干货!机器学习遇上运筹优化,助力企业降本增效:一种双层优化方法
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

运筹帷幄,决胜千里。运筹优化(Operations Research)作为数学、计算机科学、管理学的交叉学科,如今广泛应用在企业的生产、运营、物流环节,通过计算机算法指导和辅助人类管理者进行决策。在这篇NeurlPS21论文中,本文提出了一种将最新的机器学习技术(强化学习、图神经网络)与传统优化算法结合的框架,弥补了现有机器学习框架难收敛、模型容量要求高的缺陷,在3个真实的组合优化问题上显著地提升了传统算法的求解性能。
本期AI TIME PhD直播间,我们邀请到上海交通大学博士生——汪润中,为我们带来报告分享《机器学习遇上运筹优化,助力企业降本增效:一种双层优化方法》。

汪润中:
上海交通大学三年级博士生,师从严骏驰副教授和杨小康教授,主要研究方向是机器学习-传统算法融合的组合优化和图论求解。汪润中已在CVPR、ICCV、NeurlPS、TPAM上发表第一作者论文7篇,担任CVPR、 ICCV NeurlPS、 ICLR、ECCV、AAAI等会议的审稿人。
01
Background
本文的主要研究内容针对于如何处理组合优化问题,组合优化问题如标题中所提到的运筹优化中的重要分支。
例如计算任务的调度问题,在调度问题中需合理安排计算资源及数据中的CPU的核数指派到合适的任务,实现最大效率的完成,优化目标是最小化完成所有任务的时间;
又如图学习或机器学习中常用到的,图编辑距离,图学习中常用的图之间的距离度量,它通过衡量从图1到图2之间最短的编辑路径所对应的最小的编辑代价来衡量两张图的相似程度,也是一个NP-hard的优化问题,目标为最小化图上的编辑代价;或汉密尔顿回路问题以及著名的欧拉七桥问题等。
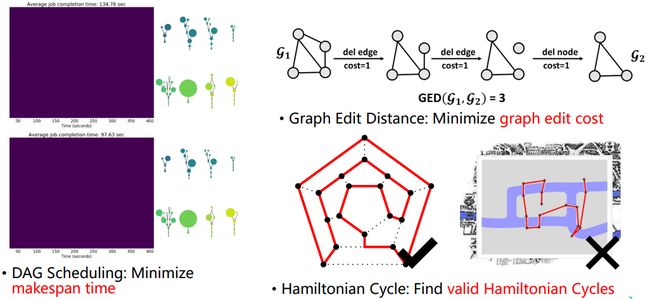
图1 Combinatorial Optimization Problems on Graphs
基于这些组合优化问题在各个领域研究应用都很广泛,但其中也存在一些问题,如组合优化问题都拥有最坏情况下的指数时间的复杂度,本质上来讲这些问题具有NP-complete或NP-hard的复杂度。
另一方面在实际中,经常不停的求解结构相似甚至数据分布上同质的问题。基于以上假设,学者们开始尝试使用数据驱动方法来处理组合优化的问题。
02
Existing Papers:Single-Level Optimization
目前关于此类问题研究的方法都可被总结为single-level optimization的优化形式,如图2所示。在此形式下,寻找合适的x以最小化函数f。式中x为决策变量,f(x)为目标函数,s.t.表示约束条件。
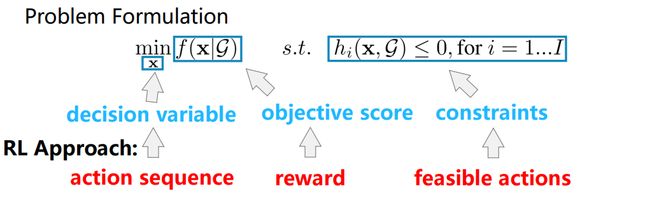
图2 Single-Level Optimization
现如今主流思路为使用强化学习来学习整个求解过程,主要是由于问题本身单独为NP-hard问题,大部分问题得不到最优解,无法进行端到端的训练。在RL框架下,决策变量会被一系列决策替代,目标函数对应RL中的reward,约束条件通过限制RL的agent动作的范围来实现。
本文通过研究发现,对于稍大规模的问题如果决策变量规模较大,动作的序列会变长,会导致sparse reword,使得RL比较难以学到有用的信息;除此之外,上述框架暗含了一个假设,即模型存在直接从G学习到x的能力,学习端到端的映射。
这为模型的容量设计带来了挑战,意味着需要为特定问题,特定的数据分布去设计不同的模型结构才能实现如此大的模型容量。
为了解决上述问题,传统的解决方法通过修改问题本身的结构来辅助问题的求解。例如在求解整数规划问题时割平面法即通过添加额外的约束(割平面),来辅助问题能够更好更快的解决。
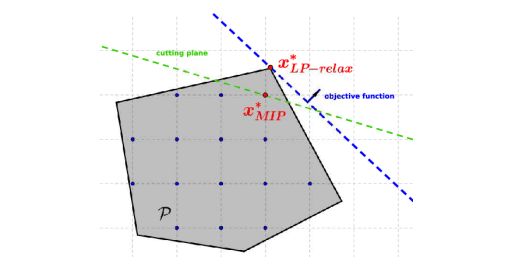
图 3 Add cutting planes for integer programming
本文发现,在计算任务调度问题中,通过修改原先数据有向无环图的结构,如加两条边,同样一个算法能够在两种修改条件下获得不一样的结果,原先21s完成的任务可被缩短到16s。通过该思路,可实现对问题求解的优化。
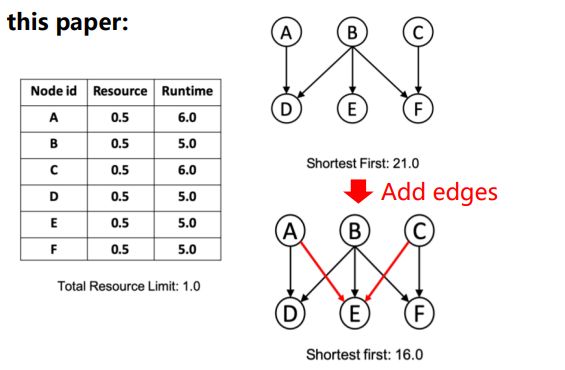
图4 Modify the graph structure to aid problem solving
03
Our Formulation:Bi-Level Optimization
基于以上观察和思路,本文提出了一个双层优化(Bi-Level)方法,其核心引入一个新的变量称为优化过的图结构G’,基于G’给出双层优化的形式,如图5所示。图中上方红色框内表示上层优化部分(Upper-Level Optimization),蓝色框内表示下层优化部分(Lower-Level Optimization)。其中上层优化目标为G’,下层优化目标为一个决策变量与单层优化形式类似。可以发现目标函数及约束条件都是相对于G’。而对于上层优化,通过优化G’来实现对最终目标函数值在原先图中G目标函数值的优化。
上层优化的约束针对于G’图结构,且要求新的图结构与原先的图结构足够相似,要求新问题中的可行域不会扩大,保证求出的决策变量一定落在原先的可行域中,保证整个框架的合理性。具体来说,上层采用强化学习模型来做,下层的优化直接采用现有的传统求解方法进行处理。

图5 Bi-Level Optimization
基于上述框架,本文提出了一个强化学习-传统算法融合的方法如图6所示。针对输入的图结构,首先调用一个传统算法可以求出一个解,在此基础上,加入ReNet Attention GNN 组成的强化学习模型进行决策,该模型在图上预测图如何修改的概率,图中红色的深浅代表了不同的预测概率。
基于预测概率,进行决策,对图的结构进行修改。基于新的图结构,再次调用传统算法得到新的解,继续调用RL修改图结构,不断循环。图中蓝色为用来做决策的上层算法,通过PPO进行学习。下层黄色表示传统求解算法。蓝色G’表示上层优化需解决的问题,黄色X’表示下层优化需要处理的内容。由于采用强化学习进行学习,总目标函数会作为回馈函数来指导搜索与学习。
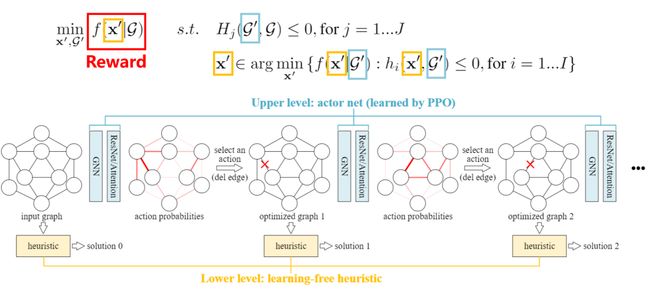
图6 Bi-Level Optimization by Reinforcement Learning
同时本文也进行了一些理论上的分析。本文基于假设内容原先图上的最优解x*可以通过不停的修改图结构来得到。由于直接证明难度较大,因此添加一定限制条件,如图7所示。但仍须注意的是找到最优的图结构本质上依旧是NP-hard,本文通过理论上的分析证明优化图结构本身是可行的,同时可启发通过该方向开发性能更强更有用的算法。

图7 限制条件
在三个问题上具体的实现可发现该框架的通用性,该方法在三个问题上基本上维持了一个比较general的特性如图8所示。

图8 Implement on 3 Combinatorial Optimization Problems
04
Experiment Results
在上述三个问题上比较了传统learning-free、single-level baseline、random baseline及本文所提出的bi-level method。可以发现,在计算任务调度上可达到10%的提升,在图编辑距离上为10%-20%的提升;在汉密尔顿回路问题上,大概可多找到5%的汉密尔顿回路。除此之外,本文所提出的算法也可以在不同规模问题上达到一个较好的泛化性能,也是具体应用实践中所需要的。
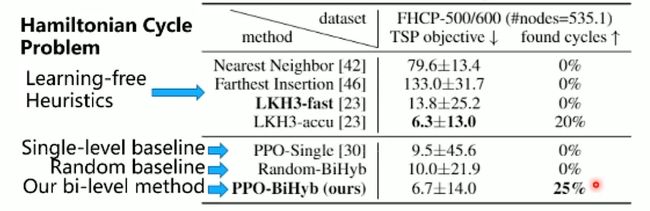
图9 Outperform learning-free and learning-based baselines

图10 Generalize with different training/testing sizes
提
醒
论文链接:
https://arxiv.org/pdf/2106.04927.pdf
论文题目:
A Bi-Level Framework for Learning to Solve Combinatorial Optimization on Graphs
点击“阅读原文”,即可观看本场回放
整理:江璐鑫
作者:汪润中
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了600多位海内外讲者,举办了逾300场活动,超150万人次观看。

我知道你
在看
哦
~
![]()
点击 阅读原文 查看回放!