop %: ', (1 - len(epochs.events)/len(events)) * 100)
return epochs
#this one requires expertise to specify the right tmin, tmax
event_id = {'Non-Target': 1, 'Target' : 2}
tmin = -0.1
tmax = 0.6
eeg_channels = mne.pick_types(raw.info, eeg=True)
picks= eeg_channels
epochs = getEpochs(raw, event_id, tmin, tmax, picks)
今天先到这,下一集继续讲!好的话给个赞,所有资料在这里
https://download.csdn.net/download/fzf1996/87860291