pandas金融数据处理
51.使用绝对路径读取本地Excel数据
import numpy as np
import pandas as pd
data = pd.read_excel('/Users/baji/Desktop/600000.SH.xls')
52.查看数据前三行
data.head(3)
53.查看每列数据缺失值情况
data.isnull().sum()

54.提取日期列含有空值的行
data[data['日期'].isnull()]

55.输出每列缺失值具体行数
for columname in data.columns:
if data[columname].count() != len(data):
loc = data[columname][data[columname].isnull().values==True].index.tolist()
print('列名:"{}",第{}行位置有缺失值'.format(columname,loc))

56.删除所有存在缺失值的行
data.dropna(axis=0,how='any',inplace=True)
how:any-有空值就删除,all-全部为空值才删除
inplace:false-返回新数据集,True-源数据集操作
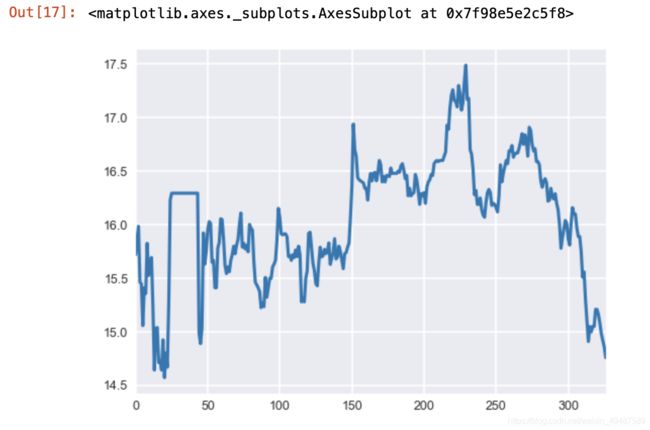
57.绘制收盘价的折线图
import matplotlib.pyplot as plt
#plt.plot(data['收盘价(元)'])
plt.style.use('seaborn-darkgrid') #设置画图风格
plt.rc('font',size=6) #设置图中字体和大小
plt.rc('figure',figsize=(4,3),dpi=150) #设置图像大小
data['收盘价(元)'].plot()
plt.style.use()
参数可以是一个URL或路径,指向自己定义的mplstyle文件,找到使用样式可用plt.style.available
共26种风格:['bmh', 'classic', 'dark_background', 'fast', 'fivethirtyeight', 'ggplot', 'grayscale', 'seaborn-bright', 'seaborn-colorblind', 'seaborn-dark-palette', 'seaborn-dark', 'seaborn-darkgrid', 'seaborn-deep', 'seaborn-muted', 'seaborn-notebook', 'seaborn-paper', 'seaborn-pastel', 'seaborn-poster', 'seaborn-talk', 'seaborn-ticks', 'seaborn-white', 'seaborn-whitegrid', 'seaborn', 'Solarize_Light2', 'tableau-colorblind10', '_classic_test']
plt.rc
matplotlib中plt.rcParams[],设置图像细节
目前学习到2种写法,一是plt.rcParams['figure.figsize']=(4,3),plt.rcParams['lines.linestyle']='-.';二是plt.rc('font',size=6),plt.rc('figure',figsize=(4,3),dpi=150)
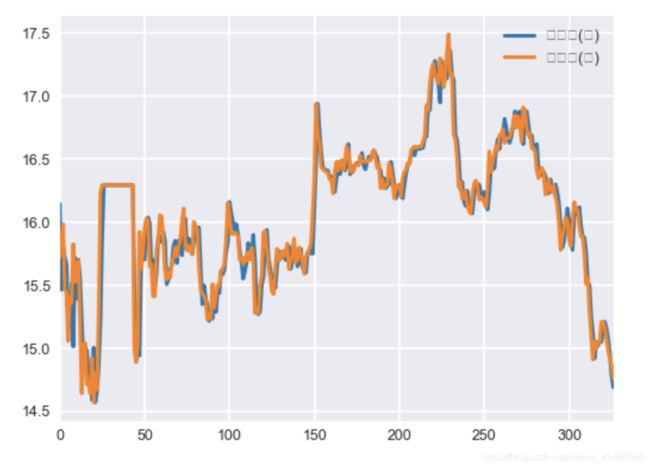
58.同时绘制开盘价与收盘价
#plt.plot(data[['开盘价(元)','收盘价(元)']])
data[['开盘价(元)','收盘价(元)']].plot()
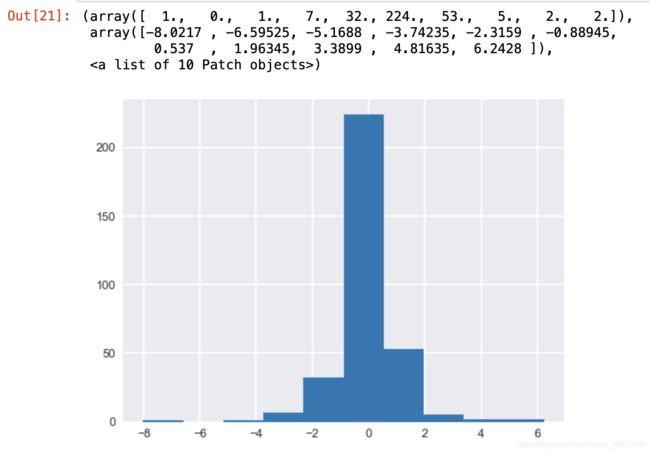
59.绘制涨跌幅的直方图
#data['涨跌幅(%)'].hist()
plt.hist(data['涨跌幅(%)'])
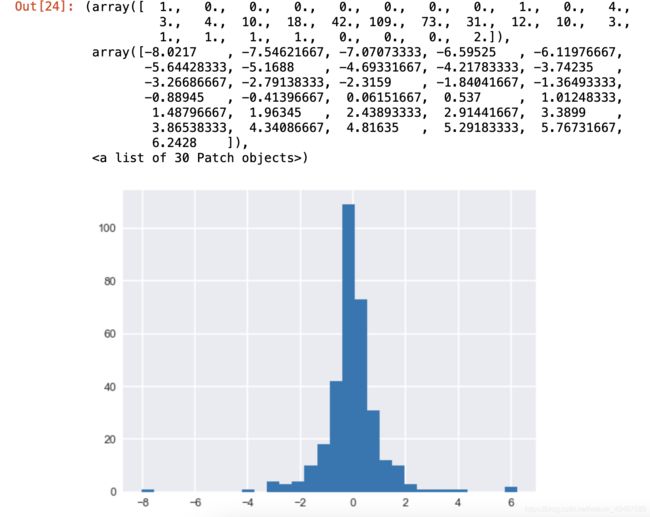
60.让直方图更细致
plt.hist(data['涨跌幅(%)'],bins=30)
#data['涨跌幅(%)'].hist(bins=30)
题目中的更细致理解为 加组距
61.以data的列名创建一个dataframe
#错误写法
# df1 = pd.DataFrame(np.array(data.columns))
df2 = pd.DataFrame(columns=data.columns.tolist())
df2
![]()
62.打印所有换手率不是数字的行
for i in range(len(data)):
if type(data.iloc[i,13]) != float:
df2 = df2.append(data.loc[i])
df2

63.打印所有换手率为–的行
data[data['换手率(%)'].isin(['--'])]
DataFrame.isin(values) 用于过滤数据帧
values:iterable,Series,List,Tuple,DataFrame或字典
return:维度布尔值的DataFrame
单参数过滤:
temp1 = data['换手率(%)'].isin(['--'])
多重参数过滤:
filter1 = data['换手率(%)'].isin(['--']),filter2 = data['前收盘价(元)].isin([12.1946,12.2946,12.3946])

64.重置data的行号
data = data.reset_index()
65.删除所有换手率为非数字的行
k=[] #设置空列表接收
for i in range(len(data)):
if type(data.iloc[i,14]) != float:
k.append(i)
data.drop(labels=k,inplace=True)
# 正确写法
data[data['换手率(%)'].isin(['--'])]
![]()
#错误写法
data['换手率(%)'].isin(['--']) 会出现维度布尔值的DataFrame

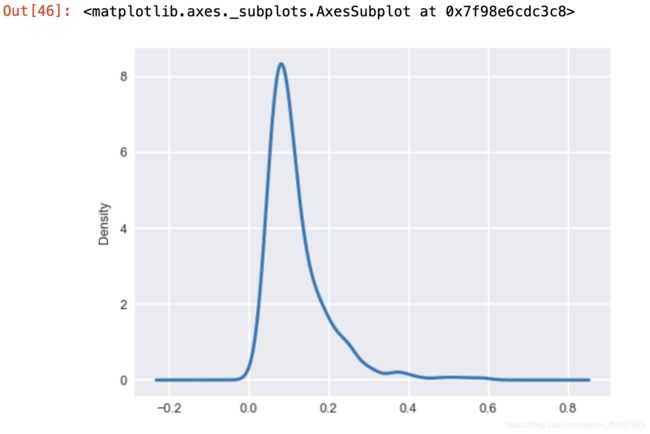
66.绘制换手率的密度曲线
data['换手率(%)'].plot(kind='kde') #kde = 密度
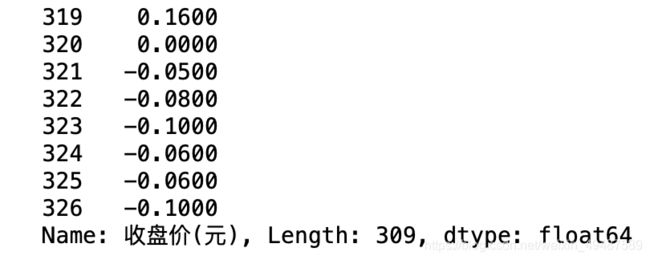
67.计算前一天与后一天收盘价的差值
data['收盘价(元)'].diff() #一阶差分
DataFrame.diff(periods=1,axis=0)
操作中是两条临近记录的差值,periods表示对比的条目数,axis表示行或列
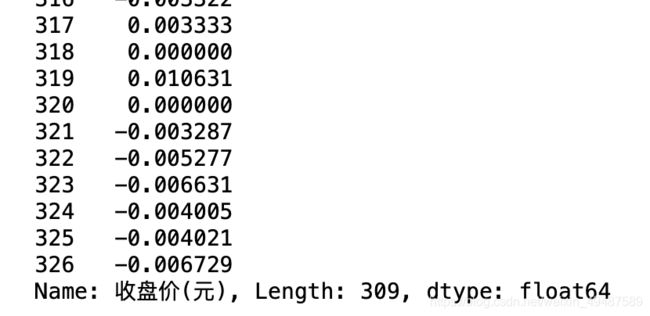
68.计算前一天与后一天收盘价变化率
data['收盘价(元)'].pct_change() #相差百分比
DataFrame.pct_change(periods=1, fill_method=‘pad’, limit=None, freq=None, **kwargs)
periods表示对比的条目数,默认为1
当前数据与先前数据的相差百分比
69.设置日期为索引
data.set_index('日期')
70.以5个数据作为一个数据滑动窗口,在这个5个数据上取均值(收盘价)
data['收盘价(元)'].rolling(5).mean()
窗口函数
DataFrame.rolling(window,min_periods=None,center=False,win_type=None,on=None,axis=0,closed=None)
window:时间窗口值,int类型,即向前几个数据
min_periods:默认与window相等,即最少窗口值的观测点数量
center:窗口标签居中,默认False
win_type:窗口类型,默认为None
on:指定计算数据滑动窗口的列,可选参数
closed:定义区间的开闭(‘left’,‘both’,‘right’),对于offset类型默认是左开右闭的即默认为right
与agg()函数快速实现多个聚类函数并输出结果,同时还可以进行重命名
method
dataframe.rolling().mean() 均值
dataframe.rolling().sum() 求和
dataframe.rolling().var() 无偏方差
dataframe.rolling().std() 标准差
dataframe.rolling().corr() 相关(二进制)
dataframe.rolling().cov() 无偏协方差(二元)
dataframe.rolling().skew() 样品偏斜度(三阶矩)
dataframe.rolling().kurt() 样品峰度(四阶炬)
dataframe.rolling().count() 非空值数量
dataframe.rolling().max() 最大值
dataframe.rolling().min() 最小值
dataframe.rolling().median() 中值
dataframe.rolling().quantile() 样本分位数(百分位上的值)
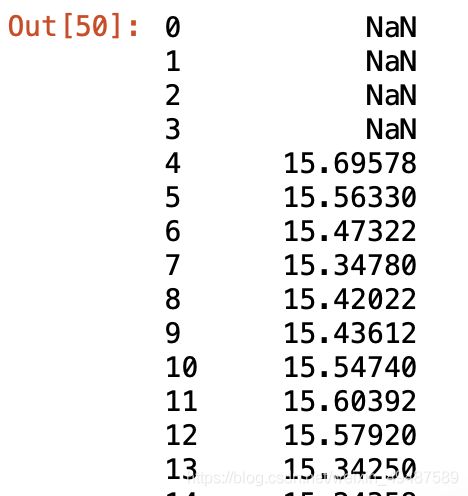
71.以5个数据作为一个数据滑动窗口,计算这五个数据总和(收盘价)
data['收盘价(元)'].rolling(5).sum()

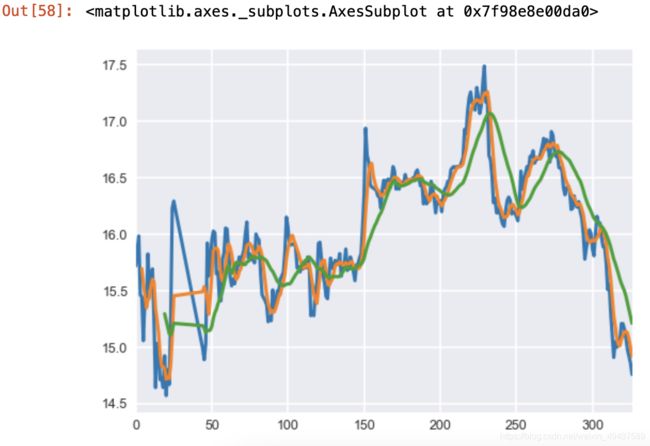
72.将收盘价5日均线、20日均线与原始数据绘制在同一个图上
#False
#data['收盘价(元)'].plot()
#data[data['收盘价(元)'].rolling(5).mean()].plot()
#data[data['收盘价(元)'].rolling(20).mean()].plot()
#True
data['收盘价(元)'].plot()
data['收盘价(元)'].rolling(5).mean().plot()
data['收盘价(元)'].rolling(20).mean().plot()
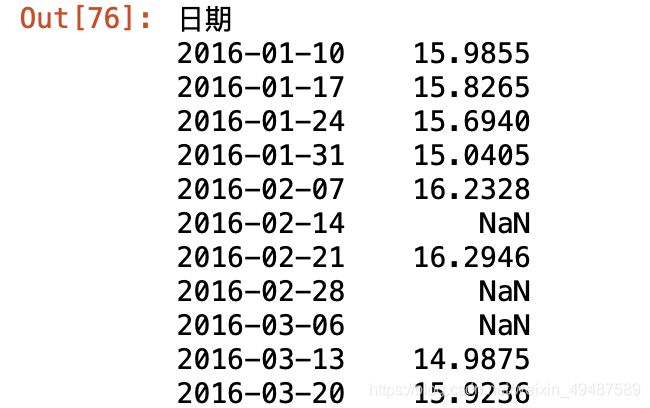
73.按周为采样规则,取一周收盘价最大值
data['收盘价(元)'].resample('W').max()
# data['收盘价(元)'].resample('7d').max()
※ 本题一直报错:TypeError: Only valid with DatetimeIndex, TimedeltaIndex or PeriodIndex, but got an instance of 'Int64Index'
多次尝试后发现由于之前data.set_index('日期')没有覆盖,再次将日期作为索引后,问题解决
74.绘制重采样数据与原始数据
data['收盘价(元)'].plot()
data['收盘价(元)'].resample('7D').max().plot()

75.将数据往后移动5天
data.shift(5)
DataFrame.shift(periods=1, freq=None, axis=0)
periods:它由一个可以为正或为负的整数组成。它定义了要移动的数
freq:可以与DateOffset, tseries模块, str或time规则一起使用
fill_value:用于填充新丢失的值
76.将数据向前移动5天
data.shift(-5)
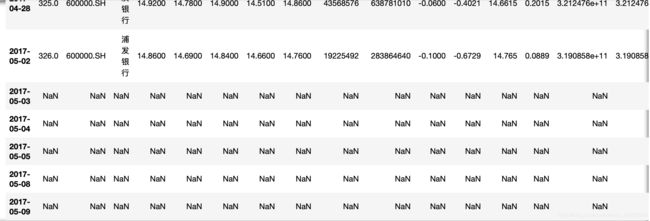
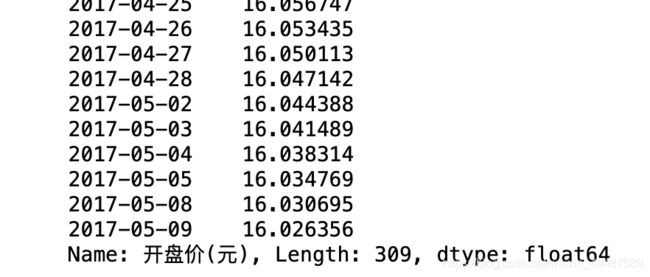
77.使用expending函数计算开盘价的移动窗口均值
data['开盘价(元)'].expanding(min_periods=1).mean()
DataFrame.expanding(min_periods = 1,center = False,axis = 0)
min_periods:需要有值的观测点的最小数量,决定显示状态,=1表示每个观测点都有值
center:把窗口的标签设置为居中,default False–>居右
expanding()与rolling()的参数用法相同,rolling()固定窗口数量,进行滑动计算;expanding()设置最小观测值,不固定窗口数量,实现累计计算
expanding()函数,类似cumsum()函数的累计求和,其优势在于还可以进行更多的聚类计算;
事实上,当rolling()函数的参数window=len(df)时,实现的效果与expanding()函数是一样的。
78.绘制上一题的移动均值与原始数据折线图
data['opening'] = data['开盘价(元)'].expanding(min_periods=1).mean()
data[['开盘价(元)','opening']].plot(figsize=(16,6))

79.计算布林指标
以下信息来源百度百科
布林线指标,即BOLL指标,其英文全称是“Bollinger Bands”,布林线(BOLL)由约翰·布林先生创造,其利用统计原理,求出股价的标准差及其信赖区间,从而确定股价的波动范围及未来走势,利用波带显示股价的安全高低价位,因而也被称为布林带。其上下限范围不固定,随股价的滚动而变化。布林指标和麦克指标MIKE一样同属路径指标,股价波动在上限和下限的区间之内,这条带状区的宽窄,随着股价波动幅度的大小而变化,股价涨跌幅度加大时,带状区变宽,涨跌幅度狭小盘整时,带状区则变窄。
——————————————————————————————————————————————————————————————
在股市分析软件中,BOLL指标一共由四条线组成,即上轨线UP 、中轨线MB、下轨线DN和价格线。
计算公式
中轨线MB=N日的移动平均线
上轨线UP=中轨线+两倍的标准差
下轨线DN=中轨线-两倍的标准差
计算过程
(1)计算MA
MA=N日内的收盘价之和÷N
(2)计算标准差MD
MD=平方根(N-1)日的(C-MA)的两次方之和除以N
(C指收盘价)
(3)计算MB、UP、DN线
MB=(N-1)日的MA
UP=MB+k×MD
DN=MB-k×MD
(K为参数,可根据股票的特性来做相应的调整,一般默认为2)
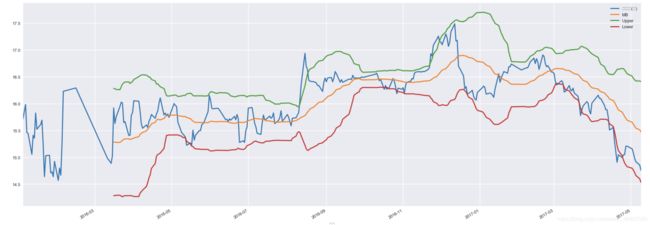
data['MB'] = data['收盘价(元)'].rolling(30).mean()
data['Upper'] = data['MB']+2*data['收盘价(元)'].rolling(30).std()
data['Lower'] = data['MB']-2*data['收盘价(元)'].rolling(30).std()
80.计算布林线并绘制
data[['收盘价(元)','MB','Upper','Lower']].plot(figsize=(16,6))