OpenCV的HSV颜色空间在无人车中颜色识别的应用
- Python
- 机器人操作系统(ROS)
- cv2.erode腐蚀
- cv2.dilate膨胀
- findContours
- bgr8_to_jpeg
- cv2.circle
- cv2.rectangle
- cv2.resize
RGB属于三基色空间,是大家最为熟悉的,看到的任何一种颜色都可以由三基色进行混合而成。然而一般对颜色空间的图像进行有效处理都是在HSV空间进行的,HSV(色调Hue,饱和度Saturation,亮度Value)是根据颜色的直观特性创建的一种颜色空间, 也称六角锥体模型。
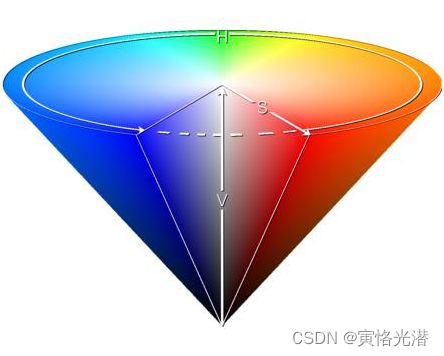
在OpenCV中HSV颜色空间的取值范围=> H:[0, 180],S:[0, 255],V:[0, 255],H色调越小越接近于红色,越高越接近于蓝色,这种表达方式也要比单纯使用红色来表示红色更加准确;S饱和度越小颜色越淡,越大颜色越浓;V亮度越小就越暗,越大越明亮。注意观察上面图片颜色的变化!
之所以选择HSV,是因为H代表的色调基本上可以确定某种颜色,再结合饱和度和亮度信息判断大于某一个阈值。而RGB 由三个分量构成, 需要判断每种分量的贡献比例。HSV空间的识别的范围更广,使用起来更方便。
1、实例演示
我们来看一个实例,拿一包蓝色外包装的宽窄香烟,识别并跟踪颜色。
1.1、颜色识别跟踪
由于本人台式机没有安装摄像头,这里使用无人车上面的摄像头,其获取摄像头视频的方法与OpenCV有点点区别,也差不多,毕竟是在OpenCV的基础上来的。
from jetbotmini import Camera
from jetbotmini import bgr8_to_jpeg
import cv2
import numpy as np
import traitlets
import ipywidgets.widgets as widgets
from IPython.display import display
# 目标颜色,这里设置为蓝色数组
color_lower = np.array([100,43,46])
color_upper = np.array([124, 255, 255])
# 相机实例
camera = Camera.instance(width=720, height=720)
# 显示控件(视频也是图片的连续帧)
color_image = widgets.Image(format='jpeg', width=500, height=400)
display(color_image)
# 实时识别颜色并反馈到上面的控件里
while 1:
frame = camera.value # (720, 720, 3) (H,W,C)
frame = cv2.resize(frame, (400, 400)) # (400, 400, 3)
frame = cv2.GaussianBlur(frame,(5,5),0) # 高斯滤波(5, 5)表示高斯矩阵的长与宽都是5,标准差为0
hsv = cv2.cvtColor(frame,cv2.COLOR_BGR2HSV)#将BGR转成HSV
mask=cv2.inRange(hsv,color_lower,color_upper)
mask=cv2.erode(mask,None,iterations=2) # 进行腐蚀操作,去除边缘毛躁
mask=cv2.dilate(mask,None,iterations=2) # 进行膨胀操作
mask=cv2.GaussianBlur(mask,(3,3),0)
cnts=cv2.findContours(mask.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)[-2] # 轮廓
if len(cnts)>0:
cnt = max(cnts,key=cv2.contourArea) # 轮廓面积
(color_x,color_y),color_radius=cv2.minEnclosingCircle(cnt) # 外接圆的位置信息
if color_radius > 10:
# 圆圈标注
cv2.circle(frame,(int(color_x),int(color_y)),int(color_radius),(255,0,255),2)
color_image.value = bgr8_to_jpeg(frame) # 转成图片传入Image组件
可以看到,粉红色的圆圈,在追踪画面中的蓝色。其中摄像头的用法与widgets中有很多的web交互组件,有兴趣的可以查阅:无人车的摄像头的实时捕获图片以及widgets小部件的相关操作
这段代码的意思就比较清晰了,实例化摄像头,将每一帧图像中按照不同颜色的HSV色域空间进行分类标记出来,通过 cv2.cvtColor(frame,cv2.COLOR_BGR2HSV) 先将BGR(这里读取到的图片是BGR而不是RGB)转换成HSV,将掩码mask和原图片进行按位与操作,找到颜色后,在颜色的轮廓上画出圆形(最小外接圆)进行标注。 如果在环境光充足的情况下,识别效果不太理想的话,我们可以在死循环里面的进行手动的更改一些参数的设置。
1.2、cv2.inRange
接下来对上述代码中的一些函数进行解释
在做mask的时候,mask=cv2.inRange(hsv,color_lower,color_upper) 这个就是低于下边界数组和高于上边界数组的值为0黑色,介于之间的为255白色,属于单通道。我们来看代码直观了解下:
import cv2
import matplotlib.pyplot as plt
img_cv2 = cv2.imread('test.jpg')
hsv = cv2.cvtColor(img_cv2, cv2.COLOR_BGR2HSV)
lowerb = np.array([20, 20, 20])
upperb = np.array([200, 200, 200])
# 黑白单通道(H,W)
mask = cv2.inRange(hsv, lowerb, upperb)
cv2.imshow('Display', mask)
cv2.waitKey(0)
cv2.destroyAllWindows()
plt.subplot(1,2,1); plt.imshow(img_cv2,aspect='auto');plt.axis('off');plt.title('BGR')
plt.subplot(1,2,2); plt.imshow(mask,aspect='auto');plt.axis('off');plt.title('mask')
plt.show()如下图BGR和mask:

1.3、cv2.erode和cv2.dilate
腐蚀操作,属于图像形态学,跟字面意思一样,进行腐蚀,我们可以查看下这个函数的帮助:
erode(src, kernel[, dst[, anchor[, iterations[, borderType[, borderValue]]]]]) -> dst
src原图跟目标图dst的大小是一样的,然后这里的kernel核的大小决定腐蚀的大小,可选。代码测试下:
import cv2
import numpy as np
image = cv2.imread('test.jpg')
kernel = np.ones((5, 5), np.uint8)
image = cv2.erode(image, None)
cv2.imshow('erode', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
其中这里的 image = cv2.erode(image, None) 第二个kernel参数可以指定也可以不指定,指定之后image = cv2.erode(image, kernel),以及修改kernel 中的大小看下效果:

实质也是做卷积运算,对于不是1的操作内的数置0,只有全为1才为1。作用如同代码中的注释,用来去掉边缘一些噪声毛刺等。cv2.dilate膨胀函数,这个可以看成是腐蚀函数的反向操作,腐蚀之后就是黑色部分扩大,膨胀函数就是缩小。
1.4、cv2.GaussianBlur
高斯模糊也是用来去噪的,我们来看下对一张图片加了高斯噪声之后,再通过这个函数来做个去噪的效果,主要针对高斯噪声:
import cv2 as cv
import numpy as np
def myShow(name,img):
cv.imshow(name,img)
cv.waitKey(0)
cv.destroyAllWindows()
# 加高斯噪声
def addGauss(img,mean=0,val=0.01):
img = img / 255
gauss = np.random.normal(mean,val**0.05,img.shape)
img = img + gauss
return img
img = cv.imread('gauss.png')
img1 = addGauss(img)
myShow('img1',img1)
img2 = cv.GaussianBlur(img1,(3,3),0)
myShow('img2',img2)这里我将原图和加了高斯噪声与降噪处理的三张图放在了一起,如下图:

1.5、cv2.findContours和drawContours
查找轮廓函数findContours(image, mode, method[, contours[, hierarchy[, offset]]]) -> contours, hierarchy 是在二值图像中检测,所以我们先将其转成灰度图片,通过threshold转成二值图片。
最后我们将轮廓画出来,使用 drawContours(image, contours, contourIdx, color[, thickness[, lineType[, hierarchy[, maxLevel[, offset]]]]]) -> image
我们来看下代码的实现:
import cv2
import numpy as np
image = cv2.imread('test.jpg')
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
image = cv2.drawContours(image,contours,-1,(255,0,0),2)
#cv2.imshow('erode',binary)
cv2.imshow('erode',image)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.RETR_EXTERNAL:检测外轮廓,忽略轮廓内部的结构。
cv2.CHAIN_APPROX_SIMPLE:压缩水平方向,垂直方向,对角线方向的元素,只保留该方向的终点坐标,例如一个矩阵轮廓只需 4 个点来保存轮廓信息。
cv2.CHAIN_APPROX_NONE:存储所有的轮廓点,相邻两个点的像素位置差不超过1
1.6、HSV颜色取值
这里使用的是蓝色来示例,如果想要其他颜色呢?在HSV中的取值情况是怎么样的,如下图:

2、OpenCV知识点
这里用的很多的是OpenCV的一些知识,我们来熟悉下常用的,比如读取图片转成灰色图片。
2.1、读取和显示图片
import cv2
img = cv2.imread('test.jpg', 0)
cv2.imshow("image",img)
# 如果注释下面的等待按键和释放窗口资源,会出现“窗口未响应”的状态,不能正常显示图片
cv2.waitKey()
cv2.destroyAllWindows()当然如果没有安装这个视觉库的话,报错:ModuleNotFoundError: No module named 'cv2'
安装命令:pip install opencv-python -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
读取图片cv2.imread()的时候,第二个参数为0,表示灰度模式,也可以使用cv2.IMREAD_GRAYSCALE 代替0
其他数字表示如下:
1表示彩色图片cv2.IMREAD_GRAYSCALE
2表示不修改模式包括通道cv2.IMREAD_UNCHANGED
2.2、读取和保存图片
img = cv2.imread('test.jpg', 0)
cv2.imwrite('new.jpg', img)这样就将以灰度模式读取的图片,通过cv2.imwrite写入的方式,保存为了一张新的图片。
2.3、读取和显示视频
同样的,我们来看下视频的效果,通俗理解就是视频不断的读取里面的每帧(图片)
import cv2
cap = cv2.VideoCapture('test.mp4')
print(cap.read()[1].shape) # (1080, 1920, 3)这样就读取了视频的一帧,返回值是一个元组,如果读取整个视频呢?我们一起来看下:
import cv2
cap = cv2.VideoCapture('test.mp4')
if (cap.isOpened() == False):
print('不能打开视频文件')
else:
fps = cap.get(cv2.CAP_PROP_FPS) # 参数可直接使用5代替
print('每帧速度:', fps,'FPS') # 每帧速度: 29.97002997002997 FPS
f_count = cap.get(cv2.CAP_PROP_FRAME_COUNT) # 7
print('总帧数: ', f_count) #总帧数: 3394.0
while(cap.isOpened()):
ret, frame = cap.read()
if ret == True:
cv2.imshow('Frame',frame)
key = cv2.waitKey(20)
# 按q键退出
if key == ord('q'):break
else:
break
# 注意释放资源
cap.release()
cv2.destroyAllWindows()这样就跟显示图片一样,显示视频了。其中cv2.waitKey(20)表示在连续帧之间等待20毫秒,那这个数值越大,等待时长越大,可以看到视频的播放就变得比较慢了。
当然更关键的是用来获取摄像头监控的视频。
# 参数 0 表示设备的默认摄像头,当设备有多个摄像头时可以改变参数选择
cap = cv2.VideoCapture(0)当然有些外接摄像头的ID可能不是0,我们可以使用遍历来获取到:
import cv2
ID = 0
while(1):
cap = cv2.VideoCapture(ID)
ret, frame = cap.read()
if ret == False:
ID += 1
else:
print(ID)
break2.4、多张图片合成视频
将一个目录里面的图片写入到视频中,方法跟前面差不多,不过需要注意的是,合成视频的图片尺寸必须一致,也就是说如果目录里面的图片大小各不相同的话,单纯的直接写入视频会失败,所以这里需要将图片裁剪成一样,利用插值法来操作:
import cv2
import os
path ='imgs'
size = (600,400) # (W,H)
fps = 1
#fourcc = cv2.VideoWriter_fourcc('X','V','I','D')
fourcc = cv2.VideoWriter_fourcc(*'XVID')
video = cv2.VideoWriter('hi.avi',fourcc,fps,size)
for item in os.listdir(path):
if item.lower().endswith('.jpg'):
img = cv2.imread(os.path.join(path,item))
img1 = cv2.resize(img, size, interpolation=cv2.INTER_CUBIC)
print(img1.shape) # (H,W,C)
video.write(img1)
video.release()
cv2.destroyAllWindows()其中interpolation参数指定的插值法:
INTER_NEAREST:最邻近插值法
INTER_LINEAR:双线性插值,默认
INTER_CUBIC:4x4像素邻域内的双立方插值
INTER_LANCZOS4:8x8像素邻域内的Lanczos插值
2.5、直线、矩形、圆圈等形状
一些常见的形状,在实际应用中很常见,这里列举如下:
2.5.1、直线
cv2.line(img, startPoint, endPoint, color, thickness)
startPoint :起始位置像素坐标
endPoint:结束位置像素坐标
color:绘制的颜色
thickness:绘制的线条宽度2.5.2、圆圈
cv2.circle(img, centerPoint, radius, color, thickness)
img:需要绘制的目标图像对象
centerPoint:绘制的圆的圆心位置像素坐标
radius:绘制的圆半径
color:绘制的颜色
thickness:绘制的线条宽度(thickness 是负数,表示圆被填充)2.5.3、矩形
cv2.rectangle(img, point1, point2, color, thickness)
img:需要绘制的目标图像对象
point1:左上顶点位置像素坐标
point2:右下顶点位置像素坐标
color:绘制的颜色
thickness:绘制的线条宽度2.5.4、文本
cv2.putText(img, text, point, font, size, color, thickness)
img:需要绘制的目标图像对象
text:绘制的文字
point:左上顶点位置像素坐标
font:绘制的文字格式
size:绘制的文字大小
color:绘制使用的颜色
thickness:绘制的线条宽度2.5.5、图片缩放
cv2.resize(InputArray src, OutputArray dst, Size, fx, fy, interpolation)
InputArray src:输入图片
OutputArray dst:输出图片
Size:输出图片尺寸
fx, fy:沿x轴,y轴的缩放系数
interpolation:插值方法3、bgr8_to_jpeg
其中最后在图片组件中需要显示图片的时候,我们需要将每帧的图像反馈到图片组件里面,然后每帧的图像是BGR,而图像组件格式为jpeg,所以需要做一个转换。
bgr8_to_jpeg这个函数就是将图像编码到内存缓冲区中,实质是一个imencode函数的封装,对图像做压缩处理
函数源码是:
def bgr8_to_jpeg(value, quality=75):
return bytes(cv2.imencode('.jpg', value)[1])里面的imencode函数如下:
imencode(ext, img[, params]) -> retval, buf
ext:定义输出格式的文件扩展名
img:要写入的图像
buf:输出缓冲区调整大小,以适应压缩图像快速查看函数源码或不方便查看源文件的情况:
import inspect
print(inspect.getsource(bgr8_to_jpeg))