Magic3D: High-Resolution Text-to-3D Content Creation(高分辨率文本到3d内容创建)
Magic3D: High-Resolution Text-to-3D Content Creation(高分辨率文本到3d内容创建)

Paper:https://readpaper.com/pdf-annotate/note?pdfId=4738271534435532801¬eId=1848084184935912192
Project:https://research.nvidia.com/labs/dir/magic3d/
原文链接:Magic3D: 高分辨率文本到3d内容创建(by 小样本视觉与智能前沿)
文章目录
- Magic3D: High-Resolution Text-to-3D Content Creation(高分辨率文本到3d内容创建)
-
- 01 现有工作的不足?
- 02 文章解决了什么问题?
- 03 关键的解决方案是什么?
- 04 取得了什么样的效果?
- 05 主要的贡献是什么?
- 06 有哪些相关的工作?
- 07 方法具体是如何实现的?
-
- Background: DreamFusion
- High-Resolution 3D Generation
-
- 1)Coarse-to-fine Diffusion Priors
- 2)Scene Models
- 3)Coarse-to-fine Optimization
- 08 实验结果和对比效果如何?
-
- Speed evaluation
- Qualitative comparisons.
- User studies.
- Personalized text-to-3D.
- Prompt-based editing through fine-tuning.
- 09 消融研究告诉了我们什么?
-
- Can single-stage optimization work with LDM prior?
- Can we use NeRF for the fine model?
- Coarse models vs. fine models.
- 10 结论
01 现有工作的不足?
DreamFusion存在两个固有的局限性:(a) NeRF优化速度极慢;(b)对NeRF进行低分辨率图像空间监督,导致处理时间长,3D模型质量低。
02 文章解决了什么问题?
我们通过利用两阶段优化框架来解决DreamFusion存在的上述两个局限性。即提升优化速度和改善3D模型的质量。
03 关键的解决方案是什么?
- 首先使用低分辨率扩散先验获得粗糙模型,并使用稀疏的3D哈希网格结构进行加速。
- 使用粗糙表示作为初始化,进一步优化了纹理3D网格模型,并使用高效的可微分渲染器与高分辨率潜在扩散模型相互作用。
04 取得了什么样的效果?
我们的方法被称为Magic3D,可以在40分钟内创建高质量的3D网格模型,这比DreamFusion快2倍(据报道平均需要1.5小时),同时也实现了更高的分辨率。
用户研究显示,相比DreamFusion, 61.7%的评分者更喜欢我们的方法。再加上图像条件生成功能,我们为用户提供了控制3D合成的新方法,为各种创意应用开辟了新的途径。
05 主要的贡献是什么?
- 我们提出Magic3D,这是一个使用文本提示进行高质量3D内容合成的框架,通过改进DreamFusion中的几个主要设计选择来实现。它由一个从粗到精的策略组成,该策略利用低分辨率和高分辨率扩散先验来学习目标内容的3D表示。Magic3D合成3D内容的分辨率比DreamFusion高8倍,速度也比DreamFusion快2倍。通过我们的方法合成的3D内容明显受到用户的青睐(61.7%)。
- 我们将为文本到图像模型开发的各种图像编辑技术扩展到3D对象编辑,并在提出的框架中展示其应用。
06 有哪些相关的工作?
- Text-to-image generation.
- 3D generative models
- Text-to-3D generation
07 方法具体是如何实现的?

Background: DreamFusion
DreamFusion引入了分数蒸馏采样(SDS),它可以计算梯度:
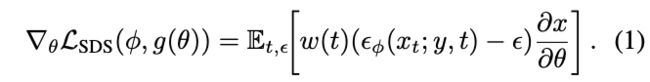
High-Resolution 3D Generation
Magic3D是一个两阶段的从粗到精的框架,使用高效的场景模型,实现高分辨率的文本到3d合成(图2)。
1)Coarse-to-fine Diffusion Priors
Magic3D以粗到细的方式使用两种不同的扩散先验来生成高分辨率的几何和纹理。在第一阶段,我们使用eDiff-I[2]中描述的基础扩散模型,它类似于DreamFusion中使用的Imagen[38]的基础扩散模型。 在第二阶段,我们使用潜在扩散模型(LDM)[36],该模型允许将梯度反向传播到高分辨率512 × 512的渲染图像中;
尽管生成了高分辨率图像,但LDM的计算是可管理的,因为扩散先验作用于分辨率为64 × 64的潜在 z t z_t zt:

2)Scene Models
Neural fields as coarse scene models.
优化的初始粗糙阶段需要从头开始寻找几何和纹理。这可能具有挑战性,因为我们需要适应3D几何结构的复杂拓扑变化和2D监控信号的深度模糊性。
由于体绘制需要沿着射线密集的样本来准确地呈现高频几何和阴影,因此必须在每个样本点评估大型神经网络的成本很快就会增加。出于这个原因,我们选择使用来自Instant NGP[27]的散列网格编码,它允许我们以更低的计算成本表示高频细节。
我们还维护了一个空间数据结构,该结构对场景占用进行编码,并利用空白空间跳变[20,45]。
具体来说,我们使用来自即时NGP[27]的基于密度的体素修剪方法,以及基于八叉树的射线采样和渲染算法[46]。通过这些设计选择,我们大大加快了粗场景模型的优化,同时保持了质量。
Textured meshes as fine scene models.
在优化的精细阶段,我们使用纹理三维网格作为场景表示。与神经领域的体渲染相比,用可微光栅化渲染纹理网格可以在非常高的分辨率下有效地执行,使网格成为我们高分辨率优化阶段的合适选择。 使用粗糙阶段的神经场作为网格几何的初始化,我们也可以避免学习网格中大量拓扑变化的困难。
我们用可变形四面体网格 ( V T , T ) (V_T,T) (VT,T)表示3D形状, 其中 V T V_T VT是网格T的顶点。
每个顶点 v i ∈ V T v_i \in V_T vi∈VT 包含了一个有符号距离域(SDF)值 s i ∈ R s_i \in R si∈R和一个顶点相对于其初始规范坐标的变形 Δ v i ∈ R 3 \Delta v_i \in R^3 Δvi∈R3。
然后,我们使用可微移动四面体算法从SDF中提取表面网格[41]。对于纹理,我们使用神经颜色场作为体积纹理表示
3)Coarse-to-fine Optimization
我们描述了我们从粗到细的优化过程,该过程首先在粗神经场表示上操作,然后在高分辨率纹理网格上操作。
Neural field optimization.
我们使用MLP来预测法线,而不是从密度差来估计法线。注意,这并不违反几何属性,因为使用了体渲染而不是表面渲染;因此,粒子在连续位置的方向不需要定向到表面级水平。这有助于我们通过避免使用有限差分来显著降低优化粗略模型的计算成本。
与DreamFusion类似,我们还使用环境贴图MLP对背景进行建模,MLP将RGB颜色预测为光线方向的函数。
我们对环境图使用了一个微小的MLP(隐藏维度大小为16),并将学习率降低了10倍,以使模型能够更多地关注神经场几何。
Mesh optimization 为了从神经场初始化中优化网格,我们通过减去一个非零常数将(粗略)密度场转换为SDF,从而产生初始 s i s_i si。
为了提高曲面的平滑度,我们进一步正则化了网格上相邻面之间的角度差。这使我们即使在具有高方差的监督信号(如SDS梯度)下也能获得良好的几何形状。
08 实验结果和对比效果如何?
Speed evaluation
非另有说明,否则粗级被训练用于5000次迭代,沿着射线有1024个样本(随后由稀疏八叉树过滤),批量大小为32,总运行时间约为15分钟(超过8次迭代/秒,由于稀疏性的差异而变化)。精细阶段使用一个批次大小为32训练3000次迭代,总运行时间为25分钟(2次迭代/秒)。两个运行时间加起来都是40分钟。所有运行时间都是在8个NVIDIA A100 GPU上测量的。
Qualitative comparisons.
User studies.

Personalized text-to-3D.
我们能够成功地修改在给定输入图像中保留被摄体的3D模型。

Prompt-based editing through fine-tuning.
我们修改了基本提示,以高分辨率微调NeRF模型,并优化了网格。结果表明,我们可以根据提示调整场景模型,例如,将“小兔子”更改为“彩色玻璃兔子”或“金属兔子”会产生类似的几何结构,但具有不同的纹理
09 消融研究告诉了我们什么?
Can single-stage optimization work with LDM prior?

Can we use NeRF for the fine model?
对虽然从头开始优化NeRF效果不佳,但我们可以遵循从粗到细的框架,但用NeRF代替第二阶段场景模型。
Coarse models vs. fine models.
我们在NeRF和网格模型上都看到了显著的质量改进,这表明我们的粗到细方法适用于一般场景模型。

10 结论
我们提出Magic3D,一个快速和高质量的文本到3d生成框架。我们在coarse-to-fine方法中受益于高效的场景模型和高分辨率的扩散先验。特别是,三维网格模型可以很好地随图像分辨率缩放,并且可以在不牺牲速度的情况下享受潜在扩散模型带来的更高分辨率监督的好处。从文本提示到准备在图形引擎中使用的高质量3D网格模型需要40分钟。通过广泛的用户研究和定性比较,我们发现与DreamFusion相比,Magic3D更受评分者的青睐(61.7%),同时速度提高了2倍。最后,我们提出了一套工具来更好地控制3D生成的样式和内容。我们希望通过Magic3D实现大众化的3D合成,开启大家在3D内容创作中的创造力。
原文链接:Magic3D: 高分辨率文本到3d内容创建(by 小样本视觉与智能前沿)