数据库:Redis数据库高可用
目录
一、Redis数据库持久化
1、redis高可用类型
2、redis实现持久化方式及优缺点
3、RDB持久化触发方式与原理
①RDB持久化原理
②手动触发
③自动触发
4、AOF持久化原理与触发方式
①AOF持久化与重写原理
②AOF文件写入与重写
③手动触发
④自动触发
5、启动时加载顺序
二、Redis数据库集群
1、集群模式
2、主从复制
①主从复制定义与作用
②主从复制原理
3、部署主从复制
①实验环境
②安装redis
③主节点配置
④2个从节点配置
⑤验证主从复制
一、Redis数据库持久化
1、redis高可用类型
高可用定义:范围宽泛,除保证提供正常服务,还要考虑数据容量的扩展,数据安全不安全是否会丢失等。
①持久化:最简单的高可用方法,主要是数据备份即将reids的内容存储到硬盘中保证数据不会因为进程退出丢失。
2、redis实现持久化方式及优缺点
①RDB持久化方式:redis每隔一段时间将记录保存到硬盘上,类似于快照,定期保存。
②AOF持久化方式:将redis的操作日志以追加的方式写入文件,类似于mysql的增量备份,需要完整备份和增量备份配合使用
优缺点:RDB持久化保存数据慢、实时性较差但是恢复比较快,缺点是若进程退出可能会丢失数据。
AOF持久化保存数据快、实时性较好但是恢复比较慢,进程退出不会造成数据丢失,即使丢失最后很少一部分。现在市场大部分用的是AOF持久化方式
3、RDB持久化触发方式与原理
①RDB持久化原理
无论是自动触发还是手动触发的save还是bgsave,RDB持久化都会生成一个RDB文件此文件生成保存在磁盘中实现了持久化。
②手动触发
save命令:save命令执行生成rdp文件时会阻塞整个服务器,整个服务器不能接收其他客户端的任何响应。
bgsave命令:bgsave命令执行时会fork一个子进程用来生成rdp文件,除了在fork子进程时不能接收其他客户端响应,其他时间都可以接收其他客户响应。
③自动触发
vim /etc/redis/6379.conf
#编辑reids主配置文件
save 900 1
save 300 10
save 60 10000
#找到此save三行,第一行表示900秒之内若有一次操作则进行持久化保存,
#第二行表示300秒之内若有19次操作则进行持久化保存,
#第三行表示60秒内若有10000次操作则进行持久化保存。
#三个条件只有有其中一个符合即可自动触发持久化保存。save 时间 次数 时间和次数可以根据需要修改。
#生成的RDB文件若安装时未指定路径则在/var/lib/redis/6379此文件夹下4、AOF持久化原理与触发方式
①AOF持久化与重写原理
AOF持久化将操作日志的增删改记录到缓存中,缓存记录命令追加到AOF文件中保存在硬盘上。
命令追加(append):将Redis的写命令加到缓冲器aof_buf,不直接写入文件,为了避免每次写命令都写入硬盘,导致磁盘I/O陈伟reidis负载的瓶颈

②AOF文件写入与重写
文件写入(write):缓存区被填满或到达指定时限后才真正将数据写入磁盘。有安全问题,停机会导致缓存区数据丢失,所以系统提供sync、fdatasync等函数强制操作系统立即将缓存区数据写入磁盘。三种写入方式
1、always 一直触发AOF的持久化,执行一条触发一次(有强一致性要求的场景使用)
2、everysec 每秒触发一次持久化,1秒执行一次不论1秒内执行了多少次命令(负载型场景,默认使用的)
3、no 不进行持久化
文件重写(rewrite):定期重写AOF文件,达到压缩的目的。如(set ky26 1,set ky26 2)删除无效数据,如重新定义了键的内容,或者删除的内容。压缩(多条命今可以合并为一个:如sadd myset vl,sadd myset v2,sadd myset v3可以合并为sadd myset vl v2 V3。) 只是这样保存但是时间还是原来的样子。
③手动触发
bgrewriteaof命令
④自动触发
设置auto-aof-rewrite-min-size 64m:当前AOF直接执行重写AOF的最小值,避免刚启动reids由于文件较小导致频繁重写AOF
设置auto-aof-rewrite-percentage 100 :当AOF文件大小是上次日志重写AOF大小的俩倍时触发AOF来自动执行BGREWRITEAOF。 只有当两个选项同时满足时,才会自动触发AOF重写,即bgrewriteaof操作。
5、启动时加载顺序
redis启动时会有限加载AOF文件来恢复数据,若AOF未开启才会加载RDB文件,AOF开启无AOF文件也不会加载RDB,若AOF文件尾部不完整报错则需要借助aof-load-truncated参数忽略错误,此参数默认是开启的
二、Redis数据库集群
1、集群模式
主从复制:高可用基础,哨兵和集群都是在主从复制基础上实现,主要实现数据的多机备份,对读操作的负载均衡和简单的故障恢复。
缺陷:故障恢复无法自动化需要手动切换,写操作无法负载均衡,存储能力受单机限制
哨兵模式::主从复制基础上,哨兵实现自动化的故障恢复,
缺陷:写操作无法负载均衡,存储能力受到单机的限制,无法对从节点进行自动化故障转移,需要对从节点做额外的监控切换操作。
Cluster集群:解决redis写操作无法负载均衡的方式以及存储能力受单机限制的问题,实现了较为完善的高可用方式
2、主从复制
①主从复制定义与作用
主从复制:将一台reids的数据复制到多开redis上被复制的redis为主节点,复制的reids为从节点,只能从主节点复制到从节点
主从复制作用:
数据冗余:实现了数据的热备,持久化之外的一种数据冗余方式
负载均衡:实现redis的读写分离,主节点复制写从节点负责读
故障恢复:主节点出现故障可以手动切换到备节点处理业务
高可用基石:哨兵模式和cluster集群都需要依赖主从复制实现
②主从复制原理
第一步:从节点向主节点发送 sync commed请求同步数据
第二步:主节点收到请求即开启一个后台进程(无论是第一次连接还是重复连接),执行数据快照操作即RDB持久化操作生成RDB文件传输给从节点,从节点将RDB文件保存在磁盘中然后读入到内存中
第三步:主节点将在生成RDB文件过程中的其他所有操作通过增量备份方式即AOF持久化方式生成AOF文件传输给从节点,若中途从节点宕机,恢复正常后会自动进行连接。
第四步:从节点可以是多个,主节点会数据文件发送给多个从节点保证所有从节点机器正常。
3、部署主从复制
①实验环境
主节点:192.168.30.11
从节点1:192.168.30.13
从节点2:192.168.30.14
②安装redis
请查看上一章节“部署Redis数据库过程”将三台服务器reids部署完成

③主节点配置
主节点:
vim /etc/redis/6379.conf
#修改内容:
bind 0.0.0.0
#修改监听主机位任意地址0.0.0.0
appendonly yes
#找到appendonly 开启AOF持久化
/etc/init.d/redis_6379 restart
#重启redis
④2个从节点配置
2个从节点:
vim /etc/redis/6379.conf
#修改内容:
bind 0.0.0.0
#修改监听主机位任意地址0.0.0.0
appendonly yes
#找到appendonly 开启AOF持久化
replication 192.168.30.11 6379
#添加主节点ip地址与端口号
/etc/init.d/redis_6379 restart
#重启reids配置生效⑤验证主从复制
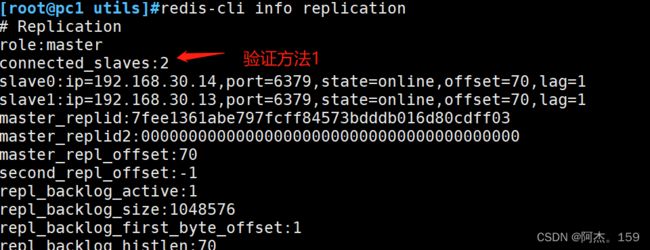
验证方法1:
主节点
redis-cli info replication
#查看下面的connected_slaves:是否为2下面的slaveip是否为2个从节点的ip
验证方法2:
主节点
tail -f -n 20 /var/log/redis_6379.log
#查看主节点日志中是否有2个从节点ip成功的信息