3D机器人视觉在仓储物流和工业自动化领域的应用 | AI ProCon 2019

整理 | 夕颜
出品 | AI科技大本营(ID:rgznai100)
随着深度学习和机器学习的发展,机器人已经走出实验室,越来越多地地应用于各行各业,其中,仓储物流和工业化领域就有许多适合机器人作业的场景环境。
人眼的一大能力是除了看到物体之外,还可以得到物体的深度信息,从而可以从更高维度实现定位识别。在工业自动化和仓储物流等对自动化有较高需求的产业领域,3D 视觉、人工智能和工业机器人的结合而成的“3D机器人视觉”正逐渐成为一种趋势,3D 机器人视觉让工业机器人等自动化装置能以更高精度、更快速度执行更复杂的工作,是产业自动化升级乃至将自动化技术推向更多产业领域必不可少的一环。

然而,你了解各种形态的机器人背后所用到的具体 AI 技术吗?3D 机器人又是什么样的概念?是否所有的机器人都有必要用到深度学习和机器学习技术才能达到最好的效果?带着这些疑问,让我们从杭州灵西机器人首席科学家,北京大学信息科学技术学院博士王灿在 2019 AI 开发者大会(AI ProCon 2019)上的演讲《3D机器人视觉在仓储物流和工业自动化领域的应用》中找寻答案。
2019 AI开发者大会是由中国 IT 社区 CSDN 主办的 AI 技术与产业年度盛会,2019 年 9 月 6-7 日,近百位中美顶尖 AI 专家、知名企业代表以及千余名 AI 开发者齐聚北京,进行技术解读和产业论证。
以下为王灿的演讲实录整理,AI科技大本营整理(ID:rgznai100):
3D视觉成像原理分类

今天我带来的演讲题目是《3D机器人视觉在仓储物流和工业自动化领域的应用》。说到3D机器人视觉,我们得先从 3D 成像讲起。3D 视觉成像按成像原理,可以大概归纳为三类: 飞行时间原理、通过光线的时间差恢复深度,以及三角测量原理。
在机器视觉领域,运用最广泛的是测距原理,并衍生出很多 3D 传感器、双目多目、线结构光、相移结构光、散斑结构光,还有散斑编码原理、多光谱共焦原理、光度测量、干度测量方法。
飞行时间原理

飞行时间原理是基于一个光线的发射器调制出的激光,通过物品本身的反射算出与物体之间的距离 ,但它有一个缺点,即因为它是通过光线速度传播的时间差来测量深度的,所以在深度差距 1 毫米时,光线差距可以算出来,但对于一个对高频电路设计有很高要求的电子器件来说,这个技术门槛限制了它的精度,只能做到亚厘米级精度。这两年,超声 ToF 克服了光学 ToF 的很多缺点,能够达到更高的精度,但是目前还未广泛应用于消费级或工业级产品上,还处于产品研发阶段。
三角测量原理
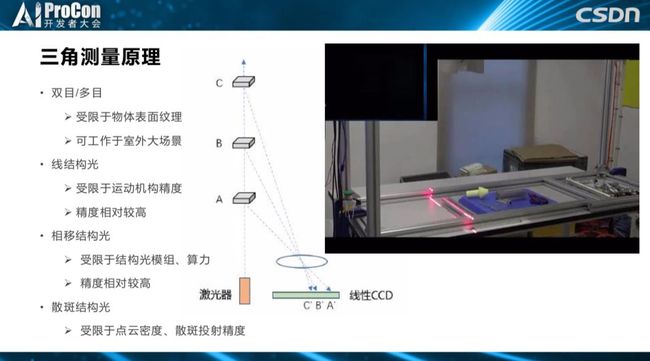
三角测量原理是指一大类3D传感器,最早是基于双目视觉。 对视觉有了解的同学应该都知道,它的缺点是必须要图像能够获得纹理信息,比如用我们所熟知的脚点,来计算信息特征点的双匹配,并恢复深度。这种方法的优势是可以用于室外环境和宽广的视野。
为了克服双目的成像缺点,在消费级和工业级的 3D 相机应用中,大家非常喜欢主动结构光的技术,主动投射结构光,无论是线结构光还是条纹光,或者是用投射散斑,这相当于为相机获得的图像人为地增加很多纹理特征,进行匹配。这里有个最简单的线扫结构光的应用,通过投射的主动光源,就可以把桌子上的物体深度恢复出来,基于最简单的激光器投射是它最基本的原理。
散斑编码原理

对于散斑编码原理,直接投射出的结构光就代表它的深度,2001 年微软最早推出第一代第一代kinect时所用的就是结构光,在不同深度上投射出不同的模式,通过获得光的模式可以直接计算深度。该原理广泛应用于 3D 手机端摄像头上。
光谱共焦测量原理

这是在 3D 成像兴起之前,在光学测量领域盛行的单点 3D 测量原理——光谱共焦测量原理,以后大家如果在工业级项目中客户要求非常高时,比如要达到 1 微米的量级,之前提到的结构光就很难做到,做工业测量适合选用这种原理。但是,它的劣势在于只能作为单点测量的工具,当然也有线阵测量,但比较困难,国内还没有看到做线阵测量特别成熟的产品。打出白光后通过分色器,把不同光点射拉大,这相当于投射在物体表面的距离所代表光的波段会非常大,物体移动 1 厘米,光的波段就会移动几纳米。如此,最后光谱解析器会解析到聚焦于物体表面光的波动,通过波长的数量推测物体的高度,这样就可以获得很高精度。
3D视觉算法
传统方法VS学习方法

讲完了 3D 视觉成像硬件方面的原理,下面来看一下 3D 视觉成像的算法。3D 视觉成像算法起源于七八十年代的光测度算法,让一束光均匀地打在物体表面,反推出它的深度,这是最早的一种算法。
其次,用到最多的是几何算法,主要是通过视差,同样一个三维点,在不同的相机中对应的位置不同,通过对应关系的差距来恢复它的深度。
现在,随着深度学习的兴起,有越来越多的数据集在做这方面的工作,尝试基于先验统计,从单幅图像中恢复三维结构。这个想法的原理基于这样一个事实,即人类用一只眼睛也能感觉到距离的远近,这是因为我们的大脑拥有先天的结构和后天认知的输入,已经获得可很多先验知识。当然,学界也有人提出反对意见,我在马毅老师的微博上引用了他对该方法的评价:“涉及到很复杂的网络,试图做深度恢复,比如单张图,但是真正去细抠算法性能还不如传统基于最近邻理论的原则算法。我认为他的说法是正确的,因为深度学习并没有利用几何关系,我们试图用一个模糊的网络去学习精确的东西,往往很难达到满意的效果。

说到这一点,我大致调研了一下最近两年的代表性工作。上图是最古老的光测度测量方法,获得了CVPR 2019的最佳论文,它的原理是通过一个不可见物体,或在半透的情况下,利用模糊的光照信息,试图恢复物体表面的深度信息。当然,这篇论文提出了一些较好的理论,虽然与最早的光测度算法一样对光照和材料的材质都有很高的要求,但这种方法也为该领域提出了一个新的思路和方向。

还有人对性能进行了量化分析,这是 3D 点源测试图,每个点都是一个 XYZ 坐标,测试不同网络模型下的性能,结果网络性能的表现不一,每个网络在不同图片上的表现也不同。最后,作者得出结论:一张测试图片和原始训练数据集中图片非常相近时,就能够搜索训练的图片,得到较高的 3D 图得分,它只是进行了搜索和分类,恰好找到了一张与它相似的图片而已。
几何方法VS学习方法

还有一些工作非常具有借鉴意义,几何方法涉及到很多自由化的问题,如何把现在的学习方法引入到自由化问题中,如更好地解决优化问题,可能是几何方法与学习方法融合的一个趋势。但是,我认为在工业领域,可能我们更多地是追求可靠性和可控性。所以,目前学习方法还不能替代几何方法。
机器人视觉

接下来讲一下机器人视觉。机器人视觉的本质在于,机器人视觉是输入信息,包括数字信息和图片,但是输出要作用于物理世界,反映出来的是在物理世界的一个动作,这是机器人视觉吸引人的地方。我之前在腾讯做视频分析和 AR 广告植入,之后在中科院做过安防监控、视频分析等,但是这些都局限在数字世界中信息的输入输出上。但是机器人视觉与之不同,机器人视觉是先通过传感器获得数字世界信息,然后作用于物理世界,这是它的魅力所在。

3D 机器人视觉的必要性,我们不仅做机器人视觉,还做 3D 机器人视觉,机器人视觉要在真实物理世界中工作,需要获得三维信息才能执行动作。2D 机器人视觉会做假设,比如将物体放在一个平面上,但最终发出的指令还是 3D 的,如果要把机器人视觉推广到更复杂、更广泛的应用中,必然需要 3D 机器人视觉。
上图是我们之前在实验室中做的一些 demo。这个双臂的 hero 机器人拥有十几个自由度,再加上物体的三维运动,规划不同任务下的摆放、拼接、抓取、识别的问题,首先我们要面对的不是视觉问题,而是机器人规划问题,我们要把物理世界的三维运动通过机器人解决十几个轴的高维空间规划问题,视觉只是起到了给它发送目标指令的作用,比如抓取位置、抓取姿态、摆放位置、摆放方法等,机器人执行的是非常复杂的高维空间规划。

上图是我们公司自己做的一些 3D 相机,第一个是双目散斑相机,用的是线结构光,线结构光的优势是精度较高,但执行效率比双目和面结构光稍差,但优势在于精度高。根据精度、视野等各种要求,不同原理的 3D 相机应用于不同的场景。
为什么我们要自己做相机?这是因为现在市场上虽然有很多人在做 3D 相机产品,但是由于需求不成熟,很多相机是非标定制的,满足不了客户的不同需求,类似的产品可能在精度上相差几个量级,所以,我们需要自己做 3D 相机设备,打造灵活的非标定制需求。
应用案例
仓储物流领域

这是我们在仓储领域主要应用的架构。首先,我们要有一个对接各类机器人本体的控制系统,控制系统主要负责又快又准又安全地进行机器人规划和检测,我们基本上可以对接四大家族(日本的安川电机 YASKAWA、发那科 FANUC、德国的库卡 KUKA、瑞士的 ABB),包括国产的比较有名的机器人,把它们集成到我们的控制器中。我们的视觉系统用于解决仓储物流领域的各种应用,包括各类消费品软包装食品、整托产品、金属制品。

这是我们参选“Top30+”评选案例的京东家电仓,它可以节省劳动力,提高效率,减轻工人作业负担。在这个场景中,机器人可以拆分不同类型的垛,箱子尺寸从 100mm 到 800mm 不等,任何形状的包装都有可能出现,且没有鲜艳的色彩,这对机器学习提出了挑战。这种问题在实际应用非常常见,比如视觉检测结果。

在电商领域机器人可以参与到哪些场景中呢?网购之后,会有人根据订单去拣货区取货,再分配到缓存区,自动化叉车把缓存区的东西卸到投递区,我们的机器人可以在投递区作业,节省人力和成本。

这是一个比家电仓更复杂的水饮仓,包装五颜六色,摆放状态不一。它的难点一是于算法,二是在于光学设计,如何获取非常复杂的各种物体的成像信息,这对硬件、软件和算法都提出了很高的要求。我们公司在国内首次将仓储物流 3D 机器人落地。

物流领域对成本非常敏感,基本上要求一年就要收回成本。
工业领域

在工业领域,这是我们为一家美国铸件公司提供的方案。工厂里铸造件降温时是黑色的,无法分辨形状,只能依靠 3D 视觉解决这个问题。工件有堆叠,也有姿态,所以需要有输出才能抓取,这个项目最后也成功落地了。但是工业领域我们做的比较少,因为工业领域非标定制需求太多,而且不成规模,这一点与电商仓储领域不同。

这是在其他领域的应用,比如京东供包,各种包裹在传输带上通过,它的难点在于视觉反应速度,这套系统不仅要测出位置,还要解决分割的问题,不能把两个包裹当成一个包裹,也不能把一个包裹当成两个包裹。它还要测量体积,包裹经过时,3D 相机可以通过物体表面点的分布推算出体积,这样商品入库时既得到了面单信息,又得到了体积信息。更全面的产品信息还应该加上称重,一次性得到所有信息,然后由机器人抓取。目前,机器人主要集中在大的分拣中心和物流中心。
另外,我们的其他产品案例还包括用协作性机器人进行柔性物体的抓取、小型分拣等。
Q&A
Q1:您刚才讲到 3D 视觉容易受光线的影响,能详细说一下吗?
A1: 因为 3D 成像可以用非结构化成像,所以自然界中的可见光对算法没有影响。
Q2:现在的相机已经有这个功能?
A2: 对,在物流领域,一般我们用 800 万的光线,用红外光线较多。
Q3:您讲到抓取物体也可以用到一些2D检测技术,再与3D视觉相结合,具体如何结合?3D视觉技术在于3D相机和相机的参数和编码,它与机器学习或机器视觉有什么关系?
A3 :首先对两个相机做外参数标定,标定完之后,相当于知道了XYZ的信息,就可以把 XYZ 坐标映射到 2D 相机坐标下,通过内参数映射到坐标旗下。你可以反向投射回去,比如在2D平面上获取一个区域的信息,3D 成像的点云是面,可以用 2D 投射回去,对应到 3D 点云上的某一区域,从 2D 到 3D 是多解的,但 3D 也是一个面,虽然是 3D,但是在物体上投射过去之后,还是能对应到点云上,再在点云上计算对应的点位置就可以了。
至于 3D 视觉技术与机器学习的关系,从几年前开始就已经有很多基于单幅图像来恢复 3D 信息的工作,他们认为基于一个 3D 图像是可以恢复深度图的。当然,这种方法在实际应用中也有一定的效果,一张图深度恢复到网络,就可以恢复出距离,端到端的网络可以做到。我后面讲到的融合主要是几何的方法,多视角几何本来可以通过纯理论推算,只不过后面计算时用到一些优化的方法,深度学习不引入任何结构,比如两个双目,明明可以通过标定算法,内参外参全部标定出来,这是一个非常复杂的参数,理论可推导的可能有二三十个因子,一定要用深度学习得到一个非常精确的因子。我认为,如果通过几何标定已经可以做到亚毫米的精度,却非用深度学习学出高精度是没有必要的。
但是,深度学习网络可以帮助做 3D 几何方法中的结构化模块。
Q4:用 3D 相机得到深度,之后的处理手段会用到深度学习和机器学习吗?
A4 :会,获取 3D 信息之后,3D 信息就是一个三维的矩阵,也可以把它变成二维信息,也就是图像,深度图像一样可以用 2D 的深度学习方法处理,也有很多直接处理 3D 点源的网络。用传统方法,识别 3D 点源拍出来的物体目标也有很多方法。
Q5:3D 相机成本有多高?
A5: 消费级的 3D 相机陈本可能只有几百上千,但工业场景中对精度和速度要求很高陈本就不是一个量级的了,它的成本主要分布在几个方面,一个是主动光源模组的成本,模组做得越精密,工艺越复杂就越贵。现在在消费电子领域,比如在移动端手机上,有很多原理的深度摄像头,他们可能用的工艺不同,成本功耗也都不同。
第二,精度,理论上来说,用的分辨率越高达到的精度越高,这只是精度问题,实际应用中还要考虑速度问题,这要求带宽足够,比如用 500 万的相机获得 100 帧的帧率,要保证嵌入式这块做得非常好,才能满足带宽需求,成本也随之大大提高。
Q6:京东的机器人相机的成本是多少?
A6:大约有 10 万,那个相机比较复杂,包括光学和内部结构、GPU 计算都比较特殊。
灵西机器人首席科学家,北京大学信息科学技术学院博士
演讲嘉宾:
王灿, 杭州灵西机器人首席科学家,北京大学信息科学技术学院博士
(*本文为 AI科技大本营整理文章,请微信联系 1092722531)
◆
精彩推荐
◆
20 19 中国大数据技术大会(BDTC)再度来袭! 豪华主席阵容及百位技术专家齐聚, 15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。
限量 5 折票开售,数量有限,扫码购买,先到先得!

推荐阅读

你点的每个“在看”,我都认真当成了AI