Spark学习---7、Spark内核(源码提交流程、任务执行、Shuffle、内存管理)
这是本人的学习过程,看到的同道中人祝福你们心若有所向往,何惧道阻且长;
但愿每一个人都像星星一样安详而从容的,不断沿着既定的目标走完自己的路程;
最后想说一句君子不隐其短,不知则问,不能则学。
如果大家觉得我写的还不错的话希望可以收获关注、点赞、收藏(谢谢大家)
文章目录
- 一、源码全流程
-
- 1.1 Spark提交流程(YarnCluster)
- 1.2 Spark通讯架构
- 1.3 Spark任务划分
- 1.4 任务调度
- 1.5 Shuffle原理
- 二、环境准备及提交流程
-
- 2.1 程序起点
- 2.2 Spark组件通信
-
- 2.2.1 Spark中通信框架的发展
- 1.2.2 三种通信方式
- 2.2.3 Spark底层通信原理
- 3、任务的执行
-
- 3.1 概述
-
- 3.1.1 任务切分和任务调度原理
- 3.1.2 本地化调度
- 3.1.3 失败重试与黑名单机制
- 4、Shuffle
-
- 4.1 Shuffle的原理和执行过程
- 4.2 HashShuffle解析
-
- 4.2.1 未优化的HashShuffle
- 4.2.2 优化后的HashShuffle
- 4.3 SortShuffle解析
-
- 4.3.1 SortShuffle解析
- 4.3.2 bypassShuffle
- 5、Spark内存管理
-
- 5.1 堆内和堆外内存
-
- 5.1.1 概念
- 5.1.2 堆内内存和堆外内存优缺点
- 5.1.3 如何配置
- 5.2 堆内内存空间分配
-
- 5.2.1 静态内存管理
- 5.2.2 统一内存管理
- 5.3 储存内存管理
-
- 5.3.1 RDD持久化机制
- 5.3.2 淘汰与落盘
- 5.4 执行内存管理
一、源码全流程
1.1 Spark提交流程(YarnCluster)
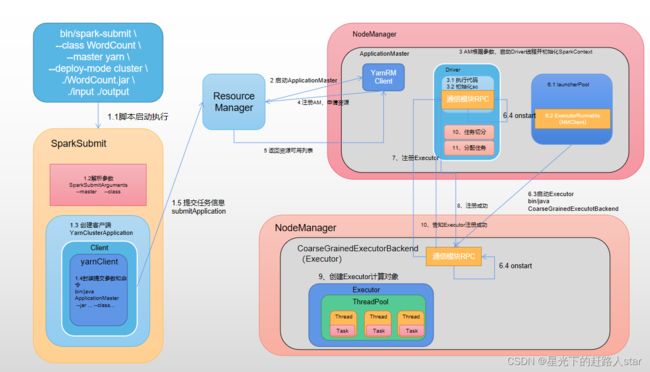
1.2 Spark通讯架构

1.3 Spark任务划分

1.4 任务调度
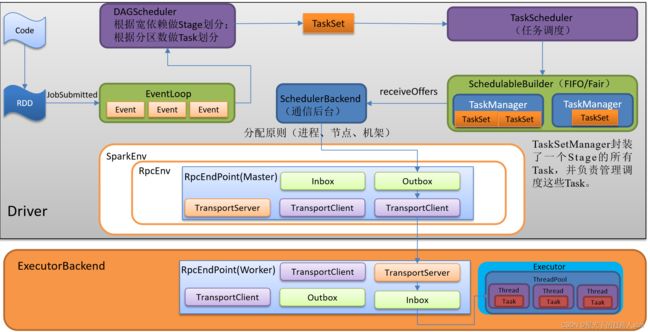
1.5 Shuffle原理
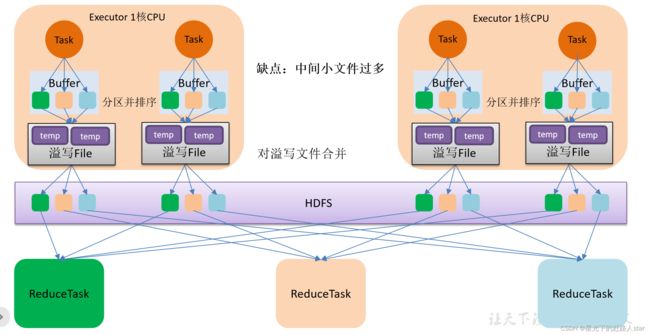
1、HashShuffle流程
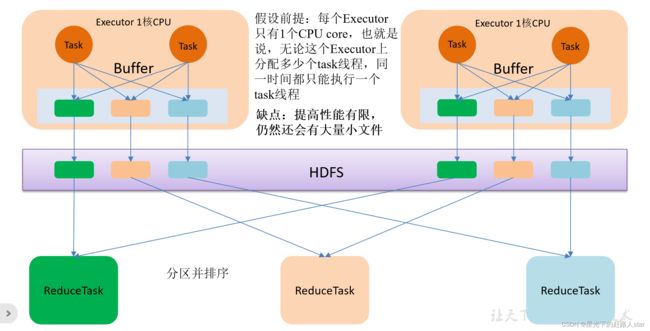
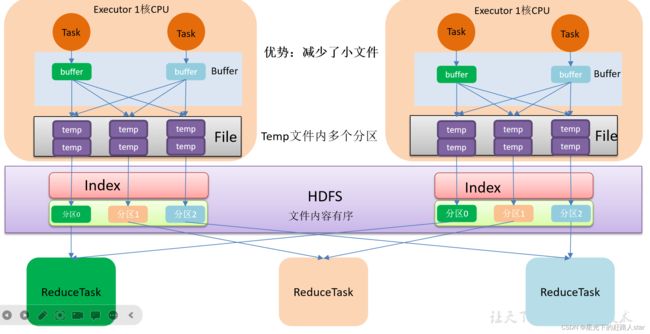
2、优化后的HashShuffle流程(共用Buffer)
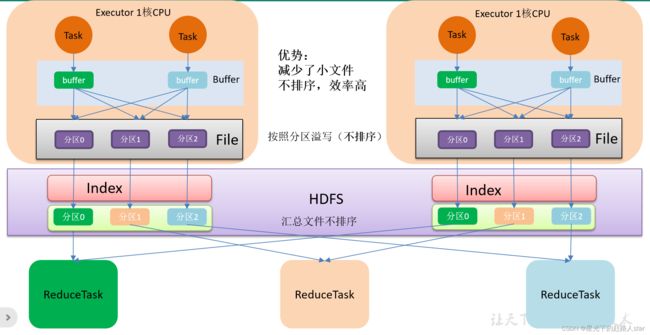
3、SortShuffle流程
4、bypassShuffle流程
二、环境准备及提交流程
2.1 程序起点
1、spark-3.3.0-bin-hadoop3\bin\spark-submit.cmd
=> cmd /V /E /C “”%~dp0spark-submit2.cmd" %"
2、spark-submit2.cmd
=> set CLASS=org.apache.spark.deploy.SparkSubmit
“%~dp0spark-class2.cmd” %CLASS% %
3、spark-class2.cmd
=> %SPARK_CMD%
4、在spark-class2.cmd文件中增加打印%SPARK_CMD%语句
echo %SPARK_CMD%
%SPARK_CMD%
5、在spark-3.3.0-bin-hadoop3\bin目录上执行cmd命令
6、进入命令行窗口,输入
spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ./examples/jars/spark-examples_2.12-3.3.0.jar 10
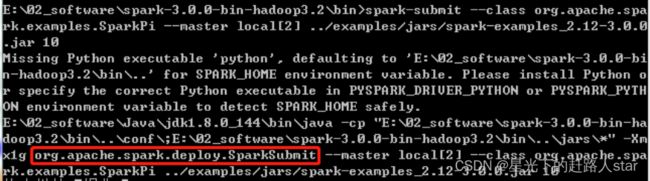
7、发现底层执行的命令为
java -cp org.apache.spark.deploy.SparkSubmit
说明:java -cp和 -classpath一样,是指定类运行所依赖其他类的路径。
8、执行java -cp 就会开启JVM虚拟机,在虚拟机上开启SparkSubmit进程,然后开始执行main方法
java -cp =》开启JVM虚拟机 =》开启Process(SparkSubmit)=》程序入口SparkSubmit.main
9、在IDEA中全局查找(ctrl + n):org.apache.spark.deploy.SparkSubmit,找到SparkSubmit的伴生对象,并找到main方法
override def main(args: Array[String]): Unit = {
val submit = new SparkSubmit() {
... ...
}
}
2.2 Spark组件通信
2.2.1 Spark中通信框架的发展
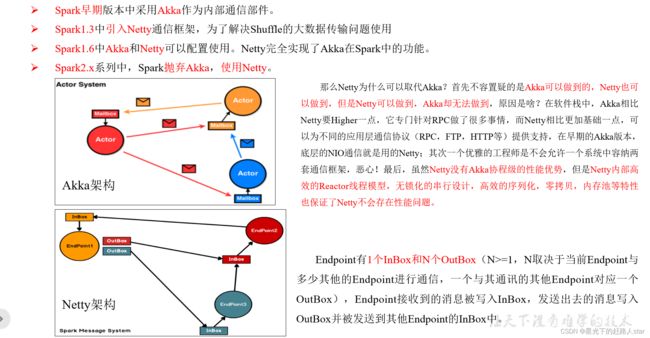
1.2.2 三种通信方式
1、三种通信方式
BIO:阻塞式IO Spark底层采用Netty
NIO:非阻塞式IO Netty:支持NIO和Epoll模式
AIO:异步非阻塞式IO 默认采用NIO
2、举例说明
比如去饭店吃饭,老板说你前面有四个人,需要等一会;
(1)如果你在桌子面前一直等着,就是阻塞式IO–BIO。
(2)如果你和老板说,饭先做着,我先去打篮球。在打篮球的过程中ing,时不时回来看一下饭是否做好,就是非阻塞式IO-NIO
(3)先给老板说,我去打篮球,一个小时后给我送到指定位置,就是异步非阻塞式-AIO。
3、注意:
Linux对AIO支持的不够好,Windows支持AIO很好
Linux采用Epoll方式模仿AIO
2.2.3 Spark底层通信原理
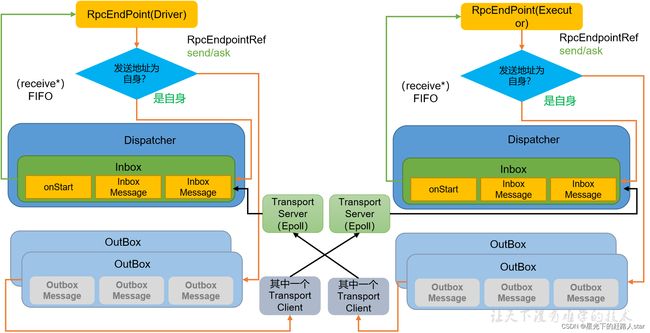
| 组件名 | 说明 |
|---|---|
| RpcEndpoint | RPC通信终端。Spark针对每个节点(Client/Master/Worker)都称之为一个RPC终端,且都实现RpcEndpoint接口,内部根据不同端点的需求,设计不同的消息和不同的业务处理,如果需要发送(询问)则调用Dispatcher。在Spark中,所有的终端都存在生命周期:Constructor =》onStart =》receive* =》onStop |
| RpcEnv | RPC上下文环境,每个RPC终端运行时依赖的上下文环境称为RpcEnv;在当前Spark版本中使用的NettyRpcEnv |
| Dispatcher | 消息调度(分发)器,针对于RPC终端需要发送远程消息或者从远程RPC接收到的消息,分发至对应的指令收件箱(发件箱)。如果指令接收方是自己则存入收件箱,如果指令接收方不是自己,则放入发件箱; |
| Inbox | 指令消息收件箱。一个本地RpcEndpoint对应一个收件箱,Dispatcher在每次向Inbox存入消息时,都将对应EndpointData加入内部ReceiverQueue中,另外Dispatcher创建时会启动一个单独线程进行轮询ReceiverQueue,进行收件箱消息消费; |
| RpcEndpointRef | RpcEndpointRef是对远程RpcEndpoint的一个引用。当我们需要向一个具体的RpcEndpoint发送消息时,一般我们需要获取到该RpcEndpoint的引用,然后通过该应用发送消息。 |
| OutBox | 指令消息发件箱。对于当前RpcEndpoint来说,一个目标RpcEndpoint对应一个发件箱,如果向多个目标RpcEndpoint发送信息,则有多个OutBox。当消息放入Outbox后,紧接着通过TransportClient将消息发送出去。消息放入发件箱以及发送过程是在同一个线程中进行; |
| RpcAddress | 表示远程的RpcEndpointRef的地址,Host + Port。 |
| TransportClient | Netty通信客户端,一个OutBox对应一个TransportClient,TransportClient不断轮询OutBox,根据OutBox消息的receiver信息,请求对应的远程TransportServer; |
| TransportServer | Netty通信服务端,一个RpcEndpoint对应一个TransportServer,接受远程消息后调用Dispatcher分发消息至对应收发件箱; |
3、任务的执行
3.1 概述
3.1.1 任务切分和任务调度原理
任务切分
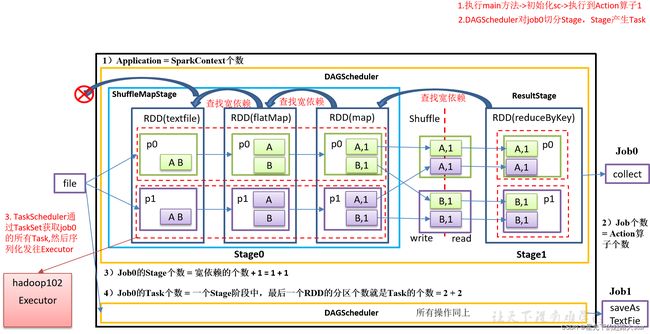
任务调度
3.1.2 本地化调度
任务分配原则:根据每个Task的优先位置,确定Task的Locality(本地化)级别,本地化一共有五种,优先级由高到低的顺序。
移动数据不如移动计算。
| 名称 | 解析 |
|---|---|
| PROCESS_LOCAL | 进程本地化,task和数据在同一个Executor中,性能最好。 |
| NODE_LOCAL | 节点本地化,task和数据在同一个节点中,但是task和数据不在同一个Executor中,数据需要在进程间进行传输。 |
| RACK_LOCAL | 机架本地化,task和数据在同一个机架的两个节点上,数据需要通过网络在节点之间进行传输。 |
| NO_PREF | 对于task来说,从哪里获取都一样,没有好坏之分。 |
| ANY | task和数据可以在集群的任何地方,而且不在一个机架中,性能最差。 |
3.1.3 失败重试与黑名单机制
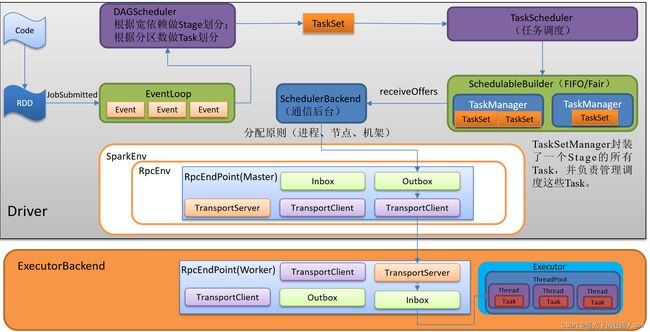
除了选择合适的Task调度运行外,还需要监控Task的执行状态,前面也提到过,与外部打交道的是SchedulerBackend,Task被提交到Executor启动执行后,Executor会将执行状态上报给SchedulerBackend,SchedulerBackend则告诉TaskScheduler,TaskScheduler找到该Task对应的TaskSetManager,并通知到该TaskSetManager,这样TaskSetManager就知道Task的失败与成功状态。
对于失败的Task,会记录它失败的次数,如果失败次数还没有超过最大重试次数,那么就把它放回待调度的Task池子中,否则整个Application失败。
在记录Task失败次数过程中,会记录它上一次失败所在的Executor和Host,这样下次再调度这个Task时,会使用黑名单机制,避免它被调度到上一次失败的节点上,起到一定的容错作用。黑名单记录Task上一次失败所在的ExecutorID和Host,以及其对应的“拉黑”时间,“拉黑”时间是指这段时间内不要再往这个节点上调度这个Task了。
4、Shuffle
Spark最初版本HashShuffle
Spark 0.8.1版本以后: 优化后的HashShuffle
Spark1.1版本: 加入SortShuffle,默认是HashShuffle
Spark1.2版本: 默认是SortShuffle,但是可配置HashShuffle
Spark2.0版本: 删除HashShuffle只有SortShuffle
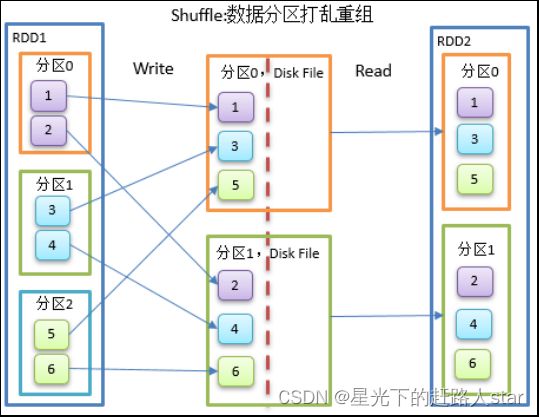
4.1 Shuffle的原理和执行过程
Shuffle一定会有落盘
1、如果Shuffle过程中落盘数据减少,那么可以提高性能。
2、算子如果存在预聚合功能,可以提高Shuffle的性能。
4.2 HashShuffle解析
4.2.1 未优化的HashShuffle
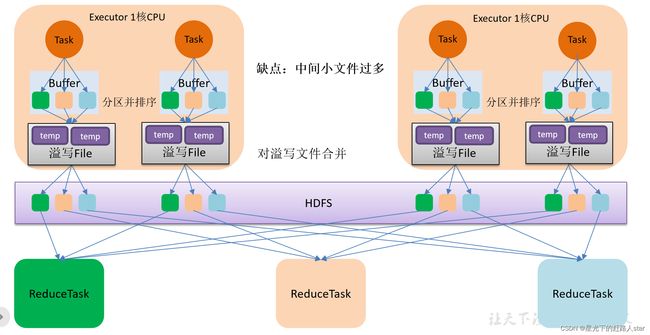
4.2.2 优化后的HashShuffle
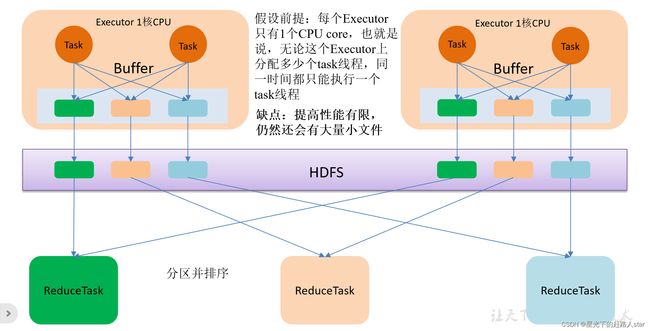
优化的HashShuffle过程就是启用合并机制,合并机制就是复用Buffer,开启合并机制的配置是spark.shuffle.consolidateFiles。该参数默认值是flase,将其设置为true即可开启优化机制。通常来说,如果我们使用HashShuffleManager,那么都建议开启这个选项。
4.3 SortShuffle解析
4.3.1 SortShuffle解析

在该模式下,数据会先写入一个数据结构,reduceByKey写入Map,一边通过Map局部聚合,一边写入内存。Join算子写入ArrayList,直接写入内存中。然后需要判断是否达到阙值,如果达到就会将内存数据结构的数据写入到磁盘,清空内存数据结构。
在溢写磁盘时,先根据key进行排序,排序过后的数据,会分批写入到磁盘文件中。默认批次为10000条,数据会以每批一万条写入到磁盘文件中。写入磁盘文件通过缓冲区溢写的方式,每次溢写都会产生一个磁盘文件,也就是说一个Task过程会产生多个临时文件。
最后在每个Task中,将所有的临时文件合并,这就是merge过程,此过程将所有临时文件读取出来,一次写入到最终文件。意味着一个Task的所有数据都在这一个文件中。同时单独写一份索引文件,标识下游各个Task的数据在文件中的索引,start offset和end offset。
4.3.2 bypassShuffle
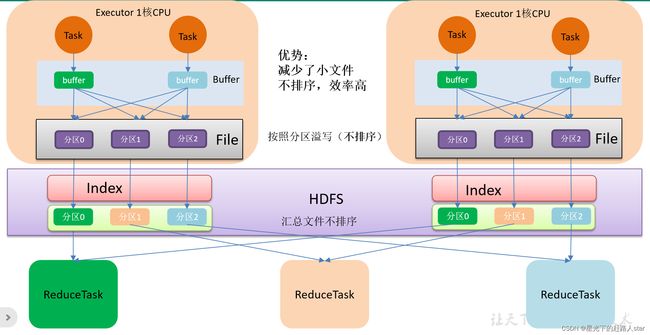
bypassShuffle和SortShuffle的区别就是不对数据排序。
bypass运行机制的触发条件如下:
① shuffle reduce task数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值,默认为200。
② 不是聚合类的shuffle算子(比如reduceByKey不行)。
5、Spark内存管理
5.1 堆内和堆外内存
5.1.1 概念
Spark支持堆内内存也支持堆外内存
① 堆内内存:程序在运行时动态地申请某个大小的内存空间
② 堆外内存:直接向操作系统进行申请的内存,不受JVM控制
5.1.2 堆内内存和堆外内存优缺点
1、堆外内存,相比于堆内内存有几个优势
| 减少了垃圾回收的工作 | 因为垃圾回收会暂停其他的任务 |
| 加快了复制的速度 | 堆内存中数据Flush到远程时需要先序列化在发送,而堆外内存数据本身就是序列化的。 |
说明:
(1)堆外内存是序列化的,其占用的内存大小可以直接计算。
(2)堆内内存是非序列化的对象,其占用的内存是通过周期性地采样近似估算而得,即不是每次新增的数据项都会计算一次占用的内存大小,这种方法降低了时间开销但是有可能误差较大,导致某一个时刻的实际内存有可能远远超出预期。此外,在被Spark标记为释放的对象实例,很有可能在实际上并没有被JVM回收,导致实际可用的内存小于Spark记录的可用内存。所以Spark并不能准确记录实际可用的堆内内存,从而也就无法完全避免内存溢出OOM的异常。
2
堆外内存,相比于堆内内存几个缺点
| 堆外内存难以控制 | 如果内存泄漏,就会很难查 |
| 堆外内存不太适合存复杂的对象 | 一般简单的对象或者扁平化的比较合适 |
5.1.3 如何配置
1、堆内内存大小设置
–executor-memory 或 spark.executor.memory
2、在默认情况下堆外内存并不启用
① spark.memory.offHeap.enabled 默认false,true启用。
② spark.memory.offHeap.size 参数设定堆外空间的大小。
5.2 堆内内存空间分配
1、堆内内存包括:储存内存(Storage)、执行内存(Execution)、其他内存
2、内存管理机制:静态内存管理、统一内存管理
5.2.1 静态内存管理
在Spark最初采用的静态内存管理机制下,储存内存、执行内存和其他内存的大小在Spark应用程序运行期间均为固定的,但用户可以在应用程序启动前进行配置,堆内内存的分配如图所示

可以看到,可用的堆内内存的大小需要按照下列方式计算:
可用的存储内存 = systemMaxMemory * spark.storage.memoryFraction * spark.storage.safety Fraction
可用的执行内存 = systemMaxMemory * spark.shuffle.memoryFraction * spark.shuffle.safety Fraction
其中systemMaxMemory取决于当前JVM堆内内存的大小,最后可用的执行内存或者存储内存要在此基础上与各自的memoryFraction 参数和safetyFraction 参数相乘得出。
Storage内存和Execution内存都有预留空间,目的是防止OOM,因为Spark堆内内存大小的记录是不准确的,需要留出保险区域。
预留内存空间
上述计算公式中的两个 safetyFraction 参数,其意义在于在逻辑上预留出 1-safetyFraction 这么一块保险区域,降低因实际内存超出当前预设范围而导致 OOM 的风险(上文提到,对于非序列化对象的内存采样估算会产生误差)。值得注意的是,这个预留的保险区域仅仅是一种逻辑上的规划,在具体使用时 Spark 并没有区别对待,和”其它内存”一样交给了 JVM 去管理。
堆外的空间分配较为简单,只有存储内存和执行内存,如下图所示。可用的执行内存和存储内存占用的空间大小直接由参数spark.memory.storageFraction 决定,由于堆外内存占用的空间可以被精确计算,所以无需再设定保险区域。
静态内存管理机制实现起来较为简单,但如果用户不熟悉Spark的存储机制,或没有根据具体的数据规模和计算任务或做相应的配置,很容易造成”一半海水,一半火焰”的局面,即存储内存和执行内存中的一方剩余大量的空间,而另一方却早早被占满,不得不淘汰或移出旧的内容以存储新的内容。
由于新的内存管理机制的出现,这种方式目前已经很少有开发者使用,出于兼容旧版本的应用程序的目的,Spark 仍然保留了它的实现。
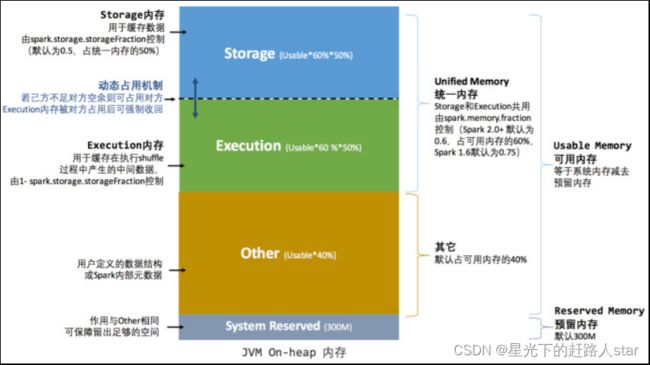
5.2.2 统一内存管理
Spark1.6 之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域,统一内存管理的堆内内存结构如图所示:
统一内存管理的堆外内存结构如下图所示:
其中最重要的优化在于动态占用机制,其规则如下:
① 设定基本的存储内存和执行内存区域(spark.storage.storageFraction),确定了双方各自的空间的范围;
② 双方的空间都不足时则存储到硬盘;
若己方空间不足而对方空余时,可借用对方的空间;(不足,不足以放下一个完整的Block)
③ 执行内存的空间被对方占用后,可让对方将占用的部分转存到硬盘,然后”归还”借用的空间;
④ 存储内存的空间被对方占用后,无法让对方”归还”,需要考虑 Shuffle过程中的很多因素,实现起来较为复杂。
统一内存管理的动态占用机制如图所示:
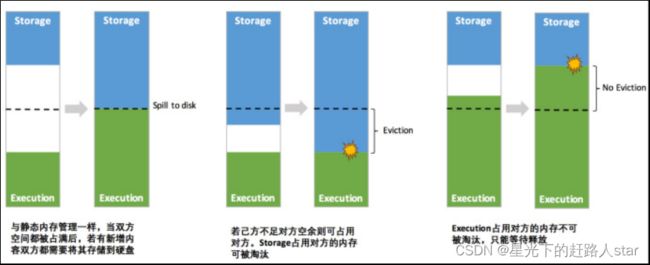
凭借统一内存管理机制,Spark在一定程度上提高了堆内和堆外内存资源的利用率,降低了开发者维护Spark内存的难度,但并不意味着开发者可以高枕无忧。
如果存储内存的空间太大或者说缓存的数据过多,反而会导致频繁的全量垃圾回收,降低任务执行时的性能,因为缓存的RDD数据通常都是长期驻留内存的。所以要想充分发挥Spark的性能,需要开发者进一步了解存储内存和执行内存各自的管理方式和实现原理。
5.3 储存内存管理
5.3.1 RDD持久化机制
- 回顾spark知识点:
① 弹性分布式数据集(RDD):
·是Spark最根本的数据抽象,是只读的分区记录(Partition)的集合
·只能基于在稳定物理存储中的数据集上创建或者在其他的RDD上执行转换操作产生一个新的RDD。
·转换后的RDD与原始的RDD之间产生的依赖关系,构成了血缘依赖(Lineage)。
·凭借血缘依赖,Spark 保证了每一个RDD都可以被重新恢复。
·但RDD的所有转换都是惰性的,只有当有Action算子触发时,Spark才会创建任务读取RDD,执行转换。
② 任务执行:
·Task在启动之初读取一个分区时,会先判断这个分区是否已经被持久化;
·如果没有则需要检查Checkpoint 或按照血统重新计算。
·即在一个 RDD 上要执行多次计算,可以在第一次计算中使用persist或cache方法,在内存或磁盘中持久化或缓存这个RDD,从而在后面的行动时提升计算速度。
③ RDD的持久化:
·事实上,rdd.cache()方法=rdd. persist(StorageLevel.MEMORY_ONLY),故缓存是一种特殊的持久化。
·堆内和堆外存储内存的设计,便可以对缓存RDD时使用的内存做统一的规划和管理。
·RDD的持久化由 Spark的Storage模块负责,实现了RDD与物理存储的解耦合。
·Storage模块负责管理Spark在计算过程中产生的数据,将那些在内存或磁盘、在本地或远程存取数据的功能封装了起来。在具体实现时Driver端和 Executor 端的Storage模块构成了主从式的架构,即Driver端的BlockManager为Master,Executor端的BlockManager 为 Slave。
·Storage模块在逻辑上以Block为基本存储单位,RDD的每个Partition经过处理后唯一对应一个 Block(BlockId 的格式为rdd_RDD-ID_PARTITION-ID )。
·Driver端的Master负责整个Spark应用程序的Block的元数据信息的管理和维护,
·Executor端的Slave需要将Block的更新等状态上报到Master,同时接收Master 的命令,例如新增或删除一个RDD。
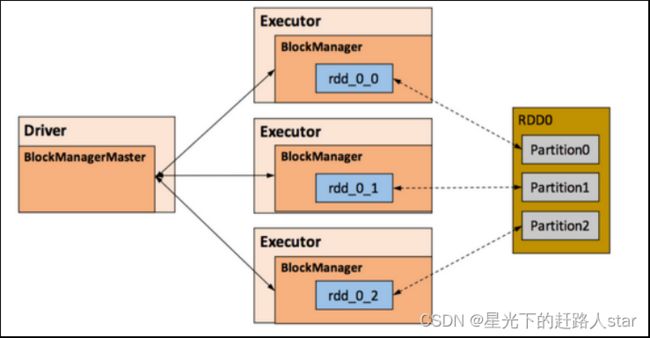
2、RDD持久化的存储级别
在对RDD持久化时,Spark规定了MEMORY_ONLY、MEMORY_AND_DISK 等7种不同的存储级别,而存储级别是以下5个变量的组合:
class StorageLevel private(
private var _useDisk: Boolean, //磁盘
private var _useMemory: Boolean, //这里其实是指堆内内存
private var _useOffHeap: Boolean, //堆外内存
private var _deserialized: Boolean, //是否为非序列化
private var _replication: Int = 1 //副本个数
)
Spark中7种存储级别如下:

通过对数据结构的分析,可知存储级别从三个维度定义了RDD的 Partition(同时也就是Block)的存储方式:
① 存储位置:磁盘/堆内内存/堆外内存。
·MEMORY_AND_DISK是同时在磁盘和堆内内存上存储,实现了冗余备份。
·OFF_HEAP 则是只在堆外内存存储,目前选择堆外内存时不能同时存储到其他位置。
② 存储形式:Block 缓存到存储内存后序列化或非序列化。
·MEMORY_ONLY是非序列化方式存储,
·OFF_HEAP 是序列化方式存储。
③ 副本数量:大于1时需要远程冗余备份到其他节点。
·如DISK_ONLY_2需要远程备份1个副本。
- RDD的缓存过程
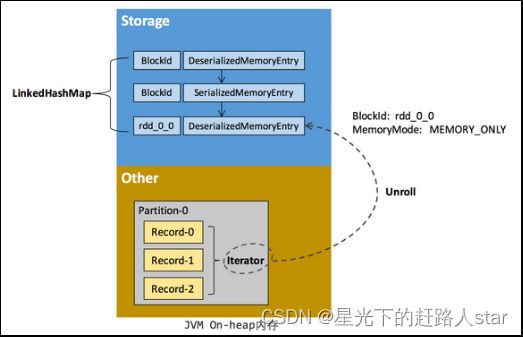
① RDD 在缓存到存储内存之前:
·Partition中的数据一般以迭代器(Iterator)的数据结构来访问
·通过Iterator可获取分区中每一条序列化或者非序列化的数据项(Record)
·这些Record对象实例在逻辑上占用了JVM堆内内存的other部分的空间
·同一Partition的不同Record的存储空间并不连续。
② RDD 在缓存到存储内存之后:
·Partition 被转换成Block,Record在堆内或堆外存储内存中占用一块连续的空间。
·将Partition由不连续的存储空间转换为连续存储空间的过程,Spark称之为"展开"(Unroll)。
③ Block 有序列化和非序列化两种存储格式,具体以哪种方式取决于该 RDD 的存储级别。
·序列化的Block则以SerializedMemoryEntry的数据结构定义,用字节缓冲区(ByteBuffer)来存储二进制数据。
·非序列化的Block以一种 DeserializedMemoryEntry 的数据结构定义,用一个数组存储所有的对象实例。
④ Executor中Storage模块对数据的管理
·在Executor中Storage模块用一个LinkedHashMap来管理堆内和堆外存储内存中所有的Block对象的实例,
·对这个LinkedHashMap新增和删除间接记录了内存的申请和释放。
·因为不能保证存储空间可以一次容纳Iterator中的所有数据,
·当前的计算任务在Unroll时要向MemoryManager申请足够的Unroll空间来临时占位
·空间不足则Unroll失败,空间足够时可以继续进行。
·对于序列化的Partition,其所需的Unroll空间可以直接累加计算,一次申请。
·对于非序列化的 Partition 则要在遍历Record的过程中依次申请,即每读取一条Record,采样估算其所需的Unroll空间并进行申请,空间不足时可以中断,释放已占用的Unroll空间。
·如果最终Unroll成功,当前Partition所占用的Unroll空间被转换为正常的缓存RDD的存储空间,如图所示。
注意:
静态内存管理时,Spark 在存储内存中专门划分了一块 Unroll 空间,其大小是固定的
统一内存管理时则没有对 Unroll 空间进行特别区分,当存储空间不足时会根据动态占用机制进行处理。
5.3.2 淘汰与落盘
- 淘汰
由于同一个Executor的所有的计算任务共享有限的存储内存空间,当有新的 Block 需要缓存但是剩余空间不足且无法动态占用时,就要对LinkedHashMap中的旧Block进行淘汰(Eviction),而被淘汰的Block如果其存储级别中同时包含存储到磁盘的要求,则要对其进行落盘(Drop),否则直接删除该Block。
存储内存的淘汰规则为:
① 被淘汰的旧Block要与新Block的MemoryMode相同,即同属于堆外或堆内内存;
② 新旧Block不能属于同一个RDD,避免循环淘汰;
③ 旧Block所属RDD不能处于被读状态,避免引发一致性问题;
④ 遍历LinkedHashMap中Block,按照最近最少使用(LRU)的顺序淘汰,直到满足新Block所需的空间。 - 落盘
落盘的流程则比较简单,如果其存储级别符合_useDisk为true的条件,再根据其_deserialized判断是否是非序列化的形式,若是则对其进行序列化,最后将数据存储到磁盘,在Storage模块中更新其信息。
5.4 执行内存管理
执行内存主要用来存储任务在执行Shuffle时占用的内存,Shuffle是按照一定规则对RDD数据重新分区的过程,我们来看Shuffle的Write和Read两阶段对执行内存的使用:
- Shuffle Write
① 若在map端选择普通的排序方式,采用ExternalSorter进行外排,在内存中存储数据时主要占用堆内执行空间。
② 若在map端选择Tungsten的排序方式,采用ShuffleExternalSorter直接对以序列化形式存储的数据排序,在内存中存储数据时可以占用堆外或堆内执行空间,取决于用户是否开启了堆外内存以及堆外执行内存是否足够。 - Shuffle Read
在对reduce端的数据进行聚合时,要将数据交给Aggregator处理,在内存中存储数据时占用堆内执行空间。
如果需要进行最终结果排序,则要将再次将数据交给ExternalSorter 处理,占用堆内执行空间。
恭喜大家看完了小编的博客,希望你能够有所收获,我一直相信躬身自问和沉思默想会充实我们的头脑,希望大家看完之后可以多想想喽,编辑不易,求关注、点赞、收藏(Thanks♪(・ω・)ノ)。