YOLO格式 转为 旋转数据标注rolabelimg/labelimg2的VOC格式(集成主成分提取角度)
之前用labelimg标注了七十张的yolo格式数据集,但是现在要换识别的模型,需要用到带有角度的VOC格式数据集,传统VOC格式数据集包含的位置信息是(xmin, ymin, xmax, ymax),而使用rolabelimg/labelimg2标注的旋转举矩形数据集包含的位置信息是(cx, cy, w, h, angle)。
前四项cx, cy, w, h可以使用yolo提供的x_0, y_0, w_0, h_0计算得到,但是无法得到角度信息,于是使用基于主成分提取的方向校正(OpenCV)方法得到目标框的角度,然后写为VOC的XML格式。
本文共分为两部分:主成分方向提取代码和VOC格式生成代码。
1. 主成分方向提取代码(OpenCV)
我用的体系是很简单的椭圆结构,方向比较好提取,因此可以使用PCA特征提取的方法求得主方向。下面介绍参考代码的修改部分。
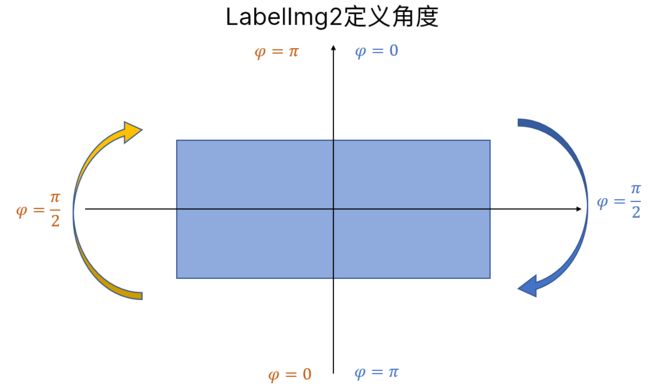
函数设计的思路是输入(img, cx, cy, width, height),输出角度值,这个角度值按照下图定义,纵轴正方向开始,顺时针旋转是角度增大,一直增加到 ,然后到达纵轴负方向;继续逆时针旋转后角度从0开始,又增加到,直到回到纵轴正方向。
,然后到达纵轴负方向;继续逆时针旋转后角度从0开始,又增加到,直到回到纵轴正方向。
而且我需要的是短边的角度,PCA程序生成两个角度:第一、第二主成分方向,第一主成分方向就是下图长边的方向,第二主成分方向才是我需要的短边的方向,生成后发现第二主方向都是分布在一三四象限的,没有找到第二象限的方向,即角度范围在 ,第一象限的也很少,角度转换就很好设计了:
,第一象限的也很少,角度转换就很好设计了:
theta = (theta_PCA - math.pi / 2) if (theta_PCA > math.pi / 2) else (theta_PCA + math.pi / 2)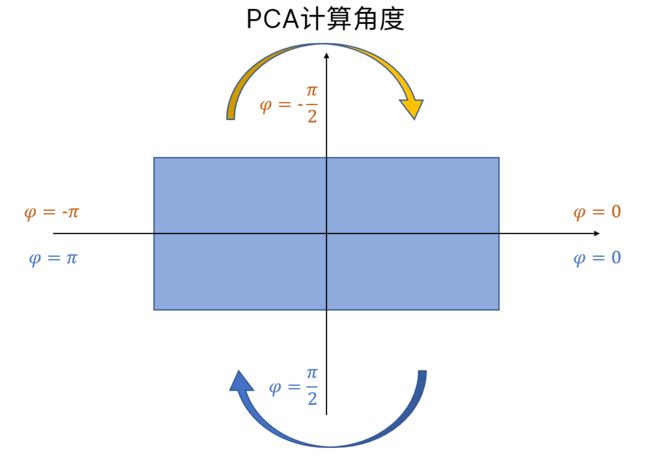
get_angle程序如下:
def get_angle(img, cx, cy, width, height):
# 14.18 基于 PCA 的方向矫正 (OpenCV):https://blog.csdn.net/youcans/article/details/125782405
# 必须要规定截取图像的范围,不能小于零!!!
Pheight, Pwidth, _ = img.shape
# 裁剪坐标为[y0:y1, x0:x1]
#截取的左上坐标
left_top = (max(int(cx - width / 2), 0), min(int(cy - height / 2), Pheight))
#截取的右下坐标
right_bottom = (max(int(cx + width / 2), 0), min(int(cy + height / 2), Pwidth))
# 裁剪坐标为[y0:y1, x0:x1]
img_crop = img[left_top[1]:right_bottom[1], left_top[0]:right_bottom[0]]
# cv_show('img_crop', img_crop, True)
gray = cv2.cvtColor(img_crop, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(gray, 200, 255, cv2.THRESH_BINARY_INV)
# 寻找二值化图中的轮廓,检索所有轮廓,输出轮廓的每个像素点
contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE) # OpenCV4~
fullCnts = np.zeros(img_crop.shape[:2], np.uint8) # 绘制轮廓函数会修改原始图像
fullCnts = cv2.drawContours(fullCnts, contours, -1, (255, 255, 255), thickness=3) # 绘制全部轮廓
# 按轮廓的面积排序,绘制面积最大的轮廓
cnts = sorted(contours, key=cv2.contourArea, reverse=True) # 所有轮廓按面积排序
cnt = cnts[0] # 第 0 个轮廓,面积最大的轮廓,(1445, 1, 2)
maxCnt = np.zeros(img_crop.shape[:2], np.uint8) # 初始化最大轮廓图像
cv2.drawContours(maxCnt, cnts[0], -1, (255, 255, 255), thickness=3) # 仅绘制最大轮廓 cnt
# 主成分分析方法提取目标的方向
markedCnt = maxCnt.copy()
ptsXY = np.squeeze(cnt).astype(np.float64) # 删除维度为1的数组维度,(1445, 1, 2)->(1445, 2)
mean, eigenvectors, eigenvalues = cv2.PCACompute2(ptsXY, np.array([])) # (1, 2) (2, 2) (2, 1)
# 绘制第一、第二主成分方向轴
center = mean[0, :].astype(int) # 近似作为目标的中心 [266 281]
# e1xy = eigenvectors[0,:] * eigenvalues[0,0] # 第一主方向轴
e2xy = eigenvectors[1,:] * eigenvalues[1,0] # 第二主方向轴
# p1 = (center + 0.1*e1xy).astype(np.int) # P1:[149 403]
p2 = (center + 0.1*e2xy).astype(np.int) # P2:[320 332]
theta = np.arctan2(eigenvectors[1,1], eigenvectors[1,0]) # 第二主方向角度 133.6
# cv2.circle(markedCnt, center, 6, 255, -1) # 在PCA中心位置画一个圆圈 RGB
# cv2.arrowedLine(markedCnt, center, p1, (255, 0, 0), thickness=2, tipLength=0.1) # 从 center 指向 pt1
cv2.arrowedLine(markedCnt, center, p2, (255, 0, 0), thickness=2, tipLength=0.2) # 从 center 指向 pt2
# cv_show('markedCnt', markedCnt, True)
theta = (theta - math.pi / 2) if (theta > math.pi / 2) else (theta + math.pi / 2)
return theta2. VOC格式生成代码
相较于参考代码做了以下修改,可以生成rolabelimg/labelimg2能够识别的旋转矩形VOC数据集:
增加了二级节点
;
增加了二级节点
及其下的三级节点 ;
增加了二级节点
;
二级标签下
其余的
、 根据当前数据集进行修改,其中、 、 用了绝对路径,不知道相对路径行不行。
其他部分和参考代码类似,比较好理解,就不过多介绍了,makexml代码如下:
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
"""
dic = {'0': "single", # 创建字典用来对类型进行转换
'1': "overlap"} # 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致
files = os.listdir(txtPath)
for i, name in enumerate(files):
if name == 'classes.txt':
continue
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
txtList = txtFile.readlines()
add_0 = name.split('.')[0].rjust(4, '0') # 左侧补零
img_path = "images1_" + add_0 + ".png"
img = cv2.imread(picPath + img_path)
# if cv_show(img_path, img, True) is None:
# break
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签开始
foldercontent = xmlBuilder.createTextNode("image")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签开始
filenamecontent = xmlBuilder.createTextNode("images1_" + add_0 + ".png")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
path = xmlBuilder.createElement("path") # path标签开始
img_path_all = os.path.abspath(picPath + img_path)
pathcontent = xmlBuilder.createTextNode(img_path_all)
path.appendChild(pathcontent)
annotation.appendChild(path) # path标签结束
source = xmlBuilder.createElement("source") # source标签开始
database = xmlBuilder.createElement("database") # source子标签database开始
databasecontent = xmlBuilder.createTextNode('Unknown')
database.appendChild(databasecontent)
source.appendChild(database) # source子标签database结束
annotation.appendChild(source) # source标签结束
size = xmlBuilder.createElement("size") # size标签开始
width = xmlBuilder.createElement("width") # size子标签width开始
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height开始
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth开始
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
segmented = xmlBuilder.createElement("segmented") # segmented标签开始
segmentedcontent = xmlBuilder.createTextNode("0")
segmented.appendChild(segmentedcontent)
annotation.appendChild(segmented) # segmented标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签开始
picname = xmlBuilder.createElement("name") # name标签开始
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签开始
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签开始
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签开始
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
robndbox = xmlBuilder.createElement("robndbox") # robndbox标签开始
cx = xmlBuilder.createElement("cx") # cx标签开始
cxData = float(oneline[1]) * 1280 - 256 / 2
cxContent = xmlBuilder.createTextNode(str(cxData))
cx.appendChild(cxContent)
robndbox.appendChild(cx) # cx标签结束
cy = xmlBuilder.createElement("cy") # cy标签开始
cyData = float(oneline[2]) * 800 + 224 / 2
cyContent = xmlBuilder.createTextNode(str(cyData))
cy.appendChild(cyContent)
robndbox.appendChild(cy) # cy标签结束
w = xmlBuilder.createElement("w") # w标签开始
wData = float(oneline[3]) * 1280
wContent = xmlBuilder.createTextNode(str(wData))
w.appendChild(wContent)
robndbox.appendChild(w) # w标签结束
h = xmlBuilder.createElement("h") # h标签开始
hData = float(oneline[4]) * 800
hContent = xmlBuilder.createTextNode(str(hData))
h.appendChild(hContent)
robndbox.appendChild(h) # h标签结束
angle = xmlBuilder.createElement("angle") # angle标签开始
angleData = get_angle(img, cxData, cyData, 1.25 * wData, 1.25 * hData)
angleContent = xmlBuilder.createTextNode(str(angleData))
angle.appendChild(angleContent)
robndbox.appendChild(angle) # angle标签结束
object.appendChild(robndbox) # robndbox标签结束
annotation.appendChild(object) # object标签结束
f = open(xmlPath + "images1_" + add_0 + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
print(xmlPath + "images1_" + add_0 + ".xml", 'created successfully!')
f.close()完整代码:
from xml.dom.minidom import Document
import os
import math
import cv2
import numpy as np
def cv_show(name, img, pause = False):
cv2.imshow(name, img)
key = cv2.waitKey(0 if pause == True else 1) & 0xFF
if key == 27: # keycode 27 = Escape
cv2.destroyAllWindows()
else:
cv2.destroyAllWindows()
return 1
def get_angle(img, cx, cy, width, height):
# 14.18 基于 PCA 的方向矫正 (OpenCV):https://blog.csdn.net/youcans/article/details/125782405
# 必须要规定截取图像的范围,不能小于零!!!
Pheight, Pwidth, _ = img.shape
# 裁剪坐标为[y0:y1, x0:x1]
#截取的左上坐标
left_top = (max(int(cx - width / 2), 0), min(int(cy - height / 2), Pheight))
#截取的右下坐标
right_bottom = (max(int(cx + width / 2), 0), min(int(cy + height / 2), Pwidth))
# 裁剪坐标为[y0:y1, x0:x1]
img_crop = img[left_top[1]:right_bottom[1], left_top[0]:right_bottom[0]]
# cv_show('img_crop', img_crop, True)
gray = cv2.cvtColor(img_crop, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(gray, 200, 255, cv2.THRESH_BINARY_INV)
# 寻找二值化图中的轮廓,检索所有轮廓,输出轮廓的每个像素点
contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE) # OpenCV4~
fullCnts = np.zeros(img_crop.shape[:2], np.uint8) # 绘制轮廓函数会修改原始图像
fullCnts = cv2.drawContours(fullCnts, contours, -1, (255, 255, 255), thickness=3) # 绘制全部轮廓
# 按轮廓的面积排序,绘制面积最大的轮廓
cnts = sorted(contours, key=cv2.contourArea, reverse=True) # 所有轮廓按面积排序
cnt = cnts[0] # 第 0 个轮廓,面积最大的轮廓,(1445, 1, 2)
maxCnt = np.zeros(img_crop.shape[:2], np.uint8) # 初始化最大轮廓图像
cv2.drawContours(maxCnt, cnts[0], -1, (255, 255, 255), thickness=3) # 仅绘制最大轮廓 cnt
# 主成分分析方法提取目标的方向
markedCnt = maxCnt.copy()
ptsXY = np.squeeze(cnt).astype(np.float64) # 删除维度为1的数组维度,(1445, 1, 2)->(1445, 2)
mean, eigenvectors, eigenvalues = cv2.PCACompute2(ptsXY, np.array([])) # (1, 2) (2, 2) (2, 1)
# 绘制第一、第二主成分方向轴
center = mean[0, :].astype(int) # 近似作为目标的中心 [266 281]
# e1xy = eigenvectors[0,:] * eigenvalues[0,0] # 第一主方向轴
e2xy = eigenvectors[1,:] * eigenvalues[1,0] # 第二主方向轴
# p1 = (center + 0.1*e1xy).astype(np.int) # P1:[149 403]
p2 = (center + 0.1*e2xy).astype(np.int) # P2:[320 332]
theta = np.arctan2(eigenvectors[1,1], eigenvectors[1,0]) # 第二主方向角度 133.6
# cv2.circle(markedCnt, center, 6, 255, -1) # 在PCA中心位置画一个圆圈 RGB
# cv2.arrowedLine(markedCnt, center, p1, (255, 0, 0), thickness=2, tipLength=0.1) # 从 center 指向 pt1
cv2.arrowedLine(markedCnt, center, p2, (255, 0, 0), thickness=2, tipLength=0.2) # 从 center 指向 pt2
# cv_show('markedCnt', markedCnt, True)
theta = (theta - math.pi / 2) if (theta > math.pi / 2) else (theta + math.pi / 2)
return theta
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
"""
dic = {'0': "single", # 创建字典用来对类型进行转换
'1': "overlap"} # 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致
files = os.listdir(txtPath)
for i, name in enumerate(files):
if name == 'classes.txt':
continue
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
txtList = txtFile.readlines()
add_0 = name.split('.')[0].rjust(4, '0') # 左侧补零
img_path = "images1_" + add_0 + ".png"
img = cv2.imread(picPath + img_path)
# if cv_show(img_path, img, True) is None:
# break
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签开始
foldercontent = xmlBuilder.createTextNode("image")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签开始
filenamecontent = xmlBuilder.createTextNode("images1_" + add_0 + ".png")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
path = xmlBuilder.createElement("path") # path标签开始
img_path_all = os.path.abspath(picPath + img_path)
pathcontent = xmlBuilder.createTextNode(img_path_all)
path.appendChild(pathcontent)
annotation.appendChild(path) # path标签结束
source = xmlBuilder.createElement("source") # source标签开始
database = xmlBuilder.createElement("database") # source子标签database开始
databasecontent = xmlBuilder.createTextNode('Unknown')
database.appendChild(databasecontent)
source.appendChild(database) # source子标签database结束
annotation.appendChild(source) # source标签结束
size = xmlBuilder.createElement("size") # size标签开始
width = xmlBuilder.createElement("width") # size子标签width开始
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height开始
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth开始
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
segmented = xmlBuilder.createElement("segmented") # segmented标签开始
segmentedcontent = xmlBuilder.createTextNode("0")
segmented.appendChild(segmentedcontent)
annotation.appendChild(segmented) # segmented标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签开始
picname = xmlBuilder.createElement("name") # name标签开始
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签开始
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签开始
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签开始
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
robndbox = xmlBuilder.createElement("robndbox") # robndbox标签开始
cx = xmlBuilder.createElement("cx") # cx标签开始
cxData = float(oneline[1]) * 1280 - 256 / 2
cxContent = xmlBuilder.createTextNode(str(cxData))
cx.appendChild(cxContent)
robndbox.appendChild(cx) # cx标签结束
cy = xmlBuilder.createElement("cy") # cy标签开始
cyData = float(oneline[2]) * 800 + 224 / 2
cyContent = xmlBuilder.createTextNode(str(cyData))
cy.appendChild(cyContent)
robndbox.appendChild(cy) # cy标签结束
w = xmlBuilder.createElement("w") # w标签开始
wData = float(oneline[3]) * 1280
wContent = xmlBuilder.createTextNode(str(wData))
w.appendChild(wContent)
robndbox.appendChild(w) # w标签结束
h = xmlBuilder.createElement("h") # h标签开始
hData = float(oneline[4]) * 800
hContent = xmlBuilder.createTextNode(str(hData))
h.appendChild(hContent)
robndbox.appendChild(h) # h标签结束
angle = xmlBuilder.createElement("angle") # angle标签开始
angleData = get_angle(img, cxData, cyData, 1.25 * wData, 1.25 * hData)
angleContent = xmlBuilder.createTextNode(str(angleData))
angle.appendChild(angleContent)
robndbox.appendChild(angle) # angle标签结束
object.appendChild(robndbox) # robndbox标签结束
annotation.appendChild(object) # object标签结束
f = open(xmlPath + "images1_" + add_0 + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
print(xmlPath + "images1_" + add_0 + ".xml", 'created successfully!')
f.close()
if __name__ == "__main__":
picPath = "image/" # 图片所在文件夹路径,后面的/一定要带上
txtPath = "yolo/" # txt所在文件夹路径,后面的/一定要带上
xmlPath = "voc/" # xml文6780p 件保存路径,后面的/一定要带上
makexml(picPath, txtPath, xmlPath)参考文章:
【OpenCV 例程 300篇】237. 基于主成分提取的方向校正(OpenCV)_YouCans的博客-CSDN博客_opencv 图像主方向
YOLO与voc格式互转,超详细_@秋野的博客-CSDN博客_yolo转voc