分布式锁的实现方式
文章目录
- 一、分布式锁概述
-
- 1.1 为什么需要分布式锁
- 1.2 概述分布式锁
- 1.3 分布式锁的特性
- 1.4 分布式锁的类型
- 1.5 实现重点
- 二、Mysql数据库实现分布式锁
-
- 2.1 表结构
- 2.2 加锁
- 2.3 解锁
- 2.4 锁超时
- 2.5 实现重入锁
- 三、Redis实现分布式锁
-
- 3.1 加锁
- 3.2 解锁
- 3.3 锁超时
- 3.4 redlock的容错性问题
- 四、总结
一、分布式锁概述
1.1 为什么需要分布式锁
通常我们说的锁,指的是单机单进程中多线程环境下,当多个线程同时访问共享资源时,会引发并发访问的问题,可能导致数据不一致或竞态条件。通过使用锁,可以确保一次只有一个线程能够访问共享资源,从而避免这些问题。
通常使用的锁有:
1)互斥锁
2)自旋锁
3)信号量
4)读写锁
5)原子变量以及内存屏障
6)条件变量
那么,如果是多个进程相互竞争一个资源,如何保证资源只会被一个操作者持有呢?
在分布式系统中,一个应用部署在多台机器当中,在某些场景下,为了保证数据一致性,要求在同一时刻,同一任务只在一个节点上运行,即保证某个行为在同一时刻只能被一个线程执行;在单机单进程多线程环境,通过锁很容易做到,比如mutex、spinlock、信号量等;而在多机多进程环境中,此时就需要分布式锁来解决了。可以理解为在分布式场景中实现互斥类型的锁。
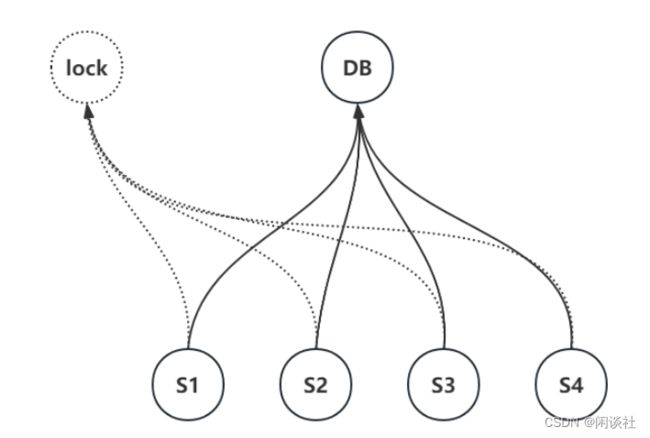
S1~S4是分布在不同机器或不同网段的节点。每个节点在执行某项操作前需要先获取锁,只有成功拿到锁才能执行后续的操作。
1.2 概述分布式锁
1)分布式锁是什么类型的锁?
分布式锁是在分布式场景中实现互斥类型的锁。
分布式:运行的节点可能在不同的机器或者网段当中,节点间通过socket进行通信
互斥类型:同一时刻只允许一个执行体进入临界资源
2)分布式锁解决了什么问题?
解决分布式事务中的隔离性问题。在分布式场景中,同时只允许一个节点执行某类任务。
3)分布式锁的存储
分布式锁本身也是一种资源,在分布式场景中,通过网络交互的方式,不同机器的实体都可以访问锁资源。可以将锁资源保存在MySQL后者Redis中。
4)分布式锁的行为
分布式锁的行为分别加锁和解锁。加锁和解锁本质上是一次网络交互行为,某个实例加锁成功,其他实例便加锁失败。并且,加锁和解锁的对象必须是同一个,除了因为网络异常而造成的锁超时情况。
1.3 分布式锁的特性
1)互斥性
同时只允许一个持锁对象进入临界资源;其他待持锁对象要么等待,要么轮询检测是否能获取锁。需要记录持有锁对象(加锁对象和解锁对象必须为同一个)方便判定锁被谁占有了。加锁的时候需要打上该对象的标记,解锁的时候取消标记。
2)锁超时
允许持锁对象持锁最长时间;如果持锁对象宕机,需要外力解除锁定,方便其他持锁对象获取锁。
在单进程的多线程场景下,资源和行为是同生共死的关系,程序宕机会自动释放所有资源和行为。而在分布式场景中有比较大的差别,锁资源和行为是分离的,通过网络交互操作锁,要考虑到锁资源宕机和行为实体宕机的情况如何释放资源和解除行为。
比如行为实体宕机了,如何释放锁?如果不能释放锁则其他的实体将一直等待;所以,需要锁超时机制,设置操作时长的最大值,超时释放锁。再比如锁资源宕机的情况。
3)可用性
锁存储位置若宕机,可能引发整个系统不可用。因此需要有备份存储位置和切换备份存储的机制,从而确保服务可用;
实现上有两种方式:
a)计算型:不存储数据只完成行为,比如网关只计算分发请求,不存储数据。此类实现方式是开多个备份点。
b)存储型:存储数据或者资源。此类实现方式是准备多个备份点,存储超过半数以上的备份节点;并且具有切换功能,以解决宕机问题。
4)容错性
若锁存储位置宕机,恰好锁丢失的话,是否能正确处理。
具体来说,就是一个实体行为申请了锁,此时锁资源宕机,切换到了备份资源。此时需要备份资源具有一致性,即确保数据在系统中的不同副本之间保持同步和一致的状态。
实现方式是通过一致性算法,比如raft一致性算法。
比如redlock的实现:开奇数个进程,写锁的时候,写入进程半数以上成功的返回获取锁成功,否则失败。
1.4 分布式锁的类型
1)重入锁和非重入锁
两者的区别是:是否允许持锁对象再次获取锁
对于一个进程多线程环境下,就是递归锁和非递归锁
2)公平锁和非公平锁
公平锁:通过排队来实现,对应的是互斥锁
非公平锁:不间断尝试获取锁来实现,对应的是自旋锁
对于互斥锁,当一个线程尝试获取一个已经被其他线程占有的互斥锁时,该线程会在用户态自旋等待一小段时间。当超过一定时间阈值后,会转入内核态,进入阻塞状态。该线程会被放入阻塞队列中,并引起线程切换。当互斥锁的持有者释放锁时,操作系统会唤醒等待中的线程,从阻塞队列中取出一个线程加入就绪队列,等待CPU调度。
对于自旋锁,当一个线程尝试获取一个已经被其他线程占有的自旋锁时。如果是单处理器,该线程会在一个循环中忙等待,空转CPU直到锁被释放。如果是多处理器系统中,该线程会在循环中忙等待一定时间,如果锁还不可用,则会调用sched_yield(),引起线程切换。自旋等待的线程会切换至非运行状态,并被放入就绪队列,等待CPU调度。
在就绪队列中的好处是当有CPU核心空闲时会从就绪队列中取出任务执行;可以注意到互斥锁是先加入阻塞队列再进入就绪队列。
1.5 实现重点
1)锁是一种资源,需要存储。同时要保证可用性,避免锁失效。
2)互斥语义:给锁打标记。加锁对象和解锁对象必须为同一个,解锁时需要判断当前持有锁的对象是否是自己。
3)加锁和解锁行为是网络通信,需要考虑锁超时(超时时间要远大于一次网络交互的时间)。
4)如何获知持锁对象的释放锁的行为:a)主动探寻(非公平锁);b)被动通知,有广播通知(非公平锁),有排队单独通知(公平锁)。
5)是否支持同一持锁对象多次加锁,即重入锁与非重入锁。
二、Mysql数据库实现分布式锁
MySQL是关系型数据库,通过表存储数据。不同业务类型的锁放置表中不同的行。
主要利用 MySQL 唯一键的唯一性约束来实现互斥性;
2.1 表结构
DROP TABLE IF EXISTS `dislock`;
CREATE TABLE `dislock` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`lock_type` varchar(64) NOT NULL COMMENT '锁类型',
`owner_id` varchar(255) NOT NULL COMMENT '持锁对象',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_lock_type` (`lock_type`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT
CHARSET=utf8 COMMENT='分布式锁表';
- id,不同类型的锁 主键id不断自增。
- lock_type,锁的类型用来描述不同业务类型的锁。实现互斥。
- owner_id,持锁对象,允许谁来解锁,其他对象不能解锁;另一个作用是避免重复加锁。
- update_time,具体操作锁的时间,主要用于解决锁超时问题。
- 唯一索引是指一列中不存在重复字段的行,即字段唯一。
- 主键是非空唯一索引。
根据唯一索引的约束实现互斥,即lock_type在一个表中不会出现两个相同的lock_type。唯一键是确保字段在表中是唯一的。

2.2 加锁
假设S1加锁成功,也就是往表dislock中成功插入一条记录。其中:act_lock是具体的锁,ad2daf3是S1的id。
INSERT INTO dislock (`lock_type`, `owner_id`) VALUES ('act_lock', 'ad2daf3');
2.3 解锁
假设S1解锁,也就是从表中删除对应的记录。要表明解什么锁lock_type,谁来解owner_id,如果id不一致解锁失败。
DELETE FROM dislock WHERE `lock_type` = 'act_lock' AND `owner_id` = 'ad2daf3';
Mysql在解锁之后没有主动通知的功能。其他申请锁的实例只能在获取锁失败之后,休眠一会再主动轮询,看是否能加锁。
// 连续分布式锁的使用案例
while (1) {
CLock my_lock;
bool flag = dlm->ContinueLock("foo", 14000, my_lock);
if (flag) {
printf("获取成功, Acquired by client name:%s, res:%s, vttl:%d\n",
my_lock.m_val, my_lock.m_resource, my_lock.m_validityTime);
// do resource job
sleep(10);
} else {
printf("获取失败, lock not acquired, name:%s\n", my_lock.m_val);
sleep(rand() % 3);
}
}
2.4 锁超时
锁超时是在MySQL中有超进程,利用定时器实现定时检测表,用当前时间减去update_time,如果超过最大持锁时间,就主动删除这条记录(释放锁)。
2.5 实现重入锁
在表结构中加一个count字段,加锁count加一,解锁count减一;当count等于0时删除数据(解锁)。
优点:
1)简单易用:使用MySQL作为分布式锁的实现方式相对简单,无需引入额外的组件或服务。
2)数据持久性:MySQL作为关系型数据库,具备数据持久性的特点,分布式锁的状态可以被持久化存储,即使系统重启也能保持锁的状态。
3)可靠性:MySQL提供了ACID事务特性,可以确保分布式锁的可靠性和一致性。
缺点:
1)效率不高,需要另起一个线程检测锁超时;并且MySQL是一种关系型数据库,对于高并发的场景可能存在性能瓶颈,因为每次获取或释放锁都需要与数据库进行交互。
2)锁释放不能主动通知,只能通过主动探寻解决;
3)还需额外实现锁失效的问题,解锁失败,其他线程将无法获得锁;
4)单点故障:如果使用单个MySQL实例作为分布式锁的中心节点,当该节点发生故障时,整个分布式锁系统将失效。
三、Redis实现分布式锁
redis是
1)内存数据库:Redis主要将数据存储在内存中,因此它可以被称为内存数据库。相比传统的磁盘存储数据库,Redis在读取和写入数据时具有更快的速度和更低的延迟。
2)数据结构数据库:Redis不仅仅是简单的键值对存储,它还提供了多种数据结构的支持,例如字符串、哈希表、列表、集合和有序集合等。这使得开发人员可以根据实际需求选择合适的数据结构,并在应用程序中使用这些数据结构来实现更复杂的功能。
3)键值数据库:Redis以键值对的形式存储数据。每个键都是唯一的,并且与一个值关联。这使得Redis非常适合用作分布式缓存、会话存储和数据存储等场景,其中快速查找和存储数据是关键。
3.1 加锁
redis的set命令中,可以把key存放锁的类型,value存放持锁对象;为了实现锁的互斥性,使用NX参数(NX就是not exist的缩写)。
zxm@ubuntu:~$ redis-cli
// key:act_lock uuid:111 NX 表示只有当key不存在时,该命令执行成功,否则失败
127.0.0.1:6379> set act_lock 111 NX
OK
// 因为key:act_lock 已经存在,所以加锁失败
127.0.0.1:6379> set act_lock 222 NX
(nil)
// 解锁act_lock
127.0.0.1:6379> del act_lock
(integer) 1
// 因为key:act_lock 已经解除,所以加锁成功
127.0.0.1:6379> set act_lock 222 NX
OK
真正加锁操作一般不会使用上面的,因为需要考虑重入锁。可以考虑使用hash的数据结构。
--[[
KEYS[1] lock_name
KEYS[2] lock_channel_name
ARGV[1] lock_time (ms)
ARGV[2] uuid
]]
if redis.call('exists', KEYS[1]) == 0 then
redis.call('hset', KEYS[1], ARGV[2], 1)
redis.call('pexpire', KEYS[1], ARGV[1])
return
end
-- 若支持锁重入,将注释去掉
-- if redis.call('hexists', KEYS[1], ARGV[2]) == 1 then
-- redis.call('hincrby', KEYS[1], ARGV[2], 1)
-- redis.call('pexpire', KEYS[1], ARGV[1])
-- return
-- end
redis.call("subscribe", KEYS[2])
return redis.call('pttl', KEYS[1])
这段代码是一个 Redis Lua 脚本片段,根据给定的键(KEYS)和参数(ARGV),检查键是否存在,如果不存在则设置字段的初始值为 1,并为键设置过期时间。
这段代码的功能如下:
1)使用 Redis 的 exists 命令检查键 KEYS[1] 是否存在。如果结果为 0,表示键不存在。
2)如果键不存在,则使用 Redis 的 hset 命令将键 KEYS[1] 中的字段 ARGV[2] 的值设置为 1。
3)接着,使用 Redis 的 pexpire 命令为键 KEYS[1] 设置过期时间,过期时间由参数 ARGV[1] 指定。pexpire 命令以毫秒为单位设置过期时间。
4)最后,代码执行结束,函数返回。
3.2 解锁
先用get命令获取持锁对象的value,与自己对比。如果相等才调用del解锁。
get act_lock
if (val == uuid)
{
/ 解锁
del act_lock ;
}
注意上述三个操作是应当是原子操作
--[[
KEYS[1] lock_name
KEYS[2] uuid
]]
local uuid = redis.call("get", KEYS[1])
if uuid == KEYS[2] then
redis.call("del", KEYS[1])
end
3.3 锁超时
redis的set命令中有EX和PX参数,设置超时时间。
EX就是Expire的缩写,这个以秒为单位。
PX是pExpire,这个是以毫秒为单位。
set act_lock 123 NX EX 10
# 或者
set act_lock 123 NX PX 10000
可以使用ttl命令查看剩余时间。
ttl act_lock
锁超时设定一定要远远大于网络交互时间。
3.4 redlock的容错性问题
一般redis有5个备份结点(进程),分别在不同的机器当中R1 - R5。比如S1申请锁资源,主要R1 - R5中,半数以上的节点回复确认,那么就获取锁成功。这样可以保证数据的一致性。

redis集群主从复制采用的是异步复制的方式,存在主从数据不一致问题,数据丢失意味着锁丢失;为了解决这个问题使用redlock方法,执行加锁时向所有的节点都执行相同语句,有半数以上(N/2 + 1)写成功就表示加锁成功。
(1)加锁,需要对每个进程执行加锁操作,超过半数以上成功才能说明加锁成功。
(2)解锁,需要对每个进程执行解锁操作,超过半数以上成功才能说明解锁成功。
四、总结
redis是效率最高的分布式锁;etcd是完备性最高的分布式锁;MySQl是效率最低的、最不完备的分布式锁。
三者比较:
1)完备性:etcd > redis >mysql
2)性能: redis > etcd > mysql
3)选择:三者都有选etcd。只有MySQL,那么就使用MySQL实现分布式锁。不要为了实现分布式锁引入redis等中间件