K近邻算法的理论与基于python实现
KNN(K Nearest Neighbor)K近邻算法
-
- K近邻算法理论
-
- 注意事项
- 代码实现
K近邻算法理论
K近邻算法是一个有监督学习,需要提供有标签的样本进行训练,才能去预测新的样本。
K近邻算法,应该是最简单的一个机器学习算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。(这就类似于现实生活中少数服从多数的思想)
在训练集中找寻距离测试样本最近的K个样本。通过统计这K个样本的类别,来判断测试样本的类别
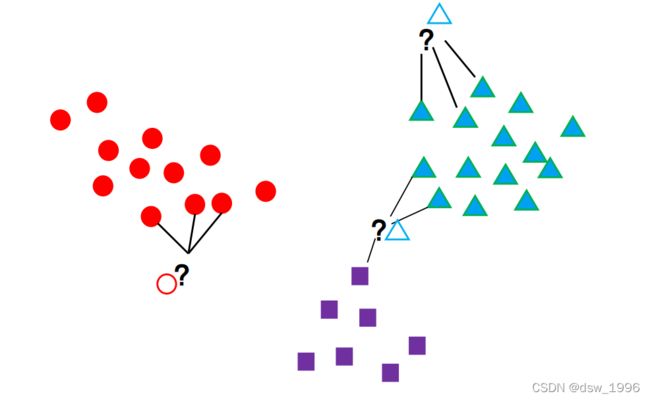
如图所示,先已有三簇带有标签的数据,现在来了几个新的数据,这些数据的标签未知,k近邻算法的思想就是,选择离我当前样本最近的k个样本,选取k个样本中数量最多的样本标签作为我当前样本的标签。
图中的k=3,即当一个新的样本输入进来后,选择与当前样本最近的三个样本,选择这三个样本中数量最多的样本标签作为该样本的标签。
这里的距离度量使用最简单的欧式距离,即设point1(x1,y1), point2(x2,y2):
point1 和 point2 之间的距离 R = ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 R = \sqrt{(x_1-x_2)^2 + (y_1-y_2)^2} R=(x1−x2)2+(y1−y2)2
注意事项
K值得选取对模型的训练和结果的准确性有着很重要的影响,k选取得太小会导致模型的复杂性升高,训练模型过拟合,例如当k=1时,每次只会判断离它最近得一个点,计算的复杂性升高,而且噪声得干扰性也会升高,导致模型过拟合;当k值选取得很大时,模型得表达能力又会减弱,如果k取得很大,就相当于在统计当前总样本中哪个标签得数量最多,然后赋给新的标签,这就没有任何意义了,模型过于欠拟合。
样本数据需要做标准化和归一化,消除不同量纲之间的影响。比如一组数据集统计的是你的年龄和收入,年龄的取值一般只会在1-100,而工资的取值在1-50000可能更多,此时如果直接去算欧式距离,那么年龄对距离的影响微乎其微,距离完全就取决于收入的差距,这不是我们想要的结果,就需要对这两组数据做标准化和归一化,标准化和归一化的公式这里不列举。
下面的demo假设是在同一量纲下的数据,仅仅为了演示k近邻算法的工作流程
代码实现
导入需要使用的包
import numpy as np
import operator
knn算法的定义
'''
trainData - 训练集 N
testData - 测试 1
labels - 训练集标签
'''
def knn(trainData, testData, labels, k):
# 计算训练样本的行数
rowSize = trainData.shape[0]
# 计算训练样本和测试样本的差值
diff = np.tile(testData, (rowSize, 1)) - trainData
# 计算差值的平方和
sqrDiff = diff ** 2
sqrDiffSum = sqrDiff.sum(axis=1)
# 计算距离
distances = sqrDiffSum ** 0.5
# 对所得的距离从低到高进行排序
sortDistance = distances.argsort()
count = {}
for i in range(k):
vote = labels[sortDistance[i]]
# print(vote)
count[vote] = count.get(vote, 0) + 1
# 对类别出现的频数从高到低进行排序
sortCount = sorted(count.items(), key=operator.itemgetter(1), reverse=True)
# 返回出现频数最高的类别
return sortCount[0][0]
加载数据集(用到的是鸢尾花的数据集,放到文章末尾)
def load_DataSet(data_path):
file_data = data_path
# 数据读取
data = np.loadtxt(file_data,dtype = float, delimiter = ',',usecols=(0,1,2,3))
lab = np.loadtxt(file_data,dtype = str, delimiter = ',',usecols=(4))
# 分为训练集和测试集和
N = 150
N_train = 100
N_test = 50
perm = np.random.permutation(N)
index_train = perm[:N_train]
index_test = perm[N_train:]
data_train = data[index_train,:]
lab_train = lab[index_train]
data_test = data[index_test,:]
lab_test = lab[index_test]
return data_train,lab_train,data_test,lab_test
主函数
if __name__ == '__main__':
# 参数设定
k= 5
n_right = 0
data_train,lab_train,data_test,lab_test = load_DataSet('iris.data')
for i in range(N_test):
test = data_test[i,:]
det = knn(data_train, test, lab_train, k)
if det == lab_test[i]:
n_right = n_right+1
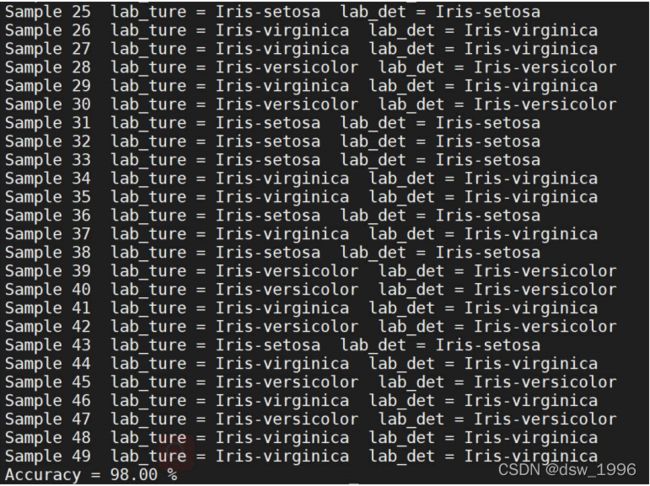
print('Sample %d lab_ture = %s lab_det = %s'%(i,lab_test[i],det))
# 结果分析
print('Accuracy = %.2f %%'%(n_right*100/N_test))
运行结果
数据集:(直接复制内容,放到和当前py文件的同级目录下,命名为iris.data)
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
5.4,3.9,1.7,0.4,Iris-setosa
4.6,3.4,1.4,0.3,Iris-setosa
5.0,3.4,1.5,0.2,Iris-setosa
4.4,2.9,1.4,0.2,Iris-setosa
4.9,3.1,1.5,0.1,Iris-setosa
5.4,3.7,1.5,0.2,Iris-setosa
4.8,3.4,1.6,0.2,Iris-setosa
4.8,3.0,1.4,0.1,Iris-setosa
4.3,3.0,1.1,0.1,Iris-setosa
5.8,4.0,1.2,0.2,Iris-setosa
5.7,4.4,1.5,0.4,Iris-setosa
5.4,3.9,1.3,0.4,Iris-setosa
5.1,3.5,1.4,0.3,Iris-setosa
5.7,3.8,1.7,0.3,Iris-setosa
5.1,3.8,1.5,0.3,Iris-setosa
5.4,3.4,1.7,0.2,Iris-setosa
5.1,3.7,1.5,0.4,Iris-setosa
4.6,3.6,1.0,0.2,Iris-setosa
5.1,3.3,1.7,0.5,Iris-setosa
4.8,3.4,1.9,0.2,Iris-setosa
5.0,3.0,1.6,0.2,Iris-setosa
5.0,3.4,1.6,0.4,Iris-setosa
5.2,3.5,1.5,0.2,Iris-setosa
5.2,3.4,1.4,0.2,Iris-setosa
4.7,3.2,1.6,0.2,Iris-setosa
4.8,3.1,1.6,0.2,Iris-setosa
5.4,3.4,1.5,0.4,Iris-setosa
5.2,4.1,1.5,0.1,Iris-setosa
5.5,4.2,1.4,0.2,Iris-setosa
4.9,3.1,1.5,0.1,Iris-setosa
5.0,3.2,1.2,0.2,Iris-setosa
5.5,3.5,1.3,0.2,Iris-setosa
4.9,3.1,1.5,0.1,Iris-setosa
4.4,3.0,1.3,0.2,Iris-setosa
5.1,3.4,1.5,0.2,Iris-setosa
5.0,3.5,1.3,0.3,Iris-setosa
4.5,2.3,1.3,0.3,Iris-setosa
4.4,3.2,1.3,0.2,Iris-setosa
5.0,3.5,1.6,0.6,Iris-setosa
5.1,3.8,1.9,0.4,Iris-setosa
4.8,3.0,1.4,0.3,Iris-setosa
5.1,3.8,1.6,0.2,Iris-setosa
4.6,3.2,1.4,0.2,Iris-setosa
5.3,3.7,1.5,0.2,Iris-setosa
5.0,3.3,1.4,0.2,Iris-setosa
7.0,3.2,4.7,1.4,Iris-versicolor
6.4,3.2,4.5,1.5,Iris-versicolor
6.9,3.1,4.9,1.5,Iris-versicolor
5.5,2.3,4.0,1.3,Iris-versicolor
6.5,2.8,4.6,1.5,Iris-versicolor
5.7,2.8,4.5,1.3,Iris-versicolor
6.3,3.3,4.7,1.6,Iris-versicolor
4.9,2.4,3.3,1.0,Iris-versicolor
6.6,2.9,4.6,1.3,Iris-versicolor
5.2,2.7,3.9,1.4,Iris-versicolor
5.0,2.0,3.5,1.0,Iris-versicolor
5.9,3.0,4.2,1.5,Iris-versicolor
6.0,2.2,4.0,1.0,Iris-versicolor
6.1,2.9,4.7,1.4,Iris-versicolor
5.6,2.9,3.6,1.3,Iris-versicolor
6.7,3.1,4.4,1.4,Iris-versicolor
5.6,3.0,4.5,1.5,Iris-versicolor
5.8,2.7,4.1,1.0,Iris-versicolor
6.2,2.2,4.5,1.5,Iris-versicolor
5.6,2.5,3.9,1.1,Iris-versicolor
5.9,3.2,4.8,1.8,Iris-versicolor
6.1,2.8,4.0,1.3,Iris-versicolor
6.3,2.5,4.9,1.5,Iris-versicolor
6.1,2.8,4.7,1.2,Iris-versicolor
6.4,2.9,4.3,1.3,Iris-versicolor
6.6,3.0,4.4,1.4,Iris-versicolor
6.8,2.8,4.8,1.4,Iris-versicolor
6.7,3.0,5.0,1.7,Iris-versicolor
6.0,2.9,4.5,1.5,Iris-versicolor
5.7,2.6,3.5,1.0,Iris-versicolor
5.5,2.4,3.8,1.1,Iris-versicolor
5.5,2.4,3.7,1.0,Iris-versicolor
5.8,2.7,3.9,1.2,Iris-versicolor
6.0,2.7,5.1,1.6,Iris-versicolor
5.4,3.0,4.5,1.5,Iris-versicolor
6.0,3.4,4.5,1.6,Iris-versicolor
6.7,3.1,4.7,1.5,Iris-versicolor
6.3,2.3,4.4,1.3,Iris-versicolor
5.6,3.0,4.1,1.3,Iris-versicolor
5.5,2.5,4.0,1.3,Iris-versicolor
5.5,2.6,4.4,1.2,Iris-versicolor
6.1,3.0,4.6,1.4,Iris-versicolor
5.8,2.6,4.0,1.2,Iris-versicolor
5.0,2.3,3.3,1.0,Iris-versicolor
5.6,2.7,4.2,1.3,Iris-versicolor
5.7,3.0,4.2,1.2,Iris-versicolor
5.7,2.9,4.2,1.3,Iris-versicolor
6.2,2.9,4.3,1.3,Iris-versicolor
5.1,2.5,3.0,1.1,Iris-versicolor
5.7,2.8,4.1,1.3,Iris-versicolor
6.3,3.3,6.0,2.5,Iris-virginica
5.8,2.7,5.1,1.9,Iris-virginica
7.1,3.0,5.9,2.1,Iris-virginica
6.3,2.9,5.6,1.8,Iris-virginica
6.5,3.0,5.8,2.2,Iris-virginica
7.6,3.0,6.6,2.1,Iris-virginica
4.9,2.5,4.5,1.7,Iris-virginica
7.3,2.9,6.3,1.8,Iris-virginica
6.7,2.5,5.8,1.8,Iris-virginica
7.2,3.6,6.1,2.5,Iris-virginica
6.5,3.2,5.1,2.0,Iris-virginica
6.4,2.7,5.3,1.9,Iris-virginica
6.8,3.0,5.5,2.1,Iris-virginica
5.7,2.5,5.0,2.0,Iris-virginica
5.8,2.8,5.1,2.4,Iris-virginica
6.4,3.2,5.3,2.3,Iris-virginica
6.5,3.0,5.5,1.8,Iris-virginica
7.7,3.8,6.7,2.2,Iris-virginica
7.7,2.6,6.9,2.3,Iris-virginica
6.0,2.2,5.0,1.5,Iris-virginica
6.9,3.2,5.7,2.3,Iris-virginica
5.6,2.8,4.9,2.0,Iris-virginica
7.7,2.8,6.7,2.0,Iris-virginica
6.3,2.7,4.9,1.8,Iris-virginica
6.7,3.3,5.7,2.1,Iris-virginica
7.2,3.2,6.0,1.8,Iris-virginica
6.2,2.8,4.8,1.8,Iris-virginica
6.1,3.0,4.9,1.8,Iris-virginica
6.4,2.8,5.6,2.1,Iris-virginica
7.2,3.0,5.8,1.6,Iris-virginica
7.4,2.8,6.1,1.9,Iris-virginica
7.9,3.8,6.4,2.0,Iris-virginica
6.4,2.8,5.6,2.2,Iris-virginica
6.3,2.8,5.1,1.5,Iris-virginica
6.1,2.6,5.6,1.4,Iris-virginica
7.7,3.0,6.1,2.3,Iris-virginica
6.3,3.4,5.6,2.4,Iris-virginica
6.4,3.1,5.5,1.8,Iris-virginica
6.0,3.0,4.8,1.8,Iris-virginica
6.9,3.1,5.4,2.1,Iris-virginica
6.7,3.1,5.6,2.4,Iris-virginica
6.9,3.1,5.1,2.3,Iris-virginica
5.8,2.7,5.1,1.9,Iris-virginica
6.8,3.2,5.9,2.3,Iris-virginica
6.7,3.3,5.7,2.5,Iris-virginica
6.7,3.0,5.2,2.3,Iris-virginica
6.3,2.5,5.0,1.9,Iris-virginica
6.5,3.0,5.2,2.0,Iris-virginica
6.2,3.4,5.4,2.3,Iris-virginica
5.9,3.0,5.1,1.8,Iris-virginica