JVM 常量池、即时编译与解析器、逃逸分析
一、常量池
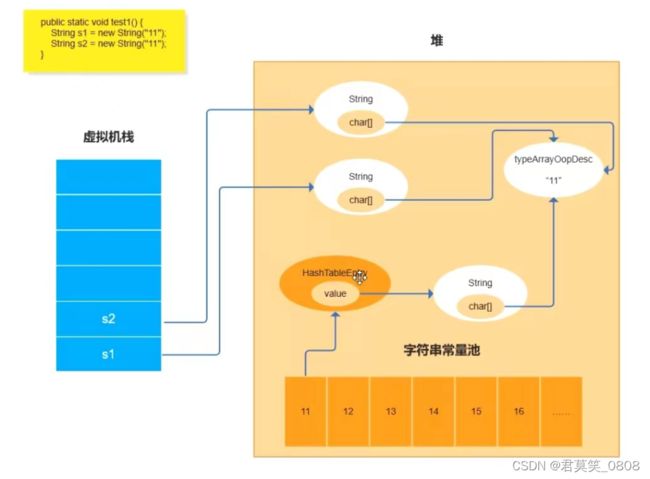
1.1、常量池使用 的数据结构
常量池底层使用HashTable
key 是字符串和长度生成的hashValue,然后再hash生成index, 该index就是key;Value是一个HashTableEntry;
1、key
hashValue = hash string(name, len)
index = hash to index(hashValue);
1、根据字符串(即 name)以及字符串的长度计算出hashValue
2、根据hashValue计算出index,这个index就是key
2、value
1、HashtableEntry
2、将Java的string类的实例instanceOopDesc封装成HashtableEntry
3、struct HashtableEntry {
INT PTR hash;
void* key;
void* value; instanceopDesc
HashtableEntry* next;
};
1.2、JVM底层是如何操作常量池
String s = "1";
1、去字符串常量池中去查, 有直接返回对应的string对象
2、如果没有,就会创建string对象、char数组对象,
3、将这个string对象对应的InstanceOopDesc封装成HashtableEntry,作为StringTable的value进行存储
4、new String()就是在堆上又创建一个对象char[] 指向typeArrayOopDesc
二、即使编译与解析器
2.0 编译过程
- .java源文件通过编译器(javac.exe)编译成.class文件
- JVM通过ClassLoader对.calss文件进行解释(自解码解释器和JIT即使编译器)—该过程需要调用核心类

3、说说JVM内的解释器(Just In Time Compiler)和即时编译器(JIT)
作用:解释器和即时编译器(Just In Time Compiler,JIT)是JVM中将字节码转化为机器码的工具。
解释器: 解释器将字节码解析成集器能识别的机器码。解释方式是一行一行的读取,解释到哪就执行到哪。
即使编译器:以方法为单位,将热点代码的字节码一次性转为机器码,并在本地缓存起来的工具。避免了部分代码被解释器逐行解释执行的效率问题。
2.1 编译器
2.1.1 即时编译器种类
C1
C2
2.1.2 即时编译器 分层编译
分层编译
c1编译器是client模式下的即时编译器
1、触发的条件相对C2比较宽松:需要收集的数据较少
2、编译的优化比较浅:基本运算在编译的时候运算掉了 final
3、c1编译器编译生成的代码执行效率较C2低
c2编译器是server模式下的即时编译器
1、触发的条件比较严格,一般来说,程序运行了一段时间以后才会触发
2、优化比较深
3、编译生成的代码执行效率较C1更高
混合编译
程序运行初期触发C1编译器
程序运行一段时间后触发C2编译器
2.1.3 编译器与解释器关系
即时编译器生成的代码就是给模板解释器用的
- 解释器:程序执行的时候,解释器首先发挥作用,省去了编译器编译时间,加快程序的执行效率
- 编译器:在程序运行过程中,随着时间的推移,编译器就开始慢慢发挥了作用,把热点代码编译成本地代码后,以后执行相同的代码,即可直接获取,更高的执行效率。
- 解释器和编译器相互配合,使程序高效执行。
2.1.4 问题分享
分享阿里早年的一个故障
热机切冷机故障: 冷机启动后有大量代码编译,造成cpu爆炸,机器宕机
冷机:刚启动的时候
热机:启动很长时间
2.1.5 热点代码存放位置
热点代码缓存区在 方法区,C++代码中以 CodeCache存在
调优中的一种
server编译器模式下代码缓存大小则起始于 2496KB
client编译器模式下代码缓存大小起始于 160KB
2.1.6 触发条件
热点代码被编译为 硬编码即汇编指令
热点代码
即时编译的最小单位不是一个函数,而是代码块 (for、while)
判断热点代码探测方法
采样式的热点探测
周期性检查线程栈顶,经常出现在栈顶的就是热点代码
-
优点:简单高效。
-
缺点:容易受到线程阻塞或其他因素影响
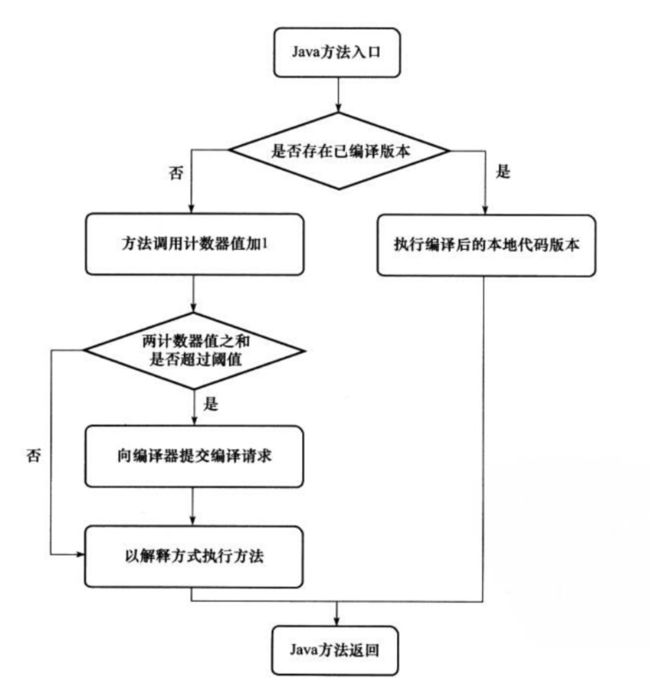
方法调用计数器
client 编译器模式下,N 默认的值 1500
Server 编译器模式下,N 默认的值则是 10000
可通过 -XX:CompileThreadhold设置,在一段时间内被调用次数。当超过一定的时间限度,如果方法的调用次数仍然不足以让它提交给即时编译器编译,那么这个方法的调用计数器就会被减少一半,这个过程称为方法调用计数器热度的衰减(Counter Decay),而这段时间就成为此方法的统计的半衰周期( Counter Half Life Time)。进行热度衰减的动作是在虚拟机进行垃圾收集时顺便进行的,可以使用虚拟机参数 -XX:CounterHalfLifeTime 参数设置半衰周期的时间,单位是秒。
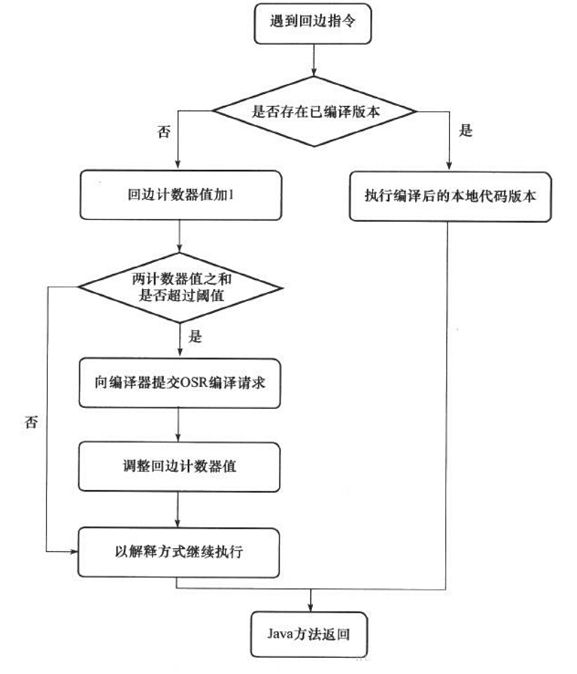
回边计数器(Back Edge Counter )
统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为“回边”( Back Edge )。显然,建立回边计数器统计的目的就是为了触发 OSR 编译。关于这个计数器的阈值, HotSpot 提供了 -XX:BackEdgeThreshold 供用户设置,但是当前的虚拟机实际上使用了 -XX:OnStackReplacePercentage 来简介调整阈值。
2.2 解析器
2.2.1 解释器种类
字节码解释器
Java字节码->c++代码->硬编码
模板解释器
Java字节码->硬编码
2.2.2 运行模式
解析器有三种运行模式
1、-Xint 纯字节码解释器
2、-Xcomp 纯模板解释器
程序比较大
3、-Xmixed 字节码解释器 + 模板解释器
比较一下这三种运行模式的性能
231
321
与程序大小有关,程序较大时Xcomp会使程序变得更大,编译器很慢
三、逃逸分析
3.1 逃逸
什么对象不会逃逸
局部对象不会产生逃逸
什么对象会逃逸
共享变量,方法返回值,参数 会产生逃逸
3.2 分析
三种手段
3.2.1 标量替换
public void test2() {
System.out.println(EA);
System.out.println(1);
}
3.2.2 锁消除
局部对象new Object(),锁被消除掉
public void test() {
synchronized (new Object()){
System.out.println("=============");
}
}
public void test() {
System.out.println("=============");
}
3.2.3 栈上对象分配
不产生逃逸的方法内,对象会部分被分配到栈上面
参考博客:JVM的mixed mode_yzpyzp的博客-CSDN博客