【实验练习】基于自注意力机制Vision Transformer模型实现人脸朝向识别 (Python实现) 内容原创
题目
人脸识别是一个复杂的模式识别问题,人脸识别是人脸应用研究中非常重要的一步。由于人脸形状不规则、光线和背景条件多样,导致人脸检测精度受限。实际应用中,大量图像和视频源中人脸的位置、朝向、朝向角度都不是固定的,极大化的增加了人脸识别的难度。目前研究中,大多数研究是希望人脸识别过程中去除人脸水平旋转对识别过程的不良影响。但实际应用时往往比较复杂。
现给出采集到的一组人脸朝向不同角度时的图片,详见Image文件夹。图像来自不同的10个人,每人5个图像,人脸朝向分别为:向左、左前方、前方、右前方和向右。请选择本课程学习的任意一种算法进行训练,能够对任意给出的人脸图像进行朝向预测和识别。
# -*- coding: utf-8 -*- #
"""
@Project :Exp
@File :FaceVitRun.py
@Author :ZAY
@Time :2023/5/30 15:44
@Annotation : " "
"""
import os
import glob
import torch
import torch.nn as nn
import datetime
import numpy as np
from timm.models.layers import to_2tuple
from torchvision import transforms
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
from Exp.Plot import plotloss,plotShow,plotROC
from Net.VitNet import ViT
from DataLoad import Mydataset, Mydatasetpro
from EarlyStop import EarlyStopping
from sklearn import metrics
from sklearn.preprocessing import label_binarize
from sklearn.metrics import accuracy_score,auc,roc_curve,precision_recall_curve,f1_score, precision_score, recall_score
from matplotlib import pyplot as plt
LR = 0.0001 # 0.0001
EPOCH = 100
BATCH_SIZE = 10
Test_Batch_Size = 6
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def judgeType(y_predicted):
if y_predicted == 0:
pre = "left"
elif y_predicted == 1:
pre = "lf"
elif y_predicted == 2:
pre = "front"
elif y_predicted == 3:
pre = "rf"
else:
pre = "right"
return pre
class ConfusionMatrix(object):
def __init__(self, num_classes: int, labels: list):
self.matrix = np.zeros((num_classes, num_classes)) # 初始化混淆矩阵,元素都为0
self.num_classes = num_classes # 类别数量,本例数据集类别为5
self.labels = labels # 类别标签
def update(self, preds, labels):
for p, t in zip(preds, labels): # pred为预测结果,labels为真实标签
self.matrix[p, t] += 1 # 根据预测结果和真实标签的值统计数量,在混淆矩阵相应位置+1
def summary(self): # 计算指标函数
# calculate accuracy
sum_TP = 0
n = np.sum(self.matrix)
for i in range(self.num_classes):
sum_TP += self.matrix[i, i] # 混淆矩阵对角线的元素之和,也就是分类正确的数量
acc = sum_TP / n # 总体准确率
print("the model accuracy is ", acc)
# kappa
sum_po = 0
sum_pe = 0
for i in range(len(self.matrix[0])):
sum_po += self.matrix[i][i]
row = np.sum(self.matrix[i, :])
col = np.sum(self.matrix[:, i])
sum_pe += row * col
po = sum_po / n
pe = sum_pe / (n * n)
# print(po, pe)
kappa = round((po - pe) / (1 - pe), 3)
# print("the model kappa is ", kappa)
return str(acc)
def plot(self): # 绘制混淆矩阵
matrix = self.matrix
print("matrix: ",matrix)
plt.imshow(matrix, cmap=plt.cm.Blues)
# 设置x轴坐标label
plt.xticks(range(self.num_classes), self.labels, rotation=45)
# 设置y轴坐标label
plt.yticks(range(self.num_classes), self.labels)
# 显示colorbar
plt.colorbar()
plt.xlabel('True Labels')
plt.ylabel('Predicted Labels')
plt.title('Confusion matrix (acc=' + self.summary() + ')')
# 在图中标注数量/概率信息
thresh = matrix.max() / 2
for x in range(self.num_classes):
for y in range(self.num_classes):
# 注意这里的matrix[y, x]不是matrix[x, y]
info = int(matrix[y, x])
plt.text(x, y, info,
verticalalignment='center',
horizontalalignment='center',
color="white" if info > thresh else "black")
plt.tight_layout()
plt.savefig(".//Result//matrix.png")
plt.show()
if __name__ == "__main__":
global id_to_species
store_path = './/model//transformer.pt'
txt_path = './/Result//Vit.txt'
# 使用glob方法来获取数据图片的所有路径
all_imgs_path = glob.glob(r"./Data/*/*.bmp") # 数据文件夹路径
# for var in all_imgs_path:
# print(var)
# 利用自定义类Mydataset创建对象face_dataset
face_dataset = Mydataset(all_imgs_path)
print("文件夹中图片总个数:",len(face_dataset)) # 返回文件夹中图片总个数
# face_dataloader = torch.utils.data.DataLoader(face_dataset, batch_size = 8) # 每次迭代时返回8个数据
# 为每张图片制作对应标签
species = ['left', 'lf', 'front', 'rf', 'right']
species_to_id = dict((c, i) for i, c in enumerate(species))
id_to_species = dict((v, k) for k, v in species_to_id.items())
print("id_to_species",id_to_species)
# 对所有图片路径进行迭代
all_labels = []
for img in all_imgs_path:
# 区分出每个img,应该属于什么类别
for i, c in enumerate(species):
if c in img:
all_labels.append(i)
print("all_labels",all_labels)
# 对数据进行转换处理
transform = transforms.Compose([
transforms.Resize((420, 420)), # 做的第一步转换
transforms.ToTensor() # 第二步转换,作用:第一转换成Tensor,第二将图片取值范围转换成0-1之间,第三会将channel置前
])
face_dataset = Mydatasetpro(all_imgs_path, all_labels, transform)
face_dataloader = DataLoader(
face_dataset,
batch_size = BATCH_SIZE,
shuffle = True
)
imgs_batch, labels_batch = next(iter(face_dataloader))
print("imgs_batch.shape",imgs_batch.shape) # torch.Size([4, 3, 420, 420])
# plt.figure(figsize = (12, 8))
# for i, (img, label) in enumerate(zip(imgs_batch[:6], labels_batch[:6])):
# img = img.permute(1, 2, 0).numpy() # (H,W,C)
# plt.subplot(2, 3, i + 1) # subplot(numRows, numCols, plotNum) numRows 行 numCols 列
# plt.title(id_to_species.get(label.item()))
# plt.imshow(img)
# plt.show() # 展示图片
# 划分数据集和测试集
index = np.random.permutation(len(all_imgs_path))
print("index",index)
# 打乱顺序
all_imgs_path = np.array(all_imgs_path)[index]
all_labels = np.array(all_labels)[index]
for i in range(len(all_imgs_path)):
print("第{}张图片存储路径为:{}, 朝向为:{}, 标签为:{}".format(i + 1, all_imgs_path[i],judgeType(all_labels[i]),all_labels[i]))
# 80%做训练集
# c = int(len(all_imgs_path) * 0.8)
# print("训练集和验证集数量:", c)
c = 40
v = 4
t = 6
c_imgs = all_imgs_path[:c]
c_labels = all_labels[:c]
v_imgs = all_imgs_path[c:c+v]
v_labels = all_labels[c:c+v]
t_imgs = all_imgs_path[c+v:]
t_labels = all_labels[c+v:]
test_face_dataset = Mydatasetpro(t_imgs, t_labels, transform)
global test_face_dataloader
test_face_dataloader = DataLoader(
test_face_dataset,
batch_size = t,
shuffle = False # 在每个epoch开始的时候是否进行数据的重新排序,默认false
)
# train_imgs = all_imgs_path[:c]
# train_labels = all_labels[:c]
# test_imgs = all_imgs_path[c:]
# test_labels = all_labels[c:]
# print(test_imgs)
# print(test_imgs.shape)
# print(test_labels)
# print(test_labels.shape)
cal_ds = Mydatasetpro(c_imgs, c_labels, transform) # TrainSet TensorData
val_ds = Mydatasetpro(v_imgs, v_labels, transform) # TestSet TensorData
test_ds = Mydatasetpro(t_imgs, t_labels, transform)
# print(next(iter(face_dataloader)))
# 改进 psize 30-60 减少必要的epoch heads 12-6 减少参数和必要的epoch
modeltrian(image_size = 420, ncls=5, psize=60, depth=3, heads=12, dim = 2048, mlp_dim=1024, path=store_path, data_train = cal_ds, data_test = val_ds) # depth=6, heads=10, 12, 14
# modeltest(image_size = 420, ncls = 5, psize = 60, depth=3, heads=6, dim = 2048, mlp_dim=1024, path=store_path, data_test = test_ds, txt_path = txt_path)
acc, precis, reca, F1, roc_auc = model4AUCtest(image_size = 420, ncls=5, psize=60, depth=3, heads=12, dim = 2048, mlp_dim=1024, path=store_path, data_test = test_ds, txt_path = txt_path) # depth=6, heads=10, 12, 14
# print("acc:{}, precis:{}, recall:{}, F1:{}, auc:{}".format(acc, precis, reca, F1, roc_auc))
测试结果
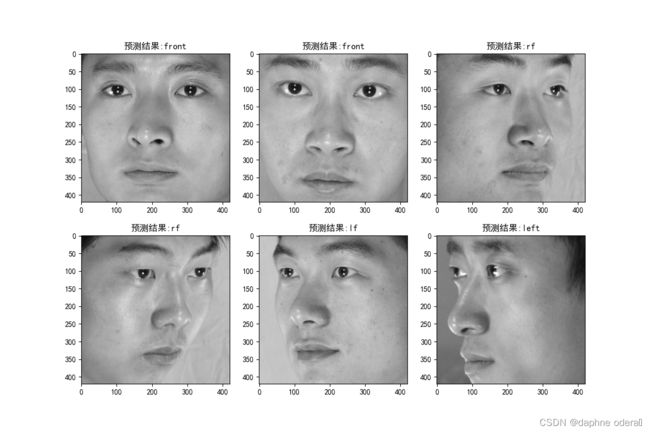
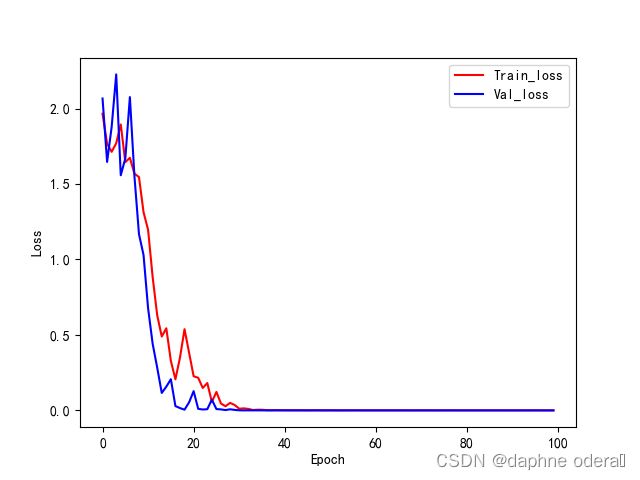
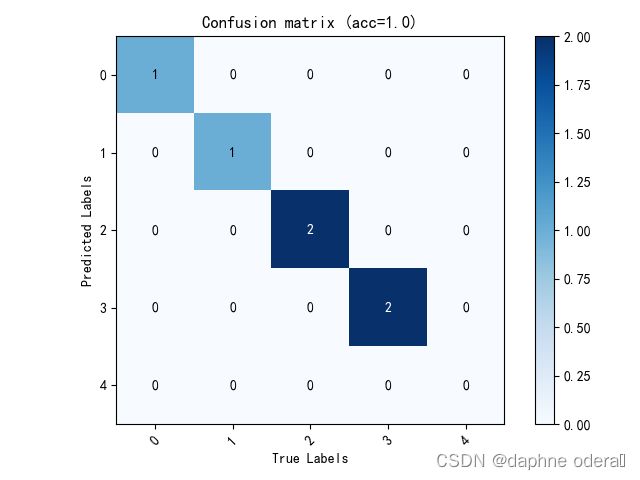
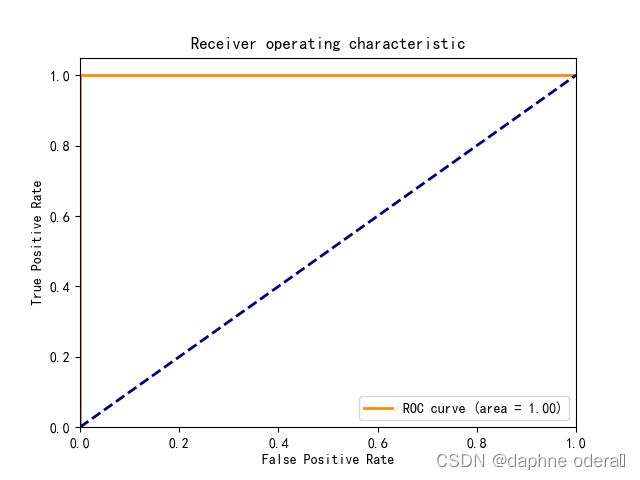
第1张图片朝向为:front, 第1张图片预测为:front 第2张图片朝向为:front, 第2张图片预测为:front 第3张图片朝向为:rf, 第3张图片预测为:rf 第4张图片朝向为:rf, 第4张图片预测为:rf 第5张图片朝向为:lf, 第5张图片预测为:lf 第6张图片朝向为:left, 第6张图片预测为:left acc:1.0, precis:1.0, recall:1.0, F1:1.0, auc:1.0 DATE:_2023-06-04_13-23-15, TEST:Avg_acc= 1.0000, train_time = 0:00:54.309789, test_time = 0:00:00.274266 当前模型参数量: 38.990857 M