leetcode小笔记-SQL
leetcode
leetcode 免费版
1、1407)空值处理
1)空值判断:只能采用IS NULL或IS NOT NULL,而不能采用=, <, <>, !=这些操作符来判断NULL。
2)空值处理:
①coalesce():coalesce(表达式1,表达式2,…) 按照顺序首先执行表达式1,如果不为null则返回表达式1的结果 如果为null,则往下执行表达式2。以此类推。 可以用于当返回值为null时的默认返回。
②isnull()
③notnull()
④nvl()
⑤ifnull(需要判断的值,为空时返回的值) :
SELECT IFNULL((),0) AS 'XXX'
2、176)LIMIT 3,2 = LIMIT 2 OFFSET 3
指从第4行开始取2条
3、176)窗口函数
https://zhuanlan.zhihu.com/p/80051518
1、窗口函数格式:
window_function (expression) OVER (
[ PARTITION BY part_list ]
[ ORDER BY order_list ]
[ { ROWS | RANGE } BETWEEN frame_start AND frame_end ] )
窗口函数只能在select字句中使用,不能在where和group 字句中使用。
2、开窗的范围:
①rows
取当前行至前5行:ROWS between 5 preceding and current row --共6行 rows 5 preceding
取当前行至后5行:ROWS between current row and 5 following --共6行
取前5行至后5行:ROWS between 5 preceding and 5 folowing --共11行
②range
取当前行至当前行数据-5行:RANGE between 5 preceding and current row
取当前行至当前行数据+5行:RANGE between current row and 5 following
当前行数据-5行至当前行数据+5行:RANGE between 5 preceding and 5 folowing
注:按order by 的字段数据计算位置。

参考:https://blog.csdn.net/m0_52606060/article/details/129132985
如果不指定范围,则默认采用以下定义:
- 若不指定 ORDER BY,默认使用分区内所有行 RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING.
- 若指定了 ORDER BY,默认使用分区内第一行到当前值 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
3、窗口函数执行顺序:
- 每行数据进行一次计算,输入多行数据(窗口),返回一个值。
- 窗口函数仅仅只会将结果附加到当前的结果上,它不会对已有的行或列做任何修改。

注意到窗口函数的求值仅仅位于 ORDER BY 之前,而位于 SQL 的绝大部分之后。这也和窗口函数只附加、不修改的语义是呼应的——结果集在此时已经确定好了,再依此计算窗口函数。
3、窗口函数分类:
1) 专用窗口函数,rank, dense_rank, row_number
2) 聚合函数,如sum. avg, count, max, min等
①RANK() OVER(业务逻辑):
查出指定条件后的进行排名,条件相同排名相同
1134557
②DENSE_RANK() OVER(业务逻辑) :
查出指定条件后的进行排名,条件相同排名相同(序号紧密)
11234556
③ROW_NUMBER() OVER(业务逻辑):
查出指定条件后的进行排名,条件相同排名也不相同
12345678
rank() over(partition by course order by grade desc,student_id asc) rn
--每个课程按照成绩、学生学号排序(相同成绩的两个同学,学号小的为1,学号大的为2)
4、178)窗口函数格式
dense_rank() over(order by score desc) as ‘rank’ √
dense_rank() over(order by score desc) rn √
dense_rank() over(order by score desc) as rank ×
dense_rank() over(order by score desc) rank ×
5、197)日期相减、时间差:DATEDIFF()\ TIMESTAMPDIFF()
①MySQL:TIMESTAMPDIFF(类型,开始时间,结束时间) ——可以返回年,月,日等的差异
https://www.yisu.com/zixun/168973.html
②SQL Server:DATEDIFF(datepart, startdate, enddate) ——可以返回年,月,日等的差异
https://blog.csdn.net/qq_34498806/article/details/85614472
MySQL:DATEDIFF(date1, date2)——以天为单位返回差值date1 - date2
DATEDIFF(day,'2008-12-29','2008-12-30');
6、197)向上偏移行 LAG函数
LAG()函数,从当前行访问上一行的数据或上一行之前的行。LAG()是一个Window函数,它提供对当前行之前的指定物理偏移量的行的访问。
LAG(return_value ,offset [,default]) OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...)
offset - 从当前行返回的行数,默认为1。
default - 是当offset超出分区范围时要返回的值,默认为NULL。
PARTITION BY子句-将结果集的行分配到应用LAG()函数的分区。
ORDER BY子句-每个分区中行的顺序。
LAG(net_sales,1) OVER ( --返回月销量,偏移量为1(即返回上月的值)
PARTITION BY brand_name --按照品牌分类
ORDER BY month --按月排序
) next_month_sales --命名为上月销量
7、1667)字符串格式处理
①CONCAT() 函数:
CONCAT 可以将多个字符串拼接在一起。
②LEFT(str, length) 函数:
从左开始截取字符串,length 是截取的长度。
③UPPER(str) 与 LOWER(str):
UPPER(str) 将字符串中所有字符转为大写
LOWER(str) 将字符串中所有字符转为小写
④SUBSTRING(str, begin, end):
截取字符串,end 不写默认为空。
SUBSTRING(name, 2) 从第二个截取到末尾。
思路:CONCAT 用来拼接字符串 ● LEFT 从左边截取字符 ● RIGHT 从右边截取字符 ● UPPER 变为大写 ● LOWER 变为小写 ● LENGTH 获取字符串长度
CONCAT(UPPER(left(name, 1)), LOWER(RIGHT(name, length(name) - 1)))
--首字母大写,其他小写
8、197)FORMAT() 函数,标准格式
FORMAT( (net_sales - previous_sales) / previous_sales, 'P' ) --百分数格式
9、627)UPDATE 更新数据
UPDATE Product
SET sale_price = sale_price - 1000
WHERE product_name = '运动T恤';
10、1484)group_concat 结果逗号分隔
group_concat函数:
group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator
'分隔符'] )
group_concat(distinct product order by product asc separator ',')
11、1527)模糊匹配
like “%XXX%”
12、1179)行列转化
CASE WHEN函数和sum函数的应用:
SUM(CASE WHEN month='Jan' THEN revenue END) AS Jan_Revenue
FROM department
GROUP BY id;
13、1795)行列转化 2
①列转行:union连接
②行转列:sum(if(…)) 或者 sum(case when…)+ group by
14、IF表达式
IF( expr1 , expr2 , expr3 ):expr1条件,条件为true,则值是expr2 ,false,值就是expr3
if(表达式,if_true,if_false)
15、1795)UNION
Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;最常见的是过程表与历史表UNION;
Union All:对两个结果集进行并集操作,包括重复行,不进行排序;
16、快捷注解 “ctrl+/”
leetcode 付费版
一、简单
1、1731)ROUND 四舍五入
ROUND (x,y)函数:返回最接近于参数x的数,其值保留到小数点后面y位,若y为负值,则将保留x值到小数点左边y位。
2、1083)分组链接 group_concat()
语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator ‘分隔符’] )
SELECT
id,
name,
group_concat(cla separator '-') cla,
sum(num) num
FROM st
GROUP BY id,name;


3、2504)字符串链接 concat()
SELECT person_id
,concat(name,'(',left(profession,1),")") as name
FROM person
4、512)联合键子查询 where in 筛选
eg:查找每一个玩家首次登陆的设备名称。
select
player_id, device_id
from activity
where (player_id, event_date) in -- 登录日期是最早的登录日期
(
select player_id, min(event_date)
from activity
group by player_id
)
5、1517)正则表达式
^ 表示以后面的字符为开头
[] 表示括号内任意字符
- 表示连续
- 表示重复前面任意字符任意次数
\ 用来转义后面的特殊字符,以表示字符原本的样子,而不是将其作为特殊字符使用
$ 表示以前面的字符为结尾
前缀名以字母开头:1
前缀名包含字母(大写或小写)、数字、下划线_、句点. 和 或 横杠-:[a-zA-Z0-9_.-]*
以域名’@leetcode.com’结尾:@leetcode.com$
--查找有效的邮箱
--有效的邮箱包含符合下列条件的前缀名和域名:
--前缀名是包含字母(大写或小写)、数字、下划线 '_'、句点 '.' 和/或横杠 '-' 的字符串。前缀名必须以字母开头。域名是 '@leetcode.com' 。
select * from users
where mail REGEXP '^[a-zA-Z][a-zA-Z0-9\_\.\-]*@leetcode\.com$'
6、1543)格式化文本
1.lower()转化成小写字母
2.trim() 去除前后空格(保留中间空格)
3.ltrim() 去除左边空格
4.rtrim() 去除右边空格
5.replace(… , ’ ', ‘’) 去除全部空格
6.date_format()格式化时间
二、中等
1、550)avg的灵活应用
avg(a.event_date is not null) = sum(if(a.event_date is not null, 1, 0))/count(*)
①先判断内部返回布尔值(bool):TRUE为1,FALSE为0
②对布尔值求平均值:可以算出TRUE的占比
2、1747)列的偏移对比 lag() / lead()
lag() 从上一行取,lead() 从下一行取。
①lag(列名,向上偏移几位,超出行数时默认值) over(partition by … order by …) ——向上取
select id,name,
lag(name,1,0) over ( order by id )
from kkk;

②lead(列名,向下偏移几位,超出行数时默认值) over(partition by … order by …)——向下取
3、1867)group by 详解
https://blog.csdn.net/qq_41059320/article/details/89281125
4、1459)ABS取绝对值
abs() :绝对值
power(m,n) :m的n次方
sqrt() :开平方根
5、1454)between and 的边界
SQL中 between and是包括边界值的,not between不包括边界值。
特例:between and 限定日期需要注意,如果and后的日期是到天的,那么默认为00:00:00。即不包含and后当天其他时间的数据。例如:and 后的日期为2013年3月24日,就等价于2013-3-24 00:00:00 ,那么2013-3-24 18:28:38的数据就差不到了,需要进行to_char处理。
5、1454)连续的日期 自定义变量
SELECT @var_name := expr [, @var_name = expr] FROM table
6、1501)截取一部分 substring(),left()
| phone_number |
|---|
| 051-1234567 |
①SUBSTRING(字符串,开始位置,截取长度):开始位置从1开始
substring(phone_number,1,3)
-- 输出:051
②LEFT(字符串,截取长度):从左开始,截取3个字符串长度
left(phone_number,3)
-- 输出:051
7、1831)最大值 max()
两个最大值,max()会全部取出。
8、1949)共同好友
①需要一张每个用户和其好友的关系表
②自联结,好友相同,取出两个表用户id及为拥有共同好友的名单
③剔除用户id相同的行(自己跟自己好友相同)
④count(好友id),求出共同好友的数据
9、612)求平方power() 开根号sqrt()
求平面上的点之间的最短距离。
注:p1(x1, y1) 和 p2(x2, y2) 这两点之间的距离是 sqrt((x2 - x1)2 + (y2 - y1)2)
SELECT ROUND(sqrt(MIN(power((p1.x - p2.x),2) + power((p1.y - p2.y),2))),2) AS shortest
FROM point2d p1
JOIN point2d p2
ON p1.x<>p2.x or p1.y<>p2.y
10、1355) any的用法
查找非最多,非最少的项目。
select activity as ACTIVITY
from friends
group by activity
having count(*)>any(
select count(*) from friends group by activity
) and count(*)<any(
select count(*) from friends group by activity
)
11、1811)连续的记录
方法一:窗口函数
count(row - row_number()) >= 3 连续3行
方法二:lag() lead() 函数
row +1 = lead(row,1,0) and lead(row,1,0)+1 = lead(row,2,0) 连续3行
lead() or lad() = 当前行 连续2行
方法三:自连接
方法四:用户变量
12、1853)date_format() 日期格式转换

13、1939)timestampdiff() 时间差
TIMESTAMPDIFF(unit,begin,end)
unit参数是确定(end-begin)的结果的单位,表示为整数。 以下是有效单位:
- MICROSECOND
- SECOND
- MINUTE
- HOUR
- DAY
- WEEK
- MONTH
- QUARTER
- YEAR
14、2175)cast() 格式转化
CAST( XXX as signed) :转化为int类型
可带参数:
①日期 : DATE
②时间: TIME
③日期时间型 : DATETIME
④浮点数 : DECIMAL
⑤整数 : SIGNED
⑥无符号整数 : UNSIGNED
15、2394)ceiling() 小数点,进一
select CEILING(3.1)
结果:4
16、1596)窗口函数和group by一起使用
https://www.cnblogs.com/LittleOctopus/p/16327537.html
1、执行顺序:
①先group by
②窗口函数对group by的结果进行开窗
2、例子:
select customer_id
, product_id
, rank() over(partition by customer_id order by count(*) desc) as rk
-- group by之后分组情况如下图。开窗时只需要对customer_id进行分组,对每组中count(*)进行排序。
from orders
group by customer_id, product_id


三、困难
1、569)求中位数-1
中位数是一个数值,将一个数据集划分成两个长度相等的部分,其中一个部分的数据比它大,另一部分比它小。
SELECT id
FROM ( SELECT*,
row_number() over(partition by 公司 order by 工资 desc) as rn, --工资排序
count(id) over(partiton by 公司)as cnt --计算每个公司的员工数
FROM employee) a
WHERE rn >= cnt/2 and rn <= cnt/2+1 -- 如果员工个数为偶数,cnt/2和cnt/2+1两个数都是中位数;如果员工个数为奇数,cnt/2为浮点数,中位数为cnt/2+0.5包含在[cnt/2,cnt/2+1]。
2、571)求中位数-2
使用sum over(order by ) 对数字个数进行正序和逆序累计,当某一数字的 正序和逆序累计 均大于 整个序列的数字个数的一半 时即为中位数。

frenquency 为数字出现的频次,0无论进行倒序累计还是正序累计,数字个数都是大于12/2。

将最后选定的一个或两个中位数进行求均值即可。
SELECT avg(num) as median
FROM(
SELECT num,
sum(frequency) over(order by num desc) as desc_sum,
sum(frequency) over(order by num) as asc_sum
FROM numbers
)a
CROSS JOIN (SELECT sum(frequency) as total FROM numbers) b
WHERE desc_sum >= total/2 AND asc_sum >= total/2
3、1336)CTE(公共表表达式)
MySQL 在 8.0 的版本引入了公共表表达式(Common Table Expressions),简称 CTE。公用表表达式是一个命名的临时结果集。
WITH cte_name (column_list) AS (
query)
SELECT * FROM cte_name;
查询中的列数必须与column_list中的列数相同。 如果省略column_list,CTE将使用定义CTE的查询的列列表。
4、1336)构建数列
方法一:SELECT ROW_NUMBER() OVER() AS num FROM t (最大值为t表的记录数)
方法二:MySQL-使用递归。CTE 可以用来写递归。
WITH RECURSIVE cte (n) AS
(
SELECT 1 # 返回初始数据集,初始值为1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 5 # 返回递归后的数据集
)
SELECT * FROM cte;
①使用 WITH RECURSIVE 开头,关键词 RECURSIVE 表明这段表达式是递归表达式。
②自引用。第二个 SELECT 里面 FROM 子句之后接的是 CTE 名称,即在这里它引用了自身,这也是实现递归的关键逻辑所在。
③第1个 select代表它的初始数据集是 n = 1 。第2个select代表终止条件是 n < 5,迭代的表达式是 n = n + 1。
④如果没有终止条件或者表达式写得有问题(比如把n = n + 1 写成 n = n - 1),SQL 直到超出了递归最大深度后才会终止。
⑤注意:第一个CTE非recursive也讲"recursive"写在第一个CTE。
关于用递归生成连续序号的文章请看——生成数字序列
5、1767)递归CTE recursive
with recursive t(n) as (
select 1
union all
select n+1 from t where n<(select max(subtasks_count) from tasks)
)
6、1384)日期处理
1)datediff(end, start):日期差
2)dayofyear(date):求出某一天在一年中是第几天
3)date_add(date,INTERVAL expr type) :日期向后几天。向日期增加指定的时间间隔,expr为时间间隔,type参数可以为"HOUR\DAY\WEEK\MONTH\QUARTER\YEAR" 等
4)date_sub(‘2016-08-01’,interval 1 day) :日期向前1天。结果为 2016-07-31。向后为“interval -1 day”
5)year(date):取年份
6)date(date):提取日期或日期/时间表达式的日期部分。格式:YYYY-MM-DD
7)CAST(expr AS type)
8)date_format(date,format):将日期值格式化为特定格式。date_format(date,‘%Y-%m-%d’),结果“2022-01-01”。
https://www.runoob.com/sql/func-date-format.html

7、1384)内连接和交叉连接
内连接(join/inner join)的结果包含在交叉连接(cross join)中,通常内连接用 “=” 作为连接条件,但也可以使用 “<=” 和 “BETWEEN” 等谓词,筛选出cross join中的其他结果。
8、1767)补充字符长度 LPAD()
需求:对不足三位数的序号在前面补‘0’。
解决:MySQL 提供了 LPAD() 左填充函数。
9、1635)窗口函数——累计和移动平均数
1、count()
①累计count
select dealer_id, sales, count(*) over(order by dealer_id) as `count` from q1_sales;
| dealer_id | sales | count |
|---|---|---|
| 1 | 19745 | 4 |
| 1 | 19745 | 4 |
| 1 | 8227 | 4 |
| 1 | 9710 | 4 |
| 2 | 16233 | 7 |
| 2 | 16233 | 7 |
| 2 | 9308 | 7 |
| 3 | 15427 | 10 |
| 3 | 12369 | 10 |
| 3 | 9308 | 10 |
| ------------ | -------- | -------- |
②分组count
select dealer_id, sales, count(sales) over(partition by dealer_id) as `count` from q1_sales;
| dealer_id | sales | count |
|---|---|---|
| 1 | 19745 | 4 |
| 1 | 19745 | 4 |
| 1 | 8227 | 4 |
| 1 | 9710 | 4 |
| 2 | 16233 | 3 |
| 2 | 16233 | 3 |
| 2 | 9308 | 3 |
| 3 | 15427 | 3 |
| 3 | 12369 | 3 |
| 3 | 9308 | 3 |
| ------------ | -------- | -------- |
2、avg()
求移动平均数
select month,
ride_distance,
avg(ride_distance) over(order by month rows between current row and 2 following) as average_ride_distance
from q1_sales;


10、1892)not exists 和 not in 用法
结论: IN适合于外表大而内表小的情况(子查询表小);EXISTS适合于外表小而内表大的情况(子查询表大)。
select * from temp
where (user1_id,l.page_id) not in (
select user_id,page_id
from likes)
select * from temp
where not exists (
select *
from Likes
where user_id=user1_id
and page_id=l.page_id
)
11、2118)group_concat() 与 concat()
group_concat() :纵向拼接
concat() :横向拼接
GROUP_CONCAT(DISTINCT expression
ORDER BY expression
SEPARATOR sep)
CONCAT(expression1, expression2, expression3,...)

11、2153)临时变量 / 用户变量
变量:https://blog.csdn.net/qq_42374697/article/details/115278081

用户变量:一般在动态求和(累加)、排名中使用。
-- 动态求和(累加)
select person_name, @cnt:=@cnt+weight amount
from queue, (select @cnt:=0) t1
order by turn
1、声明并初始化
方式一★ :
SET @变量名 = 值;方式二 :
SET @变量名 := 值;方式三 :
SELECT @变量名 := 值;
2、赋值(更新变量的值)
方式一:★
SET @变量名=值;
SET @变量名:=值;
SELECT @变量名:=值;
例如:
SELECT
@row := row_no,
@name := book_name
FROM tb_book
WHERE id = 1;
注意:使用SET赋值时可以用“=”或“:=”,但是使用SELECT语句赋值时必须用“:=赋值”。
方式二:
SELECT 字段 INTO @变量名
FROM 表
where 条件;
例如:
①
SELECT AVG(`salary`) INTO @avg_s
FROM `employees`;
②
SELECT row_no,book_name INTO @row,@name FROM tb_book WHERE id = 1;
3、使用(查看变量的值)★
SELECT @变量名;
例如
①
SELECT @avg_s;
②输出结果
SELECT @row;
SELECT @name;
SET @m=1;
SET @n=1;
SET @sum-@m+@n;
SELECT @sum;
更多例子参见:sql中变量的使用 https://blog.csdn.net/qq_41081716/article/details/108428687
12、2252)动态sql语句/存储过程
SELECT CONCAT('SELECT product_id, '
, GROUP_CONCAT('MAX(CASE WHEN store = \'',store,'\' THEN price END) AS ',store)
, ' FROM Products GROUP BY product_id') INTO @sql
FROM temp;
上述动态代码@sql相当于下文:
SELECT product_id,
max(case when store = 'XXX' then price end) as XXX -- XXX是store的值
from products
group by product_id
完整的sql:
CREATE PROCEDURE PivotProducts()
BEGIN
# Write your MySQL query statement below.
-- 修改gourp_concat函数的默认长度
set group_concat_max_len = 102400;
-- 生成一个包含所有store名称的表
WITH temp as(
select distinct store
from products
order by store
)
-- 生成动态sql语句
SELECT CONCAT('SELECT product_id, '
, GROUP_CONCAT('MAX(CASE WHEN store = \'',store,'\' THEN price END) AS ',store)
, ' FROM Products GROUP BY product_id') INTO @sql
FROM temp;
-- 准备和执行生成的SQL语句
PREPARE statement FROM @sql;
EXECUTE statement;
END
13、连续的记录
方法一:窗口函数
count(row - row_number()) >= 3 连续3行
方法二:lag() lead() 函数
row +1 = lead(row,1,0) and lead(row,1,0)+1 = lead(row,2,0) 连续3行
lead() or lad() = 当前行 连续2行
方法三:自连接
方法四:用户变量
14、连续的记录(日期)
15、1225)subdate() 日期差
SUBDATE() 函数从日期中减去时间/日期间隔,然后返回日期。
SUBDATE(date, days)
date 必需。原日期
days 必需。从 date 中减去的天数
-- 从一个日期减去 10 天并返回日期:
SELECT SUBDATE("2017-06-15",10);
16、连接的书写方法
select *
from t1,t2 -- cross join 笛卡尔积
select *
from t1,t2
where t1.row_1 = t2.row_2 -- inner join
SQL基础教程-书
1-查询基础
1、SQL语句类型
DDL-数据定义语言(CREATE、DROP、ALTER)
DML-数据操纵语言(SELECT、INSERT、UPDATE、DELETE)
DCL-数据控制语言(COMMIT、ROLLBACK、GRANT、REVOKE)
2、常数的查询
SELECT '商品' AS string,
38 AS number,
'2009-02-24' AS date,
product_id,
product_name
FROM Product;
3、删除重复行
distinct():含有null的行,也会当作一类数据被保留
4、注释
● 1行注释:书写在“–”之后,只能写在同一行。
● 多行注释:书写在“/* ”和“*/”之间,可以跨多行
5、算数运算
加法运算 +
减法运算 -
乘法运算 *
除法运算 /
注:含null的运算,结果都是null
6、比较运算符
和~相等 =
和~不相等 <>
大于等于~ >=
大于~ >
小于等于~ <=
小于~ <
注:无法对null使用比较运算符,只能使用is null,或者 is not null。
7、字符串的比较
字符串类型(chr)的数据在进行比较的时候,有以下规则:
只比较第一位,可以将“11”看作“1-1”,“1-1”应比“2”小,所以字符串类型下,“11”<“2”。
8、逻辑运算符
NOT:用来否定某一条件(不常用)
AND:在其两侧的查询条件都成立时整个查询条件才成立
OR:在其两侧的查询条件有一个成立时整个查询条件都成立
注:AND 运算符优先于 OR 运算符。想要优先执行OR运算符时可以使用括号()。
2-聚合与排序
1、聚合函数
COUNT:计算表中的记录数(行数)
SUM: 计算表中数值列中数据的合计值
AVG: 计算表中数值列中数据的平均值
MAX: 求出表中任意列中数据的最大值
MIN: 求出表中任意列中数据的最小值
COUNT(*):计算全部数据的行数
聚合函数会忽略null进行计算:
COUNT(purchase_price):计算NULL之外的数据的行数
SUM 函数,即使包含 NULL,也可以计算出合计值。
AVG计算平均值的情况与 SUM 函数相同,会事先删除 NULL再进行计算。
MAX/MIN 函数几乎适用于所有数据类型的列。只要是能够排序的数据,就肯定有最大值和最小值。SUM/AVG函数只适用于数值类型的列。
eg:日期不能sum,但是可以用max
2、聚合函数常见错误
①使用聚合函数时,SELECT 子句中只能存在以下三种
元素:
● 常数
● 聚合函数
● GROUP BY子句中指定的列名(也就是聚合键)
②在GROUP BY子句中写了列的别名:

③只有SELECT子句和HAVING子句(以及ORDER BY子句)中能够使用聚合函数:

3、DISTINCT 和 GROUP BY
distinct 和 group by 都能够删除后续列中的重复数据,能够实现相同的功能:
SELECT DISTINCT product_type
FROM Product;
SELECT product_type
FROM Product
GROUP BY product_type;
-- 执行结果相同
4、HAVING子句
where 只能指定记录(行)的条件,having 可以指定组(集合)的条件。
HAVING 子句中能够使用的 3 种要素:
● 常数
● 聚合函数
● GROUP BY子句中指定的列名(即聚合键)
优先用where子句
5、ORDER BY 排序
①ASC 和 DESC 是 ascendent(上升的)和descendent(下降的)这两个单词的缩写,只作用于1列。
②含null的列:不能对NULL 使用比较运算符,也就是说,不能对 NULL 和数字进行排序,也不能与字符串和日期比较大小。因此,使用含有 NULL 的列作为排序键时,NULL 会在结果的开头或末尾汇总显示。
③ORDER BY 子句中却是允许使用别名。因为执行顺序中,orderby在select之后执行。另外,也可以使用SELECT子句中未使用的列和聚合函数。

6、SQL执行顺序
①执行顺序:
FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY

②书写顺序:
SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY
3-数据更新
数据的插入(INSERT语句的使用方法)
数据的删除(DELETE语句的使用方法)
数据的更新(UPDATE语句的使用方法)
事务
略
4-复杂查询
1、视图
视图——> select语句产生的临时表,结果并不会储存在硬盘中
CREATE VIEW 视图名称(<视图列名1>, <视图列名2>, ……)
AS
视图的限制:
①定义视图时不能使用ORDER BY子句
②对视图进行更新:from子句只有一张表,且视图未聚合(未使用distinct、group by、having)。对视图的更新会影响原表
2、子查询
子查询就是一次性视图,子查询在select语句执行完毕之后就会消失
子查询需要命名
先执行内层子查询,再执行外层的select语句
3、标量子查询
只返回一行一列的单一值的子查询为标量子查询。

几乎所有地方都可以使用标量子查询:
无论是 SELECT 子句、GROUP BY 子句、HAVING 子句,还是
ORDER BY 子句,能够使用常数或者列名的地方都可以使用。

普通子查询不能用在select子句中,也不能用在运算符中:

4、关联子查询
普通子句不能用在运算符中,关联子查询可以。
SELECT product_type, product_name, sale_price
FROM Product AS P1
WHERE sale_price > (SELECT AVG(sale_price)
FROM Product AS P2
WHERE P1.product_type = P2.product_type --这个条件是关键
GROUP BY product_type);
- 这里起到关键作用的就是在子查询中添加的 WHERE 子句的条件。该条件的意思就是,在同一商品种类中对各商品的销售单价和平均单价进行比较。
- 条件必须放在内部:因为子查询内部的关联名称(p2)只能用于内部。“内部可以看到外部,而外部看不到内部”。
5、关联名称的作用范围
- “内部可以看到外部,而外部看不到内部”
- SQL是按照先内层子查询后外层查询的顺序来执行的,外层执行的时候,内层已经执行结束只留下执行结果。

5-函数、谓词、CASE表达式
1、函数分类
● 算术函数(用来进行数值计算的函数):加+ 减- 乘* 除/ 等
● 字符串函数(用来进行字符串操作的函数)
● 日期函数(用来进行日期操作的函数)
● 转换函数(用来转换数据类型和值的函数)
● 聚合函数(用来进行数据聚合的函数):只有COUNT、SUM、AVG、MAX、MIN共5个
注:绝大多数的函数对于null都返回null。
2、算术函数
①ABS(数值)——绝对值;
②MOD(被除数,除数)——求余数,SQL Server使用“%”来计算余数;
③ROUND(对象数值,保留小数的位数)—— 四舍五入;
3、字符串函数
①拼接——MySQL使用CONCAT函数; SQL Server使用“+”运算符;其他用“字符串1||字符串2”;
②LENGTH(字符串)——字符串长度;SQL Server使用LEN函数;汉字1个字符会返回多个字节;
③LOWER(字符串)——小写转换;UPPER(字符串)大写转换
④REPLACE(对象字符串,替换前的字符串,替换后的字符串)——字符串的替换
⑤字符串的截取:
-SUBSTRING(对象字符串 FROM 截取的起始位置 FOR 截取的字符数)——PostgreSQL 和 MySQL 专用;
-SUBSTRING(对象字符串,截取的起始位置,截取的字符数)——SQL Server专用;
-SUBSTR(对象字符串,截取的起始位置,截取的字符数)——Oracle/DB2专用;
4、日期函数
①当前日期:
-CURRENT_DATE——无法在 SQL Server 中执行;
-CAST(CURRENT_TIMESTAMP AS DATE)——SQL Server使用;
-CURRENT_DATE——Oracle使用;
②当前时间:
-CURRENT_TIME——无法在 SQL Server 中执行;
-CAST(CURRENT_TIMESTAMP AS TIME)——SQL Serve;
-CURRENT_TIMESTAMP——Oracle,得到的结果还包含日期;
③当前日期和时间:
-CURRENT_TIMESTAMP——可以在SQL Server 中执行;
④EXTRACT(日期元素 FROM 日期)—— SQL Server 使用DATEPART函数;
5、CAST 转换函数
①CAST(转换前的值 AS 想要转换的数据类型)——数据类型转换,将字符串类型转化成整数类型(integer)或日期类型(date);
cast(year as char) -- 将日期转化为文本格式
②COALESCE(数据1,数据2,数据3……)——将NULL 转换成其他值,参数个数可以自由设定,是 SQL 特有的函数,各种DBMS 中都可用;Oracle 中 NVL为简化版;
6、谓词
● LIKE
● BETWEEN
● IS NULL、IS NOT NULL:判断是否为null
● IN、NOT IN:OR的简便用法,选取对象很多的时候用。可以使用子查询作为参数。
● EXISTS
7、LIKE
-LIKE '%ddd%':包含“ddd”的记录
-LIKE 'abc_ _':值为“abc + 任意 2 个字符”的记录
8、BETWEEN
BETWEEN 的特点就是结果中会包含两个临界值。
如果不想让结果中包含临界值,那就必须使用 < 和 >。
9、EXIST 谓词
EXIST 只需要在右侧书写 1 个参数,该参数通常都会是一个子查询。
EXIST(存在)谓词的主语是“记录”。由于 EXIST 只关心记录是否存在,因此返回哪些列都没有关系。SELECT子句可以写任意列。存在符合条件的记录即判断为真。
SELECT product_name, sale_price
FROM Product AS P
WHERE EXISTS (SELECT 1 -- 这里可以书写适当的常数
FROM ShopProduct AS SP
WHERE SP.shop_id = '000C'
AND SP.product_id = P.product_id);
可以把在 EXIST 的子查询中书写 SELECT * 当作 SQL 的一种习惯。
EXIST基本上也都可以使用 IN(或者 NOT IN)来代替。
10、CASE表达式
CASE WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
WHEN <求值表达式> THEN <表达式>
. . .
ELSE <表达式>
END
如果when为真,就返回then子句中的表达式,case执行到此为止。如果不为真,就跳到下一条when子句的求值。如果直到最后一条when为止结果都不为真,那么就返回else中的表达式,执行终止。
CASE表达式可以书写在任意位置。
11、行列互换
SELECT SUM(CASE WHEN product_type="衣服"
THEN sale_price ELSE 0 END) as sum_price_clothes,
SUM(CASE WHEN product_type="厨房用具"
THEN sale_price ELSE 0 END) as sum_price_kitchen,
SUM(CASE WHEN product_type="办公用品"
THEN sale_price ELSE 0 END) as sum_price_office
FROM product;

12、简单CASE表达式
CASE <表达式>
WHEN <表达式> THEN <表达式>
WHEN <表达式> THEN <表达式>
WHEN <表达式> THEN <表达式>
. . .
ELSE <表达式>
END

6-集合运算
1、行的运算

1)UNION
选取表的并集。
①UNION会除去重复的记录,UNION ALL会保留重复的记录
②列数必须相同
③列的类型必须相同
④ORDER BY 子句只能在最后使用一次
2)INTERSECT
选取表中的交集。
①INTERSECT ALL会保留重复的记录
SELECT product_id, product_name
FROM Product
INTERSECT
SELECT product_id, product_name
FROM Product2
ORDER BY product_id;

3)EXCEPT
补集,做减法
SELECT product_id, product_name
FROM Product
EXCEPT
SELECT product_id, product_name
FROM Product2
ORDER BY product_id;
表1中不与表2重合的部分。

2、列的运算——联结

a JOIN b ON a.id=b.id
a JOIN b USING (id)
1)内连接——INNER JOIN (JOIN)
内联结只能选取出同时存在于两张表中的数据。
SELECT SP.shop_id, SP.shop_name, SP.product_id, P.product_name, P.sale_price
FROM ShopProduct AS SP
JOIN Product AS P
ON SP.product_id = P.product_id
WHERE SP.shop_id = '000A';
SELECT SP.shop_id, SP.shop_name, SP.product_id, P.product_name, P.sale_price
FROM ShopProduct SP, Product P
WHERE SP.product_id = P.product_id AND SP.shop_id = '000A';
2)外连接——OUTER JOIN(LEFT JOIN/ RIGHT JOIN/FULL OUTER JOIN)
对于外联结来说,只要数据存在于某一张表当中,就能够读取出来。
①left join:左表为主表。结果表包含主表中的所有数据。
②right join:右表为主表。结果表包含主表中的所有数据。
③full outer join:结果表包含左右表中的所有数据。
3)交叉连接——CROSS JOIN(笛卡尔积)
SELECT SP.shop_id, SP.shop_name, SP.product_id, P.product_name
FROM ShopProduct AS SP
CROSS JOIN Product AS P;
inner join 的结果是cross join结果中符合条件的那些。cross join的结果是两个表所有可能的组合结果。
7-SQL高级处理
1、窗口函数
窗口函数为每行数据进行一次计算,输入多行数据(窗口),返回一个值。
1、窗口函数兼具分组和排序两种功能。
<窗口函数> OVER ( [PARTITION BY <列清单>]
ORDER BY <排序用列清单>)
2、窗口函数类型
① 能够作为窗口函数的聚合函数(SUM、AVG、COUNT、MAX、MIN)
② RANK、DENSE_RANK、ROW_NUMBER等专用函数
3、窗口函数使用限制:
窗口函数只能在SELECT子句中使用。不能在WHERE 子句或者 GROUP BY 子句中使用。
原因是窗口函数是对WHERE子句和GROUP BY子句处理后的结果进行操作的。
4、ORDER BY的区别 :
窗口函数中的order by 只是用来决定窗口函数根据什么顺序进行计算,对结果的排序没有影响。因此也可能会得到乱序的结果。需要再次使用ORDER BY子句对结果进行排序。
2、窗口函数-专用函数
1)专用函数原理-rank为例
SELECT product_name, product_type, sale_price,
RANK () OVER (PARTITION BY product_type
ORDER BY sale_price) AS ranking
FROM Product;

2)专用函数
●RANK:存在相同位次的记录,则会跳过之后的位次。
eg:有 3 条记录排在第 1 位时:1 位、1 位、1 位、4 位……
●DENSE_RANK:存在相同位次的记录,也不会跳过之后的位次。
eg:有 3 条记录排在第 1 位时:1 位、1 位、1 位、2 位……
●ROW_NUMBER:赋予唯一的连续位次。
eg:有 3 条记录排在第 1 位时:1 位、2 位、3 位、4 位…
rank() over(partition by XXX order by XXX);
dense_rank() over(partition by XXX order by XXX);
row_number() over(partition by XXX order by XXX);
3、窗口函数-聚合函数
1)聚合窗口函数需要填写聚合的列:
SELECT product_id, product_name, sale_price,
AVG (sale_price) OVER (ORDER BY product_id) AS current_avg
FROM Product;

2)移动平均数:
①关键词:ROWS(“行”)和 PRECEDING(“之前”)
eg:ROWS 2 PRECEDING
SELECT product_id, product_name, sale_price,
AVG (sale_price) OVER (ORDER BY product_id
ROWS 2 PRECEDING) AS moving_avg
FROM Product;
-- rows 2 preceding “截至到之前2行”
这里我们使用了 ROWS(“行”)和 PRECEDING(“之前”)两个关键字,将框架指定为“截止到之前 ~ 行”,因此“ROWS 2 PRECEDING”就是“截止到之前 2 行”,即当前记录和它前面的两条记录。
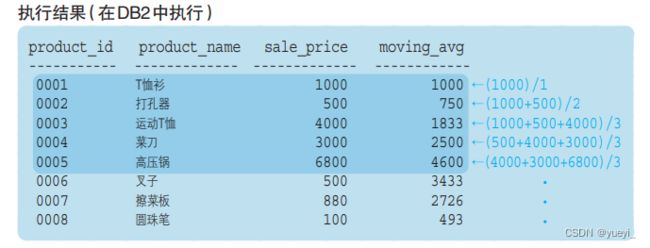

②关键字: FOLLOWING(“之后”)。
eg:ROWS 2 FOLLOWING
SELECT product_id, product_name, sale_price,
AVG (sale_price) OVER (ORDER BY product_id
ROWS 2 FOLLOWING) AS moving_avg
FROM Product;
--截止到之后2行

③关键词:区间
eg:ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
SELECT product_id, product_name, sale_price,
AVG (sale_price) OVER (ORDER BY product_id
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS moving_avg
FROM Product;
--当前记录的前1行和后1行

4、GROUPING 运算符
GROUPING运算符可以用来计算小计和合计。
GROUPING 运算符包含以下 3 种:
●ROLLUP
●CUBE
●GROUPING SETS
注:目前PostgreSQL和 MySQL并不支持GROUPING运算符(MySQL仅支持ROLLUP)。
5、GROUPING 运算符-ROLLUP
1)计算一个小计和总计:
SELECT product_type, SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type);
注:在MySQL中需要将GROUP BY子句改写为“GROUP BY product_type WITH ROLLUP;”。

在本例中就是一次计算出了如下两种组合的汇总结果:
① GROUP BY ()
② GROUP BY (product_type)
2)计算两个小计和总计:
SELECT product_type, regist_date, SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type, regist_date);
注:在MySQL中需要将GROUP BY子句为“GROUP BY product_type, regist_date WITH ROLLUP;”。

在本例中,相当于使用 UNION 对如下 3 种模式的聚合级的不同结果进行连接:
① GROUP BY ()
② GROUP BY (product_type)
③ GROUP BY (product_type, regist_date)

6、GROUPING 函数
1)grouping函数:让NULL更加容易分辨。
该函数在其参数列的值为超级分组记录所产生的 NULL 时返回 1,其他情况返回 0。
SELECT GROUPING(product_type) AS product_type,
GROUPING(regist_date) AS regist_date,
SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type, regist_date);
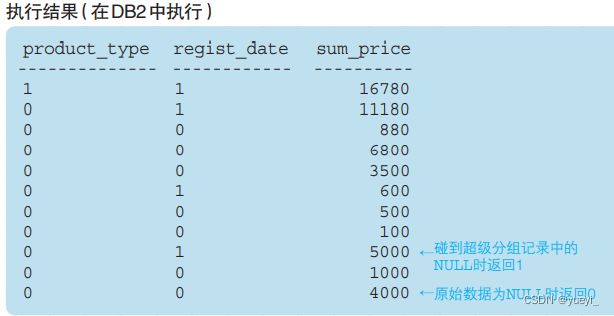
2)函数应用:
SELECT CASE WHEN GROUPING(product_type) = 1
THEN '商品种类 合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date) = 1
THEN '登记日期 合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,--返回字符串数据类型,因为case表达式要求返回值必须一致。
SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type, regist_date);

7、GROUPING 运算符-CUBE
1)用法:CUBE 的语法和 ROLLUP 相同,只需要将ROLLUP 替换为 CUBE 就可以了。
SELECT CASE WHEN GROUPING(product_type) = 1
THEN '商品种类 合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date) = 1
THEN '登记日期 合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
SUM(sale_price) AS sum_price
FROM Product
GROUP BY CUBE(product_type, regist_date);
在本例中,相当于使用 UNION 对如下 4 种模式的聚合级的不同结果进行连接:
① GROUP BY ()
② GROUP BY (product_type)
③ GROUP BY (regist_date)
④ GROUP BY (product_type, regist_date)
8、GROUPING 运算符-GROUPING SETS
GROUPING SETS运算符可以从 ROLLUP 或者 CUBE 的结果中取出部分记录。
SELECT
warehouse,
product,
SUM (quantity) qty
FROM
inventory
GROUP BY
GROUPING SETS(
(warehouse,product),
(warehouse),
(product),
()
);

8-通过应用程序连接数据库
略
a-zA-Z ↩︎