利用R分别绘制配对连线散点图、云雨图、山脊图
大家好,我是带我去滑雪!
精美的科研绘图总会给人眼前一亮,今天学习利用R绘制多组配对连线散点图、云雨图、山脊图,这三幅图最近都曾出现在Nature Communications (IF 16.6)中,比如配对连线散点图,如下所示:
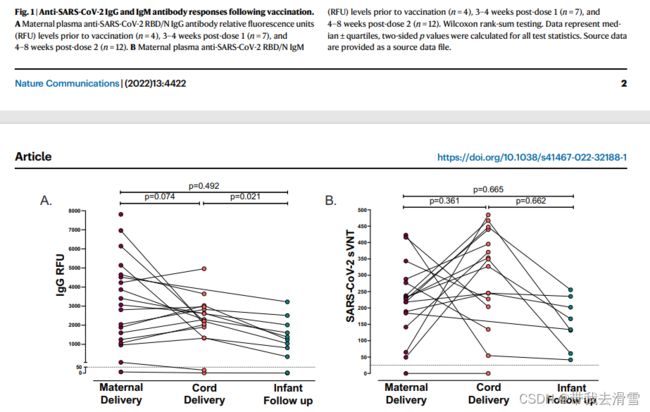
因此值得一学,方便后续用于自己的科研论文中,下面逐一进行学习。
目录
1、多组配对连线散点图
(1)什么是配对连线散点图?
(2)应用场景
(3)代码实现
2、云雨图
(1)什么是云雨图?
(2)运用场景
(3)代码实现
3、山脊图
(1)什么是山脊图?
(2)应用场景
(3)代码实现
1、多组配对连线散点图
(1)什么是配对连线散点图?
多组配对连线散点图(Paired Line Scatter Plot)是一种用于可视化配对变量之间关系的图表。这种图表通过在图中连接配对点之间的线段,展示两个变量在不同配对观测值之间的关联性。在配对设计的研究中,每个观测都有两个相关的变量的测量结果。这些变量可能是在相同个体或实验单位上测量的两个不同指标,或者是对同一组样本在不同时间点上取得的测量结果。配对连线散点图可用于可视化这两个变量之间的关系,并显示出配对观测之间的连接。
(2)应用场景
多组散点图结合配对连线和差异分析在很多领域中都可以应用,例如:
在生物医学研究中,可以使用多组散点图和配对连线来探索不同组别或不同时间点下的相关性和趋势。例如,可以比较药物治疗前后的指标变化,将每个个体的两个时间点的测量结果绘制成散点图,并使用配对线来表示个体之间的相关性。此外,可以使用差异分析方法如配对 t 检验或重复测量方差分析来评估两个时间点之间的差异。
在执行实验/介入研究研究中,可以使用多组散点图和配对连线来比较不同实验组或处理组之间的结果差异。例如,在药物治疗研究中,可以比较不同药物组或剂量组的治疗效果。绘制每个个体在不同组别下的测量结果散点图,并使用配对连线来表示个体之间的配对关系。然后,使用差异分析方法如方差分析(ANOVA)来评估组别之间的差异。
在教育研究中,可以使用多组散点图和配对连线来比较教学干预对学生学业成绩的影响。例如,可以比较不同教学方法或教学环境下的学生成绩。绘制每个学生在不同条件下的成绩散点图,并使用配对连线表示每个学生的配对关系。然后,使用差异分析方法如配对 t 检验或重复测量方差分析来评估教学干预的效果。
(3)代码实现
install.packages("tidyverse")
install.packages("reshape2")
install.packages("ggthemes")
install.packages("rstatix")# 生成示例数据
dt = data.frame(sample = paste0('sample',1:25),
A = runif(25,5,368),
B = runif(25,100,400),
C = runif(25,1,200))
head(dt)
# 长宽转换
library(tidyverse)
library(reshape2)
dt_long <- melt(dt,
measure.vars = c("A","B",'C'),
variable.name = "group",
value.name = "value")
# 绘图
library(ggplot2)
library(ggthemes)
head(dt_long)
# 绘制散点图+配对连线
p1 <- ggplot(dt_long,aes(group, value, fill = group))+
geom_line(aes(group = sample),
size = 0.5)+#图层在下,就不会显示到圆心的连线
geom_point(shape = 21,
size = 3,
stroke = 0.6,
color = 'black')+
scale_x_discrete(expand = c(-1.05, 0)) + # 坐标轴起始
scale_fill_manual(values = c('#800040','#fc6666','#108080'))+
geom_rangeframe() + # 坐标轴分离
theme_tufte() +
theme(legend.position = 'none', # 标签字体等
axis.text.y = element_text(size = 14,
face = "bold"),
axis.text.x = element_text(size =14,
face = "bold"),
axis.title.y = element_text(size = 15,
color = "black",
face = "bold")) +
labs(x = ' ',
y = 'Values')p1
# 为了绘制原图的差异形式 手动计算p值
library(rstatix)
result = t_test(dt_long,value~group)
head(result)# 添加显著性标记
p2 <- p1 +
coord_cartesian(clip = 'off',ylim = c(0,500))+
theme(plot.margin = margin(1,0,0,0.5,'cm'))+
annotate('segment',x=1,xend=1.99,y=510,yend=510,color='black',cex=.6)+
annotate('segment',x=1,xend=1,y=505,yend=515,color='black',cex=.6)+
annotate('segment',x=1.99,xend=1.99,y=505,yend=515,color='black',cex=.6)+
annotate('segment',x=2.01,xend=3,y=510,yend=510,color='black',cex=.6)+
annotate('segment',x=2.01,xend=2.01,y=505,yend=515,color='black',cex=.6)+
annotate('segment',x=3,xend=3,y=505,yend=515,color='black',cex=.6)+
annotate('segment',x=1,xend=3,y=530,yend=530,color='black',cex=.6)+
annotate('segment',x=1,xend=1,y=525,yend=535,color='black',cex=.6)+
annotate('segment',x=3,xend=3,y=525,yend=535,color='black',cex=.6)+
annotate("text", x = 1.5, y = 520, label ="p = 0.080",size = 6)+
annotate("text", x = 2.5, y = 520, label ="p = 0.129",size = 6)+
annotate("text", x = 2, y = 540, label ="p = 0.0004",size = 6)
p2
ggsave('绘图.pdf',p2,width = 8,height = 7)输出结果:
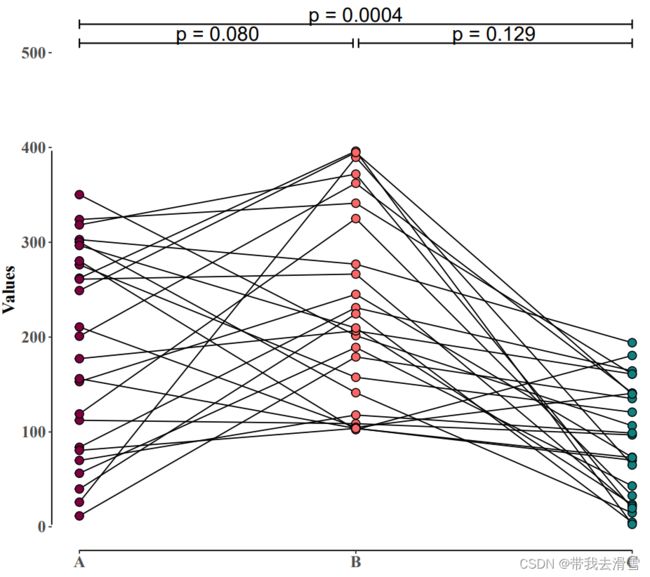
2、云雨图
(1)什么是云雨图?
云雨图(Cloud and Rain Plot)是一种数据可视化图表,被用于展示不同组别或条件下的数据分布和差异。它是一种变种的多组散点图,结合了散点图和柱状图的特点,以形象地呈现数据的分布情况。通常,对于两组或两组以上的数据展示其特征和比较不同组之间的大致差异时,我们会选择箱线图或箱线图加添加扰动的散点图进行展示。但是,由于箱线图和散点图本身的局限,例如不能提供关于数据分布偏态和尾重程度的精确度量、对于批量比较大的数据批,反应的形状信息更加模糊和用中位数代表总体评价水平有一定的局限性等,人们亟需对数据的信息进行更全面可视化的图形。在这种背景下,云雨图也就孕育而成。顾名思义,云雨图即使“云”(小提琴图半边)和“雨”(散点图),外加箱线图的一种联合体。它通过中位数和置信区间很好地提供了原始数据、概率分布和“一目了然的统计推断”的概述。
云雨图由两个部分组成:云部分和雨部分。在云部分:使用散点图来展示数据的分布情况。每一个散点代表一个数据点,它们根据 x 轴上的数值来水平分布,并根据 y 轴上的数值来显示垂直位置。云部分的目的是展示数据的分布情况和密度。在雨部分使用柱状图来展示不同组或条件下的数据统计量,通常是均值或中位数。每个柱状图代表一个组别或条件,其高度表示该组别或条件的数据统计量。雨部分的目的是比较不同组别或条件之间的数据差异。
云雨图的优点是同时展示了数据的分布和差异。云部分提供了对数据分布的直观了解,可以看出数据的聚集程度和离群值的存在。雨部分则强调了组别或条件之间的数值差异,帮助我们理解和比较不同情况下的数据特征。
(2)运用场景
云雨图适用于多种运用场景,其中一些示例包括:
第一,在医学研究中,云雨图可用于展示不同患者群体或治疗方案之间的数据分布和差异。例如,在药物研究中,可以使用云雨图展示不同剂量组中患者的生物标志物水平,同时比较各组之间的数据差异。
第二,在社会科学研究中,云雨图可用于比较不同群体(例如性别、年龄组等)之间的数据分布和差异。例如,在心理学研究中,可以使用云雨图展示不同性别群体在某一心理测量指标上的得分分布,以及性别群体之间的差异。
第三,在市场调研中,云雨图可用于比较不同市场细分或消费者群体之间的数据分布和差异。例如,对于某种产品或服务的用户调研数据,可以使用云雨图展示不同年龄段或地理位置的用户在关键指标上的得分分布,并比较不同群体之间的数据差异。
第四,在教育评估中,云雨图可用于比较不同学校、班级或教育介入项目之间的学业成绩或评估指标的数据分布和差异。例如,可以使用云雨图展示不同学校在某一学科考试成绩上的分布,并比较各学校之间的差异。
第五,在质量控制中,云雨图可用于比较不同生产批次或供应商之间的产品质量数据分布和差异。例如,在制造业中,可以使用云雨图展示不同供应商提供的产品在某项指标上的测试结果分布,并比较各供应商之间的数据差异。
(3)代码实现
install.packages("gghalves")
library(ggplot2)
library(gghalves)dat <- iris[, c(2, 5), drop = F]
dat$Group <- rep(1:(nrow(dat)/3), times = 3)
head(dat, 5)## 绘制“云朵” - 小提琴图的左半边
ggplot(dat, aes(x = Species, y = Sepal.Width, fill = Species))+
geom_half_violin(side = "r", trim = F, color = NA)+
scale_fill_manual(limits = base::unique(dat$Species),
values = rainbow(3))## 添加“雨滴” - 抖动散点图
ggplot(dat, aes(x = Species, y = Sepal.Width, fill = Species))+
geom_half_violin(side = "r", trim = F, color = NA, alpha = 0.75,
position = position_nudge(x = 0.15, y = 0))+
geom_point(aes(x = as.numeric(Species) - 0.15, y = Sepal.Width, color = Species),
position = position_jitter(width = 0.05, seed = 2021), size = 0.8, shape = 19)+
scale_fill_manual(limits = base::unique(dat$Species),
values = rainbow(3))## 添加箱线图,并更改为经典主题背景
ggplot(dat, aes(x = Species, y = Sepal.Width, fill = Species))+
geom_half_violin(side = "r", trim = F, color = NA, alpha = 0.75,
position = position_nudge(x = 0.15, y = 0))+
geom_point(aes(x = as.numeric(Species) - 0.15, y = Sepal.Width, color = Species),
position = position_jitter(width = 0.05, seed = 2021), size = 0.8, shape = 19)+
geom_boxplot(width = 0.1, alpha = 0.75)+
scale_fill_manual(limits = base::unique(dat$Species),
values = rainbow(3))+
theme_classic()
## 翻转图形
ggplot(dat, aes(x = Species, y = Sepal.Width, fill = Species))+
geom_half_violin(side = "r", trim = F, color = NA, alpha = 0.75,
position = position_nudge(x = 0.15, y = 0))+
geom_point(aes(x = as.numeric(Species) - 0.15, y = Sepal.Width, color = Species),
position = position_jitter(width = 0.05, seed = 2021), size = 0.8, shape = 19)+
geom_boxplot(width = 0.1, alpha = 0.75)+
scale_fill_manual(limits = base::unique(dat$Species),
values = rainbow(3))+
coord_flip()+
theme_classic()
p2=ggplot(dat, aes(x = Species, y = Sepal.Width, fill = Species))+
geom_half_violin(side = "r", trim = F, color = NA, alpha = 0.75,
position = position_nudge(x = 0.15, y = 0))+
geom_point(aes(x = as.numeric(Species) - 0.15, y = Sepal.Width, color = Species),
position = position_jitter(width = 0.05, seed = 2021), size = 0.8, shape = 19)+
geom_boxplot(width = 0.1, alpha = 0.75)+
scale_fill_manual(limits = base::unique(dat$Species),
values = rainbow(3))+
coord_flip()+
theme_classic()ggsave('绘图2.pdf',p2,width = 8,height = 7)
输出结果:
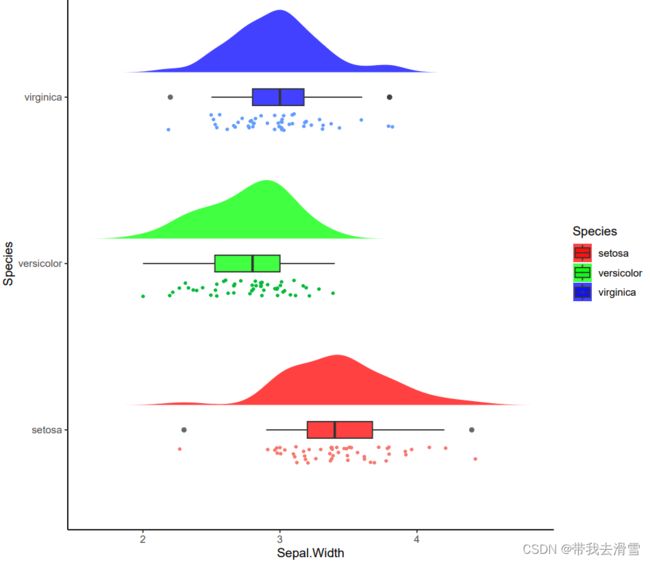
3、山脊图
(1)什么是山脊图?
山脊图(Ridge Plot)是一种数据可视化图表,用于展示多个核密度估计曲线(Kernel Density Estimation, KDE)的堆叠。它被用于可视化多个分布的形状和相对关系,尤其在比较不同组别或条件下的数据分布时非常有用。在山脊图中,每个核密度估计曲线代表一个组别或条件。这些曲线在水平轴上对齐,并根据其相对密度进行堆叠,形成一种山脊状的图像。曲线的高度表示对应组别的相对密度或频率。
山脊图通常使用半透明的颜色来绘制曲线,使得堆叠的部分可以透过看到下方的曲线,以显示整体和局部的分布情况。同时,可以通过曲线的颜色来区分不同组别或条件。
(2)应用场景
第一,在统计分析和数据探索中,山脊图可以展示不同样本、组别或条件下的数据分布情况,帮助研究人员观察和比较分布的形状、峰值位置和相对密度。
第二,在机器学习和分类任务中,山脊图可用于可视化不同类别的特征变量分布,帮助理解类别之间的相似性和差异性,从而指导特征选择和模型建立。
第三,在市场研究和用户行为分析中,山脊图可用于展示不同用户群体或市场细分的行为数据分布,例如购买行为、用户偏好等,以辅助市场定位和目标用户群体的识别。
(3)代码实现
install.packages("ggridges")
install.packages("cols4all")
library(ggridges)
library(ggplot2)
library(cols4all)df <- iris
df
p <- ggplot(data = df,
aes(x = Sepal.Length, y = Species, fill = Species)) +
geom_density_ridges() +
theme_classic()
p
ggsave('绘图3.pdf',p,width = 8,height = 7)输出结果:
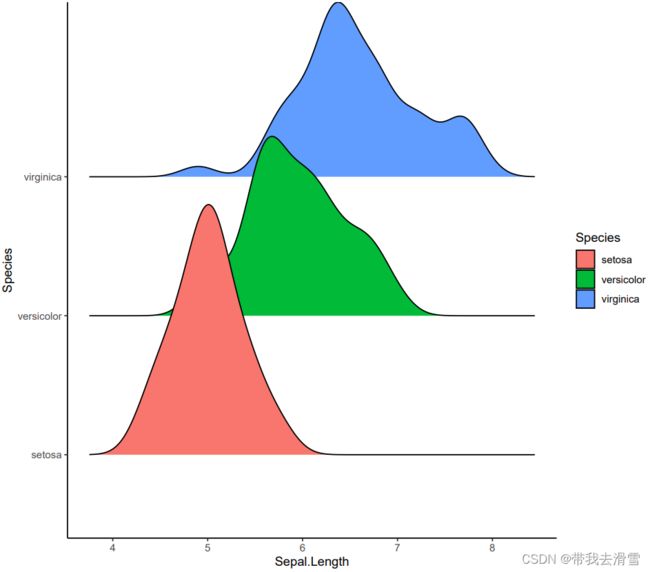
需要数据集的家人们可以去百度网盘(永久有效)获取:
链接:https://pan.baidu.com/s/1E59qYZuGhwlrx6gn4JJZTg?pwd=2138
提取码:2138
更多优质内容持续发布中,请移步主页查看。
点赞+关注,下次不迷路!