深度学习系列6——目标检测 YOLO 系列1
1. 概述
本文主要对 YOLO V1 的原理做一个简单的介绍,关于背景,网络上已经很多了,不再赘述。
YOLO V1 论文下载:You Only Look Once: Unified, Real-Time Object Detection
2. YOLO V1
YOLO(You Only Look Once)是一个基于深度神经网络的目标识别和定位算法,其优势是运行速度非常快,随着不断迭代,相比 V1,识别的效果也有了极大地提升。相比于 RCNN 两步配合完成检测,YOLO 直接一步到位,输入图像,输出结果,所见即所得。
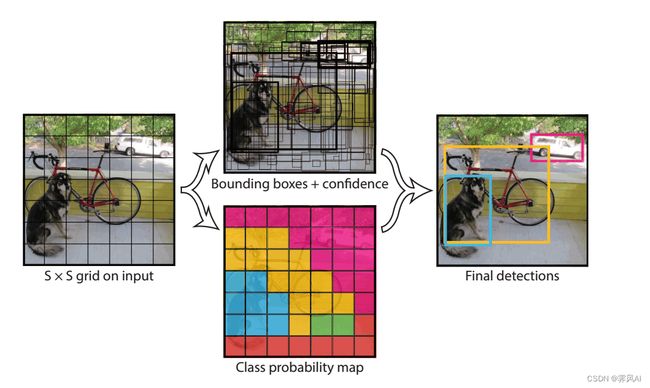
3. 训练阶段
3.1 数据标注
训练数据在开始神经网络的训练之前,需要进行标注(监督学习),即下图,通过标注工具绘制 ground turth,而 ground truth 的中心点落在哪一个 grid cell,就由该 grid cell 的 bounding box 对目标进行预测。

一些说明:
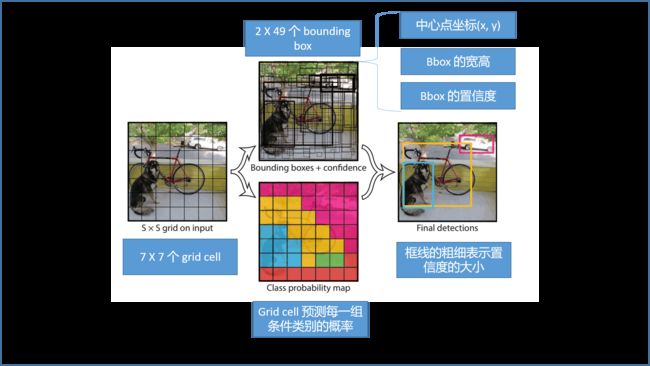
(1)每一个 grid cell 预测一个类别,7 x 7 = 49 个 grid cell 预测共 49 个物体;
(2)每个 grid cell 预测两个 bounding box ,与 ground truth 交并比比较大的 bounding box 为最终预测物体的框;
(3)49 X2 = 98 个 bounding box 的中心点都落在所属的 grid cell 里面。

实现效果就是让负责预测的框与实际的框尽可能一致。
当 ground truth 的中心点落在 grid cell ,用 ground truth IOU 比较大的 bounding box 去拟合物体 , IOU 比较小的框则抛弃。
当 bounding box 的中心点没有落在预测目标的 grid cell 中,那么其预测出的两个框都直接抛弃,预测框的置信度越低越好。
3.2 损失函数
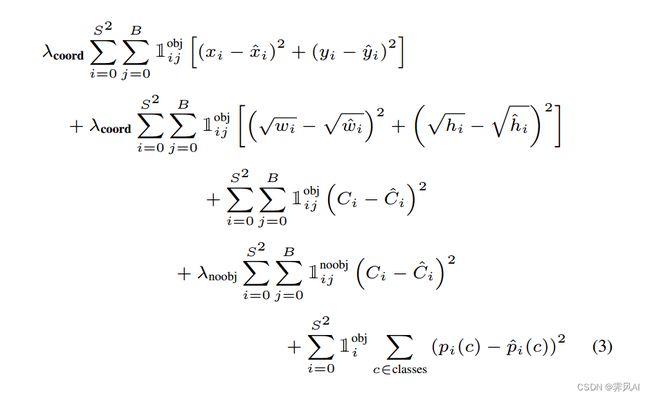
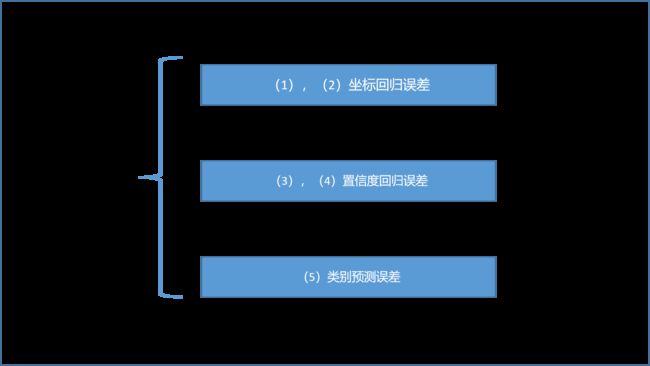
损失函数总共包含 5 项,依次分析一下,YOLO 将目标检测问题转换为回归问题求解。
(1)负责检测物体的 bounding box 中心点定位误差
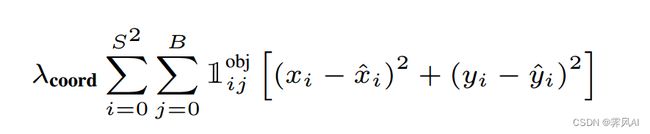
残差平方和,bounding box 要尽可能与 ground truth 重合,预测值与标签值之间做差。
(2)负责检测物体的 bounding box 的高宽定位误差
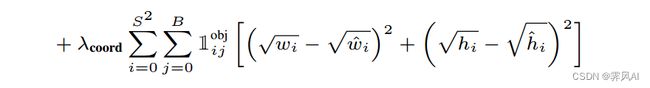
bounding box 与 ground truth 之间的宽高误差,开平方是为了平衡大框与小框对误差的敏感度。
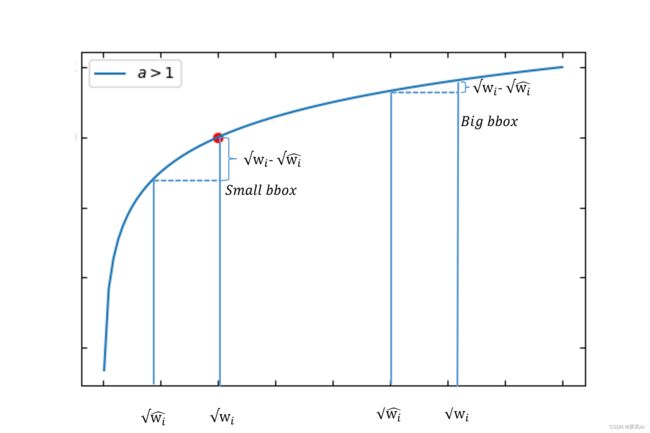
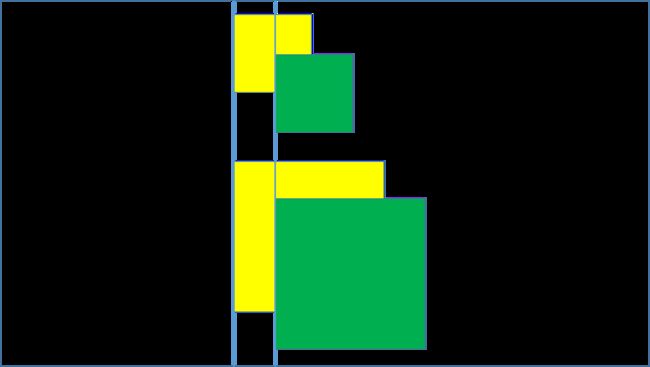
可以看到 bounding box 偏移同样的距离,小目标所产生的误差是大于大目标的。经过开方之后,使得小框产生的误差对大框更加公平。
这是因为目标边界框与预测边界框偏移同样距离,大框和小框的 IOU 差别是不一样的。黄色:目标,绿色:预测。
(3)负责检测物体的 bounding box 的 confidence 误差

标签值为 ground truth 与 bounding box 的 IOU,预测值与 IOU 越接近越好。
(4)不负责检测物体的 bounding box 的 confidence 误差

那些被抛弃的 bounding box 的误差,包括预测到目标,但 IOU 较小的 bounding box 和没有预测到物体的 bounding box,他们的置信度越小越好,为最好为 0。
(5)负责检测物体的 grid cell 的分类误差
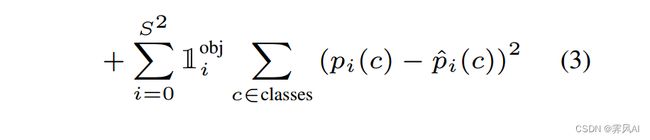
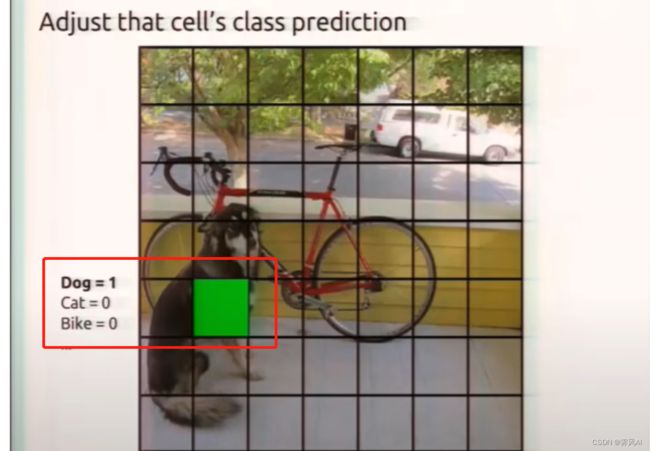
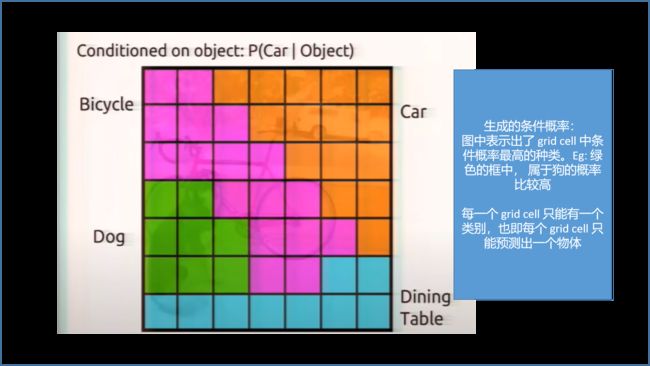
负责预测目标的 grid cell 的概率越接近于 1 越好,如图,预测狗 grid cell 的条件概率为 1。
损失函数中的 λ 是权重,对于真正负责检测目标的项给与更高的权重,不负责检测目标的项给与更低的权重。
| 下标 | 解释 |
|---|---|
| i | s x s 个 grid cell,为 7 x 7 = 49 |
| j | bounding box 的数目,为 2 |
4. 预测阶段
4.1 网络框架
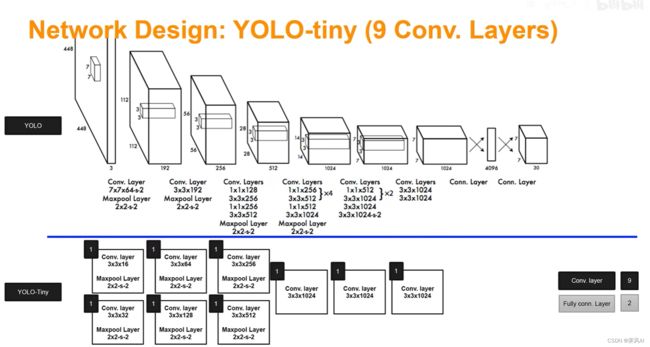
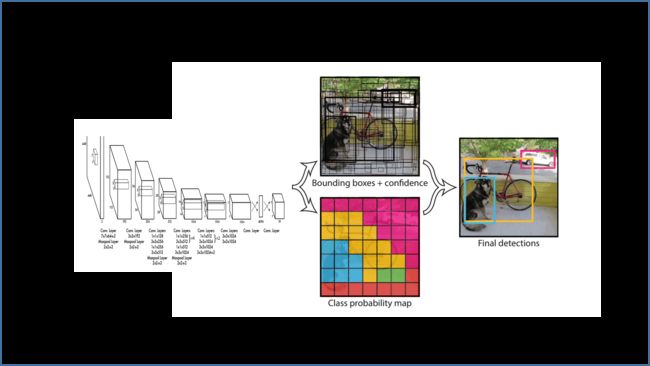
图中上部分为 YOLO V1 的神经网络框架,一系列卷积操作的叠加。
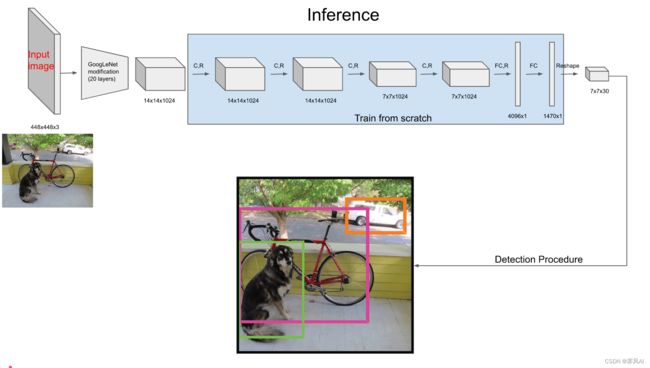
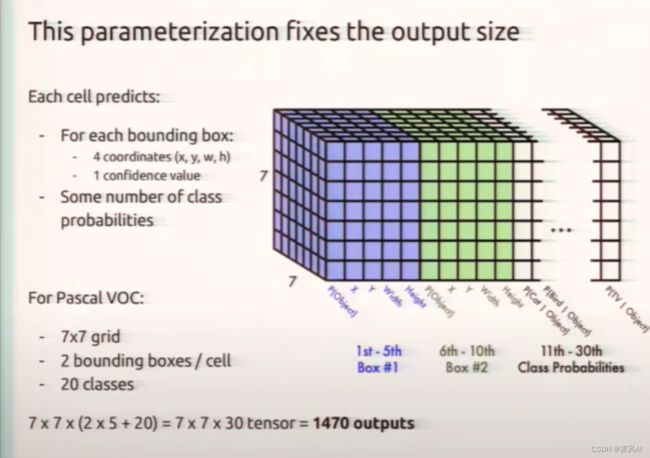
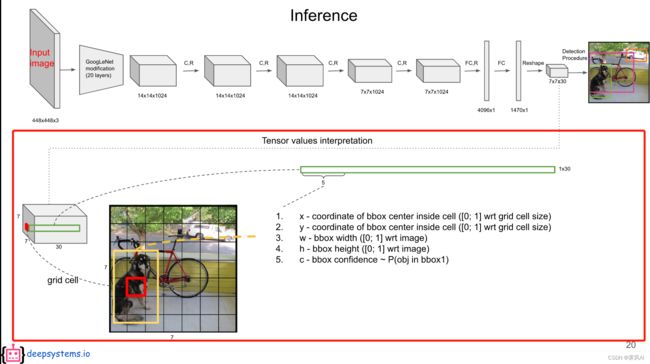
其输入为 448 x 448 x 3 的图像,最终输出为 7 x 7 x 30 的 feature map(30 个 7 x 7 的矩阵叠到一起)。
模型预测各部分参数组成:
7 X 7 X 30 的张量解释:
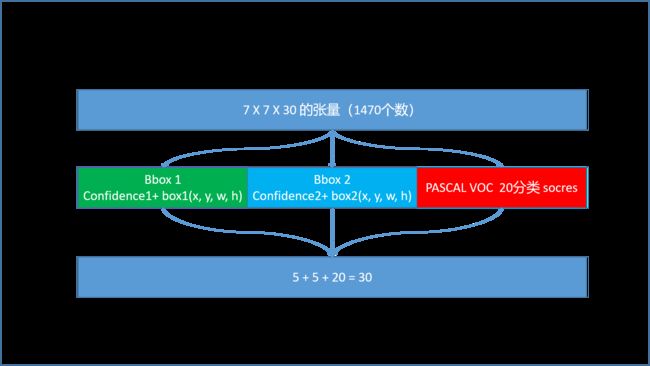
30 维数据组成:
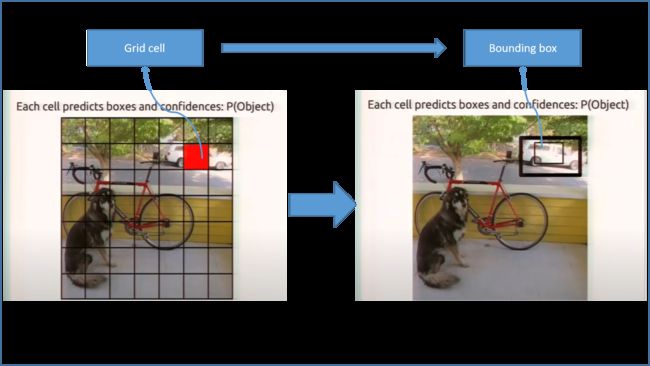
grid cell ----> bounding box:
条件预测概率:
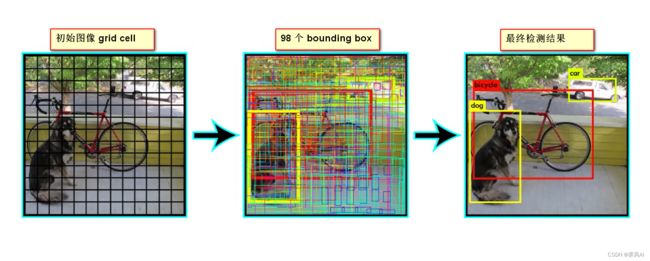
预测过程:
输入图像到结果输出:
4.2 NMS 非极大值抑制
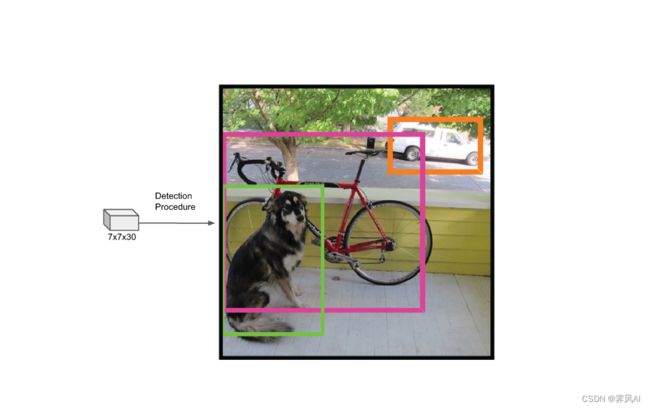
对最终一个预测目标获得的 98 个预测框进行筛选,过滤掉重复和低置信度的预测框,只保留下 1 个。
7 X7 X 30 张量处理:
目标检测的概率:
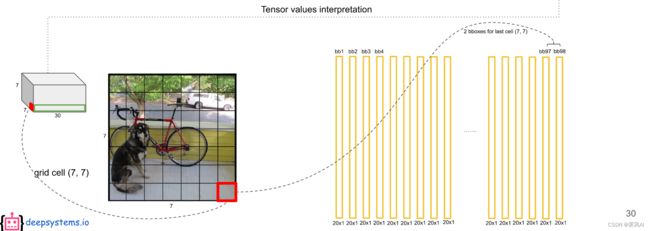
在每个 Bounding box 上的预测的条件概率 乘以 该 grid cell 的置信度,得到在该预测框的全概率,一个竖条表示该 bounding box 得到共 20 个分类的概率值。
如何从 7 x 7 x 30 的张量获得最终结果?
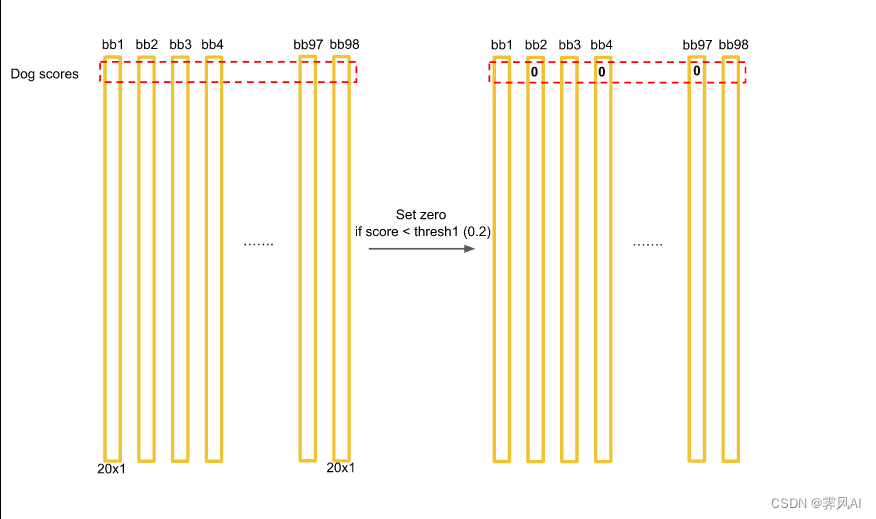
(1)以 dog 为例,将小于某个阈值(Dog 此处 为 0.2)的概率值全部设置为 0;
(2)对修改了概率之后的结果进行排序,概率值大的放到前面,小的排在后面;

(3)NMS 过程
经过排序之后,得到概率序列。具体如何取出最终的结果呢?
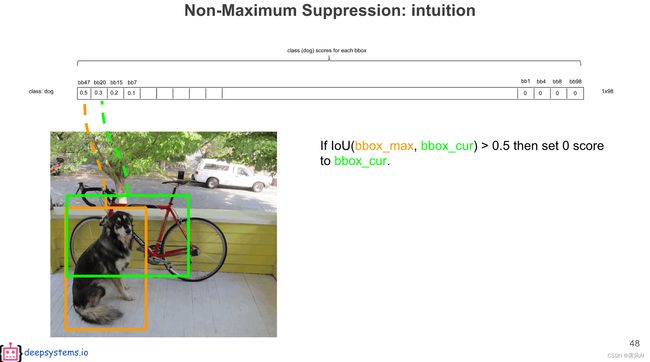
即将排在第二位(bb47)的概率值与第一位(bb20)比较,如果 IOU 大于某个阈值(此处为 0.5),则将小概率设置为 0,意思是小概率和大概率的 bounding box 识别的是同一个对象。
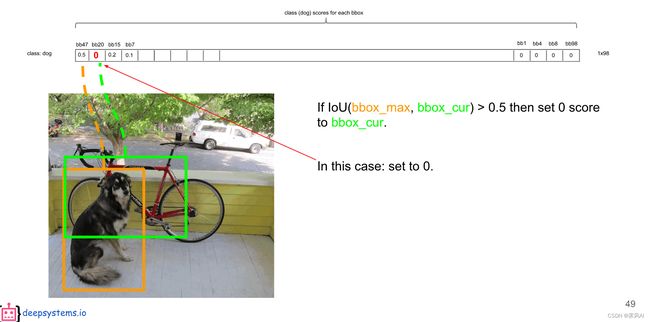
然后,再将排在第三位(bb15)与第一位(bb47)比较,如果 IOU 大于设定的阈值(此处为 0.5),则继续设置为 0,否则保留此概率,进行后一个(bb7)判定;
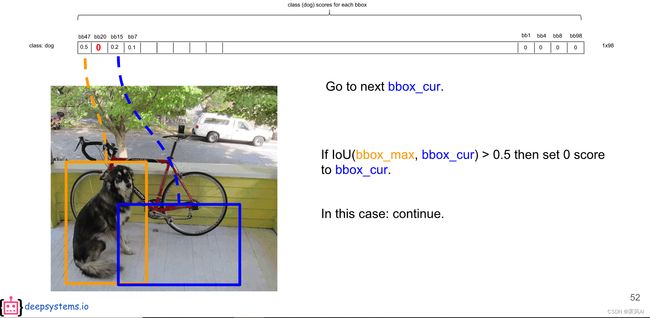
在完成第一轮判别之后,按照上述流程进入第二轮判定,用第一轮判定后,排在第二位的概率值继续重复比较过程,完成此次判定,以此类推,直至得到该分类的最终结果,从而进入到下一个分类。
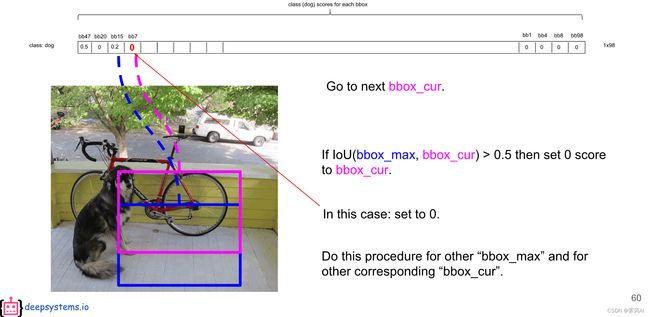
完成所有类别的判定之后,就得到每一个分类的预测结果。
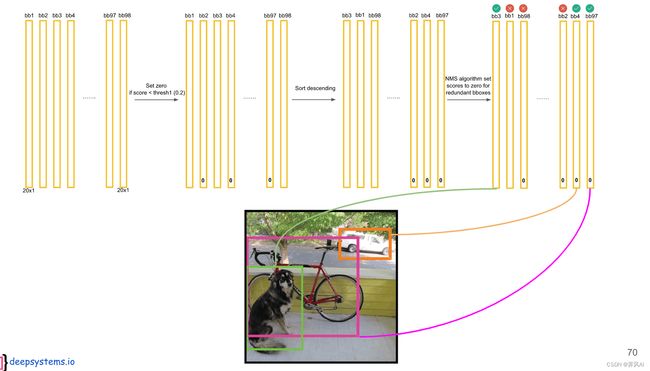
感谢参考链接处的各位博主,让知识获取变得更加容易。
欢迎关注公众号:【千艺千寻】,共同成长
参考:
- 3.1 YOLO系列理论合集(YOLOv1~v3)
- 【目标检测-YOLO】博客阅读:Introduction to the YOLO Family
- 【精读AI论文】YOLO V1目标检测,看我就够了
- deepsystems.io
- object detection目标检测
- YOLOv1 深入理解