机器学习算法--K近邻(KNN)
K近邻(KNN)算法
1、K-近邻算法
k近邻算法是一种基本分类和回归方法。当对数据的分布只有很少或者没有任何先验知识时,K 近邻算法是一个不错的选择。K近邻算法有三要素:k 值的选择、距离度量和分类决策规则
K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。(这就类似于现实生活中少数服从多数的思想) 如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。这也就是我们的目的,来了一个新的数据点,我要得到它的类别是什么?好的,下面我们根据k近邻的思想来给绿色圆点进行分类。
如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。这也就是我们的目的,来了一个新的数据点,我要得到它的类别是什么?好的,下面我们根据k近邻的思想来给绿色圆点进行分类。
- 如果K=3,绿色圆点的最邻近的3个点是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
- 如果K=5,绿色圆点的最邻近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
2、k近邻算法三要素
当K近邻算法的三要素k 值的选择、距离度量和分类决策规则确定以后,每一个新输入的实例都有唯一的分类。这相当于根据三要素将特征空间划分为一些子空间,确定子空间里的每个点所属的类。那么k怎么确定的,k为多少效果最好呢?所谓的最近邻又是如何来判断给定呢?
2.1 、选取k值以及它的影响
一般而言,从k = 1 k = 1k=1开始,随着的逐渐增大,K近邻算法的分类效果会逐渐提升;在增大到某个值后,随着的进一步增大,K近邻算法的分类效果会逐渐下降。
k值较小,相当于用较小的邻域中的训练实例进行预测,只有距离近的(相似的)起作用
- 单个样本影响大
- “学习”的近似误差(approximation error)会减小,但估计误差(estimation error)会增大
- 噪声敏感
- 整体模型变得复杂,容易发生过拟合
k值较大,这时距离远的(不相似的)也会起作用
- 近似误差会增大,但估计误差会减小
- 整体的模型变得简单
为方便理解,下面用图解解释
假设我们选取k=1这个极端情况,怎么就使得模型变得复杂,又容易过拟合了呢?
假设我们有训练数据和待分类点如下图:
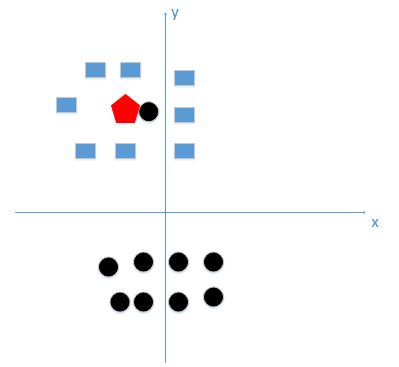
上图中有俩类,一个是黑色的圆点,一个是蓝色的长方形,现在我们的待分类点是红色的五边形。根据我们的k近邻算法步骤来决定待分类点应该归为哪一类。我们由图中可以得到,很容易我们能够看出来五边形离黑色的圆点最近,k又等于1,那太好了,我们最终判定待分类点是黑色的圆点。
由这个处理过程我们很容易能够感觉出问题了,如果k太小了,比如等于1,那么模型就太复杂了,我们很容易学习到噪声,也就非常容易判定为噪声类别,而在上图,如果,k大一点,k等于8,把长方形都包括进来,我们很容易得到我们正确的分类应该是蓝色的长方形。
所谓的过拟合就是在训练集上准确率非常高,而在测试集上准确率低,经过上例,我们可以得到k太小会导致过拟合,很容易将一些噪声(如上图离五边形很近的黑色圆点)学习到模型中,而忽略了数据真实的分布。
如果我们选取较大的k值,就相当于用较大邻域中的训练数据进行预测,这时与输入实例较远的(不相似)训练实例也会对预测起作用,使预测发生错误,k值的增大意味着整体模型变得简单。
所以,k值既不能过大,也不能过小
那么我们一般怎么选取呢?我们一般选取一个较小的数值,通常采取 交叉验证法来选取最优的k值。(也就是说,选取k值很重要的关键是实验调参,类似于神经网络选取多少层这种,通过调整超参数来得到一个较好的结果)
2.2、距离度量
我们所说的距离是两个实例点之间的相似度。所以K近邻算法中一个重要的问题是计算样本之间的距离,以确定训练样本中哪些样本与测试样本更加接近。
在实际应用中,我们往往需要根据应用的场景和数据本身的特点来选择距离计算方法。当已有的距离方法不能满足实际应用需求时,还需要针对性地提出适合具体问题的距离度量方法。
我们通常有以下几种度量单位;

2.3、分类决策规则
一般都是多数表决规则(majority voting rule),即把k个邻近的多数类别作为测试样本的类别。
3、特征归一化的必要性
首先举例如下,我用一个人身高(cm)与脚码(尺码)大小来作为特征值,类别为男性或者女性。我们现在如果有5个训练样本,分布如下:
A [(179,42),男] B [(178,43),男] C [(165,36)女] D [(177,42),男] E [(160,35),女]
通过上述训练样本,我们看出问题了吗?
很容易看到第一维身高特征是第二维脚码特征的4倍左右,那么在进行距离度量的时候,我们就会偏向于第一维特征。这样造成俩个特征并不是等价重要的,最终可能会导致距离计算错误,从而导致预测错误。口说无凭,举例如下:
现在我来了一个测试样本 F(167,43),让我们来预测他是男性还是女性,我们采取k=3来预测。
下面我们用欧式距离分别算出F离训练样本的欧式距离,然后选取最近的3个,多数类别就是我们最终的结果,计算如下:

由计算可以得到,最近的前三个分别是C,D,E三个样本,那么由C,E为女性,D为男性,女性多于男性得到我们要预测的结果为女性。
这样问题就来了,一个女性的脚43码的可能性,远远小于男性脚43码的可能性,那么为什么算法还是会预测F为女性呢?那是因为由于各个特征量纲的不同,在这里导致了身高的重要性已经远远大于脚码了,这是不客观的。所以我们应该让每个特征都是同等重要的!这也是我们要归一化的原因!归一化公式如下:

4、代码实例(鸢尾花分类)
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
def LoadData():
iris = load_iris()
# 将数据转为pandas,方便处理
iris_pd = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_pd['target'] = iris.target
X = iris.data
y = iris.target.reshape(-1, 1)
return X, y, iris, iris_pd
# 归一化数值
def autoNorm(data):
minValue = data.min(0)
maxValue = data.max(0)
ranges = maxValue-minValue
normData = data - np.tile(minValue, (data.shape[0], 1))
normData = normData/np.tile(ranges, (data.shape[0], 1))
return normData
# 划分训练集
def data_split(X, y):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
return X_train, X_test, y_train, y_test
# 曼哈顿距离
def l1_distance(a, b):
return np.sum(np.abs(a-b), axis=1)
# 欧式距离
def l2_distance(a, b):
return np.sqrt(np.sum((a-b) ** 2, axis=1))
# 分类器的实现
class KNN(object):
# 定义一个初始化方法
def __init__(self, k_neighber = 1, dist_func = l1_distance):
self.k_neighber = k_neighber
self.dist_func = dist_func
# 模型训练方法
def fit(self, x, y):
self.X_train = x
self.y_train = y
# 模型预测方法
def predict(self, x):
# 初始化预测分类数组
y_predict = np.zeros((x.shape[0], 1), dtype=self.y_train.dtype)
for i, x_test in enumerate(x):
distance = self.dist_func(self.X_train, x_test)
nn_index = np.argsort(distance)
nn_y = self.y_train[nn_index[:self.k_neighber]].ravel()
y_predict[i] = np.argmax(np.bincount(nn_y))
return y_predict
if __name__ == '__main__':
X, y, iris, iris_pd = LoadData()
print(X)
X = autoNorm(X)
print(X)
X_train, X_test, y_train, y_test = data_split(X, y)
knn = KNN(k_neighber=3, dist_func=l2_distance)
knn.fit(X_train, y_train)
y_pre = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pre)
print('预测准确率: ', accuracy)
5、sklearn实现KNN手写数字识别
import numpy as np
import os
from sklearn.neighbors import KNeighborsClassifier as kNN
def img2vector(filename):
"""
将图片的文本文档转换为向量的形式
:param
filename:文档名
:return:
returnVector:图片对应的一维向量
"""
returnVector = np.zeros((1, 1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVector[0, i * 32 + j] = int(lineStr[j])
fr.close()
return returnVector
def handWritingClassfierTest():
"""
手写数字测试
:return:
"""
trainingFilelist = os.listdir('trainingDigits') # 返回trainingDigits目录下的文件名
m = len(trainingFilelist)
trainLabel = []
trainingMat = np.zeros((m, 1024))
for i in range(m):
fileName = trainingFilelist[i]
classNumber = int(fileName.split('_')[0]) # 标签数字
trainLabel.append(classNumber)
trainingMat[i,:] = img2vector('trainingDigits/{}'.format(fileName))
# 构建KNN分类器
neigh = kNN(n_neighbors=3, algorithm='auto')
neigh.fit(trainingMat, trainLabel)
testFilelist = os.listdir('testDigits')
n = len(testFilelist)
error = 0.0
for i in range(n):
fileName = testFilelist[i]
classNumber = int(fileName.split('_')[0]) # 标签数字
imgVectortset = img2vector('trainingDigits/{}'.format(fileName))
classPredict = neigh.predict(imgVectortset)
print('分类结果是{},真实结果是{}'.format(classPredict, classNumber))
if(classPredict != classNumber):
error += 1.0
print('总共错了{}个数据,错误率是{}%%'.format(error, error / n * 100))
if __name__ == '__main__':
handWritingClassfierTest()
「数据下载」https://www.aliyundrive.com/s/jcmpT3VLVJ1 提取码: x00p