第一阶段-第十章 Python基础的综合案例(数据可视化-折线图可视化)
目录
- 一、本章的案例介绍
-
- 1.可视化案例(本章)的学习目标
- 2.需要实现的效果图
- 3.数据来源
- 二、json数据格式
-
- 1.学习目标
- 2.什么是json
- 3. json的作用
- 4.json的语法要求
- 5.Python数据和json数据的相互转化(dumps转json、loads转Python)
- 6.本节的代码演示
- 7.本小节的总结
- 三、pyecharts模块介绍
-
- 1. pyecharts模块
- 2. 安装pyecharts模块
- 3.本小节的总结
- 四、pyecharts快速入门
-
- 1.学习目标
- 2. pyecharts入门(以折线图为例)
- 3. pyecharts的配置的简要介绍
- 4. 全局配置(set_global_opts方法)
- 5.本节的代码演示
- 五、数据处理以及创建折线图
-
- 1.学习目标
- 2.如何查看json文件的层级关系
- 3.本节的代码演示
说明:该文章是学习 黑马程序员在B站上分享的视频 黑马程序员python教程,8天python从入门到精通而记录的笔记,笔记来源于本人。 若有侵权,请联系本人删除。笔记难免可能出现错误或笔误,若读者发现笔记有错误,欢迎在评论里批评指正。此笔记对应的doc文件的百度网盘下载链接为 Python入门(黑马)的学习笔记,提取码:1b3k。另外,本次笔记新加了 gif动图,使用免费的potplayer播放器可以控制gif的播放进度。


一、本章的案例介绍
1.可视化案例(本章)的学习目标
通过案例,回忆巩固Python基础的语法;锻炼编程能力,熟练语法的使用。
2.需要实现的效果图



3.数据来源

二、json数据格式
1.学习目标
知道什么是json;掌握如何使用json进行数据转化。
2.什么是json

3. json的作用

4.json的语法要求
从下图中可以看出,json的语法格式相当于由Python的字典或者内嵌字典的列表转换成的字符串。

5.Python数据和json数据的相互转化(dumps转json、loads转Python)
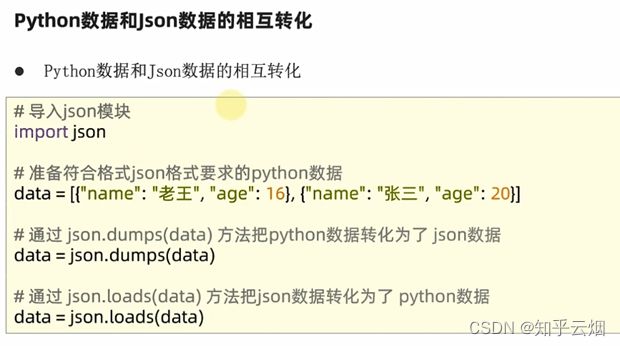
6.本节的代码演示
先打开软件,创建一个名为“10_ Python基础的综合案例”的文件夹,创建一个名为“01_json数据格式”的py文件。


编写代码并运行。代码如下,可参考注释进行理解。
"""
演示JSON数据和Python的相互转换
"""
import json # 导入内置的json模块
# 准备列表,列表内每一个元素都是字典,将其转换为JS0N
data = [{"name": "张大山", "age": 11}, {"name": "王大锤", "age": 13}, {"name": "赵小虎", "age": 16}]
json_str = json.dumps(data, ensure_ascii=False)
# ensure_ascii=False表示不用转换成ASCII码 如果为了节省空间,请不要写ensure_ascii=False
print(f"json_str的数据类型是:{type(json_str)}")
print(f"json_str的内容是:{json_str}")
# 准备字典,将字典转换为JSON
d = {"name": "周杰轮", "addr": "台北"}
json_str = json.dumps(d, ensure_ascii=False)
print(f"json_str的数据类型是:{type(json_str)}")
print(f"json_str的内容是:{json_str}")
# 将JSON字符串转换为Python数据类型[{k:V,k:V},k:V,k:v}]
s = '[{"name": "张大山", "age": 11}, {"name": "王大锤", "age": 13}, {"name": "赵小虎", "age": 16}]'
l = json.loads(s)
print(f"l的类型为:{type(l)}")
print(f"l的内容为:{l}")
# 将JSON字符串转换为Python数据类型{k:V,K:V}
s = '{"name": "周杰轮", "addr": "台北"}'
d = json.loads(s)
print(f"d的类型为:{type(d)}")
print(f"d的内容为:{d}")

7.本小节的总结

三、pyecharts模块介绍
1. pyecharts模块

Pyecharts的官方网站为:“pyecharts.org”,可以如下图一样操作,还可以将语言选择为中文。
Pyecharts还有一个画廊的网站:“https://gallery.pyecharts.org/”。如下图所示打开这个画廊网站,它是Pyecharts的画廊。为什么要去看它的画廊呢?因为Pyecharts是一个可视化的框架,主要功能就是产生各种各样的图表。在这样一个画廊网站里,就好比美术作品的展览会一样,我们可以在里面找到自己感兴趣的图表,然后查看它们的实现代码。利用这些代码,再更改一些数据,可以得到我们想要的图表。
2. 安装pyecharts模块

具体操作如下:首先,如下图,打开“命令提示符”。

然后如下图所示进行安装。

3.本小节的总结

四、pyecharts快速入门
1.学习目标
构建一个基础的折线图;使用全局配置项设置属性。
2. pyecharts入门(以折线图为例)

3. pyecharts的配置的简要介绍

全局配置就是针对我们整个图像来去进行设置,比如图像的标题、图像的图例、工具箱等。对于系列配置,就是针对具体的轴数据进行配置。
4. 全局配置(set_global_opts方法)
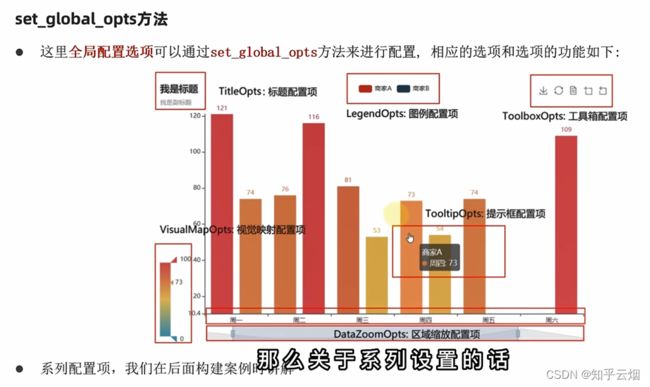

title_opts为标题的设置,legend_opts为图例的设置,toolbox_opts为工具箱的设置,用法见演示。
5.本节的代码演示
先打开软件,创建一个名为“02_pyecharts基础入门”的py文件。

编写代码,代码如下,可参考注释进行理解。然后如下图所示右键运行代码,然后就会产生文件render.html,点击打开该文件,然后再使用浏览器(本次用的是Edge)打开即可看到本次生成的折线图。
"""
演示pyecharts的基础入门
"""
# 导包
from pyecharts.charts import Line # 用来构建折线对象
from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, VisualMapOpts # 导入标题、图例、工具箱、视觉映射的控制选项
# 创建一个折线图对象
line = Line()
# 给折线图对象添加x轴的数据
line.add_xaxis(["中国", "美国", "英国"])
# 给折线图对象添加y轴的数据
line.add_yaxis("非真实的GDP", [30, 20, 10])
# 设置全局配置项 - set_global_opts
line.set_global_opts(
# TitleOpts用来控制标题 pos即位置position pos_left="center"表示居中 pos_bottom="1%"表示距离底部1%的位置
title_opts=TitleOpts(title="GDP展示", pos_left="center", pos_bottom="1%"),
# LegendOpts用来图例
legend_opts=LegendOpts(is_show=True),
# ToolboxOpts用来控制工具箱
toolbox_opts=ToolboxOpts(is_show=True),
# VisualMapOpts用来控制视觉映射
visualmap_opts=VisualMapOpts(is_show=True)
)
# 通过render方法,将代码生成为图像
line.render()
6.本小节的总结

五、数据处理以及创建折线图
1.学习目标
能够通过json模块对数据进行处理;通过pyecharts完成疫情折线图。
2.如何查看json文件的层级关系
如下两张图所示,文件“美国.txt”存储了一堆json格式的数据,第二张图是本次json数据的层次关系,至于如何查看json文件的层次关系,本条将给出详细的步骤。
注:加入黑马程序员的qq群可获得文件“美国.txt”,或者本人也会将文件上传到百度网盘,供大家一起学习使用。


如下图,首先打开存储json数据的文件“美国.txt”,然后将其中的json数据使用Ctr+C进行复制。然后再打开能解析json的网站(本人随便找了个,链接为:“https://c.runoob.com/front-end/53/”),之后将json数据粘贴进去,然后点击“格式化”,点击箭头“→”,就可以查看json数据的层次关系了。
3.本节的代码演示
如下图,在文件夹“10_Python基础的综合案例”处右键,创建一个名为“03_折线图开发”的py文件。

如下图,在编写代码时需去掉不符合json规范的内容。


在编写代码时还需要根据json文件的层次关系拿到相应的数据。如下图,先边编写代码边验证,得到“trend”的数据。
"""
演示可视化需求1:折线图开发
"""
import json
# 处理数据
f_us = open("D:/test/1-10-3/美国.txt", "r", encoding="UTF-8")
us_data = f_us.read() # 美国的全部内容
# 去掉不合JS0N规范的开头
us_data = us_data.replace('jsonp_1629344292311_69436(', '')
# 去掉不合JS0N规范的结尾
us_data = us_data[:-2]
# JS0N转Python字典
us_dict = json.loads(us_data)
# print(type(us_dict))
# print(us_dict)
# 获取trend key
trend_data = us_dict['data'][0]['trend']
print(type(trend_data))
print(trend_data)

然后将得到的“trend”的数据重新放入json的解析网站中进行解析,由于这些数据有点不符合json的格式规范,于是重新换了个json解析网站(链接:“http://sjson.cn/”)。如下图所示,将鼠标放到“trend”的数据的开头,使用快捷键shift+END选中“trend”的数据(shift+END是选中一行的快捷键),再使用快捷键Ctr+C进行复制。然后打开json网站,把原有数据删除,再使用快捷键Ctr+V把数据粘贴进去,把数据粘贴进去,然后得到“trend”的数据的层次结构。
继续编写代码,如下图所示,需根据“trend”的数据的层次关系获取2020年的日期信息、确诊信息。
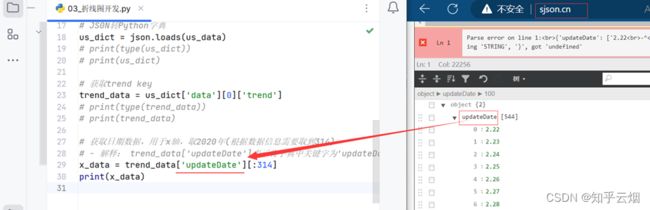

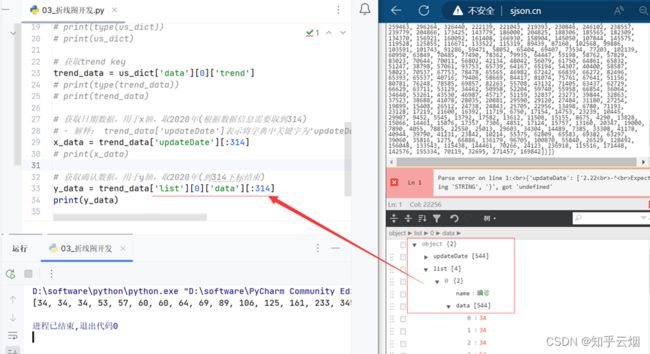
由于第一个画的是美国的疫情图,故将变量trend_data、x_data、y_data改成us_trend_data、us_x_data、us_y_data。之后,日本、印度的疫情数据可同理获得,代码类似。然后,继续编写完代码并右键运行,然后去查看文件render.html。
"""
演示可视化需求1:折线图开发
"""
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LabelOpts
# 处理数据
f_us = open("D:/test/1-10-3/美国.txt", "r", encoding="UTF-8")
us_data = f_us.read() # 美国的全部内容
f_jp = open("D:/test/1-10-3/日本.txt", "r", encoding="UTF-8")
jp_data = f_jp.read() # 日本的全部内容
f_in = open("D:/test/1-10-3/印度.txt", "r", encoding="UTF-8")
in_data = f_in.read() # 印度的全部内容
# 去掉不合JS0N规范的开头
us_data = us_data.replace('jsonp_1629344292311_69436(', '')
jp_data = jp_data.replace('jsonp_1629350871167_29498(', '')
in_data = in_data.replace('jsonp_1629350745930_63180(', '')
# 去掉不合JS0N规范的结尾
us_data = us_data[:-2]
jp_data = jp_data[:-2]
in_data = in_data[:-2]
# JS0N转Python字典
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)
# print(type(us_dict))
# print(us_dict)
# 获取trend key
us_trend_data = us_dict['data'][0]['trend']
jp_trend_data = jp_dict['data'][0]['trend']
in_trend_data = in_dict['data'][0]['trend']
# print(type(trend_data))
# print(trend_data)
# 获取日期数据,用于x轴,取2020年(根据数据信息需要取到314)
# - 解释: trend_data['updateDate']表示将字典中关键字为'updateDate'的数据取出来 切片[:314]是将前面313个数据取出来
us_x_data = us_trend_data['updateDate'][:314] # 查看文档后取314
jp_x_data = jp_trend_data['updateDate'][:315] # 查看文档后取315
in_x_data = in_trend_data['updateDate'][:269] # 查看文档后取269
# print(x_data)
# 获取确认数据,用于y轴,取2020年(到314下标结束)
us_y_data = us_trend_data['list'][0]['data'][:314]
jp_y_data = jp_trend_data['list'][0]['data'][:315]
in_y_data = in_trend_data['list'][0]['data'][:269]
# print(y_data)
# 生成图表
line = Line() # 构建折线图对象
# 添X抽数据
line.add_xaxis(us_x_data)
line.add_xaxis(jp_x_data)
line.add_xaxis(in_x_data)
# 添心抽数据
line.add_yaxis("美国确诊人数", us_y_data,
label_opts=LabelOpts(is_show=False)) # 添加美国的y轴数摇 label_opts=LabelOpts(is_show=False):标签不显示数字
line.add_yaxis("日本确诊人数", jp_y_data,
label_opts=LabelOpts(is_show=False)) # 添伽日本的y轴数据
line.add_yaxis("印度确诊人数", in_y_data,
label_opts=LabelOpts(is_show=False)) # 添加印度的y轴数据
# 设置全局选项
line.set_global_opts(
# 标题设置
title_opts=TitleOpts(title="2020年美日印三国确诊人数对比折线图", pos_left="center", pos_bottom="1%"),
)
# 调用render方法,生成图表
line.render()
# 关闭文件对象
f_us.close()
f_jp.close()
f_in.close()
注:本次演示存在一个问题,那就是美日印的数据的日期起点不一样,导致本次演示的2020年的x轴的数据个数不一样,所以最后的图还是存在一定的问题的。原视频默认美日印的数据的日期起点一样了,故把21年的部分数据也给取来了,这样就不存在本次个人遇到的问题。目前,个人因能力有限,暂时不会解决这个问题,欢迎大家提出自己的观点。
好了,本章的笔记到此结束,谢谢大家阅读。