【AI画画教程】无整合包使用LoRA和Dreambooth训练全流程详解(Linux)
前言
本教程遵循简单原则,不使用任何民间整合包。
目前很多AI画画训练整合包臃肿复杂,教程也是名词乱炖,容易对初学者造成理解误差和使用困难。因为许多整合包都依赖于sd-scripts库,它自身就能支持绝大多数的训练场景,学会这个后,自己也可以根据自己的工作流搭整合包了。
此外,Dreambooth和LoRA并不是指代某一类独立的训练方法,而是多种训练方法的组合,也需要清楚它们的作用和原理。(详见讨论部分)
注意,这篇文章需要Linux平台,也就是说包括AutoDL、AWS、腾讯云、阿里云等有GPU租用的平台,只要选类似Ubuntu或CentOS的Linux镜像,都通用。
效果
电子龙AI卡图效果展示
文章目录
- 前言
- 效果
-
- 电子龙AI卡图效果展示
- 训练方法
-
- 一、准备材料
-
- 1. 拉取sd-scripts
- 2.数据处理
- 3.编写数据集描述文件
- 4.编写训练命令
- 二、训练过程
- 可视化(以电子龙为例)
-
- 一、准备材料
- 二、测试LoRA效果
- 使用正则项图像
-
- 准备材料与训练过程
-
- 1.正则项图像集
- 2.修改数据集描述文件
- 3.修改训练命令
- 4. 训练与结果展示
- 讨论
-
- 一、Clip Skip和VAE项设置到首页
- 二、LoRA和Dreambooth到底是什么关系?有什么区别?对应哪些微调技巧?
-
- 所以你们是什么关系
- 所以你们有什么区别
- 所以你们对应哪些微调技巧
- 实际使用时,不要在意这个方法到底LoRA还是Dreambooth,而是要搞清楚自己面临什么问题
训练方法
一、准备材料
需要准备:
- sd-scripts
- 训练图像
- 训练的基础模型(.ckpt或.safetensors)
- 带GPU的Linux环境
我的工作区选在/mnt/sd2,python虚拟环境位于/mnt/sd2/stable-diffusion-webui/venv,下面都以这些路径为例子,复制时记得替换成你的路径。
export WORK_DIR=/mnt/sd2
export PY_ENV=/mnt/sd2/stable-diffusion-webui/venv
1. 拉取sd-scripts
这个仓库的脚本已经满足绝大部分的训练场景了,现在整合包基本都依赖这个库。
cd $WORK_DIR
git clone https://github.com/kohya-ss/sd-scripts
如果你没有Python3.10或者版本比3.10小,那么需要更新一下,再配个虚拟环境:
# 配置apt
apt update
apt install software-properties-common
add-apt-repository ppa:deadsnakes/ppa
# 安装python3.10和虚拟环境
apt install python3.10
apt install python3.10-venv
python3.10 -m venv $PY_ENV
# (可选)创建软链接,这样就可以用python3来运行python3.10的版本等等
ln -fs $PY_ENV/bin/python3.10 /usr/bin/python3
ln -fs $PY_ENV/bin/accelerate /usr/bin/accelerate
检查一下python库是否满足sd-scripts的要求,或者直接更新
cd $WORK_DIR/sd-scripts
python3 -m pip install --ignore-installed -r ./requirements.txt
我已经安装了一些库,但是不想强制变成sd-scripts要求的版本,所以加了--ignore-installed参数,不更新那些已经安装的库。
如果安装失败,建议加上pip清华源:
python3 -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --ignore-installed -r ./requirements.txt
2.数据处理
先确认你的数据集:
- 即使只有1张图也可以训练
- 每张图分辨率尽量不小于512*512,不够的可以用AI超分辨率工具来修一下图
- 不要用超过1000*1000之类太大的图片
- (可选)尽量裁剪成目标分辨率大小,推荐用
www.birme.net
以电子龙为例,我收集了28张有电子龙主体的系列卡图,每张的大小都在512*512分辨率以上:

收集好后,存到工作目录中:
# 新建数据集目录
mkdir -p $WORK_DIR/dataset/cyberdragon
然后图片都放入$WORK_DIR/dataset/cyberdragon目录下,文件夹、图片的名字没有要求。
3.编写数据集描述文件
在$WORK_DIR/dataset下新建数据集描述文件cyberdragon.toml,粘贴以下内容:
[general]
enable_bucket = true # 使用长宽比自适应策略(Aspect Ratio Bucketing)
[[datasets]]
resolution = 512 # 学习的目标分辨率
batch_size = 2 # 每step训练的图像数(批量大小)
[[datasets.subsets]]
image_dir = '/mnt/sd2/dataset/cyberdragon' # 指定包含训练图像的文件夹
class_tokens = 'cbdg dragon' # 指定标识符类
num_repeats = 1 # 训练图像的迭代次数
注意image_dir改成刚刚的图片数据集路径。
我使用了Dreambooth论文中的 自创词+类型词 方法,对应class_tokens中的内容'cbdg dragon'。其中cbdg作为我的自创词,代表我训练的电子龙主体,dragon作为主体的类型词,使其与龙关联起来。
节选自《DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation》: Given ∼ 3−5 images of a subject we finetune a text-to-image diffusion model with the input images paired with a text prompt containing a unique identifier and the name of the class the subject belongs to (e.g., “A [V] dog”).
4.编写训练命令
以后可能会频繁修改训练参数来调优出图效果,命令文件可以视为训练的版本管理,可以记录之前的训练参数,方便以后回溯复盘。
在$WORK_DIR/dataset下新建训练命令文件cyberdragon.sh,粘贴以下内容:
accelerate launch --num_cpu_threads_per_process 4 $WORK_DIR/sd-scripts/train_network.py \
--pretrained_model_name_or_path="/mnt/sd2/stable-diffusion-webui/models/Stable-diffusion/AnythingV5_v5PrtRE.safetensors" \
--dataset_config="/mnt/sd2/dataset/cyberdragon.toml" \
--output_dir="/mnt/sd2/stable-diffusion-webui/models/Lora" \
--output_name="cyberdragon" \
--save_model_as=safetensors \
--clip_skip=2 \
--prior_loss_weight=1.0 \
--max_train_steps=4000 \
--learning_rate=1e-4 \
--unet_lr=1e-4 \
--text_encoder_lr=1e-5 \
--optimizer_type="AdamW" \
--xformers \
--mixed_precision="no" \
--cache_latents \
--gradient_checkpointing \
--save_n_epoch_ratio=8 \
--network_module=networks.lora \
--network_dim=64 \
--network_alpha=32
注意:文档格式必须是Unix(LF),否则不识别反斜杠换行,就得手动复制输入到命令行中运行了。如果用notepad++,则点击编辑-文档格式转换-转为Unix(LF)。
你必须要修改的内容:
--pretrained_model_name_or_path:指定基础模型,即要从中执行额外训练的模型(.ckpt 或 .safetensors)。
--dataset_config:数据集描述文件,即刚刚新建的.toml文件路径。
--output_dir:输出LoRA结果的位置,我这里输出到我webui的LoRA目录中了。
可能要修改的内容:
--output_name:输出LoRA的文件名。
--vae:如果基础模型带有VAE文件,加上这个参数指定VAE路径
--clip_skip:如果基础模型指定的clip skip不是1(一般写实的模型是1,二次元的是2),那么需要加上这个参数,比如--clip_skip=2。我用的AnythingV5就需要指定clip skip为2.
二、训练过程
以阿里云购买的V100GPU和Ubuntu22.04环境为例。
执行刚刚的命令文件,进行训练:
cd /mnt/sd2/dataset
bash < ./cyberdragon.sh
以下是输出:
root@c230511:/mnt/sd2/dataset# ./cyberdragon.sh
2023-05-11 00:35:27.138614: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-05-11 00:35:27.383777: E tensorflow/stream_executor/cuda/cuda_blas.cc:2981] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2023-05-11 00:35:30.744157: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory
2023-05-11 00:35:30.744242: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory
2023-05-11 00:35:30.744254: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
The following values were not passed to `accelerate launch` and had defaults used instead:
`--num_processes` was set to a value of `1`
`--num_machines` was set to a value of `1`
`--mixed_precision` was set to a value of `'no'`
`--dynamo_backend` was set to a value of `'no'`
To avoid this warning pass in values for each of the problematic parameters or run `accelerate config`.
2023-05-11 00:35:47.558358: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-05-11 00:35:47.787581: E tensorflow/stream_executor/cuda/cuda_blas.cc:2981] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2023-05-11 00:35:50.413823: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory
2023-05-11 00:35:50.413904: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory
2023-05-11 00:35:50.413917: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
prepare tokenizer
Load dataset config from /mnt/sd2/dataset/cyberdragon.toml
prepare images.
found directory /mnt/sd2/dataset/cyberdragon contains 28 image files
28 train images with repeating.
0 reg images.
no regularization images / 正則化画像が見つかりませんでした
[Dataset 0]
batch_size: 1
resolution: (512, 512)
enable_bucket: True
min_bucket_reso: 256
max_bucket_reso: 1024
bucket_reso_steps: 64
bucket_no_upscale: False
[Subset 0 of Dataset 0]
image_dir: "/mnt/sd2/dataset/cyberdragon"
image_count: 28
num_repeats: 1
shuffle_caption: False
keep_tokens: 0
caption_dropout_rate: 0.0
caption_dropout_every_n_epoches: 0
caption_tag_dropout_rate: 0.0
color_aug: False
flip_aug: False
face_crop_aug_range: None
random_crop: False
token_warmup_min: 1,
token_warmup_step: 0,
is_reg: False
class_tokens: cbdg dragon
caption_extension: .caption
[Dataset 0]
loading image sizes.
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 28/28 [00:00<00:00, 286.45it/s]
make buckets
number of images (including repeats) / 各bucketの画像枚数(繰り返し回数を含む)
bucket 0: resolution (512, 512), count: 28
mean ar error (without repeats): 0.0
prepare accelerator
Using accelerator 0.15.0 or above.
loading model for process 0/1
load StableDiffusion checkpoint
/mnt/sd2/stable-diffusion-webui/venv/lib/python3.10/site-packages/safetensors/torch.py:98: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
with safe_open(filename, framework="pt", device=device) as f:
/mnt/sd2/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/_utils.py:776: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
return self.fget.__get__(instance, owner)()
/mnt/sd2/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/storage.py:899: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
storage = cls(wrap_storage=untyped_storage)
loading u-net: <All keys matched successfully>
loading vae: <All keys matched successfully>
loading text encoder: <All keys matched successfully>
Replace CrossAttention.forward to use xformers
[Dataset 0]
caching latents.
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 28/28 [00:03<00:00, 8.26it/s]
import network module: networks.lora
create LoRA network. base dim (rank): 64, alpha: 32.0
create LoRA for Text Encoder: 72 modules.
create LoRA for U-Net: 192 modules.
enable LoRA for text encoder
enable LoRA for U-Net
prepare optimizer, data loader etc.
use AdamW optimizer | {}
running training / 学習開始
num train images * repeats / 学習画像の数×繰り返し回数: 28
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 28
num epochs / epoch数: 143
batch size per device / バッチサイズ: 1
gradient accumulation steps / 勾配を合計するステップ数 = 1
total optimization steps / 学習ステップ数: 4000
steps: 0%| | 0/4000 [00:00<?, ?it/s]epoch 1/143
/mnt/sd2/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/utils/checkpoint.py:31: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn("None of the inputs have requires_grad=True. Gradients will be None")
steps: 1%|▉ | 28/4000 [00:28<1:07:34, 1.02s/it, loss=0.192]
epoch 2/143
......省略训练过程......
epoch 143/143
steps: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4000/4000 [1:07:42<00:00, 1.02s/it, loss=0.116]
saving checkpoint: /mnt/sd2/stable-diffusion-webui/models/Lora/cyberdragon.safetensors
model saved.
至此,训练完毕。
可视化(以电子龙为例)
一、准备材料
- stable-diffusion-webui
- locon、lycoris插件
一般来说出图都是在stable-diffusion-webui上做的,我安装到了$WORK_DIR/stable-diffusion-webui目录下。关于stable-diffusion-webui安装可以看我之前的教程【踩坑笔记】从零开始部署安装Stable Diffusion 2 WebUI。
接下来安装两个用于加载LoRA的插件:
cd $WORK_DIR/stable-diffusion-webui/extensions
git clone https://github.com/KohakuBlueleaf/a1111-sd-webui-lycoris
git clone https://github.com/KohakuBlueleaf/a1111-sd-webui-locon
二、测试LoRA效果
启动webui:
cd $WORK_DIR/stable-diffusion-webui
python3 launch.py --port 9965 --listen --enable-insecure-extension-access --xformers
切换基础模型,展开LoRA面板,单击对应卡片以应用上训练好的LoRA:
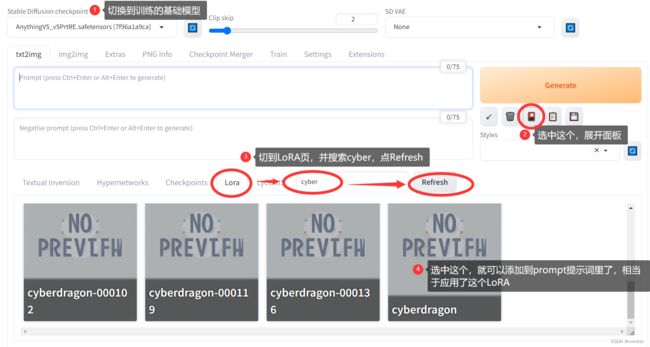
Clip Skip和VAE项设置到首页的方法详见讨论章节
单击对应的LoRA卡片后,会在正向词Prompt中增加对应的LoRA标签
最后一个数字代表应用LoRA的权重,取值为(0,1],我个人一般取0.8、0.85、0.9这样。
写上刚刚设置的class token作为激活词,后面附上自己喜欢的Prompt (示例
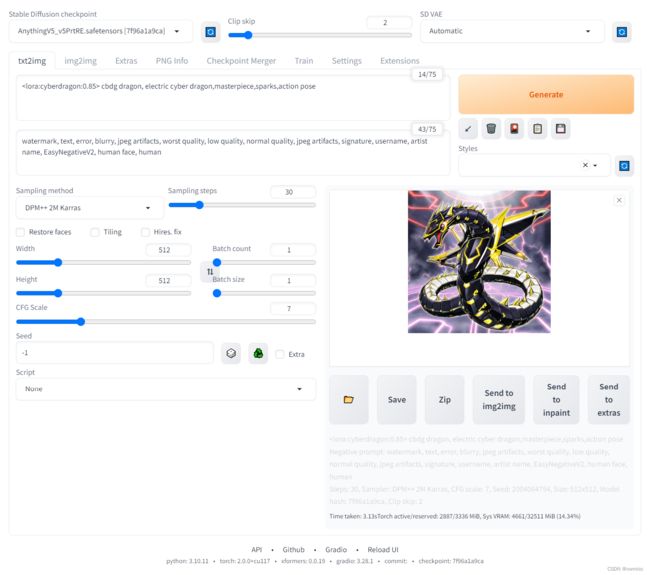
出图就像抽卡,多抽几次看看效果。我的第一次抽卡还挺酷的:

使用正则项图像
训练可能会由于数据集大小、训练参数等原因,出现欠拟合或过拟合的情况。
欠拟合:表现为图像质量低,与目标风格差距大。原因可能是训练步数不足、基础模型风格不合适等。
过拟合:表现为图像缺乏多样性,与训练集的背景、姿势等高度相似。原因可能是训练步数过多、训练图像太少等。
在训练中加入"正则项图像"主要解决的是"过拟合"与"灾难性遗忘"的问题。
"正则项图像"对应《Dreambooth》论文中的prior-preservation图像,用来防止模型过拟合。通过自己先生成一些图像,依赖论文中loss的prior-preservation term对训练过程正则化,来解决过拟合与语言漂移问题。
我看到好多人叫它“正则化图像”,我个人觉得这个词会导致歧义。如果把“正则项图像”叫做“正则化图像”,可能会让人误以为要对这些图像进行某种形式的“规则化”,而不是它想表达的在训练时使用这些图像对模型进行约束。
准备材料与训练过程
1.正则项图像集
除了前面训练章节提到的材料以外,还需要额外准备正则项图像集。就是直接使用基础模型,打上你不带自创词的class token,生成一系列图像,然后把不好看的删掉就可以了。最后,生成的图片单独放到一个文件夹内。我放到了$WORK_DIR/dataset/cyberdragon_reg文件夹下。
2.修改数据集描述文件
在$WORK_DIR/dataset下新建一个新的数据集描述文件cyberdragon2.toml,用于添加正则项图像数据集:
[general]
enable_bucket = true # 使用长宽比自适应策略(Aspect Ratio Bucketing)
[[datasets]]
resolution = 512 # 学习的目标分辨率
batch_size = 2 # 每step训练的图像数(批量大小)
[[datasets.subsets]]
image_dir = '/mnt/sd2/dataset/cyberdragon' # 指定包含训练图像的文件夹
class_tokens = 'cbdg dragon' # 指定标识符类
num_repeats = 10 # 训练图像的迭代次数(这里要比正则化图像的迭代次数高)
# 仅在使用正则项图像时添加以下内容。不使用则删除
[[datasets.subsets]]
image_dir = '/mnt/sd2/dataset/cyberdragon_reg' # 指定包含训练图像的文件夹
class_tokens = 'dragon' # 指定标识符类(仅标识词)
num_repeats = 1 # 正则项图像的迭代次数
注意,训练图像的迭代次数要比正则项图像的迭代次数多,自己试了一下大概多10倍,效果是还可以的。
3.修改训练命令
在$WORK_DIR/dataset下新建训练命令文件cyberdragon2.sh,粘贴以下内容:
accelerate launch --num_cpu_threads_per_process 4 $WORK_DIR/sd-scripts/train_network.py \
--pretrained_model_name_or_path="/mnt/sd2/stable-diffusion-webui/models/Stable-diffusion/AnythingV5_v5PrtRE.safetensors" \
--dataset_config="/mnt/sd2/dataset/cyberdragon2.toml" \
--output_dir="/mnt/sd2/stable-diffusion-webui/models/Lora" \
--output_name="cyberdragon2" \
--save_model_as=safetensors \
--clip_skip=2 \
--prior_loss_weight=1.0 \
--max_train_steps=4000 \
--learning_rate=1e-4 \
--unet_lr=1e-4 \
--text_encoder_lr=1e-5 \
--optimizer_type="AdamW" \
--xformers \
--mixed_precision="no" \
--cache_latents \
--gradient_checkpointing \
--save_n_epoch_ratio=8 \
--network_module=networks.lora \
--network_dim=64 \
--network_alpha=32
相比于先前的命令,仅修改了dataset_config和output_name,为了与前一次训练分开。
可能要修改的内容:
--prior_loss_weight:这个参数决定了正则项图像学习时占的权重,越大正则项发挥的效果越强硬。如果没有把握最好别动,否则可能效果变差。
4. 训练与结果展示
bash <./cyberdragon2.sh
等训练完后,可视化就和之前的方法一样,看效果:

讨论
一、Clip Skip和VAE项设置到首页
找到webui的设置Settings,展示所有页Show all pages,然后搜索Quicksettings list项,把内容修改成sd_model_checkpoint,CLIP_stop_at_last_layers,sd_vae。之后点Apply Settings,再点Reload UI,就可以在首页展示clip skip和VAE了。
这里的参数可以在目录下的config.json中找到。
二、LoRA和Dreambooth到底是什么关系?有什么区别?对应哪些微调技巧?
它们代表的是微调模型的不同技巧,本质都是为了解决如何去微调模型的问题。因为,微调大模型很难,具体难在:
- 全量微调(微调所有参数)占用的显卡内存非常大
- 全量微调时产生的模型文件占用的磁盘空间非常大
- 微调后的模型难以准确生成特定目标的外观(比如,仅用几张图片生成电子龙)
- 微调后的模型会灾难性遗忘之前的能力(比如,只会生成电子龙,忘记什么是龙了)
LoRA解决了1和2,Dreambooth解决了3和4。一般都是同时使用它们提供的方法来进行大模型微调的。
所以你们是什么关系
LoRA和Dreambooth并不是“二选一”的关系,而是互相帮助,互相成全的关系,一般它们的微调技巧会被同时使用。
所以你们有什么区别
LoRA主要解决模型全量训练的一些弊端,Dreambooth主要解决模型个性化目标重现和防止灾难性遗忘的问题。然而:
LoRA论文中没有使用Dreambooth(可能发生关键性遗忘)
Dreambooth论文中没有使用LoRA(意味着它是全量微调)
在训练AI时,单独使用LoRA则会面临被Dreambooth所解决的问题,反之也是。
所以你们对应哪些微调技巧
LoRA ≈ 低秩矩阵近似 + 旁路结构重参数化
Dreambooth ≈ 自创词&标识词策略 + 历史记忆加入正则项
实际使用时,不要在意这个方法到底LoRA还是Dreambooth,而是要搞清楚自己面临什么问题
- 如果你有足够的时间、显存和硬盘来全量训练模型,那就没必要用LoRA
- 如果你的微调模型已经能很好地生成你的目标,那就没必要用Dreambooth的"自创词&标识词策略"
- 如果你不需要模型记住以前的记忆而是专注于你的目标,没有过拟合,那么就没必要使用Dreambooth的"正则项图像"
这个系列还没写完,后面再出一篇教程教优化、效果比较原则和我常用的工作流。
如果有什么想法,可以留言交流。不想留言的可以在微信加我,账号就是我的CSDN昵称。