二十三、HTTP
文章目录
- 一、HTTP协议
-
- (一)定义:
- (二)认识URL
-
- 1.域名->必须被转化成为IP
- 2.URL中可以省略的部分
-
- (1)端口号可缺省
- (2)登录信息可以省略
- (3)当我们访问自己的服务器时,https可省略,端口号不可省!
- 3.特定的服务与特定端口的关系
- 4.http协议是做什么的
- 5.如果我们client没有获取的时候,资源在网络服务器上!
- 6.资源文件在Linux服务器上
- 7.Linux要如何找到这个文件呢?——通过路径!
- (二)urlencode和urldecode
- 二、HTTP协议的请求格式
-
- (一)http协议的请求分为三部分(我们这里以四部分解析)
-
- 1.请求行
- 2.请求报头
- 3.空行
- 4.有效载荷
- (二)http协议的响应
-
- 1.响应行
- 2.响应报头
- 3.空行
- 4.有效载荷
- (三)send 写入函数
- (四)telnet 命令——远程以协议方式登录某服务
-
- 1.telnet请求服务器
- 2.百度上请求服务器
- 三、HTTP协议的响应,初步使用HTML
-
- (一)html
- (二)响应内容,使用html
-
- 1.响应内容,使用html
- 2.Content-Length 保证能读取到完整的正文
- 3.把html和服务器工作解耦——readFile 要请求的资源
- 四、表单
-
- (一)网络行为有两种
- (二)GET方法
- (三)POST方法
- (四)GET vs POST
一、HTTP协议
虽然我们说,应用层协议是我们程序员自己定的,但实际上,已经有大佬们定义了一些现成的,又非常好用的应用层协议 ,供我们直接参考使用,HTTP( 超文本传输协议 ) 就是其中之一。
(一)定义:
超文本传输协议,是一个无链接,无状态的应用层协议。
(二)认识URL
平时我们俗称的 “网址” 其实就是说的 URL。
URL:统一资源定位服务(unit resource locate),用于在互联网中定位某种资源!
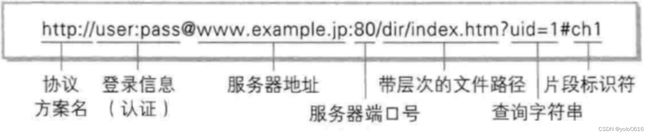

1.域名->必须被转化成为IP
因为网络通信的本质: socket : IP+ port,所以(服务器地址)域名->必须被转化成为IP;访问网络服务,服务端必须具有port!
2.URL中可以省略的部分
(1)端口号可缺省
使用确定协议的时候,一般显示的时候,会缺省端口号:
浏览器访问指定的url的时候,浏览器或app必须给我们自动添加port
浏览器如何得知,url匹配的port是谁呢?——特定的众所周知服务,端口号必须是确定的! !
httpserver—> 80
httpsServer—>443 sshd—> 22
用户自己写的网络服务bind端口的范围:[1024,n];因为前1023个是给httpserver这些服务的。
(2)登录信息可以省略
登录信息我们一般放在页面上登录,一般不放在URL中,所以可以省略。
(3)当我们访问自己的服务器时,https可省略,端口号不可省!
当我们访问自己的服务器时,只需要IP+port:120.78.126.148:8080
https可省略,因为默认会选择https协议;登录信息一般放在页面上登录也可以省略;端口号不可省因为服务是我们自己写的,并不是众所周知服务。
3.特定的服务与特定端口的关系
->警察与110;抢救服务与120;火警灭火服务与119
4.http协议是做什么的
用于查阅文档,看音视频,这些都是以网页的形式呈现的。网页实际就是一个 .htmI文件
http用途:获取网页资源的,视频,音频等也都是文件!
解释:http是向特定的服务器申请特定的”资源”的,把资源获取到本地(本地可以是浏览器/app/迅雷播放器)进行展示或者某种使用的!
5.如果我们client没有获取的时候,资源在网络服务器上!
就在你的网络服务器(软件)所在的服务器(硬件,计算机)上。
6.资源文件在Linux服务器上
服务器都是Linux系统的,这些资源都是文件,即资源文件在Linux服务器上。要打开资源文件,读取和发送会给客户端——前提:软件服务器,必须先找到这个文件!
7.Linux要如何找到这个文件呢?——通过路径!
/ 就是Linux下的路径分隔符!
(二)urlencode和urldecode
像 / ? : 等这样的字符 , 已经被 url 当做特殊意义理解了,因此这些字符不能随意出现,比如, 某个参数中需要带有这些特殊字符 , 就必须先对特殊字符进行转义。
encode 编码 为了区分一些特殊的!
服务器(软件)收到url 对自己特殊的%xx 进行解码!
转义的规则如下 :
将需要转码的字符转为 16 进制,然后从右到左,取 4 位 ( 不足 4 位直接处理 ) ,每 2 位做一位,前面加上 % ,编码成 %XY
格式!
二、HTTP协议的请求格式

(一)http协议的请求分为三部分(我们这里以四部分解析)
每行以 \r\n 结尾!
1.请求行
第一部分只有一行叫 请求行:包含了①请求方法 method。②url 一般省略了域名和端口,只有路径。③版本 http/1.1
注意:http协议请求时大小写是忽略的,例如请求行的 GET / HTTP/1.1 和get / http/1.1 都一样
2.请求报头
第二部分包含多行内容叫 请求报头:每一行包含很多请求属性,都是KV形式的,例如 Key: value(注意:和value中间有空格)
3.空行
第三部分只有一行叫空行:因为只包含了一个 \r\n ,用与做分隔符,把报头和有效载荷分离。
4.有效载荷
第四部分只有一行叫有效载荷:包含了请求正文:
①登陆账号和密码。②个人信息/音频/视频等等。
注意:前三部分(请求行,请求报头,空行)都为http协议的报头;有效载荷就是个人信息!
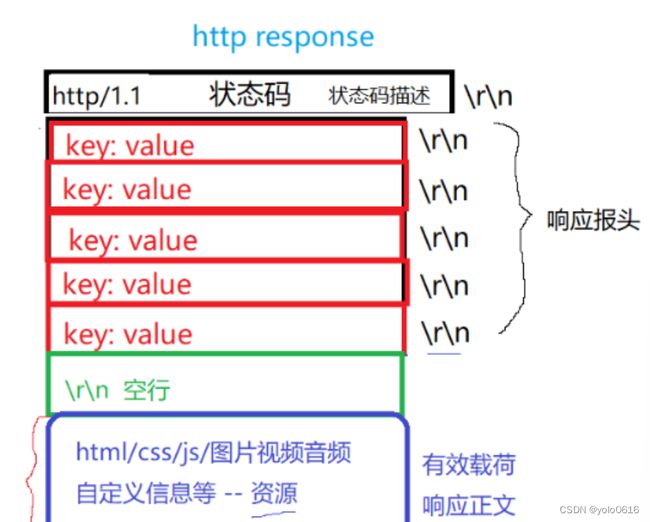
(二)http协议的响应
也是每行以 \r\n 结尾!
1.响应行
第一部分只有一行叫 响应行:包含了①版本 http/1.1。②状态码。(例如404报错,200代表OK)③状态码描述。(例如404对应的“Not Found”描述)
2.响应报头
第二部分包含多行内容叫 响应报头:每一行包含很多响应属性,都是KV形式的,Key: value(注意:和value中间有空格)比如 Content-Type: text/html; charset=utf-8 用于表示正文是 text/html文档类型,字符集为utf-8
3.空行
第三部分只有一行叫 空行:因为只包含了一个 \r\n ,用与做分隔符,把报头和有效载荷分离
4.有效载荷
第四部分只有一行叫 有效载荷:包含了响应正文:①htm/css/js/图片视频音频,自定义信息等——资源
http协议构建一个请求,响应
(三)send 写入函数
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
把缓冲区buf中的len个长度数据写入 sockfd这个文件中,flags设为0,send和write函数等价
返回值:返回实际写入的字节数,错误返回-1错误码被设置。
(四)telnet 命令——远程以协议方式登录某服务
我们的服务器的响应内容:
1.telnet请求服务器
先把./serverTcp 8080把服务器起来,然后telnet 127.0.0.1 8080,再 ctrl+],输入请求 GET / http/1. 0 ,就可以得到服务器的响应信息。
2.百度上请求服务器
IP+端口,就能得到响应
三、HTTP协议的响应,初步使用HTML
(一)html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<h1>我的第一个标题</h1>
<p>我的第一个段落。</p>
</body>
</html>
(二)响应内容,使用html
示例:
HTTP/1.0 200 OK\r\n
Content-Type 标定正文的类型
1.响应内容,使用html
——“HTTP/1.0 200 OK\r\n”; HTTP/1.0 版本,200状态码表示通过,OK状态码描述
——“Content-Type: text/html\r\n” ; Content-Type内容类型,正文的类型是html文本类型。(text-文本类型)
——“\r\n”; 这是空行
2.Content-Length 保证能读取到完整的正文
任何协议的request or response:
报头+有效载荷
①http如何保证自己的报头和有效载荷被全部读取呢?
——无论是请求还是响应,读取完整报头:按行读取,直到读取到空行上
②你又如何保证 你能读取到完整的正文呢? ?
——报头能读取完毕,请求或者响应属性中”一定”要包含正文的长度!
response += ("Content-Length: " + std::to_string(html.size()) + “\r\n”);
3.把html和服务器工作解耦——readFile 要请求的资源
我要把特定的资源放到特定的目录下的文件中!
①文件在哪里? ——在请求的请求行中,第二个字段就是你要访问的文件 。
例如:请求行:GET /a/b/c.html http/1.0 ,/a/b/c.html就是要访问的文件
②GET /a/b/c.html http/1.0 中的 / 是web目录,不是根目录
a前面的 / 不是根目录, web根目录,但可以设置成为根目录
path = “/a/b/index.html”; ——请求的人请求的文件路径
resource = “./wwwroot”; // 我们的web根目录,我们服务器内部给请求的路径自动加上前缀
resource += path; // ——> ./wwwroot/a/b/index.html
四、表单
(一)网络行为有两种
我想把远端的资源拿到你的本地: GET /index.html http/1.1。
我们想把我们的属性字段,提交到远端。
提交到远端的两种方法:GET or POST
在HTTP中GET会以明文方式将我们对应的参数信息,拼接到url中。
HTTP/1.1协议中可使用的方法
当浏览一个Web页面时,客户端要向服务器发送请求,而这个请求中要包含请求的方法。HTTP协议/1.1支持的方法有:GET、POST、PUT、DELETE、HEAD、OPTIONS、TRACE、CONNECT。
(二)GET方法
在HTTP中GET会以明文方式将我们对应的参数信息,拼接到url中
(三)POST方法
POST方法提交参数,会将参数以明文的方式,拼接到http的正文中来进行提交!
只需把method=“get” 改成method=“post”
(四)GET vs POST
- GET通过url传参
- POST通过正文传参
- GET方法传参不私密(因为GET会把用户输入的有效信息用户名,密码等回显到浏览器)
- POST方法因为通过正文传参,所以,相对比较私密一些(因为一些小白一般不会抓包看正文,所以相对私密)
- GET通过url传参,POST通过正文传参,所以一般一些比较大的内容都是通过post方式传参的
- HTTP GET请求提交参数有长度限制;HTTP POST请求提交参数没有长度限制。
解释6:Http Get方法提交的数据大小长度并没有限制,HTTP协议规范没有对URL长度进行限制。但是特定的浏览器及服务器对URL有限制,所以还是有限制的; 因为POST方法通过正文传参,理论上讲,POST是没有大小限制的。HTTP协议规范也没有进行大小限制,起限制作用的是服务器的处理程序的处理能力,而并非限制。