Centos7 Docker部署Prometheus+Grafana+Alertmanager钉钉告警
前言
总体讲解的是Prometheus监控资产信息,Grafana打造可视化效果。监控的目标有很多实例,如:服务器资产硬件信息,Docker容器,kubernetes,日志,微服务等。本人也是处于学习阶段,运维必备技能。希望和大家共同交流
快速部署
server端:192.168.10.159
需要监控的client端:192.168.10.150
一、Prometheus
此文章最重要的一句话:运维=Ctrl工程师,此文章每个空行都是有意义的,复制的时候千万注意,我已经踩个这个坑了,除非你会,不然还是别乱动。
-
讲解:部署到指定目录及拉取个prometheus的配置文件。
创建目录mkdir -p /data/applications/prometheus临时启个prometheus的容器,把配置文件复制下来。
docker run -d -p 9090:9090 --name=prometheus prom/prometheus docker cp prometheus:/etc/prometheus/prometheus.yml /data/applications/prometheus docker rm -f prometheus -
讲解:正式部署prometheus
热加载两种方式:
kill -HUP pid
curl -X POST http://192.168.10.159:9090/-/reloaddocker run -d \ -p 9090:9090 \ --name=prometheus \ --network-alias prometheus \ --restart=always \ -v /data/applications/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \ -v /data/applications/prometheus/rules:/etc/prometheus/rules \ -v /data/applications/prometheus/ClientAll:/etc/prometheus/ClientAll \ prom/prometheus --config.file=/etc/prometheus/prometheus.yml --web.enable-lifecycle参数讲解,不做详细解释,快速部署学习
参数 快速介绍 -p 指定映射端口 –name 指定容器名称 –network-alias 指定网络别名 –restart 随docker而启动 -v 映射目录及文件 –config.file 指定配置文件 –web.enable-lifecycle 热加载 -
讲解:修改配置文件,不做详细解释,快速部署学习,该删的都删了,只留了精华,你细品
vim /data/applications/prometheus/prometheus.yml global: scrape_interval: 15s evaluation_interval: 15s alerting: alertmanagers: - static_configs: - targets: ["192.168.10.159:9093"] #这个是用来告警用的后面再讲解,先部署,本机的ip是10.159 rule_files: - "/etc/prometheus/rules/*.yml" #这个是用来存放告警规则文件,后面再讲解,先部署 scrape_configs: - job_name: "prometheus" static_configs: - targets: ["192.168.10.159:9090"] #本机的ip是10.159 - job_name: "File_Discovery_service" file_sd_configs: #基于文件发现服务方式,也可以基于Consul服务发现等,其它方式不讲解,又不给工资费劲 - files: - ClientAll/*.json #用json格式文件方式发现服务,下面的是用yaml格式文件方式,都可以,反正两个都部署了,随便你用哪个 refresh_interval: 10m - files: - ClientAll/*.yaml refresh_interval: 10m -
讲解:编辑发现服务的配置文件,11.85是我之前就部署了,不用管这个,现在再部署一个ip10.150,演示用
vim /data/applications/prometheus/ClientAll/node.json #再添加一行的话,上一行末尾必须写上逗号 [ {"targets": [ "192.168.11.85:9100" ],"labels": {"instance": "个人服务器"}}, {"targets": [ "192.168.10.150:9100" ],"labels": {"instance": "测试服务器"}} ]#上述服务端基本配置完了,修改完所有配置文件必须重启prometheus。 docker restart prometheus #防火墙添加开放端口 #prometheus firewall-cmd --zone=public --add-port=9090/tcp --permanent #alertmanager firewall-cmd --zone=public --add-port=9093/tcp --permanent #钉钉 firewall-cmd --zone=public --add-port=8060/tcp --permanent #grafana firewall-cmd --zone=public --add-port=3000/tcp --permanent firewall-cmd --reload setenforce 0 #或者永久关闭防火墙和SElinx systemctl stop firewalld systemctl disable firewalld setenforce 0 sed -i 's/^SELINUX=.*/SELINUX=disabled/g' /etc/selinux/config -
讲解:配置客户端Client资产监控服务。机制是,服务端主动读取客户端所展示的信息,进行筛选符合条件并告警。
官网不建议docker安装,我认同,应为这东西,部署100台服务器的话你要装100个docker吗?那就源码安装吧,写个脚本批量发布下,搜搜的就完事了,简单明了,当然了,/data/applications/prometheus/ClientAll/node.json,也要写一百行ip,标签等等。当然还有更简单的,不用你部署ip,基于Consul服务发现,自动发现目标。本章讲的是基于配置文件发现。我不太想讲Consul发现,不然要写很多字,电费很贵。
下载服务:prometheus官网
随便介绍几个大致的意思·prometheus #你自己猜
·alertmanager #告警推送,什么意思=自行百度
·blackbox_exporter #黑盒监控,什么意思=自行百度
·consul_exporter #Consul监控,什么意思=自行百度
·graphite_exporter
·haproxy_exporter
·memcached_exporter
·mysqld_exporter #mysql监控,什么意思=自行百度
·node_exporter #服务详细信息监控,什么意思=自行百度
·promlens
·pushgateway
·statsd_exporter现在就下载node_exporter,用来监控资产硬件信息,研究完这个你可以再研究其它的一个一个来
在10.150服务器上创建服务存放目录mkdir -p /data/applications/node_exporter/ #上传下载的服务包,并解压到此目录,下载的服务包可能版本不一样,自行修改 cd /data/applications/node_exporter/ tar zxvf node_exporter-1.5.0.linux-amd64.tar.gz && mv node_exporter-1.5.0.linux-amd64/* ./ #编写启动文件 vim /usr/lib/systemd/system/node_exporter.service [Service] User=root Group=root ExecStart=/data/applications/node_exporter/node_exporter [Install] WantedBy=multi-user.target [Unit] Description=node_exporter After=network.target #防火墙添加开放端口 firewall-cmd --zone=public --add-port=9100/tcp --permanent firewall-cmd --reload setenforce 0 #或者永久关闭防火墙和SElinx systemctl stop firewalld systemctl disable firewalld setenforce 0 sed -i 's/^SELINUX=.*/SELINUX=disabled/g' /etc/selinux/config #启动服务,并加入开机自启 systemctl restart node_exporter.service systemctl enable node_exporter.service -
IP+端口进行访问,http://192.168.10.159:9090/targets 如出现以下样式,表示你部署成功了,如果是红的可能就是你部署的有问题了,反正我是一次点亮,你可以自行摸索下。部署到这里,基本已经完成了,监控资产信息,你就可以批量化部署。查看资产信息需要专业的语言来查看信息,可视化效果不太友好。所以我们就要开始搭建Grafana可视化效果了,更好的浏览所有资产的信息

二、Grafana
-
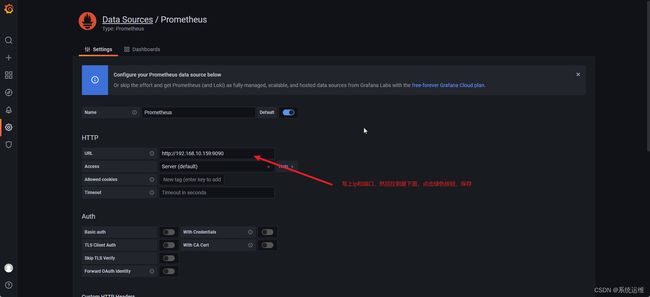
回到10.159服务器上,部署Grafana服务
docker run -d \ -p 3000:3000 \ --network-alias=grafana \ --name=grafana \ --restart=always \ grafana/grafana -
ip+端口访问,http://192.168.10.159:3000 ,初始用户和密码都是admin,输完后会让你再次修改密码,再输入两admin就可以了,不用整那么麻烦。





-
配置Grafana邮箱,用来邀请用户注册登入(也可以用来报警,但我没细研究)
#下载grafana配置文件,并修改 docker cp grafana:/etc/grafana/grafana.ini ./ vim grafana.ini #找到 [server] 标签这行,添加以下内容 domain = 192.168.10.159 #找到 [smtp] 标签这行,添加以下内容 enabled = true host = smtp.qiye.163.com:465 #我配置的是企业邮箱,其它的自行找server服务器,不讲解 user = [email protected] #企业邮箱的账号 password = xxxxxxx #企业邮箱的密码 ehlo_identity = http://192.168.10.159:3000 #本机的ip加端口 from_address = [email protected] #企业邮箱的账号 from_name = Grafana #默认,或者自己随便写个#上传配置文件至grafana,并重启 docker cp grafana.ini grafana:/etc/grafana/grafana.ini docker restart grafana
三、Alertmanager钉钉告警
上述只讲了,部署,和可视化,但是并没有设置告警阈值,比如监控磁盘容量啊,本身node_exporter服务是否正常运行等,通过钉钉发送告警
-
回到10.159服务器上,部署alertmanager,也需要个配置文件,安装prometheus的方式,部署临时容器,然后把配置文件复制下来
docker run -d -p 9093:9093 --name alertmanager prom/alertmanager docker cp alertmanager:/etc/alertmanager/alertmanager.yml /data/applications/prometheus/ docker rm -f alertmanager -
正式部署
docker run -d \ -p 9093:9093 \ --name alertmanager \ --network-alias=alertmanager \ --restart=always \ -v "/data/applications/prometheus/alertmanager.yml:/etc/alertmanager/alertmanager.yml" \ prom/alertmanager -
修改配置文件
vim /data/applications/prometheus/alertmanager.yml global: resolve_timeout: 5m route: group_by: ['alertname','app'] group_wait: 30s #在组内等待所配置的时间,如果同组内,30秒内出现相同报警,在一个组内出现 group_interval: 1m #如果组内内容不变化,合并为一条警报信息,5m后发送 repeat_interval: 1h #发送报警间隔,如果指定时间内没有修复,则重新发送报警 receiver: 'web.hook' receivers: - name: 'web.hook' webhook_configs: - url: 'http://192.168.10.159:8060/dingtalk/webhook1/send' send_resolved: true # 表示服务恢复后会收到恢复告警 inhibit_rules: - source_match: #配置了仰制告警,什么意思=自行百度 alertname: '.*' severity: '非常严重' target_match: #severity: '.*' severity: '严重' equal: ['alertname',"target","job","instance"] -
安装钉钉插件prometheus-webhook-dingtalk,和上述一样,就不解释了
docker run -d -p 8060:8060 --name=dingding timonwong/prometheus-webhook-dingtalk docker cp dingding:/etc/prometheus-webhook-dingtalk /data/applications/prometheus/ docker rm -f dingding -
正式部署
docker run -d \ -p 8060:8060 \ --name=dingding \ --restart=always \ --network-alias=dingding \ -v /data/applications/prometheus/prometheus-webhook-dingtalk:/etc/prometheus-webhook-dingtalk \ timonwong/prometheus-webhook-dingtalk -
修改配置文件,就留这几个就行啦,其它都删了,保留精华
先配置好钉钉,钉钉自定义的关键字,和token,需要记住了。关键字,必须在告警规则中有,不然钉钉发送不了消息
vim /data/applications/prometheus/prometheus-webhook-dingtalk/config.yml templates: - /etc/prometheus-webhook-dingtalk/templates/templates.tmpl targets: webhook1: url: https://oapi.dingtalk.com/robot/send?access_token=48asdasd5f2asdasd77ebd52d3611fasdasdasdasd message: text: '{{ template "email.to.message" . }}' -
编辑钉钉告警模板内容文件
vim /data/applications/prometheus/prometheus-webhook-dingtalk/templates/templates.tmpl{{ define "email.to.message" }} {{- if gt (len .Alerts.Firing) 0 -}} {{- range $index, $alert := .Alerts -}} ========= **监控告警** ========= **告警类型:** {{ $alert.Labels.alertname }} **告警级别:** {{ $alert.Labels.severity }} 级 **故障主机:** {{ $alert.Labels.instance }} {{ $alert.Labels.device }} **告警详情:** {{ $alert.Annotations.message }}{{ $alert.Annotations.description}} **故障时间:** {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} ========= = end = ========= {{- end }} {{- end }} {{- if gt (len .Alerts.Resolved) 0 -}} {{- range $index, $alert := .Alerts -}} ========= 告警恢复 ========= **告警主机:** {{ .Labels.instance }} **告警类型:** {{ .Labels.alertname }} **告警级别:** {{ $alert.Labels.severity }} 级 **告警详情:** {{ $alert.Annotations.message }}{{ $alert.Annotations.description}} **故障时间:** {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} **恢复时间:** {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} ========= = **end** = ========= {{- end }} {{- end }} {{- end }}#重启这两个服务 docker restart alertmanager dingding -
编辑告警规则文件,这里做演示,只写一个告警实例,需要其它的请点击下方链接
真棒普罗米修斯警报|警报规则的集合vim /data/applications/prometheus/rules/node_exporter.yml groups: - name: 服务器主机信息监控告警 rules: - alert: 监控所有Client_node服务 expr: up {job="File_Discovery_service"} == 0 for: 0m labels: severity: 非常严重 annotations: description: "监控的目标已丢失,请检查服务器自身或node_exporeer服务" #重启prometheus服务 docker restart prometheus -
效果图,把10.150的node_exporeer服务先关掉。就会触发告警,然后再打开也会触发告警,至于告警延迟时间长短控制,自行研究

结言
总算是讲了个大致,以上学会,只是入门级别,记住只是入门。