Transformer模型
Transformer模型详解
本文主要介绍transformer模型的具体实现
2107年,Google在论文Attention is all you need
提出了transformer模型,其使用self-attention结构取代了在NLP任务中常用的RNN网络结构,相比RNN网络结构,其最大优点是可以并行计算,Transformer模型整体架构如图1.1所示:
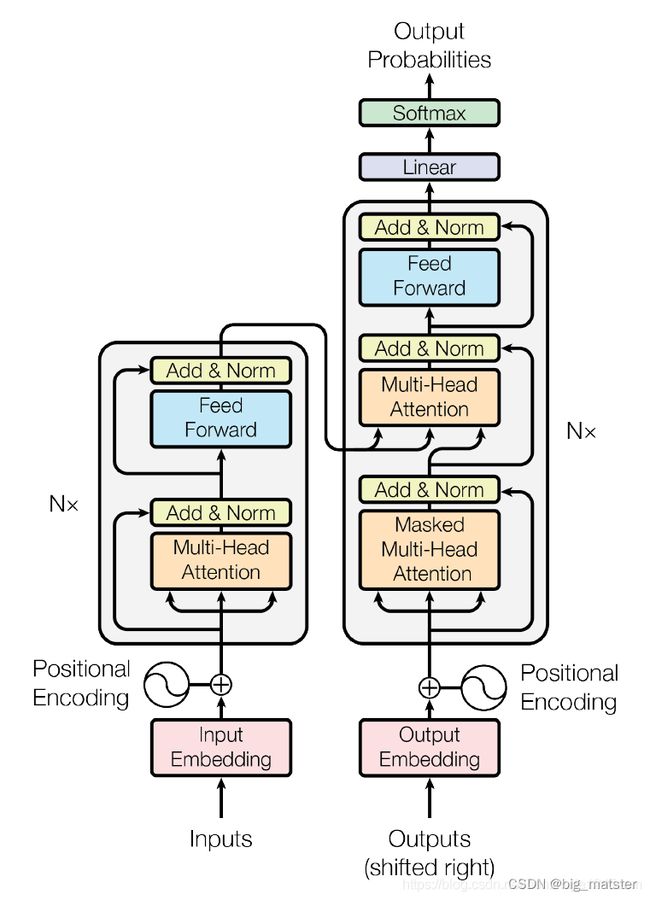
Transformer概览
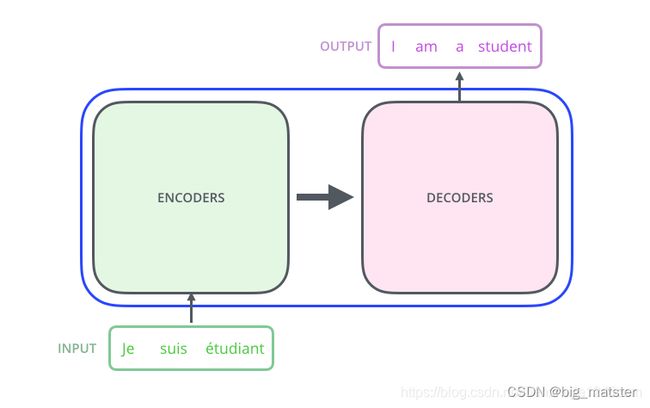
首先,让我们讲transformer模型视为一个黑盒子,如图1.2所示:在机器翻译任务中,将一种语言的一个句子作为输入,然后将其翻译成另一种语言的一个句子作为输出。

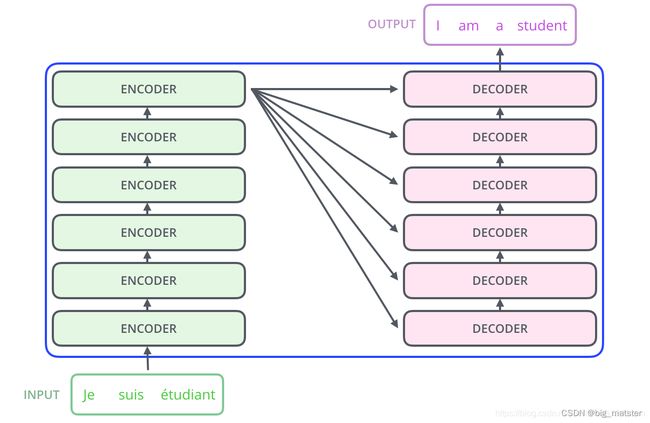
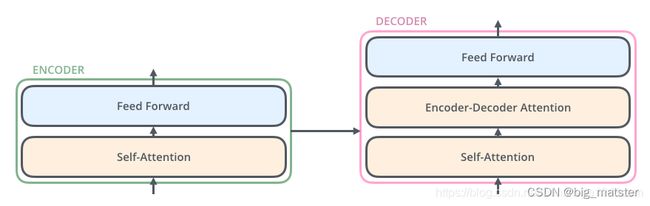
transformer本质上是一个Encoder-Decoder架构,因此,中间部分的transformer的可以分为两个部分,编码组件和解码组件、如图1.3所示:
其中,编码组件由多层编码器(Encoder)组成,(在论文中,作者使用了6层编码器)在实际使用过程中可以尝试其他层数。解码组件也由相同层数的编码器组成(Decoder)组成。(在论文中也使用了6层)。
**
**
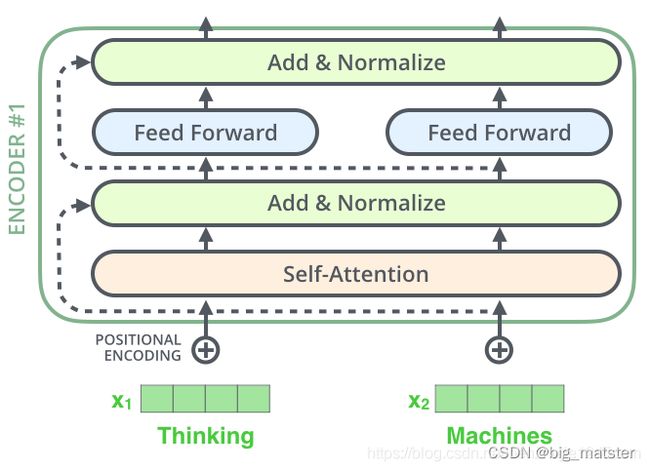
每个编码器由两个子层组成:Self-attention层(自注意力层)和Position-wise Feed Forward Network(前馈网络,缩写为FFN)。每个编码器结构都是相同的,但是其使用不同的权重参数。
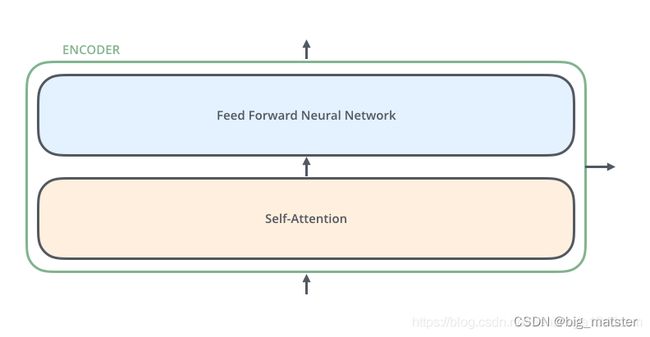
编码器的输入会先流入Self-attention层。其可以让编码器在对特定词进行编码时,使用输入句子的其他词的信息。(可以理解为:当我们翻译一个词时,不仅只关注当前的词,而且还会关注其他词的信息)
后面,我们将会详细介绍self-attention的内部结构,然后self-attention的输出会流入前馈网络。
解码器也有编码器中这两层,但是它们之间还有一个注意力层,(即Encoder-Decoder Attention). 其中用来帮忙解码关注输入句子的相关部分。
引入张量
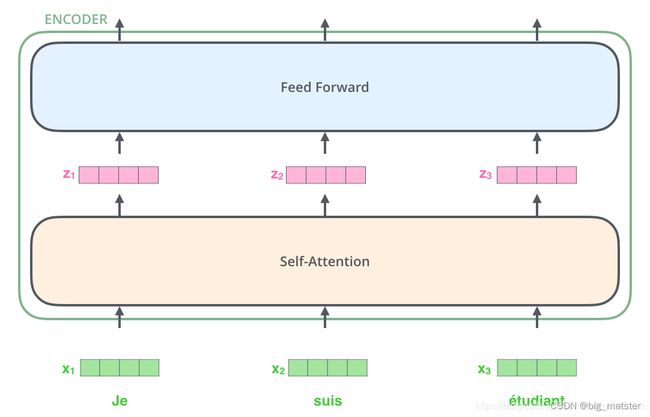
现在我们已经了解了模型的主要组成部分,让我们开始研究各种向量\张量,以及它们在这些组成部分之间是如何流动的,从而将输入经过已经训练的模型转换为输出。
和通常的NLP任务一样,首先,我们使用词嵌入算法(Embedding)将每个词转换为一个词向量,在Transformer论文中,词向量的维度是512.

每个词嵌入到大小为512的向量中,我们将用这些简单的框代表这些向量。
嵌入仅发生在这些最底层的编码器中,所有编码器都会接收到一个大小为512的向量列表——底部编码器接受到一个词嵌入向量。其他编码器接收的是上一个编码器的输出。这个列表是大小是我们可以设置的超参数。
基本上这个参数就是训练数据集的最长句子的长度。
对输入序列完成嵌入操作后,每个词都会流经编码器的两层。
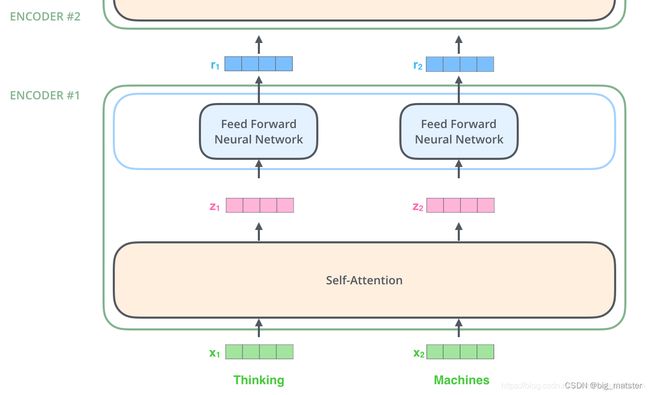
接下来,我们将输入一个更短的句子作为示例。来说明编码器中每个句子中发生了什么?
上面我们提到,编码器会接受一个向量作为输入。编码器首先将这些向量传入到Self-attention层。然后传递到前馈网络,最后将输出传递到下一个编码器。
Self-attention(自注意力)
概览
首先,我们通过一个例子,来对Self-attention有一个直观的认识,例如我们要翻译下面这个句子:
The animal didn’t cross the street because it was too tired
这个句子中it是指的是什么?是指的是animal还是street?。对人来说,这是一个简单的问题,但是算法来说却不那么简单。
当模型在处理it时,Self-attention能够将it 和animal关联起来。
当模型处理每个词(输入序列中的每个位置)时,Self-attention不仅能够关注当前词的位置,而且能够关注句子中的其他位置的词。从而更好地编码这个词。
如果你熟悉RNN,想想如何维护隐状态,使得RNN将已经处理的先前词\向量的表示。与当前正在处理的词和向量进行合并。Transformer使用Self-Attention机制将其他词理解融入到当前词中。

图 1.10 当我们在编码器 #5(堆栈中的顶部编码器)中对单词**”it“进行编码时,有一部分注意力集中在”The animal“上,并将它们的部分信息融入到”it“的编码**中。
Self-attention机制
基本结构如图所示:

缩放点击注意力
对于Self-attention来讲,Q(query)、和K(key)、和V(Value).三个矩阵均来自同一输入,并按照以下步骤计算:
首先计算Q和K之间的点积,为了防止其结果过大,去除以 d k \sqrt{d_k} dk
其中** d k d_k dk为Key向量的维度**。
然后利用Softmax操作将其结果归一化为概率分布,在乘以矩阵 V V VJ就得到权重和表示。
整个过程的计算公式表示为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q k T d k ) V Attention(Q,K,V) = softmax(\frac{Qk^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQkT)V
为了更好地理解Self-attention, 下面,我们通过具体的例子进行详细说明:
Self-attention详解
让我们看一下,如何使用向量来计算Self-attention. 计算Self-attention的步骤如下:
第一步:
对编码器的每个输入向量(在本例中,即每个词的词向量)。创建三个向量:Query向量、Key向量、Value向量。它们是通过词向量分别和3个矩阵相乘得到,这3个矩阵通过训练获得:
请注意:这些向量的维数小于词向量的维数。新向量的维数为54.而embedding和编码器输入\输出向量的维数为512.新向量不一定非要更小。这是为了使多头注意力计算保持一致的结构性选择。
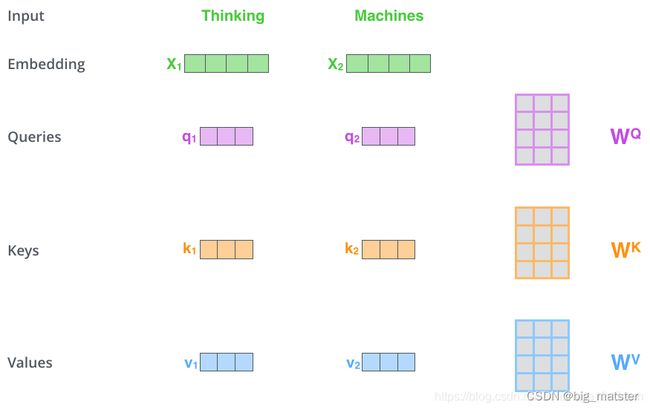
图中, X 1 X_1 X1乘以权重矩阵 W Q W^Q WQ得到 q 1 q_1 q1 即与单词关联的Query向量。最终会为输入句子中的每个词创建一个Query,一个Key和一个Value向量。
什么是Key、Query、和Value向量?
其是一种抽象的,对注意力的计算和思考非常有用,继续阅读下面注意力的计算过程,将了解这些向量所扮演的角色。
第二步
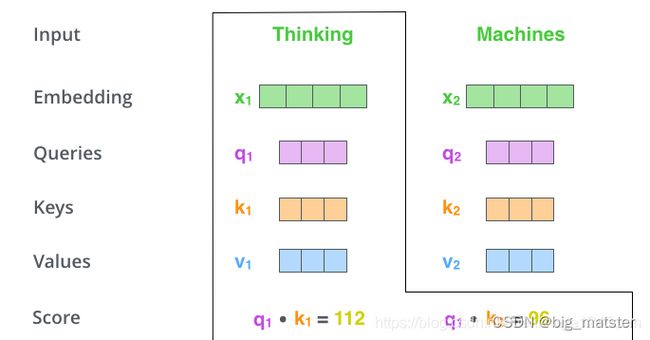
计算注意力分数,假设我们正在计算这个例子中的第一个词"Thinking"的子自注意力,需要根据“Thinking"这个词,对句子中的每个词都计算一个分数,这些分数决定了我们在编码”Thinking"这个词时,需要对其他位置的每个词放置多少注意力。
这些分数,是通过“Thinking"的Query向量,和需要评价的词的Key向量点积得到的,如果我们计算句子中第一个位置词的注意力分数。则第一个分数是 q 1 q_1 q1和 k 1 k_1 k1的点积,第二个分数是 q 1 q_1 q1和 k 2 k_2 k2的点积。
第三步
将每个分数除以 d k \sqrt{d_k} dk,( d k d_k dk是Key的向量的维度,目的是在反向传播时,求梯度更加稳定,实际上,也可以除以其他数。
第四步
将这些分数进行Softmax操作,Softmax将分数进行归一化处理,使得其都为正数并且和为1、
这些 Softmax 分数决定了在编码当前位置的词时,对所有位置的词分别有多少的注意力。很明显,当前位置的词汇有最高的分数,但有时注意一下与当前位置的词相关的词是很有用的。第五步
将每个Softmax分数分别与每个Value值向量相乘,这种做法背后的直觉理解是:对于分数高得部分,相乘后得值就越大,我们会把更多得注意力放在其身上,对于分数底得位置,相乘后得值就越小,这些位置得词可能相关性不大,我们就可以忽略这些位置得词。

第六步
将加权得Value向量求和,这样就得到了自注意力层在这些位置的输出。
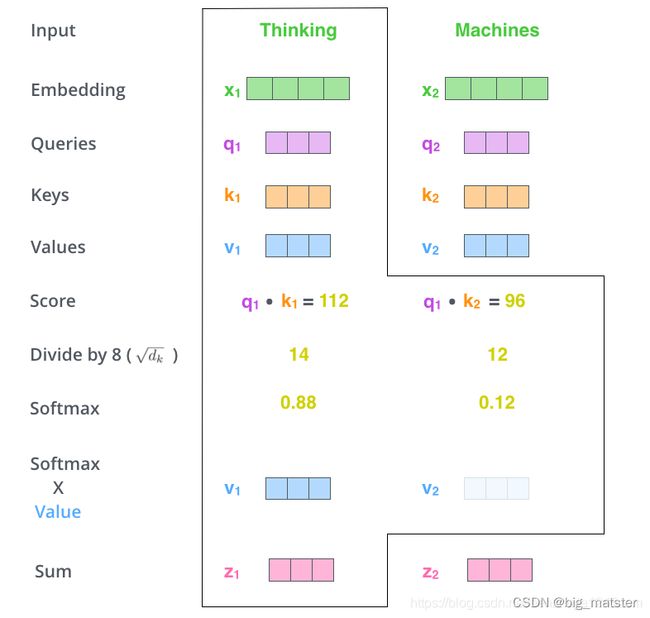
这样就完成了自注意力的计算,生成的向量会输入到前馈网络中,但是在实际实现中,此计算是以矩阵形式进行,以便实现更快的处理速度,下面来看看如何使用矩阵计算。
使用矩阵计算Self Attention
第一步
计算Query、Key、Value矩阵,首先将所有词向量放入一个矩阵 X X X中,然后分别和三个我们训练过的权重矩阵( W Q W^Q WQ, W k W^k Wk W V W^V WV),相乘,得到Q,K,V矩阵。
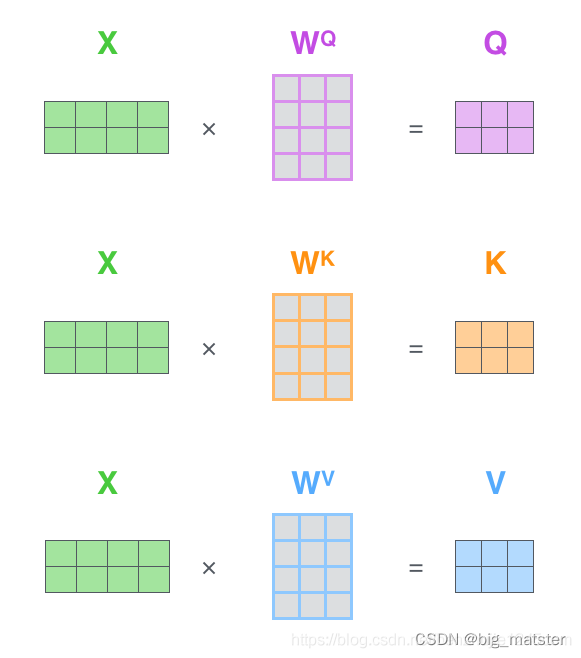
图 1.16 矩阵 X 中的每一行,表示输入句子中的每一个词的词向量(长度为 512,在图中为 4 个方框)。矩阵 Q,K 和 V 中的每一行,分别表示 Query 向量,Key 向量和 Value 向量(它们的长度都为 64,在图中为 3 个方框)
第二步:
计算自注意力,由于这里使用矩阵进行计算,可以将前面的第二步到第六步压缩为一步:
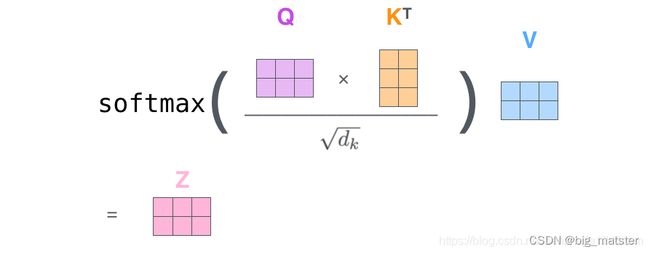
多头注意力(Multi-head Attention)
在Transformer论文中,通过添加一种多头注意力,进一步完善了自注意力层,具体做法:首先通过 h h h个不同线性变换对Query, Key, Value进行映射。
然后将不同的attention拼接起来,最后在进行一次线性变换,基本结构如图所示:
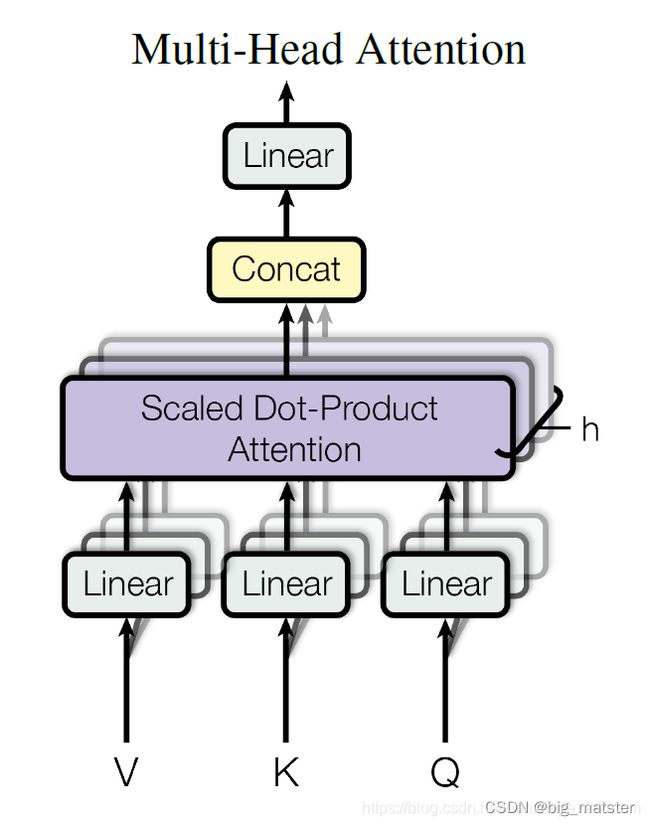
每一组注意力用于将输入映射到不同的子表示空间,这使得模型可以在不同的子表示空间中关注不同的位置。整个计算过程可以表示为:
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , h e a d 2 , h e a d 3 , . . . . . , h e a d h ) W O MultiHead(Q,K,V) = Concat(head_1,head_2,head_3,.....,head_h)W^O MultiHead(Q,K,V)=Concat(head1,head2,head3,.....,headh)WO
h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) head_i = Attention(QW_i^Q,KW_i^K,VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)
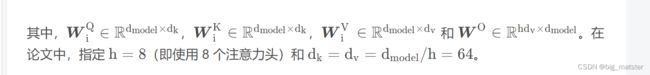
在多头注意力下,我们为每组注意力单独维护不同的 Q u e r y , K e y , V a l u e Query,Key,Value Query,Key,Value的权重矩阵,从而得到不同的 Q u e r y , K e y , V a l u e Query,Key,Value Query,Key,Value矩阵,如前面所示:我们将 X X X乘以 W Q W K 和 W V 矩阵 W^Q W^K和W^V矩阵 WQWK和WV矩阵。
得到 Q u e r y , K e y , V a l u e Query,Key,Value Query,Key,Value 矩阵。
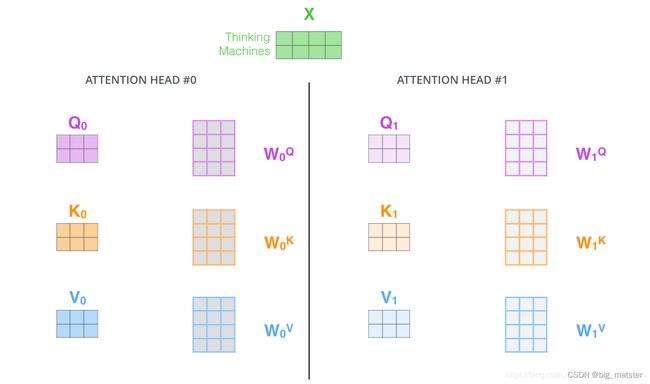
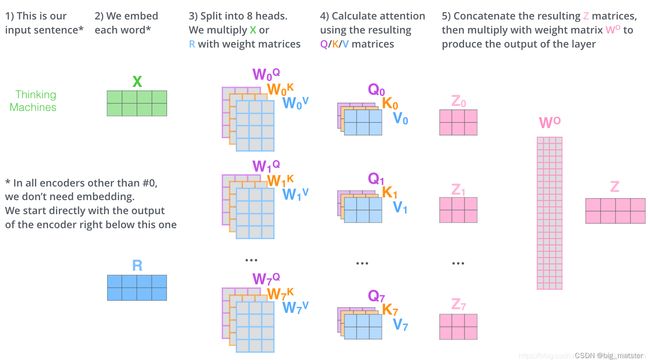
按照上面的方法,使用不同的权重矩阵进行8次注意力的计算,就可以得到8个不同的 Z Z Z矩阵。
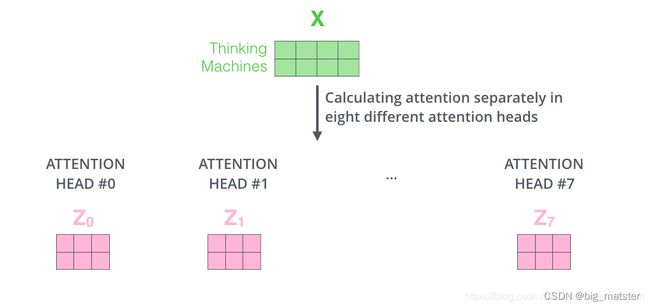
接下来就有点麻烦了,因为前馈神经网络接收的是一个矩阵(每个词的词向量),而不是上面的8个矩阵。因此,需要一种方法将八个矩阵整合成一个矩阵。具体方法如下:
- 把八个矩阵 Z 0 , Z 1 , Z 2 , . . . . , Z 7 {Z_0,Z_1,Z_2,....,Z_7} Z0,Z1,Z2,....,Z7 拼接起来。
- 把拼接后的矩阵和一个权重矩阵 W O W^O WO相乘。
- 得到最终矩阵 Z Z Z,这矩阵包含了所有注意力头的信息,这个矩阵会被输入到FFN层。

这差不多就是多头注意力的全部内容了,下面将所有内容放置在一张图中,以便我们可以同意查看。
现在让我们重新回顾下前面的例子,看看再对示例句子中的 i t it it进行编码时,不同的注意力头关注的位置分别在哪:
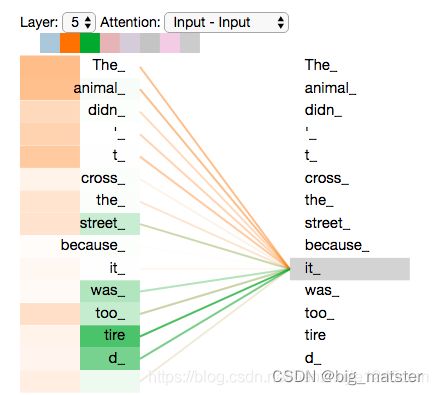
当我们对 i t it it进行编码时,一个注意力头关注 " T h e a n i m a l " "The animal" "Theanimal"时,另一个注意力头关注 t i r e d tired tired,从某种意义上来说,模型对it的表示,融入了animal和tired的部分表达。
Multi-head Attention的本质是:在参数总量保持不变的情况下,将同样的 Q u e r y , k e y , V a l u e Query,key,Value Query,key,Value映射到源来的高维空间的不同子空间中进行Attention计算。在最后一步在合并不同子空间中的Attention信息。这样降低了计算每个 head 的 Attention 时每个向量的维度。在某种意义上防止了过拟合,由于Attention在不同子空间由不同的分布,多头注意力实际上寻找了序列之间不同角度的关联关系,并在最后拼接这一步骤中,将不同子空间捕获到的关联关系再综合起来。
位置前馈网络
位置前馈网络就是一个全连接前馈网络,每个位置的词都单独经过这个完全相同的前馈神经网络。其由两个线性变换组成,即两个全连接层组成。第一个全连接层的激活函数为ReLU激活函数,可以表示为:
F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x) = max(0,xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
在每个编码器和解码器中,虽然这个全连接结构网络结构相同,但是不共享参数,整个前馈网咯的输入和输出维度都是 d m o d e l = 512 d_model = 512 dmodel=512 第一个全连接层的输出和第二个全连接层的输入维度为 d f f = 2048 d_{ff }= 2048 dff=2048。
残差连接和归一化
编码器结构有一个需要注意的细节,每个编码器的每个子层(Self-attention和FFN层)都有一个残差连接,在执行一个层的标准化操作,整个计算过程可以表示为:
s u b l a y e r o u t p u t = L a y e r N o r m ( x + S u b L a y e r ( x ) ) sub_layer_output = LayerNorm(x + SubLayer(x)) sublayeroutput=LayerNorm(x+SubLayer(x))
将向量和自注意力层的标准化操作可视化如下: 如下图所示:
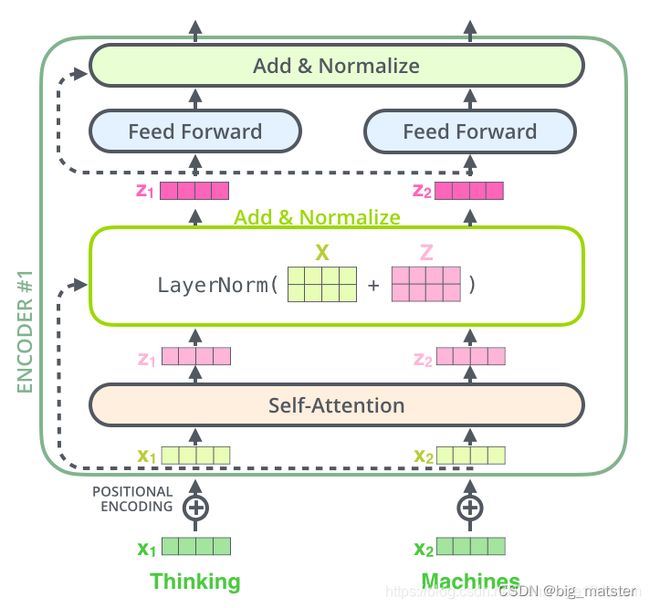
上面操作也适用于解码器的子层。假设一个 Transformer 是由 2 层编码器和 2 层解码器组成,其如下图所示:
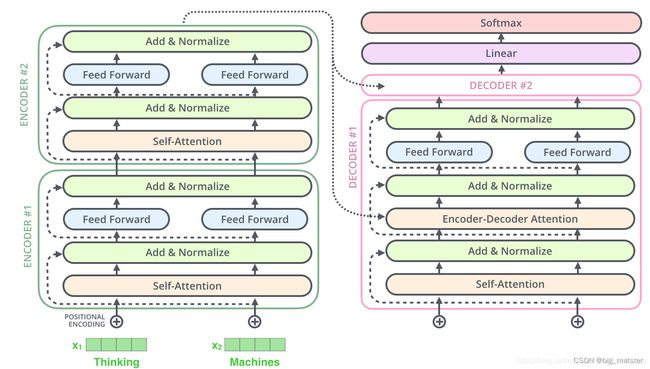
为了方便进行残差连接,编码器和解码器中的所有子层和嵌入层的输出维度都需要保持一致。在Transformer论文中 d m o d e l = 512 d_model = 512 dmodel=512.
位置编码
当目前为止,我们所描述的模型中缺少一种东西,表示序列中词顺序的方法。为了解决这个问题,Transformer模型为每个输入的词嵌入向量添加一个向量。这些向量遵循模型学习的特定i模式,有助于模型确定每个词的位置,或序列中不同词之间的距离:
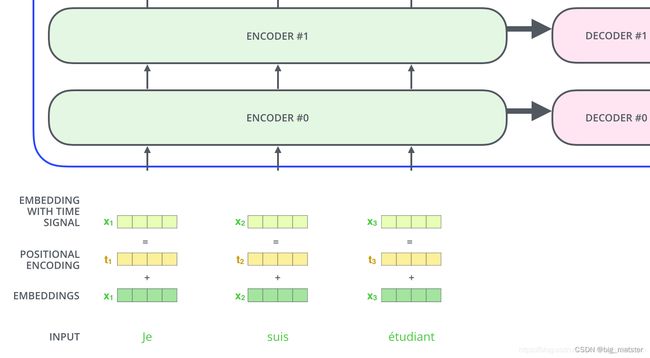
如果我们假设词嵌入向量维度是4时,那么实际位置编码如下:
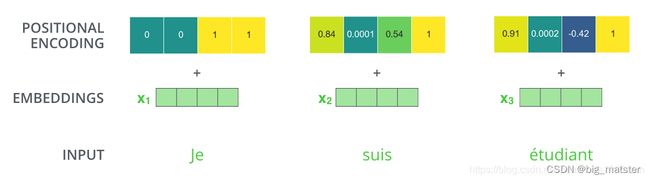
那么位置编码到底遵循什么模式,其具体数学公式如下:
P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE_(pos,2i) = sin(pos / 10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_(pos,2i+1) = cos(pos/10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中 p o s pos pos表示位置, i i i表示维度。上面的函数使得模型可以学到 t o k e n token token之间的相对位置关系;
任意位置 P E ( p o s + k ) PE_(pos + k) PE(pos+k)都可以被 P E ( p o s ) PE_(pos) PE(pos)的线性函数表示:

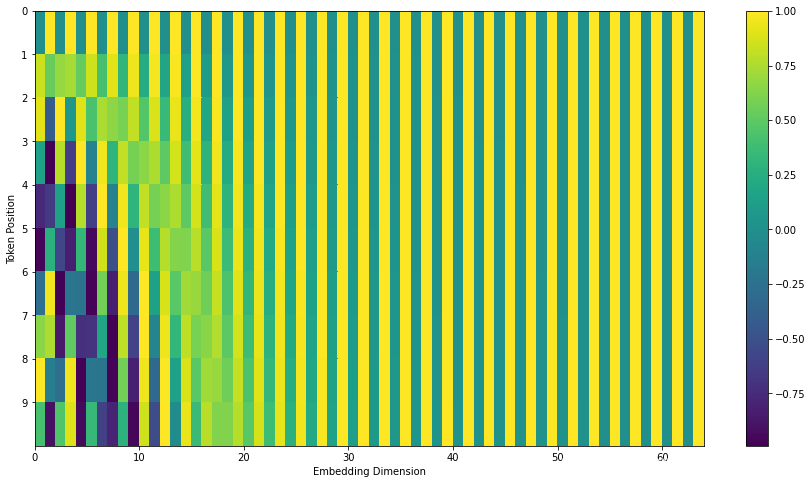
在下面,我们将这些值进行可视化,每一行对应一个向量的位置编码,以第一行对应于输入序列中第一个词的位置编码。每一行包含 64 个值,每个值的范围在 -1 和 1 之间。
解码器
现在我们已经介绍了编码器的大部分概念,我们也了解了解码器的组件的原理。现在让我们看下编码器和解码器是如何协同工作的。
通过上面的介绍,我们已经了解第一个编码器的输入是一个序列,最后一个编码器的输出是一组注意力向量 Key 和 Value。这些向量将在每个解码器的 Encoder-Decoder Attention 层被使用,这有助于解码器把注意力集中在输入序列的合适位置。
完成编码阶段后,我们开始解码阶段,解码阶段每个时间步都输出一个元素。
接下来会重复这个过程,直到输出一个结束符,表示 Transformer 解码器已完成其输出。每一步的输出都会在下一个时间步输入到下面的第一个解码器,解码器像编码器一样将解码结果显示出来。就像我们处理编码器输入一样,我们也为解码器的输入**加上位置编码,**来指示每个词的位置。
Encoder-Decoder Attention 层的工作原理和多头自注意力机制类似。不同之处是:Encoder-Decoder Attention 层使用前一层的输出构造 Query 矩阵,而 Key 和 Value 矩阵来自于解码器栈的输出。
Mask(掩码)
Mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 **Padding Mask 和 Sequence Mask。**其中,Padding Mask 在所有的 scaled dot-product attention 里面都需要用到,而 Sequence Mask 只有在 Decoder 的 Self-Attention 里面用到。
Padding Mask
Sequence Mask 是为了使得 **Decoder 不能看见未来的信息。**也就是对于一个序列,在$ t$时刻,我们的解码输出应**该只能依赖于 $t$ 时刻之前的输出,**而不能依赖 $t$ 之后的输出。因为我们需要想一个办法,把$ t$ 之后的信**息给隐藏起来**。
具体的做法:产生一个上三角矩阵,上三角的值全为 0。把这个矩阵作用在每个序列上,就可以达到我们的目的。
总结:对于 Decoder 的 Self-Attention,里面使用到的 scaled dot-product attention,同时需要 Padding Mask 和 Sequence Mask,具体实现就是两个 Mask 相加。其他情况下,只需要 Padding Mask。
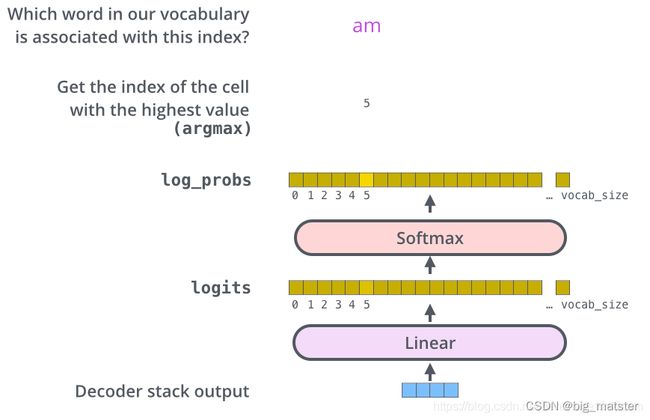
最后线性层和Softmax层
解码器栈的输出是一个 f l o a t float float向量,我们怎么把这个向量转换为一个词呢?通过一个线性层再加上一个 Softmax 层实现。
线性层是一个简单的全连接神经网络,其将解码器栈的输出向量映射到一个更长的向量,这个向量被称为 l o g i t s logits logits 向量。
现在假设我们的模型有 10000 个英文单词(模型的输出词汇表)。因此$ logits$ 向量有 10000 个数字,每个数表示一个单词的分数。
然后,Softmax会把这些分数转化为概率,最后选择最高概率作为所对应的单词,作为这个时间步的输出。
嵌入层和最后的线性层
在Transformer论文中,提到一个细节:编码组件和解码组件中的嵌入层,以及最后的线性层共享权重矩阵。不过,在嵌入层中,会将这个共享权重矩阵乘以 m o d e l \sqrt{model} model
正则化操作
- Dropout操作,对编码器和解码器每个子层的输出都使用Dropout操作。
- Label Smoothing(标签平滑)
总结
通常存储数据都使用一种张量,能不能使用其他的数据结构来存储数据。慢慢地将其探索即可。
会自己进行运行,不断的了解各种transformer的各种变体,全部都将其研究透彻,研究完整,一切一切的都会好的样子。
总结
把前馈网络编程,卷积网络,当作一层,是不是更加清晰与了然。