DPDK&SPDK中的内存管理
引言
DPDK的一大特点是使用大页(hugepage)进行内存管理,相比4KB页管理,使用大页可以减少页表大小,节省开销以及降低TLB miss的概率,从而提升应用访问内存的效率。在此基础上,DPDK主要实现了无锁队列ring,内存池mempool,内存堆heap来进行内存的分配和回收。
DPDK内存管理
开启大页
DPDK在非ARM平台上,最多支持三种尺寸(MAX_HUGEPAGE_SIZES = 3)的大页,我们熟悉的x86系统上通常有2M和1G两种大页,我们可以在/etc/grub.conf文件中配置默认大页,如:
//开启20G的大页,页大小为2MB(默认大小也为2M)
default_hugepagesz=2M hugepagesz=2M hugepages=10240
也可以按需修改,如:
echo 20480 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
开启大页后,将大页文件系统hugetlbfs挂载到目录下,用户程序就可以使用mmap映射大页文件来使用大页了
//将大页文件系统挂载到/mnt/huge目录下
mount –t hugetlbfs nodev /mnt/huge
内存初始化
DPDK的内存初始化,可以简单类比linux内存的初始化(buddy系统和slab系统),包括如下几个过程:
- 大页信息初始化
- dpdk buddy初始化(memzone,memseg list初始化&memseg 映射)
- dpdk slab初始化(heap初始化)
先上一张图, DPDK完成初始化后内存的顶层示意图,大页映射到挂载点下的文件,内部通过多个memseg list来管理大页:
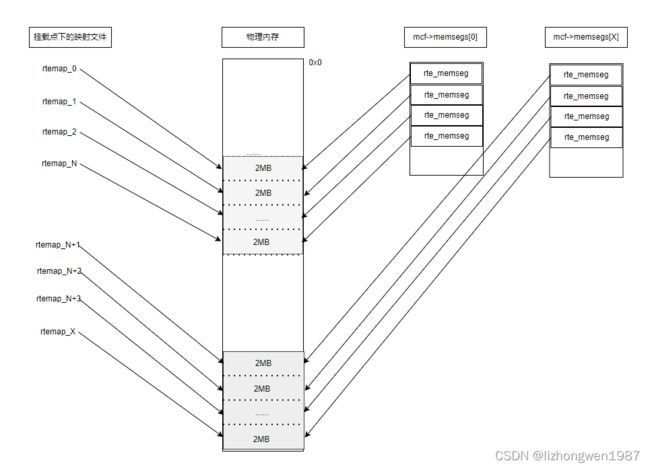
大页信息初始化
dpdk根据系统的大页配置,初始化大页数组,计算每种大页数(统计每个numa节点上的可用页面数),核心的代码调用如下:
#枚举/sys/kernel/mm/hugepages目录下的大页,记录可用大页类型在internal_conf->hugepage_info数组,对于每种大页:
#检查/proc/mounts下的hugetlbfs的挂载点,通过hugepagesz判断对应的大页类型是否可用,将可用的大页类型记录在hugepage_info数组并计算可用页面数
eal_hugepage_info_init
eal_hugepage_info_init
hugepage_info_init
calc_num_pages #累计numa节点上的大页得到总的大页数
get_num_hugepages_on_node #统计numa节点上的可用大页/sys/devices/system/node/node{X}/hugepages/hugepages-{Y}/free_hugepages
memzone初始化
memzone用来指向一段连续的内存空间,在创建mempool,ring时会用到。memzone数组,默认包含2560项memzone元素,数组末尾也有一个位图用来标识元素的分配状态,初始化完成后,通过mmap映射到文件。示意图如下:

核心调用如下:
rte_eal_memzone_init
rte_fbarray_init #分配memzone堆空间,通过mmap映射到文件
memseg list初始化
dpdk按照如下方式对系统内存进行逻辑管理, 定义内存类型:hugepage类型数 * numa节点数 定义内存类型数,如:1 * 2 = 2,那就表示有两种内存类型(即:系统配置了一种大页,有两个numa节点,按numa节点管理内存,可以减少跨numa分配内存带来的性能开销),根据内存类型及内存容量,初始化内存管理结构:每种内存类型由若干memseg list来管理赋予的内存,每个memseg list管理一段连续的内存,每个memseg管理一个大页,每个memseg list映射到文件,每个大页映射到文件,这样就可以通过文件来管理和操作每个大页。(每种内存类型支持64GB的内存,每个memseg list支持8K的memseg, 如果是2MB的大页,那么就有32KB的memseg, 4个memseg list),下面是一个memseg list的内存管理示意图:

核心的代码调用如下:
rte_eal_memory_init
rte_eal_memseg_init #按hugepage type, numa节点建立memseg list,根据指定的基地址,调用mmap分配内存区
memseg_primary_init
eal_dynmem_memseg_lists_init
eal_memseg_list_init #初始化memseg list,给管理数组rte_farray分配堆空间并通过mmap映射到文件,数组元素类型为rte_memseg,数组末尾有一个01位图,用来标识每个元素的使用状态。
eal_memseg_list_alloc #初始化memseg list,在紧邻管理数组的末尾分配大页内存区
memseg映射
内存管理结构memseg list初始化后,进一步将memseg与其管理的大页建立关系,首先初始化每个memseg list的句柄(fd)列表,然后通过mmap将每个大页映射到文件,虚拟机地址保存在memseg->addr成员中,物理地址保存在memseg->iova成员中,示意图如下:
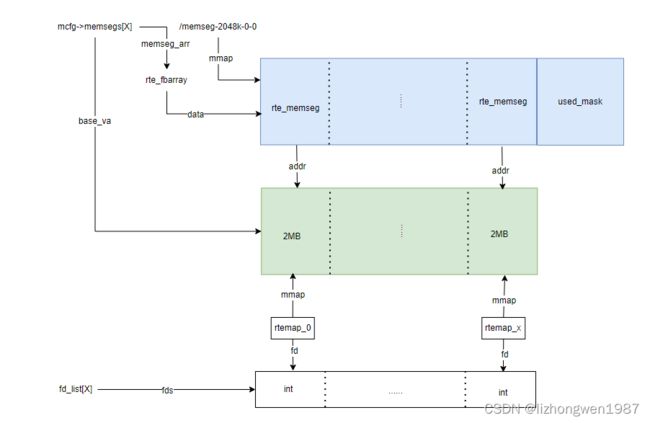
在linux上,虚拟地址的物理地址可以通过读取/proc/self/pagemap获取,具体方式请参考:rte_mem_virt2phy函数实现
1、打开文件
fd = open(“/proc/self/pagemap”, O_RDONLY);
2、获取虚拟页号VPN及文件偏移
virt_pfn = (unsigned long)virtaddr / page_size;
offset = sizeof(uint64_t) * virt_pfn
3、获取物理地址(0-54位为物理页号PFN)
retval = read(fd, &page, PFN_MASK_SIZE);
physaddr = ((page & 0x7fffffffffffffULL) * page_size)
+ ((unsigned long)virtaddr % page_size);
核心的代码调用如下:
rte_eal_memory_init
eal_memalloc_init #初始化映射句柄,按照memseg list初始化mmap映射的文件fd
rte_eal_hugepage_init #将memseg list中的每个memseg映射到mmap文件,设置memseg执行的大页物理地址
eal_dynmem_hugepage_init
heap初始化
dpdk先将内存按照大页的粒度,通过memseg list管理起来,但一页比较大,直接使用容易造成浪费,类似linux系统的内存管理,先将整个系统的内存用buddy分区管理,接着在此基础上构建了slab系统,最后提供kmalloc,kmem_cache等机制给内核应用使用;dpdk在memseg list的基础上,实现了malloc_heap来管理内存,最后提供rte_malloc,mempool等给dpdk应用使用,每个numa节点一个堆,通过双向链表链接各元素,每个堆有一个空闲链表数组,初始时由于每个memseg list都空闲,每个堆元素指向第一个memseg,并包含这个memseg list所有的memseg,连续空间很大,所以都挂接在最后的空闲链表上,每个堆元素有一个头,有三种状态:free,busy和pad(当元素分配后,剩余大小小于预设的值,就不会再加入空闲链表,而是填充掉)。初始堆的示意图如下:
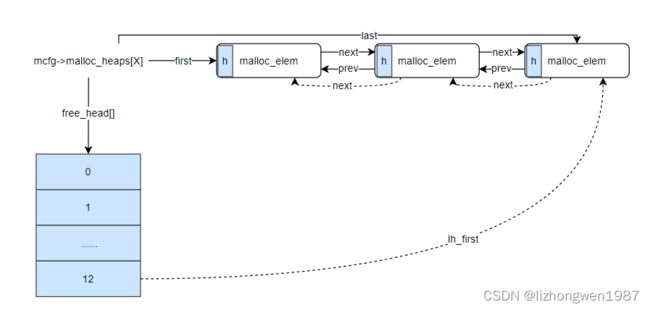
每个堆有一个包含13个元素的空闲链表数组,每个空闲链表管理元素大小范围如下:
free_head[0] - (0 , 2^8]
free_head[1] - (2^8 , 2^10]
free_head[2] - (2^10 ,2^12]
free_head[3] - (2^12, 2^14]
…
free_head[12] - (2^30, MAX_SIZE]
核心调用如下:
rte_eal_malloc_heap_init #初始化堆结构mcfg->malloc_heaps
rte_memseg_contig_walk #枚举memseg list,按numa节点添加内存到不同的heap,构建初始堆(每个堆元素malloc_heap指向memseg list中一段连续的内存)及初始化空闲链表数组free_lhead[13]
使用内存
通过memseg list(memseg)和malloc_heap,dpdk就将内存管理的底层机制搭建好了,就可以进行堆内存分配了:首先选择合适的堆,然后根据申请的内存大小,找到合适的空闲链表,枚举链表元素,找到合适的堆元素,最后分配空间
heap_alloc
find_suitable_element #一个循环,根据申请大小,找到首个合适空闲链表,
malloc_elem_can_hold #枚举空闲链表,寻找合适的堆元素
elem_start_pt
malloc_elem_alloc #分配空间(从末尾开始分配),将元素从空闲链表移除,设置堆元素状态为状态为busy,剩余元素空间重新加入合适的空闲链表
malloc_elem_free_list_remove
elem_start_pt
malloc_elem_free_list_insert
为方便内存的分配使用,dpdk进一步提供了rte_malloc,rte_mempool,rte_ring, rte_mbuf。spdk主要使用了rte_malloc,rte_mempool,rte_ring,它们的关系如下:

malloc的实现相对简单 - 直接操作heap分配内存,下面介绍下mempool,为了减少内存的碎片,将相同类型的对象用内存池来管理,mempool用环形缓冲区ring来保存内存对象。多核CPU访问同一个内存池或者同一个环形缓存区时,因为每次读写时都要进行Compare-and-Set操作来保证期间数据未被其他核心修改,所以存取效率较低为。为了减少多核访问冲突,mempool中实现了local_cache,在每个核上有一个(pre-core)。至于ring,根据生产者和消费者模型,dpdk实现了4种,每种都定义了自己的操作集,mempool,local cache, ring的关系示意图如下:
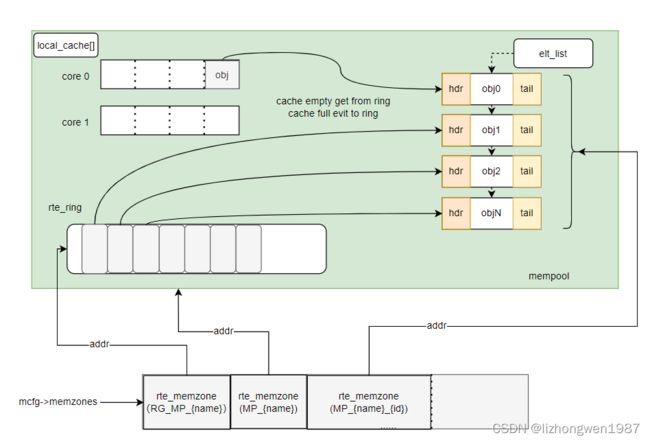
创建内存池的核心调用如下:
rte_mempool_create
rte_mempool_create_empty #初始化内存池对象rte_mempool,加入全局链表
rte_mempool_populate_default #初始化环形缓冲对象rte_ring,初始化对象内存,ring元素对象
mempool_ops_alloc_once #初始化ring,添加到全局列表
rte_memzone_reserve_aligned #分配堆空间,用于存储内存池对象
rte_mempool_populate_virt #在上述分配的堆空间,初始化内存池对象,添加对象到ring,元素列表elt_list
本文从宏观层面对dpdk中的内存管理机制,原理做了简单介绍,希望对各位读者理解dpdk内存管理有些帮助。如果你对linux的内核内存管理有所了解(buddy,slab,kmalloc,kmem_cache, pre-cpu cache),那么对dpdk的内存管理就不会陌生,dpdk本就是bypass kernel的数据面开发库,它在内存管理,驱动实现方面的思想、机制和linux kernel有可比性