ElasticSearch从入门到精通--第三话(集群环境搭建篇)
ElasticSearch从入门到精通–第三话(集群环境搭建篇)
ElasticSearch从入门到精通–第一话(入门篇)
ElasticSearch从入门到精通–第二话(原生API调用–纯代码篇)
ElasticSearch从入门到精通–第三话(集群环境搭建篇)
ElasticSearch从入门到精通–第四话(核心概念篇)
ElasticSearch从入门到精通–第五话(整合SpringBoot高效开发、分页高亮等、Kibana使用篇)
概念
单机ElasticSearch服务器提供服务,往往会有最大的负载能力,超过这个阈值,服务器性能就会大大降低,所以生产环境中,一般都是通过集群方式部署。
单机存在的问题:
- 单台机器存储容量有限
- 单台机器无法实现高可用
- 单台机器并发能力有限
集群部署时,一般考虑高性能及高可用方面节点数量都是3个以上。
集群Cluster
一个集群就是有多台服务器节点组织在一起,共同持有整个数据,并一起提供索引和搜索功能。一个ES集群有一个唯一的名字标识,默认就是elasticsearch,每个节点需要指定某个集群的名字标识,来加入到集群中。
节点Node
一个节点其实就是一个ES服务器
windows配置集群
暂在一台机器上使用部署es集群。
在es目录/config/elasticsearch.yml中,修改并放开注释
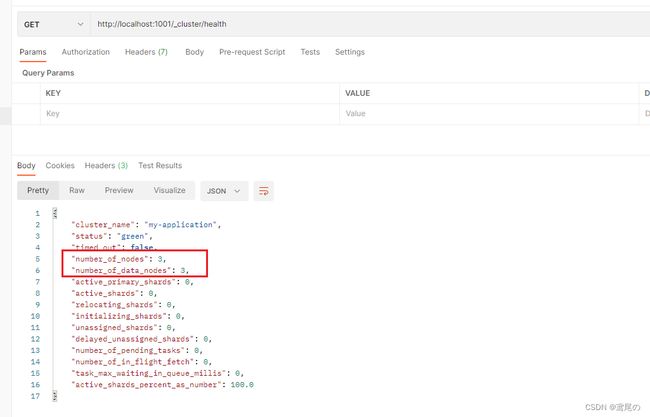
cluster.name: my-application
node.name: node-1001
http.port: 1001
transport.tcp.port: 9301
node.master: true # 有资格成为主节点
node.data: true # 数据节点
# 跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
将es拷贝两份,如图

其他两个节点,分别将配置修改下
node-1002
cluster.name: my-application
node.name: node-1002
http.port: 1002
transport.tcp.port: 9302
discovery.seed_hosts: ["localhost:9301"] # 注册到9301内部通信端口上
discovery.zen.fd.ping_timeout: 1m # 超时时间
discovery.zen.fd.ping_retries: 5 # 重试次数
node.master: true # 有资格成为主节点
node.data: true # 数据节点
# 跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
node-1003
cluster.name: my-application
node.name: node-1003
http.port: 1003
transport.tcp.port: 9303
discovery.seed_hosts: ["localhost:9301"] # 注册到9301内部通信端口上
discovery.zen.fd.ping_timeout: 1m # 超时时间
discovery.zen.fd.ping_retries: 5 # 重试次数
node.master: true # 有资格成为主节点
node.data: true # 数据节点
# 跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
启动时,记得先启动主节点,然后依次启动从节点。
通过GET请求http://localhost:1001/_cluster/health,查看集群状态
Linux单机部署es(各种踩坑)
首要的先下载好es的linux版的包,当然熟悉Docker的就可以直接使用docker安装了。我这边还是通过包的方式进行安装和配置。
将包上传到服务器后,解压缩;解压后的目录名称改不改都行。
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz
为了安全问题,ES不允许root用户直接运行,需要创建新的用户,建议不要将es解压到root用户目录下,可以放到其他的目录中,然后这个目录只为存放es(亲测,否则后续会遇到问题)
useradd es # 新增es用户
passwd es # 设置es用户的密码
chown -R es:es /es所在目录
修改es目录/config/elasticsearch.yml文件,加入配置
cluster.name: elasticsearch
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"] # 集群初始化的主节点
修改/etc/security/limits.conf,设置每个进程可以打开的文件数的限制
es soft nofile 65536
es hard nofile 65536
修改/etc/security/limits.d/20-nproc.conf,设置每个进程可以打开的文件数的限制
es soft nofile 65536
es hard nofile 65536
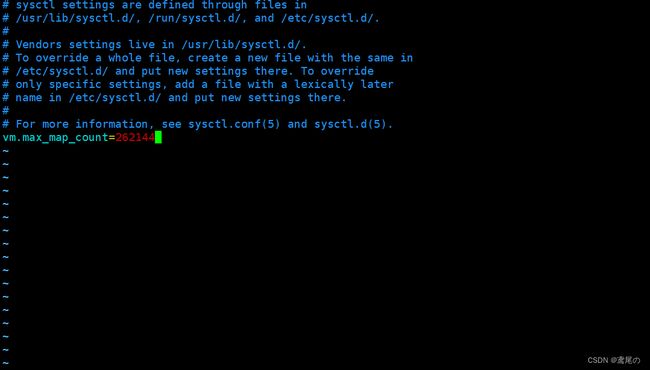
设置jvm最大虚拟内存,否则会踩坑的
#修改文件
sudo vim /etc/sysctl.conf
#添加参数
vm.max_map_count=262144
重新加载
sysctl -p
启动es(各种踩坑日志)
-
踩坑一:如果是以root用户启动的,那么会报错
java.lang.RuntimeException: can not run elasticsearch as root,切换至es用户启动 -
踩坑二:用es用户启动时,直接找不到本地的java(
could not find java in JAVA_HOME at /root/app/jdk1.8/bin/java),因为是普通用户,而我的jdk又是放到了root家目录下,普通用户访问不了,后来把这个普通用户设置为管理员依旧不能用,查阅资料后发现:要把jdk包放到普通用户相关的目录(记得给普通用户授予权限)下,然后在普通用户根目录下的.bash_profile中增加export JAVA_HOME=/home/es/jdk1.8 export PATH=$PATH:$JAVA_HOME/bin然后
source ./.bash_profile刷一下再次使用es用户执行下,再次踩坑
-
踩坑三:因为es也是放在了root家目录下,所以报错
错误: 找不到或无法加载主类 org.elasticsearch.tools.java_version_checker.Java,将es放入其他目录中执行。又他喵出现问题启动完自动关闭了,看看日志 -
踩坑四:
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144],告诉我jvm虚拟机的最大内存太小了,最少是262144,注意上面的配置尽量做全点,防止出现问题。
目测发现,我这边用的es是7.8版本的,jdk是8版本,虽然有警告版本不匹配,但是ES还是能够启动起来的,基本的使用应该是不成问题的。
Linux集群部署es
亲测踩坑,一定不要将jdk、es等环境放入到root用户家目录下,否则新建的其他用户是无权限访问它们的!!!虽然也有解决的办法,但是太浪费时间了!
集群部署时,配置肯定就会复杂起来。集群这里我搞了三个虚拟机,然后分别称为es1、es2、es3,我们把es1搞成主节点。
3个机器先同上面单机部署,把需要的东西准备好:
- 先把包解压好,然后可以起个简短的目录名
- 创建普通用户,赋予es所在目录的权限(
es目录别往root家目录里面放,小心踩坑) - 把先关的配置先给做好(
设置每个进程可以打开的文件数的限制、设置jvm最大虚拟内存)
es1
config/elasticsearch.yml文件做配置
cluster.name: elasticsearch
node.name: node-1
network.host: 192.168.1.47
http.port: 9200
node.master: true # 有资格成为主节点
node.data: true # 数据节点
# 跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
http.max_content_length: 200mb # 限制http传输的数据大小
cluster.initial_master_nodes: ["node-1"] # 集群初始化的主节点
# es7之后新增的配置。节点发现
discovery.seed_hosts: ["192.168.1.47:9300","192.168.1.26:9300","192.168.1.27:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
# 集群内同时启动的数据任务个数,默认是2个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
cluster.routing.allocation.node_concurrent_recoveries: 16
cluster.routing.allocation.node_initial_primaries_recoveries: 16
es2
config/elasticsearch.yml文件做配置
cluster.name: elasticsearch
node.name: node-2
network.host: 192.168.1.26
http.port: 9200
node.master: true # 有资格成为主节点
node.data: true # 数据节点
# 跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
http.max_content_length: 200mb # 限制http传输的数据大小
cluster.initial_master_nodes: ["node-1"] # 集群初始化的主节点
# es7之后新增的配置。节点发现
discovery.seed_hosts: ["192.168.1.47:9300","192.168.1.26:9300","192.168.1.27:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
# 集群内同时启动的数据任务个数,默认是2个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
cluster.routing.allocation.node_concurrent_recoveries: 16
cluster.routing.allocation.node_initial_primaries_recoveries: 16
es3
config/elasticsearch.yml文件做配置
cluster.name: elasticsearch
node.name: node-3
network.host: 192.168.1.27
http.port: 9200
node.master: true # 有资格成为主节点
node.data: true # 数据节点
# 跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
http.max_content_length: 200mb # 限制http传输的数据大小
cluster.initial_master_nodes: ["node-1"] # 集群初始化的主节点
# es7之后新增的配置。节点发现
discovery.seed_hosts: ["192.168.1.47:9300","192.168.1.26:9300","192.168.1.27:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
# 集群内同时启动的数据任务个数,默认是2个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
cluster.routing.allocation.node_concurrent_recoveries: 16
cluster.routing.allocation.node_initial_primaries_recoveries: 16
将这些es服务一个一个启动起来看看,先启动下es1,然后es2,es3
如果发现执行报错,没有找到主机的路由: 192.168.1.27/192.168.1.27:9300,那么就是你的电脑防火墙开着呢,要么给开放对应的端口,要么就直接把防火墙关了也行。
启动完成后,访问接口看下集群的状态情况,GET请求访问http://192.168.1.47:9200/_cat/nodes

没问题后,集群部署完成。