数据预处理matlab
matlab数据的获取、预处理、统计、可视化、降维
数据的预处理 - MATLAB & Simulink - MathWorks 中国 https://ww2.mathworks.cn/help/matlab/preprocessing-data.html
https://ww2.mathworks.cn/help/matlab/preprocessing-data.html
一、数据的获取
1.1 从Excel中获取
使用readtable()
例1:
使用spreadsheetImportOptions(Name,Value)初步确定导入信息,
再用opts.Name=Value的格式添加。
% 工作簿: C:\Users\Hao\Desktop\程序_MATLAB数学建模方法与实践_卓金武等\Cha2\sz000004.xls
% 工作表: Sheet1
%% 设置导入选项并导入数据
opts = spreadsheetImportOptions("NumVariables", 8);%变量数8
%spreadsheetImportOptions允许指定 MATLAB® 如何从电子表格文件中导入表格数据
% 指定工作表和范围
opts.Sheet = "Sheet1";
opts.DataRange = "A1:H45";
% 指定列名称和类型
opts.VariableNames = ["Date", "DateNum", "Popen", "Phigh", "Plow", "Pclose", "Volum", "Turn"];
opts.VariableTypes = ["double", "double", "double", "double", "double", "double", "double", "double"];
% 导入数据
sz000004 = readtable("C:\Users\Hao\Desktop\程序_MATLAB数学建模方法与实践_卓金武等\Cha2\sz000004.xls", opts, "UseExcel", false);
%% 清除临时变量
clear opts例2:
先初始化spreadsheetImportOptions对象,
再用opts.Name=Value的格式逐个添加。
% 初始化 SpreadsheetImportOptions 对象
opts = spreadsheetImportOptions;
% 指定变量名称
opts.VariableNames = 'LastName';
% 变量类型
opts.VariableTypes = 'categorical';
% 数据起始单元格
opts.DataRange = 'A2';
% 使用导入选项预览文件中的八行数据
preview('patients.xls',opts)
oneVar = readtable('patients.xls',opts);
% 列出变量及大小和类型
whos oneVar例3:
将导入信息存到变量里,
再使用spreadsheetImportOptions(Name,Value)添加导入信息。
% 变量数
numVars = 7;
% 变量名称
varNames = {'LastName','Gender','Age','Location','Height','Weight','Smoker'} ;
% 变量类型
varTypes = {'char','categorical','int32','char','double','double','logical'} ;
% 数据起始单元格
dataStartLoc = 'A2';
% 使用 spreadsheetImportOptions 函数和变量信息初始化导入选项对象 opts
opts = spreadsheetImportOptions('NumVariables',numVars,...
'VariableNames',varNames,...
'VariableTypes',varTypes,...
'DataRange', dataStartLoc);
% 使用导入选项预览文件中的八行数据
preview('patients.xls',opts)
% 使用 readtable 导入数据
T = readtable('patients.xls',opts);
% 列出变量及大小和类型
whos T
注:readtable仅支持下列名称-值对组:
文本和电子表格参数 -
ReadVariableNames、ReadRowNames仅文本参数 -
DateLocale、Encoding仅电子表格参数 -
Sheet、UseExcel
使用xlsread()——xlswrite()
a=xlsread('C:\Coporation_evaluation.xlsx',2,'A2:I16')
% 'C:\Coporation_evaluation.xlsx' 表示读入Excel数据所在位置
% 2 表示位于sheet2
% 'A2:I16' 表示读入的数据范围
a=xlswrite('C:\Coporation_evaluation.xlsx',a,3,'B1:C5')
% 'C:\Coporation_evaluation.xlsx' 表示写入Excel工作簿所在位置,若不存在会自动创建
% a 表示待写入的数据
% 3 表示sheet3
% 'B1:C5' 表示写入Excel中的的具体位置[data,textdata] = xlsread('D:\桌面\xx.xls'),读取的是什么
- 从文件路径为
D:\桌面\xx.xls的 Excel 文件中读取数据,并将数据存储到两个变量data和textdata中。- 其中,
xlsread()是 MATLAB 内置函数,用于读取 Excel 文件中的数据。- 第一个输入参数
'D:\桌面\aa.xls'表示了 Excel 文件的全路径,可以根据实际情况修改该值。- 第二个参数为空,则函数默认读取所有数值型数据;如果指定第二个输出参数名称(如此例中的
textdata),则函数会将 Excel 文件中的文本数据存储到该变量中。
假设我们有一个 Excel 文件,文件路径为 D:\桌面\data.xlsx,它包含以下数据:
| A | B | C | |
| 1 | 10 | 20 | a |
| 2 | 30 | 40 | b |
那么,我们可以使用以下 MATLAB 代码读取该文件中的数值型和文本数据:
[data, textdata] = xlsread('D:\桌面\data.xlsx');
执行上述代码后,MATLAB 会将该 Excel 文件中的数值型数据存储到 data 变量中,文本数据存储到 textdata 变量中。此时可以在 MATLAB 命令窗口中输入这两个变量名,查看其内容:
data =
10 20
30 40
textdata =
2×1 cell 数组
{2×1 cell}
{2×1 cell}
>> textdata{1}
ans =
'a'
>> textdata{2}
ans =
'b'
- 可见,MATLAB 已经成功地读取了 Excel 文件中的数据,并将其存储到相应的变量中。
- 其中,
textdata变量是一个 2x1 的单元格数组,每个单元格中存储了一列文本数据。 - 我们可以使用花括号
{}来访问单元格中的内容,如textdata{1}访问第一列的文本数据。
1.2 从TXT中获取
使用load()
% 生成线性间距向量,返回包含 1 和 30 之间的 8(默认100)个等间距点的行向量
a=linspace(1,30,8);
save d:\exper.txt a -ascii;
b=load('d:\exper.txt')
% save d:\exper.txt a -ascii; 把a以ASCII码的形式存储在D盘的exper.txt中,若不存在会自动创建
% b=load('d:\exper.txt') 读取'd:\exper.txt'中的数据,并储存在变量b中使用textread()
[A,B,C,...]=textread('filename','format',N,'headerlines',M)
% filename 表示txt文件名称
% format 表示所读取变量的字段格式
% N 表示读取的次数
% headerlines 表示从第M+1行开始读取使用字面值读取以忽略匹配的字符https://blog.csdn.net/jk_101/article/details/106495696
[name,type,x,y,answer]=textread('D:t.txt','%s Type%d %f %n %s',2,...
'headerlines',1)
% 格式Type%d只显示%d,因为原数据为Type1,Type2,Type3,Type4例如:
mydata.dat 的第一行如下:
Sally Type1 12.34 45 Yes读取文件的第一行,并忽略第二个字段中的字符 Type。
[names, typenum, x, y, answer] = textread('mydata.dat', ...
'%s Type%d %f %d %s', 1)返回
names =
'Sally'
typenum =
1
x =
12.34000000000000
y =
45
answer =
'Yes'使用fopen() fread() fclose()
例:
读取.m文件中的字符(读取txt文件也可以)
% 用函数fopen打开文件,r代表只读形式打开,w代表写入形式打开,a代表在文件末尾添加内容
fid=fopen('D:\CRM4.m','r'); % fid=fopen('D:\CRM4.m','w')/fid=fopen('D:\CRM4.m','a')
% 以字符形式读取整个文本
var=fread(fid,'*char');
% 将中文字段转换为相应的2字节代码,否则输出可能会乱码
var=native2unicode(var)
fclose(fid)使用fprintf()写入信息到txt
fprintf('file','format',a1,a2...)
% file 表示文件路径
% format 表示数据写入类型
% a 表示要写入的数据内容1.3 从图片中获取
%% 读取图片
clc, clear, close all
a1=imread('000.bmp');
% 获得像素矩阵行数列数
[m,n]=size(a1);
%% 批量读取图片
dirname = 'ImageChips'; % 'ImageChips'文件夹
files = dir(fullfile(dirname, '*.bmp'));
%% fuiifile用法
% f = fullfile('myfolder','mysubfolder','myfile.m')
% f = 'myfolder/mysubfolder/myfile.m'
%% dir用法
% dir name 列出与 name 匹配的文件和文件夹。如果 name 为文件夹,dir 列出该文件夹的内容。使用绝对
% 或相对路径名称指定 name。name 参数的文件名可以包含 * 通配符,路径名称可以包含 * 和 ** 通配符。
% 与** 通配符相邻的字符必须为文件分隔符。
a=zeros(m,n,19); % 创建全零数组19个m*n数组,共19张图片
pic=[];
for ii = 1:length(files)
filename = fullfile(dirname, files(ii).name);
a(:,:,ii)=imread(filename); % 将该图片信息读取到a的第ii个数组里
pic=[pic,a(:,:,ii)]; % 拼接图像
end
double(pic);
figure
imshow(pic,[])
% imshow(I,[low high]) 显示灰度图像 I,以二元素向量 [low high] 形式指定显示范围
% 若为[],使用 [min(I(:)) max(I(:))] 的显示范围。换句话说,I 中的最小值是黑色,最大值是白色1.4 从视频获取
使用视觉工具箱中的VideoFileReader
%% 读取视频数据
% 从视频文件中读取视频帧、图像和音频样本
videoFReader = vision.VideoFileReader('vippedtracking.mp4');
% 播放视频文件
videoPlayer = vision.VideoPlayer;
while ~isDone(videoFReader)
% 当来自有限数据源的数据取完时(通常是因为已读取所有数据),isDone(obj)返回true
% ~逻辑非
videoFrame = step(videoFReader); % 运行videoFReader算法,返回输出参数
step(videoPlayer, videoFrame); % 对videoFrame运行videoPlayer算法
end
release(videoPlayer); %释放资源
%% 设置播放方式
% 重置播放器
reset(videoFReader) % 将图形对象属性重置为其默认值
% 增加播放器的尺寸
r = groot; % r = groot 用于存储图形根对象的句柄。要使用圆点表示法设置根属性,首先必须存储句柄
scrPos = r.ScreenSize;
% Size/position is always a 4-element vector: [x0 y0 dx dy]
dx = scrPos(3); dy = scrPos(4);
videoPlayer = vision.VideoPlayer('Position',[dx/8, dy/8, dx*(3/4), dy*(3/4)]);
% 指定左下角和右上角的坐标
while ~isDone(videoFReader)
videoFrame = step(videoFReader);
step(videoPlayer, videoFrame);
end
release(videoPlayer);
reset(videoFReader)
%% 获取视频中的图像
videoFrame = step(videoFReader);
n = 0;
while n~=15
videoFrame = step(videoFReader);
n = n+1;
end
figure, imshow(videoFrame) % 获得第15张图像
release(videoPlayer);Matlab中fopen函数用法https://blog.csdn.net/jk_101/article/details/106494232
二、数据的预处理
数据质量三要素:准确性、完整性、一致性(格式不一致等)
两个影响因素:可信性(多少是用户信赖的)、可解释性 (是否容易理解)
数据类型的转换https://zhuanlan.zhihu.com/p/217597511
缺失值处理:
一般可删除记录、数据插补和不处理。https://blog.csdn.net/yunlinzi/article/details/90300113
| 可插补方法 | 方法描述 |
| 均值/中位数/众数插补 | 根据属性值的类型, 用该属性取值的平均数/中位数/众数进行插补。 |
| 使用固定值 | 将缺失的属性值用一个常量替换。 如广州一个工厂普通外来务工人员的“基本工资”属性的空缺值, 可以用2015年广州市普通外来务工人员工资标准1895元月, 该方法就是使用固定值。 |
| 最近临插补 | 在记录中找到与缺失样本最接近的样本的该属性值插补 |
| 回归方法 | 对带有缺失值的变量,根据已有数据和与其有关的其他变量(因变量)的数据建立拟合模型来预测缺失的属性值。 |
| 插值法 | 插值法是利用已知点建立合适的插值函数f(x), 未知值由对应点求出的函数值f(x,)近似代替。 |
插值与拟合
插值与拟合的区别和联系
1、联系
都是根据实际中一组已知数据来构造一个能够反映数据变化规律的近似函数的方法。
2、区别
插值问题不一定得到近似函数的表达形式,仅通过插值方法找到未知点对应的值。
数据拟合要求得到一个具体的近似函数的表达式。
插值方法
选用不同类型的插值函数,逼近的效果就不同,一般有:
(1)最近邻算法插值(一维插值)
(2)拉格朗日插值算法(一维插值)
(3)双线性内插算法(二维插值)
(4)分段线性插值(二维插值)
(5)三次样条插值(二维插值)
(6)克里金插值(地理学)
(7)反距离权重插值算法(地理学)
- Matlab 实现:实现分段线性插值不需要编制函数程序,它自身提供了内部的功能函数
- interp1(一维插值)
- interp2(二维)
- interp3(三维)
- intern(n维)

例:从1点12点的11小时内,每隔1小时测量一次温度,测得的温度的数值依次为:5,8,9,15,25,29,31,30,22,25,27,24.试估计每隔1/10小时的温度值.
hours=1:12;
temps=[5 8 9 15 25 29 31 30 22 25 27 24];
h=1:0.1:12;
t=interp1(hours,temps,h,'spline');
plot(hours,temps,'+',h,t,hours,temps,'r:') %作图
xlabel('Hour'),ylabel('Degrees Celsius’)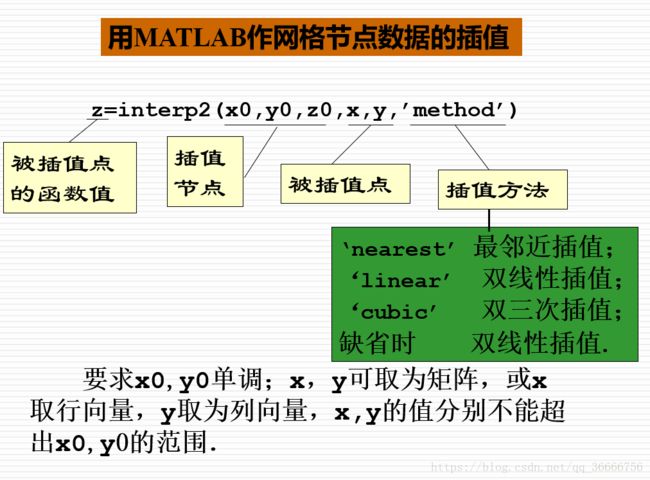
%1.先在三维坐标画出原始数据,画出粗糙的温度分布曲线图.
%输入以下命令:
x=1:5;
y=1:3;
temps=[82 81 80 82 84;79 63 61 65 81;84 84 82 85 86];
mesh(x,y,temps)
%2.以平滑数据,在 x、y方向上每隔0.2个单位的地方进行插值.
再输入以下命令:
xi=1:0.2:5;
yi=1:0.2:3;
zi=interp2(x,y,temps,xi',yi,'cubic');
mesh(xi,yi,zi)
%画出插值后的温度分布曲面图.
例 在某海域测得一些点(x,y)处的水深z由下表给出,船的吃水深度为5英尺,在矩形区域(75,200)×(-50,150)里的哪些地方船要避免进入.
%1.输入插值基点数据
%2.在矩形区域(75,200)×(-50,150)进行插值。
%3. 作海底曲面图
%4.作出水深小于5的海域范围,即z=5的等高线
%程序一:插值并作海底曲面图
x =[129.0 140.0 103.5 88.0 185.5 195.0 105.5 157.5 107.5 77.0 81.0 162.0 162.0 117.5 ];
y =[ 7.5 141.5 23.0 147.0 22.5 137.5 85.5 -6.5 -81 3.0 56.5 -66.5 84.0 -33.5 ];
z =[ 4 8 6 8 6 8 8 9 9 8 8 9 4 9 ];
x1=75:1:200;
y1=-50:1:150;
[x1,y1]=meshgrid(x1,y1);
z1=griddata(x,y,z,x1,y1,'v4');
meshc(x1,y1,z1)
%程序二:插值并作出水深小于5的海域范围。
x1=75:1:200;
y1=-50:1:150;
[x1,y1]=meshgrid(x1,y1);
z1=griddata(x,y,z,x1,y1,'v4'); %插值
z1(z1>=5)=nan; %将水深大于5的置为nan,这样绘图就不会显示出来
meshc(x1,y1,z1)
异常值处理:
- 异常值是数据集中偏离大部分数据的数据。
- 从数据值上表现为:数据集中与平均值的偏差超过两倍标准差的数据,
- 其中与平均值的偏差超过三倍标准差的数据,称为高度异常的异常值。
小波异常值提取
信号的突变点和奇异点等不规则部分通常包含重要信息,一般信号的奇异性分为两种情况:
- 信号在某一时刻其幅值发生突变,引起信号的非连续,这种类型的突变称为第一类型的间断点;
- 信号在外观上很光滑,幅值没有发生突变,但是信号的一阶微分有突变发生且一阶微分不连续,这种类型的突变称为第二类型的间断点。
- 应用小波分析可以检测出信号中的突变点的位置、类型以及变化的幅度。
例:第一类型间断点的检测
- 本例中,信号的不连续是由于低频特征的正弦信号在后半部分突然有高频特征的正弦信号加入,
- 首先利用傅里叶变换分析对信号在频域进行分析,发现无检测突变点,
- 接着利用小波分析进行分析,结果证明它能够准确地检测出了信号幅值突变的位置,即高频信号加入的时间点。
load freqbrk;
x=freqbrk;%对信号进行傅里叶变换
f=fft(x,1024);
f=abs(f);
figure;
subplot(211);
plot(x);
subplot(212);
plot(f);
%使用db6小波进行6层
[c,l]=wavedec(x,6,’db6’);
figure(2);
subplot(811);
plot(x);
ylabel('x');
%对分解的第六层低频系数进行重构
a=wrcoef('a',c,l,'db6',6);
subplot(812);
plot(a);
ylabel('a6');
for i=1:6 %对分解的第6层到第1层的高频系数分别进行
d=wrcoef('d',c,l,'db6',7-i);
subplot(8,1,i+2);
plot(d);
ylabel(['d',num2str(7-i)]);
end经验第一类突变用db6小波分解
第二类db4小波分解
load nearbrk;
x=nearbrk;
%使用db4对信号进行2层分解
[c,l]=wavedec(x,2,‘db4’);
subplot(411);
plot(x);
ylabel('x');
%对分解的第六层低频系数进行重构
a=wrcoef('a',c,l,'db4',2);
subplot(412);
plot(a);
ylabel('a2');
for i=1:2%对分解的第2层到第1层的高频系数进行重构
a=wrcoef('a',c,l,'db4',3-i);
subplot(4,1,i+2);
plot(d);
ylabel(['d',num2str(3-i)]);
end去除首尾无效数据https://blog.csdn.net/FDA_sq/article/details/124250130
举例:铣削进刀过程
- 信号数据的首部有铣削进刀过程导致的信号逐渐变大的数据,
- 相应的图中数据尾部有一段结束铣削退刀造成的逐渐变小的数据,
- 这两段数据为非正常铣削信号数据,因此是需要人工剔除的无效数据。
原理:
- 求取每次走刀过程首尾部无效数据的临界值:每次走刀原始数据的上四分位值Q。
- 原始数据的首部从前往后寻找第一个大于等于Q的数据作为进刀结束位置,剔除前面所有小于Q的信号数据;
- 同理,尾部从后往前寻找第一个大于等于Q的数据作为退刀开始位置,剔除后面所有小于Q的数据。
%使用函数:
Q=quantile(x,y,z)
% x表示要求的矩阵或者向量;y的取值为表示要求的分位数,
% 如四分之一中位数0.25,四分之三中位数0.75等;
% z的取值为1或者2,若值为1则表示按列求四分位数,若为2表示按行求四分位数。
% Q为计算的上四分位值,常用大小为 (1,n).
%注:对于向量,
Q2=quantile(raw_data,0.75,1)
%等同于Q3 = prctile(raw_data,75)重复值剔除https://blog.csdn.net/qq_43657442/article/details/118891434
使用 unique 函数,
直接删除重复行
unique(A,'rows',setOrder)
%其中,setOrder 参数有两种取值,默认是’sorted’ 即去掉重复后排序输出(以第一个元素大小位依据),
%另一个是'stable' 代表去掉重复后按原来顺序输出示例
>> a=[1 0 1;1 0 1; 1 1 1;2 5 1; 1 1 1;0 1 2 ;0 4 5 ;0 1 2]
a =
1 0 1
1 0 1
1 1 1
2 5 1
1 1 1
0 1 2
0 4 5
0 1 2
>> unique(a,'row','stable')
ans =
1 0 1
1 1 1
2 5 1
0 1 2
0 4 5
>> unique(a,'row')
ans =
0 1 2
0 4 5
1 0 1
1 1 1
2 5 1
>>
按列删除重复行
[C,ia,ic] = unique(dataRed(:,1:2),'rows'):
% 基于1、2列的数据查找dataRed中所有的唯一行。
% 指定三个输出以返回索引向量 ia 和 ic。
uA = dataRed(ia,:)
%使用 ia 对 dataRed 进行索引并检索包含前两列中元素的唯一组合的行。
dataRed(:,1:2)选择了dataRed中所有行的前两列。这通常是为了查找数据中某些列的唯一组合而不考虑其他列。'rows'参数告诉 MATLAB 在比较每个行时要考虑其顺序,因此只有包含相同值且相同顺序的行才会被视为相等。- 执行
unique函数,将前两列看作一个矩阵,并返回所有唯一行的排序结果。结果分别存储在三个变量C、ia和ic中。
具体来说,输出参数包含以下内容:
C:一个矩阵,其中包含了输入矩阵的所有唯一行,按首次出现顺序排列。ia:一个向量,其中包含了在输入矩阵中所选列的所有唯一行的索引。对于输入矩阵中的每个行,ia中的相应元素是C中相应行的索引。ic:一个向量,与输入矩阵大小相同,其中包含了输入矩阵中每个行的索引,以指示它在C中的位置。
假设有一个矩阵 dataRed 包含以下内容:
dataRed = [1, 2, 3;
4, 5, 6;
7, 8, 9;
1, 2, 3;
4, 5, 6];
调用 unique 函数:
[C,ia,ic] = unique(dataRed(:,1:2),'rows');
然后,MATLAB 将返回以下结果:
C =
1 2
4 5
7 8
ia =
1
2
3
ic =
1
2
3
1
2
这意味着,dataRed 矩阵中前两列的唯一组合是 (1, 2)、(4, 5) 和 (7, 8)。
ia 向量包含了这些行在 C 矩阵中所处的位置,
而 ic 向量指示了矩阵 dataRed 中的每个行在 C 矩阵中的位置。
matlab 找到非空的位置 去除重复数据/去除NaNhttps://blog.csdn.net/qq_20784777/article/details/126480643?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0-126480643-blog-118891434.235%5Ev35%5Epc_relevant_increate_t0_download_v2&spm=1001.2101.3001.4242.1&utm_relevant_index=3
找到非空的位置
matlab中find()函数用法 https://blog.csdn.net/qq_45767476/article/details/109081132
find()函数
idx = find(isnan(data));
- 用于查找一个向量或矩阵中所有包含 NaN(Not-a-Number)元素的下标索引。
- 具体地说,该语句执行以下步骤:
- isnan(data)返回一个与data相同大小的逻辑数组,其中包含了data中每个元素是否为NaN的信息。
- 如果是NaN,则该位置为1;否则为0。
- find()函数获取输入参数中非零元素的下标,因此对于isnan(data)返回的逻辑数组,
- find()将会返回一个包含了所有为1的元素所在位置的下标向量。
- 因此,最终得到的结果是一个列向量idx,其中包含了所有data中NaN值的下标索引。
idx = find(~isnan(data));
- 用于查找一个向量或矩阵中所有不包含 NaN(Not-a-Number)元素的下标索引。
- 具体地说,该语句执行以下步骤:
- isnan(data)返回一个与data相同大小的逻辑数组,其中包含了data中每个元素是否为NaN的信息。
- 如果是NaN,则该位置为1;否则为0。
- 在此语句中,~运算符对逻辑数组进行求反操作,即将1变为0,0变为1。
- 因此,得到的逻辑数组表示data中所有不是NaN的元素的位置。
- find()函数获取输入参数中非零元素的下标,因此对于~isnan(data)返回的逻辑数组,
- find()将会返回一个包含了所有为1的元素所在位置的下标向量。
- 因此,最终得到的结果是一个列向量idx,其中包含了所有data中非NaN值的下标索引。
例如,假设有一个5x5的矩阵A,其中包含5个NaN值。
可以通过以下方式找到这些NaN值所在的位置:
A = [1 2 NaN 4 5;
6 NaN 8 9 10;
11 12 13 NaN 15;
16 17 18 19 NaN;
NaN 21 22 23 24];
idx = find(isnan(A))
结果
idx =
3
7
12
20
25
这意味着,A矩阵的第3、7、12、20和25个元素是NaN。
可以通过以下方式找到这些非NaN值所在的位置:
A = [1 2 NaN 4 5;
6 NaN 8 9 10;
11 12 13 NaN 15;
16 17 18 19 NaN;
NaN 21 22 23 24];
idx = find(~isnan(A))
结果
idx =
1
2
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
21
22
23
24
isnan()函数用法https://blog.csdn.net/Intangilble/article/details/83786589
isnan(A):
%判断数组的元素是否是NaN。(True for Not-a-Number.)
%用法说明:
B = isnan(A)
%返回一个与A相同维数的数组;
%若A的元素为NaN(非数值),在对应位置上返回逻辑1(真),否则返回逻辑0(假)。例子
(InF 代表正无穷量;-InF 代表负无穷量;NaN代表非数值量;)
>>isnan([pi NaN Inf -Inf])
ans =
1×4 logical 数组
0 1 0 0
[data in] = unique(data(:, n)):
b = unique(A)
b = unique(A,'rows')
[b,m,n] = unique(...)
%描述
%1、b = unique(A) 返回的是和A中一样的值,但是没有重复元素。产生的结果向量按升序排序。
%A可以是一个字符串的单元阵列。
%2、b = unique(A,'rows') 返回的是A中的唯一的行数。
%3、[b,m,n] = unique(...) 也返回索引向量m和n,使得B = A(M) 和 A= B(N).
%m的每一个元素是最大的下标,使得B = A(M). 对于行的组合,B = A(M,:) 和 A= B(N,:) 剔除异常值及平滑处理https://www.bilibili.com/read/cv9279417
使用深度学习进行“序列到序列”回归https://ww2.mathworks.cn/help/deeplearning/ug/sequence-to-sequence-regression-using-deep-learning.html