Linux 下Coredump分析与配置
在Linux下开发中,我们经常听到程序员说我的程序core掉了,通常出现这类的问题是低级bug中的内存访问越界、使用空指针、堆栈溢出等情况。使程序运行过程中异常退出或者终止,满足这些条件就会产生core的文件。
为什么会发生Coredump
Core就是内存的意思,这个词源自很早以前制造内存的材料,一直延用到现在,当程序运行过程中检测到异常程序异常退出时, 系统把程序当前的内存状况存储在一个core文件中, 叫core dumped,也就信息转储,操作系统检测到当前进程异常时将通过信号的方式通知目标进程相应的错误信息,常见的信号有SIGSEGV,SIGBUS等,默认情况下进程接收到相应的信号都有相应的处理机制。
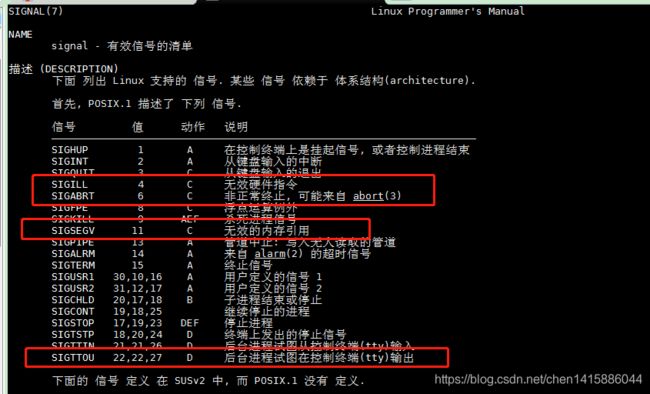
以Linux为例,Action则对应信号的处理方式,红色框标注为常见信号
在此之前最好先了解下进程的内存布局, Unix与Linux系统的进程空间布局会稍微有点不同,内核空间会比Linux小,特别是内核与用户进程采用分离的地址空间模式,这里以Linux为例:

coredump文件的存储位置
我们知道在Linux系统中,如果进程崩溃了,系统内核会捕获到进程崩溃信息,然后将进程的coredump 信息写入到文件中,这个文件名默认是core 。存储位置与对应的可执行程序在同一目录下,文件名是core,大家可以通过下面的命令看到core文件的存在位置:
 Core_pattern的格式:
Core_pattern的格式:
%p 转储过程的PID
%u (数字)转储进程的实际UID
%G (数字)转储过程的实际GID
%s 引起转储的信号数
%t 转储时间,表示为自1970年1月1日00:00:00 +0000(UTC)以来的秒数
%H 主机名(与uname(2)返回的节点名相同)
%e 可执行文件名(无路径前缀)
%E 可执行文件的路径名,用斜杠(’/’)替换为感叹号(’!’)。
%C 崩溃过程的核心文件大小软资源限制(自Linux 2.6.24开始)
了解更多可以参考https://linux.die.net/man/5/core
下面的程序可用于演示/ proc / sys / kernel / core_pattern文件中管道语法的用法。
#include 注意一下: 这里是指在进程当前工作目录的下创建。通常与程序在相同的路径下。但如果程序中调用了chdir函数,则有可能改变了当前工作目录。这时core文件创建在chdir指定的路径下。有好多程序崩溃了,我们却找不到core文件放在什么位置。和chdir函数就有关系。当然程序崩溃了不一定都产生 core文件。
下面通过的命令可以更改coredump文件的存储位置,如下:
echo “|$PWD/core_pattern_pipe_test %p UID=%u GID=%g sig=%s” >
/proc/sys/kernel/core_pattern
cat /proc/sys/kernel/core_pattern 查看路径已经变为如下:

下面带大家配置永久的core。只要出现内存访问越界、使用空指针、堆栈溢出等情况,都可以在这个目录下查看。
配置 core
1、首先在根目录下建立一个储存coredump文件的文件夹,命令如下:
mkdir /corefile
2、设置产生coredump文件的大小,命令如下:
ulimit -c unlimited
3、 执行以下两条命令:
echo “1” > /proc/sys/kernel/core_uses_pid //将1写入到该文件里
echo “/corefile/core-%e-%p-%t” > /proc/sys/kernel/core_pattern
将coredump产生的格式制定好写入core_pattern文件,这样当coredump产生时会直接以这种格式存入到根目录下的文件夹corefile中。
4、修改配置文件/etc/profile
vim /etc/profile
添加 ulimit -S -c unlimited > /dev/null 2>&1

执行命令生效该文件

5、 在配置文件/etc/rc.local中最后面添加信息(机器重启时会自动加载该命令):添加命令:
rm -rf /corefile/*
机器重启时清空该文件夹,由于产生的coredump文件很大,若不清空的话时间长了会将硬盘占满;
再执行以下两条命令:
echo “1” > /proc/sys/kernel/core_uses_pid
echo “/corefile/core-%e-%p-%t” > /proc/sys/kernel/core_pattern
测试
下面写个例子测试一下是否配置好了corefile文件
#include 编译运行,注意这里需要-g选项编译。

进入前面创建的corefile文件夹:

出现core文件表示完成coredump配置。可以用通过readelf命令进行判断是否是core文件:

运行gdb阅读core文件,命令为“gdb 程序 对应coredump文件”,这时就进入gdb的提示符“(gdb)”。

从红色方框截图可以看到,程序中止是因为信号11。
下面可以通过bt(backtrace)命令(或者where)可以看到函数的调用栈情况:

即程序执行到test.cpp的第6行是出现段错误。原因是指向了空指针。
总结
造成程序coredump的原因有很多,这里总结一下,主要是内存访问越界、使用线程不安全的函数、使用空指针、堆栈溢出等等。
这里要说一下,gdb调试coredump,大部分时候还是只能从core文件找出core的直观原因,但是更根本的原因一般还是需要结合代码一起分析当时进程的运行上下文场景,才能推测出程序代码问题所在。

欢迎关注微信公众号【程序猿编码】,添加本人微信号(17865354792),回复:领取学习资料。或者回复:进入技术交流群。网盘资料有如下:
