Week1云计算从0到1学习-感谢公司给我这个机会
第一次接触云计算,小白打卡。熟悉公司的shell脚本,深入学习。不懂的东西就去百度。倒叙查看文档内容,即按照周维度最新的学习内容写在最上方
week2学习笔记见最新博客 Week2云计算从0到1学习
Week1 Q&A
Q1:K8S为啥要引入pod这么个概念呢?
Kubernetes (请教了专业人士,为啥叫k8s,因为k和s中间是8个字母,并不是音译)是用来管理容器集群的平台。既然是管理集群,那么就存在被管理节点,针对每个 Kubernetes集群都由一个 Master 负责管理和控制集群节点
我们通过 Master 对每个节点 Node 发送命令。简单来说,Master 就是管理者,Node 就是被管理者
Node 可以是一台机器或者一台虚拟机。在 Node 上面可以运行多个 Pod,Pod 是 Kubernetes 管理的最小单位,同时每个 Pod 可以包含多个容器(Docker)
综上:pod—k8s调度的最小单元。可管理性,有些容器天生需要紧密关联,以pod为最小单位进行调度 扩展 共享资源 管理生命周期。通信和资源共享 相同的namespace 可以用localhost通信 可以共享存储,挂载vol到pod 本质是挂载vol到pod的每一个容器
参考博客 https://blog.csdn.net/stephen_curry11/article/details/106138857
Q2:比起独立的一个个container,pod额外解决了什么问题?
Container : 容器。k8s是容器管理平台,Docker,mysql ,tomcat
Pod : 一组Container的集合,是k8s中最小的执行单元
ReplicaSet : 用于指定每个Pod的备份数量。k8s,分布式架构。ReplicaSet就是用来管理Pod备份数量,保证高可靠性的组件
Service : 用于各种信息的抽象
**Label **: 每个Pod的唯一标识符,信息会存在etcd数据库中
kubelet : 每个node节点都有一个,用于启动、管理和监测各个node中Pod。k8s会将所有的容器信息记录在etcd数据库中
kube-proxy : 在k8s中,每个node都用自己的一个IP地址。而kube-proxy就是负责每个node与其他node或Matser节点通信的枢纽。信息的流入和流出、请求的转发都是通过kube-proxy进行操作的
默认情况下,每个容器的文件系统与其他容器完全隔离
可以理解为:容器组,同时pod相当于逻辑主机,进入pod后仿佛进入一个linux主机,命令都可用(linux系统下),该“主机”内又有很多容器,进入后又仿佛是又进了一个linux主机
pod作用:调度 扩展 共享资源。container是个独立的资源,无法高效的进行集群化部署
一个container只会存在一个pod中,一个container不能同时存在于多个pod中
拿豌豆荚举例来说,container就是一个个的豆子,一个pod的就是一个豌豆夹,相似的豆子们或者同类的豆子们放在一个夹子里边,同一个豆子是不可能同时存在于两个夹子里的,可以理解为它具备独立唯一性
可以将pod理解为多个container的集合,这些container是有一定共性的,container可以同时使用一个pod的公共组件,将类似的container编排在一个pod中会好管理一些,同时也节省资源。
Q3:CPU为啥要区分用户态和内核态,是为了解决什么问题呢?
避免代码进行潜在危险的操作,以防止给操作系统带来安全隐患。系统调用与返回的情况下进行两种方式的转换。
用户态状态下,执行的代码被硬件限定,不能进行某些操作,比如写入其他进程的存储空间,以防止给操作系统带来安全隐患。内核禁止此状态下的代码进行潜在危险的操作,比如写入系统配置文件、杀掉其他用户的进程、重启系统等。
当一个任务(进程)执行系统调用而陷入内核代码中执行时,我们就称进程处于内核运行态(或简称为内核态)。此时处理器处于特权级最高的(0 级)内核代码中执行。
拓展资料:
在CPU的所有指令中,有些指令是非常危险的,如果错用,将导致系统崩溃,比如清内存、设置时钟等。
如果所有的程序都能使用这些指令,那么系统死机的概率将大大增加。
所以,CPU将指令分为特权指令和非特权指令,对于那些危险的指令,只允许操作系统及其相关模块使用,普通应用程序只能使用那些不会造成灾难的指令。
Intel的CPU将特权等级分为4个级别:Ring0~Ring3
Linux使用Ring3级别运行用户态,Ring0作为内核态。
Linux的内核是一个有机整体,每个用户进程运行时都好像有一份内核的拷贝。每当用户进程使用系统调用时,都自动地将运行模式从用户级转为内核级(成为陷入内核),此时,进程在内核的地址空间中运行。
从用户空间到内核空间有以下触发手段:
1.系统调用:用户进程通过系统调用申请使用操作系统提供的服务程序来完成工作,比如read()、fork()等。系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现的。
2.中断:当外围设备完成用户请求的操作后,会想CPU发送中断信号。这时CPU会暂停执行下一条指令(用户态)转而执行与该中断信号对应的中断处理程序(内核态)
3.异常:当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
-
week1学习
CPU
中央处理器(central processing unit,简称CPU)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元
CPU的主频,即CPU内核工作的时钟频率(CPU Clock Speed)。通常所说的某某CPU是多少兆赫的,而这个多少兆赫就是“CPU的主频”
性能衡量指标:对于CPU而言,影响其性能的指标主要有主频、 CPU的位数、CPU的缓存指令集、CPU核心数和IPC(每周期指令数)。所谓CPU的主频,指的就是时钟频率,它直接的决定了CPU的性能,可以通过超频来提高CPU主频来获得更高性能。CPU 的缓存可以分为一级缓存、二级缓存和三级缓存,缓存性能直接影响CPU处理性能。部分特殊职能的CPU可能会配备四级缓存
内核态
内核态:cpu可以访问内存的所有数据,包括外围设备,例如硬盘,网卡,cpu也可以将自己从一个程序切换到另一个程序
他们的工作流程如下:
-
用户态程序将一些数据值放在寄存器中, 或者使用参数创建一个堆栈(stack frame), 以此表明需要操作系统提供的服务.
-
用户态程序执行陷阱指令
-
CPU切换到内核态, 并跳到位于内存指定位置的指令, 这些指令是操作系统的一部分, 他们具有内存保护, 不可被用户态程序访问
-
这些指令称之为陷阱(trap)或者系统调用处理器(system call handler) 他们会读取程序放入内存的数据参数, 并执行程序请求的服务
-
系统调用完成后, 操作系统会重置CPU为用户态并返回系统调用的结果
当一个任务(进程)执行系统调用而陷入内核代码中执行时,我们就称进程处于内核运行态(或简称为内核态)。此时处理器处于特权级最高的(0级)内核代码中执行。当进程处于内核态时,执行的内核代码会使用当前进程的内核栈。每个进程都有自己的内核栈。当进程在执行用户自己的代码时,则称其处于用户运行态(用户态)。即此时处理器在特权级最低的(3级)用户代码中运行。当正在执行用户程序而突然被中断程序中断时,此时用户程序也可以象征性地称为处于进程的内核态。因为中断处理程序将使用当前进程的内核栈。这与处于内核态的进程的状态有些类似
内存
内存(Memory)也称内存储器和主存储器,它用于暂时存放CPU中的运算数据,与硬盘等外部存储器交换的数据
只要计算机开始运行,操作系统就会把需要运算的数据从内存调到CPU中进行运算。当运算完成,CPU将结果传送出来
通常,我们把要永久保存、大量数据存储在外存上,把一些临时或少量的数据和程序放在内存上。当然,内存的好坏会直接影响电脑的运行速度
内存是暂时存储程序以及数据的地方。当我们使用WPS处理文稿时,当你在键盘上敲入字符时,它被存入内存中。当你选择存盘时,内存中的数据才会被存入硬(磁)盘
存储
数据存储是数据流在加工过程中产生的临时文件或加工过程中需要查找的信息。数据以某种格式记录在计算机内部或外部存储媒介上
DAS(Direct Attached Storage)直接附加存储
NAS(Network Attached Storage)网络附加存储
SAN(Storage Area Network)存储区域网络
云存储
云存储是一种网上在线存储(英语:Cloud storage)的模式,即把数据存放在通常由第三方托管的多台虚拟服务器,而非专属的服务器上。托管(hosting)公司运营大型的数据中心,需要数据存储托管的人,则透过向其购买或租赁存储空间的方式,来满足数据存储的需求。数据中心营运商根据客户的需求,在后端准备存储虚拟化的资源,并将其以存储资源池(storage pool)的方式提供,客户便可自行使用此存储资源池来存放文件或对象。实际上,这些资源可能被分布在众多的服务器主机上
PEM文件是用于对安全网站进行身份验证的Base64编码的证书文件,它可能包含私钥、证书颁发机构(CA)服务器证书或组成信任链的其他各种证书。PEM文件通常从基于Linux的Apache或Nginx Web服务器中导入,并且与OpenSSL应用程序兼容
CA根证书(--cacert):用来验证的网站证书是否是CA颁布
Docker是应用最为广泛的容器技术,通过打包镜像,启动容器来创建一个服务。但是随着应用越来越复杂,容器的数量也越来越多,由此衍生了管理运维容器的重大问题,而且随着云计算的发展,云端最大的挑战,容器在漂移
pod
Pod就是一组容器的集合,在Pod里面的容器共享网络/存储(Kubernetes实现共享一组的Namespace去替代每个container各自的NS,来实现这种能力),所以它们可以通过Localhost进行内部的通信。虽然网络存储都是共享的,但是CPU和Memory就不是。多容器之间可以有属于自己的Cgroup,也就是说我们可以单独的对Pod中的容器做资源(MEM/CPU)使用的限制。
Pod是一个或一个以上的 容器(例如Docker容器)组成的,且具有共享存储/网络/UTS/PID的能力,以及运行容器的规范。并且在Kubernetes中,Pod是最小的可被调度的原子单位。
Kubernetes提供了两种模式来让我们设置,一种是request,另一种是limits。前面也说了,我们Pod中的每个容器都有单独的Cgroup。所以我们根据需要针对每个容器都要做限制。
如下所示:
- resource:
- requests:
- cpu: "200m"
- memory: "500Mi"
- limmits:
- cpu: "2000m"
- memory: "2Gi"
- requests:它是一种硬性要求,就是这个容器必须调度到能满足要求的Node节点上。Kubernetes schedule在调度时,会检查Node上的资源,判断是否可以被调度。即如果满足200m CPU、500M的内存,那么该容器就有可能调度到该节点上。反之则不会
- limits:limits限制了该容器在运行时可以使用的最大资源值。即如果该容器使用了2G的内存,理论上kubelet会终止该容器。并重新启动。Tips:oom会根据一个算法,为每个进程打出一个分数,杀死分数最高的(印象里oom机制是这样的)
Pod存储(Volume)
用途:
- 同一pod中不同容器之间的同步共享卷
- Cache缓存一些请求的应用数据,方便下次用户存取
- 持久化数据,如db
- 挂载主机文件系统,如跟随主机时区、主机信息、日志收集
什么是K8s
k8s全称kubernetes,这个名字大家应该都不陌生,k8s是为容器服务而生的一个可移植容器的编排管理工具,越来越多的公司正在拥抱k8s,并且当前k8s已经主导了云业务流程,推动了微服务架构等热门技术的普及和落地,正在如火如荼的发展。那么称霸容器领域的k8s究竟是有什么魔力呢?
首先,我们从容器技术谈起,在容器技术之前,大家开发用虚拟机比较多,比如vmware和openstack,我们可以使用虚拟机在我们的操作系统中模拟出多台子电脑(Linux),子电脑之间是相互隔离的,但是虚拟机对于开发和运维人员而言,存在启动慢,占用空间大,不易迁移的缺点
Kubernetes可以做什么?
使用Web服务,用户希望应用程序能够7*24小时全天运行,开发人员希望每天多次部署新的应用版本。通过应用容器化可以实现这些目标,使应用简单、快捷的方式更新和发布,也能实现热更新、迁移等操作。使用Kubernetes能确保程序在任何时间、任何地方运行,还能扩展更多有需求的工具/资源。Kubernetes积累了Google在容器化应用业务方面的经验,以及社区成员的实践,是能在生产环境使用的开源平台。
- 服务发现与调度
- 负载均衡
- 服务自愈
- 服务弹性扩容
- 横向扩容
- 存储卷挂载
- 在集群上部署容器化应用
- 集群规模化部署
- 更新容器化应用的版本
- 调试容器化应用
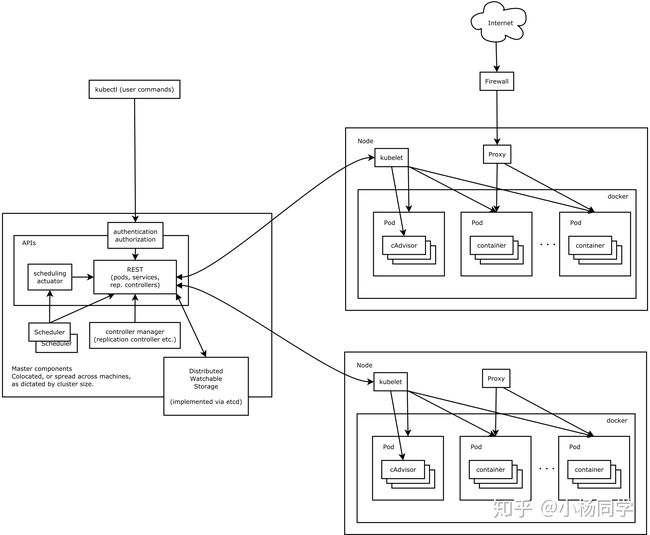
k8s集群由Master节点和Node(Worker)节点组成。
Master节点
Master节点指的是集群控制节点,管理和控制整个集群,基本上k8s的所有控制命令都发给它,它负责具体的执行过程。在Master上主要运行着:
- Kubernetes Controller Manager(kube-controller-manager):k8s中所有资源对象的自动化控制中心,维护管理集群的状态,比如故障检测,自动扩展,滚动更新等。
- Kubernetes Scheduler(kube-scheduler): 负责资源调度,按照预定的调度策略将Pod调度到相应的机器上。
- etcd:保存整个集群的状态。
Node节点
除了master以外的节点被称为Node或者Worker节点,可以在master中使用命令 kubectl get nodes查看集群中的node节点。每个Node都会被Master分配一些工作负载(Docker容器),当某个Node宕机时,该节点上的工作负载就会被Master自动转移到其它节点上。在Node上主要运行着:
K8S集群tls证书管理
1. 根证书
ca.pem 根证书公钥文件
ca-key.pem 根证书私钥文件
ca.csr 证书签名请求,用于交叉签名或重新签名
ca-config.json 使用cfssl工具生成其他类型证书需要引用的配置文件
ca.pem用于签发后续其他的证书文件,因此ca.pem文件需要分发到集群中的每台服务器上去。
证书生成命令,有效期5年
# echo '{"CN":"CA","key":{"algo":"rsa","size":2048}}' | cfssl gencert -initca - | cfssljson -bare ca -
# echo '{"signing":{"default":{"expiry":"43800h","usages":["signing","key encipherment","server auth","client auth"]}}}' > ca-config.json
2. flannel证书
证书生成命令,默认生成的证书有效期5年
# cfssl gencert -ca=/etc/ssl/etcd/ca.pem \
-ca-key=/etc/ssl/etcd/ca-key.pem \
-config=/etc/ssl/etcd/ca-config.json \
-profile=kubernetes flanneld-csr.json | cfssljson -bare flanneld
3. etcd证书
3.1服务端证书
server.pem etcd服务端证书公钥文件
server-key.pem etcd服务端证书私钥文件
server.csr 证书签名请求
3.2客户端证书
client.pem etcd客户端证书公钥文件
client-key.pem etcd客户端证书私钥文件
client.csr 证书签名请求
client.pem、client-key.pem文件给etcdctl客户端用来和etcd服务器进行通信,可根据实际需要进行配置。
4. Master节点证书
Kube-apiserver证书
Kubernetes.pem kube-apiserver证书公钥文件
Kubernetes-key.pem kube-apiserver证书私钥文件
kuberentes.csr kube-apiserver证书签名请求
5. Node节点证书
5.1 kube-proxy证书
Kube-proxy.pem kube-proxy证书公钥文件
Kube-proxy-key.pem kube-proxy证书私钥文件
Kube-proxy.csr kube-proxy证书签名请求
5.2 Kubelet证书
Kubelet-client.crt: kubectl客户端证书公钥文件
Kubelet-client.key: kubectl客户端私钥文件
Kubelet.crt:kubelet服务端证书公钥文件
Kubelet.key:kubelet服务端证书私钥文件
kubelet
kubelet 是在每个 Node 节点上运行的主要 “节点代理”。它可以使用以下之一向 apiserver 注册: 主机名(hostname);覆盖主机名的参数;某云驱动的特定逻辑
Kubelet组件运行在Node节点上,维持运行中的Pods以及提供kuberntes运行时环境,主要完成以下使命:
1.监视分配给该Node节点的pods
2.挂载pod所需要的volumes
3.下载pod的secret
4.通过docker/rkt来运行pod中的容器
5.周期的执行pod中为容器定义的liveness探针
6.上报pod的状态给系统的其他组件
7.上报Node的状态
etcd灾难恢复
etcd 被设计为能承受机器失败。etcd 集群自动从临时失败(例如,机器重启)中恢复,而且对于一个有 N 个成员的集群能容许 (N-1)/2 的持续失败。当一个成员持续失败时,不管是因为硬件失败或者磁盘损坏,它丢失到集群的访问。如果集群持续丢失超过 (N-1)/2 的成员,则它只能悲惨的失败,无可救药的失去法定人数(quorum)。一旦法定人数丢失,集群无法达到一致而因此无法继续接收更新。
为了从灾难失败中恢复,其中etcd v3 提供快照和修复工具来重建集群而不丢失 v3 键数据
待续。。。