K8S exporter应用
背景:
前面对远程http服务的拨测体验简单拨测了一下http服务,最近偶遇了一下服务到期默认进入回收站,服务连不上redis数据库的问题(腾讯云报警通知服务现在不能保证优先队列,现在会滞后性)。由于日志业务上报问题,业务的错误日志没有上报给我,程序自己收集的,这就造成了滞后性。现在了想把云内资源都监控起来,当然了我不想使用所谓的云监控!下面搞一下redis elastic mysql mongo等服务的exporter黑盒监控!
redis 监控
面临的问题:
- exporter如何监控多个实例?
- REDIS带账号密码,并且账号密码不同,也有无密码实例!
解决方案:
- https://codeantenna.com/a/xgXu2Z3xXk 一个exporter对应一个redis实例
- https://github.com/oliver006/redis_exporter 仓库有多实例的方案
- https://github.com/starsliao/ConsulManager 基于Consul服务自动注册发现
- Redis Exporter批量监控Redis Server 基于Apollo进行管理
Redis_exporter 是较常用redis监控解决方案,在早期的redis_exporter 版本中,并不能支持一个 redis_exporter 实例监控多个 Redis 实例方式,这样造成 exporter 实例的数量较多,难以维护和管理。但在后续的版本中已经解决了此问题。在 metrics 的暴漏形式上也有所改变:
# old
http://redis_exporter:9121/metrics
# now
http://redis_exporter:9121/scrape?target=redis://redis:6379
这种改变一定程度缓解了 redis_exporter实例过多,维护不易管理的现象。当然了顺便吐槽一下redis_exporter这个项目:

带有所谓政治色彩,个人很是不喜欢!
部署redis_exporter
我这里还是老老实实第二种方式了,基本参照:redis_exporter 部署配置多实例,部署一个redis exporter监控所有的Redis实例:
cat redis-exporter.yaml
---
apiVersion: v1
data:
redis_passwd.json: |
{
"redis://172.0.0.16:6379":"xxxx",
"redis://172.0.0.7:6379":"xxxxxx",
"redis://172.0.0.8:6379":"xxxxxx",
"redis://172.0.0.9:6379":"xxxxxx",
"redis://172.0.0.13:6379":"xxxxxx",
"redis://172.0.0.28:6379":"xxxxxx",
"redis://172.0.0.23:6379":"xxxxxx",
"redis://172.0.0.39:6379":"xxxxxx",
"redis://172.0.0.44:6379":"xxxxxx",
"redis://172.0.4.12:6379":"xxxxxx",
"redis://172.0.0.21:6379":"xxxxxx",
"redis://172.0.4.3:6379":"xxxxxxxx",
"redis://172.0.0.70:6379":"xxxxxx",
"redis://172.0.4.29:6379":"",
"redis://172.0.2.5:6379":"xxxxxx",
"redis://172.0.0.130:6379":"xxxxxx",
"redis://172.0.0.131:6379":"xxxxxx",
"redis://172.0.4.5:6379":"xxxxxx",
"redis://172.0.0.113:6379":"xxxxxx",
"redis://172.0.0.82:6379":"xxxxxx",
"redis://172.0.0.31:6379":"",
"redis://172.0.5.6:6379":"xxxxxx",
"redis://172.0.4.6:6379":"xxxxxx",
"redis://172.0.0.56:6379":"xxxxxx",
"redis://172.0.4.66:6379":"xxxxxx",
"redis://172.0.4.138:6379":"xxxxxx",
"redis://172.0.4.104:6379":"",
"redis://172.0.4.65:6379":"xxxxxx",
"redis://172.0.4.82:6379":"xxxxxx",
"redis://172.0.4.78:6379":"xxxxxx",
"redis://172.0.4.108:6379":"xxxxxx"
}
kind: ConfigMap
metadata:
name: redis-passwd-cm
namespace: monitoring
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: redis-exporter
name: redis-exporter
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: redis-exporter
template:
metadata:
labels:
app: redis-exporter
spec:
containers:
- name: redis-exporter
image: oliver006/redis_exporter:latest
env:
- name: TZ
value: "Asia/Shanghai"
args:
- "-redis.password-file=/opt/redis_passwd.json"
resources:
requests:
cpu: 100m
memory: 100Mi
ports:
- name: http-metrics
containerPort: 9121
protocol: TCP
volumeMounts:
- name: redis-passwd-conf-map
mountPath: "/opt"
volumes:
- name: redis-passwd-conf-map
configMap:
name: redis-passwd-cm
---
apiVersion: v1
kind: Service
metadata:
labels:
app: redis-exporter
name: redis-exporter
namespace: monitoring
spec:
ports:
- name: http-metirc
protocol: TCP
port: 9121
targetPort: 9121
selector:
app: redis-exporter
apply 创建redis-exporter。等的pod running:
kubectl apply -f redis-exporter.yaml
kubectl get pods -n monitoring|grep redis

修改Prometheus 自动发现配置:
我kubernetes集群为tke,偷懒尝试了一下修改prometheus-additional secret:
cat prometheus-additional.yaml
- job_name: 'kubernetes-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'blackbox'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets:
- https://layamarket.layabox.com
- https://layamarket.masteropen.layabox.com
- https://master-gameucenter.layabox.com
- https://master-metaspace-maker.layaverse.com
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 172.22.255.22:19115
- job_name: 'redis-exporter'
metrics_path: /scrape
scrape_interval: '15s'
scrape_timeout: '15s'
scheme: 'http'
static_configs:
- targets:
- redis://172.0.0.16:6379
- redis://172.0.0.7:6379
- redis://172.0.0.8:6379
- redis://172.0.0.9:6379
- redis://172.0.0.13:6379
- redis://172.0.0.28:6379
- redis://172.0.0.23:6379
- redis://172.0.0.39:6379
- redis://172.0.0.44:6379
- redis://172.0.4.12:6379
- redis://172.0.0.21:6379
- redis://172.0.4.3:6379
- redis://172.0.0.70:6379
- redis://172.0.4.29:6379
- redis://172.0.2.5:6379
- redis://172.0.0.130:6379
- redis://172.0.0.131:6379
- redis://172.0.4.5:6379
- redis://172.0.0.113:6379
- redis://172.0.0.82:6379
- redis://172.0.0.31:6379
- redis://172.0.5.6:6379
- redis://172.0.4.6:6379
- redis://172.0.0.56:6379
- redis://172.0.4.66:6379
- redis://172.0.4.138:6379
- redis://172.0.4.104:6379
- redis://172.0.4.65:6379
- redis://172.0.4.82:6379
- redis://172.0.4.78:6379
- redis://172.0.4.108:6379
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: redis-exporter.monitoring.svc:9121
保持默认,添加了redis自动发现的job!
手动在这里修改了:
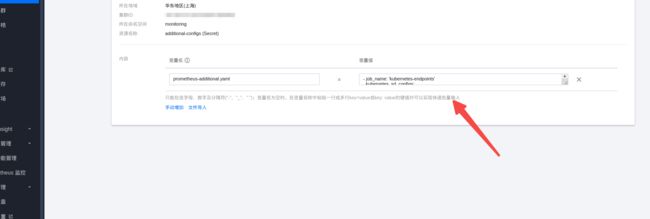
当然了正常的流程方式是这样:
kubectl delete secret additional-configs -n monitoring
kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring
也可以yaml base64修改secret中的内容…这东西看个人玩法了!
重载prometheus配置:
查看prometheus pod ip:
kubectl get pods -n monitoring -o wide|grep prometh

reload 加载服务:
root@ap-shanghai-k8s-master-1:~/prometh/redis# curl -X POST http://172.22.2.121:9090/-/reload
root@ap-shanghai-k8s-master-1:~/prometh/redis# curl -X POST http://172.22.3.51:9090/-/reload

登陆prometheus 控制台查看metrics:
点击prometheus控制台,查看Status Targets:
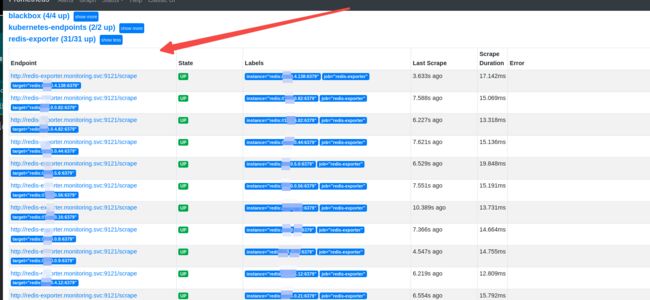
redis target已经注册了:
Prometheus 这里搜索框输入redis有很多指标可以补全:
随手点一个:
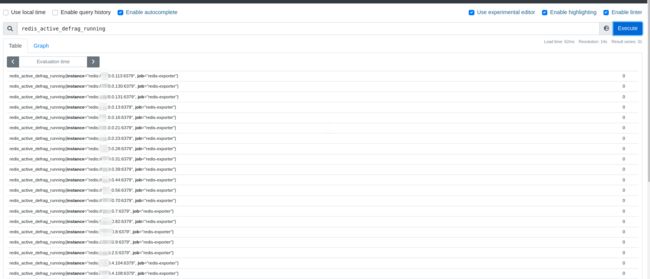
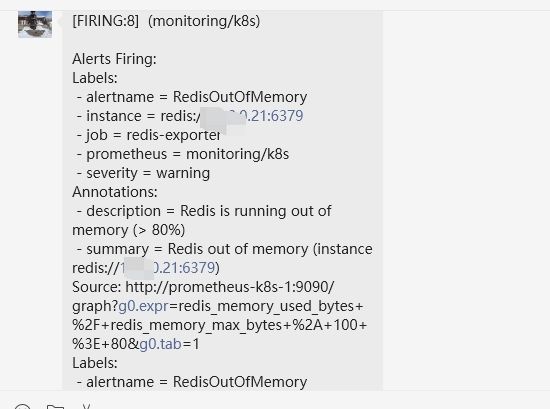
报警alert:
简单做了一个内存占用超80的报警alert:
cat redis-alert.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: redis-exporter-rule
namespace: monitoring
spec:
groups:
- name: redis-alert
rules:
- alert: RedisDown
annotations:
description: |-
Redis instance is down
VALUE = {{ $value }}
LABELS: {{ $labels }}
summary: Redis down (instance {{ $labels.instance }})
expr: redis_up == 0
for: 5m
labels:
severity: critical
- alert: RedisOutOfMemory
annotations:
description: |-
Redis is running out of memory (> 80%)
summary: Redis out of memory (instance {{ $labels.instance }})
expr: redis_memory_used_bytes / redis_memory_max_bytes * 100 > 80
for: 5m
labels:
severity: warning
- alert: RedisTooManyConnections
annotations:
description: |-
Redis instance has too many connections
VALUE = {{ $value }}
LABELS: {{ $labels }}
summary: Redis too many connections (instance {{ $labels.instance }})
expr: redis_connected_clients > 100
for: 5m
labels:
severity: warning
kubectl apply -f redis-alert.yaml
这里稍微等一下,prometheus实例加载配置文件:
kubectl logs -f prometheus-k8s-1 -n monitoring
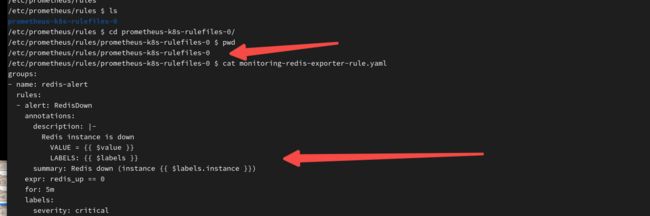
也可以进入pod确认是否配置同步过来:
kubectl exec -it prometheus-k8s-0 sh -n monitoring
cd /etc/prometheus/rules/prometheus-k8s-rulefiles-0
cat monitoring-redis-exporter-rule.yaml
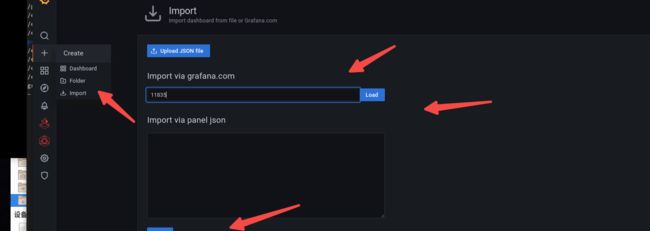
grafana监控:
我用的这个模板:https://grafana.com/grafana/dashboards/11835-redis-dashboard-for-prometheus-redis-exporter-helm-stable-redis-ha/
打开grafan控制台,点击左侧边栏**+**号 **import **11835模板 load:
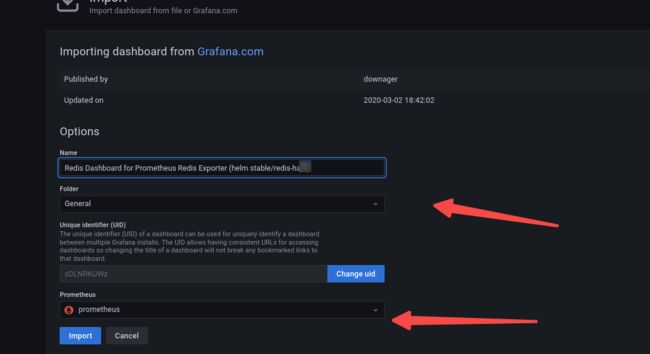
保持原有name, prometheus 数据库选择prometheus实例,Import:
正常是这样的:
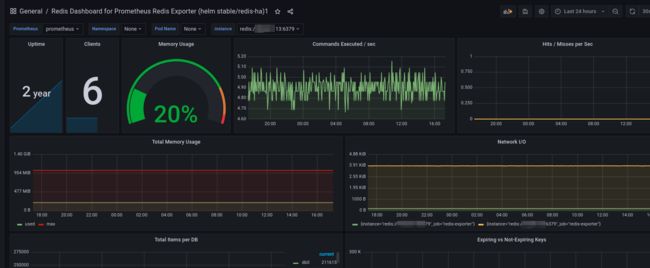
Variables 修改了一下:
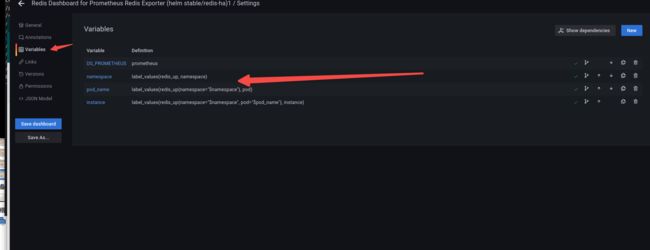
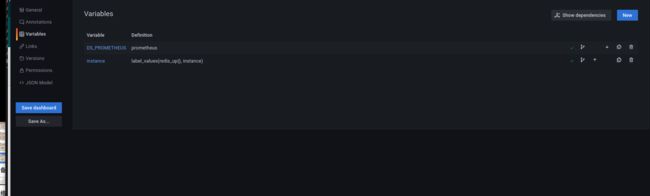
当然了只是为了个人看着习惯:
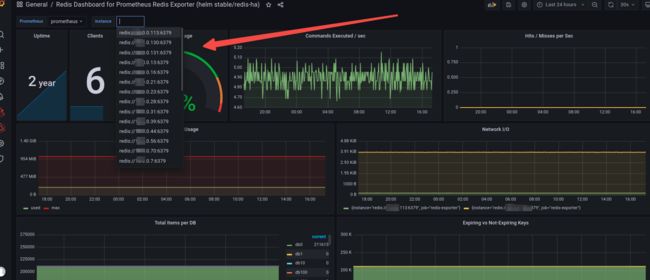
可能出现的问题:redis exporter 针对 redis2.8以及之前版本 grafana控制台 **Memory Usage 选项可能无法显示,**我默默把redis版本都进行升级了一下…
Mysql监控:
mysql授权
前提条件: 容器集群与mysql在统一VPC ,上面的redis实验环境也是。文中所有实例都在统一VPC环境下!
由于数据库是云数据库,这里演示选择了两个实例:
10.0.6.67
10.0.5.9

可以一下这样完成对mysql的监控账号授权:云联网
CREATE USER 'exporter'@'ip' IDENTIFIED BY 'XXXXXXXX' WITH MAX_USER_CONNECTIONS 3;
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'ip';
由于我这里是云数据库,我直接点击云数据库创建账号并授权:
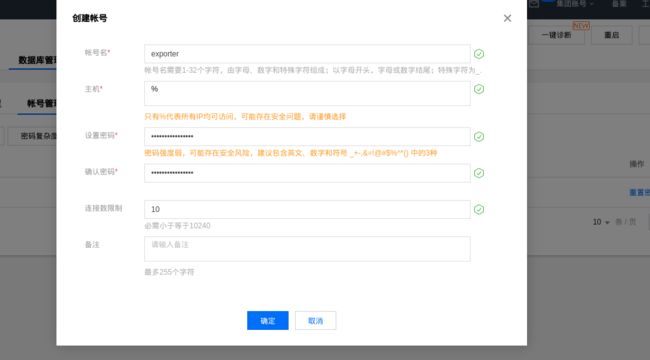
注意:主机信任这里偷懒了%,个人应该根据实际生产环境来设置!
授权:
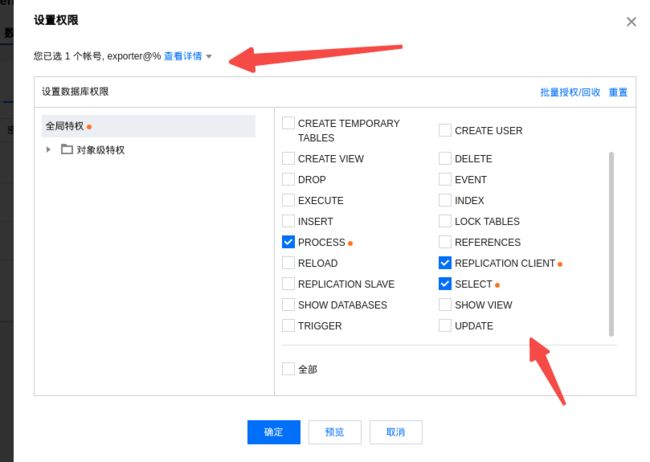
注: 控制台并没有新建一个账号直接绑定两个实例的快速方式。两个实例都进行了账号创建以及授权!
创建mysql_exporter
cat mysql-exporter.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: mysql-exporter
name: mysql-exporter
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: mysql-exporter
template:
metadata:
labels:
app: mysql-exporter
spec:
containers:
- name: mysql-exporter
image: prom/mysqld-exporter:latest
command:
- /bin/mysqld_exporter
args:
- --collect.info_schema.innodb_metrics
- --collect.info_schema.tables
- --collect.info_schema.processlist
- --collect.info_schema.tables.databases=*
- --mysqld.username=exporter
- --collect.mysql.user.privileges
- --collect.mysql.user
- --collect.global_status
- --collect.global_variables
- --collect.slave_status
- --collect.perf_schema.indexiowaits
- --collect.perf_schema.tablelocks
- --collect.perf_schema.eventsstatements
- --collect.perf_schema.eventswaits
- --collect.binlog_size
- --collect.perf_schema.tableiowaits
- --collect.perf_schema.replication_group_members
- --collect.perf_schema.replication_group_member_stats
- --collect.info_schema.userstats
- --collect.info_schema.clientstats
- --collect.perf_schema.file_events
- --collect.perf_schema.file_instances
- --collect.perf_schema.memory_events
- --collect.info_schema.innodb_cmpmem
- --collect.info_schema.query_response_time
- --collect.info_schema.tablestats
- --collect.info_schema.schemastats
env:
- name: TZ
value: "Asia/Shanghai"
- name: MYSQLD_EXPORTER_PASSWORD
value: "xxxxxx"
resources:
requests:
cpu: 100m
memory: 100Mi
ports:
- name: http-metrics
containerPort: 9104
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
labels:
app: mysql-exporter
name: mysql-exporter
namespace: monitoring
spec:
ports:
- name: http-metirc
protocol: TCP
port: 9104
targetPort: 9104
selector:
app: mysql-exporter
注:MYSQLD_EXPORTER_PASSWORD 为创建账号相对应密码。mysqld.username=exporter为对应账号。其他–collect参照文档:https://github.com/prometheus/mysqld_exporter/tree/main 。apply创建mysql-exporter:
kubectl apply -f mysql-exporter.yaml
kubectl get pods -n monitoring |grep mysql

注意:这里可能会出现一些报错,基本就是下面这样子的可以在mysql-exporter.yaml找到对应–collect 参数进行修改。基本是版本对应或者其他问题!
kubectl logs -f mysql-exporter-xxxx -n monitoring查看:
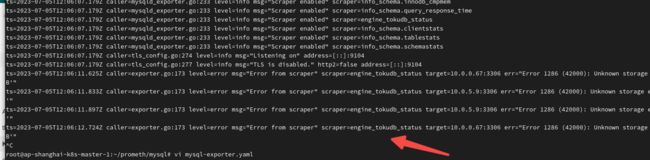
修改Prometheus 自动发现配置,并重载配置:
additional-configs添加如下配置,参照上一步中redis的类似配置:
- job_name: mysql # To get metrics about the mysql exporter’s targets'
scrape_interval: 30s
metrics_path: /probe
static_configs:
- targets:
- 10.0.0.67:3306
- 10.0.5.9:3306
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
# The mysqld_exporter host:port
replacement: mysql-exporter.monitoring.svc:9104
重载配置参照上面redis的相关设置:
curl -X POST http://172.22.3.51:9090/-/reload
curl -X POST http://172.22.2.51:9090/-/reload
登陆prometheus 控制台查看metrics:
点击控制台Status Targets:
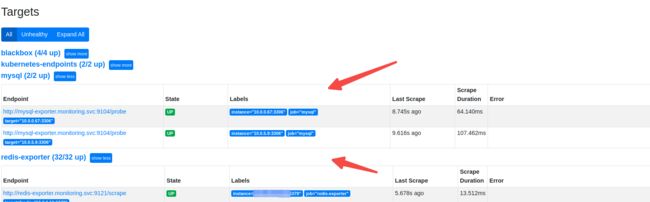
Prometheus 这里搜索框输入mysql有很多指标可以补全:
报警alert:
突然不知道拿什么来做报警指标了…为什么呢?云数据库获取不了存储这些阿?
正常的数据库 exporter监控的 mysql_exporter 是跟node_exporter一起使用的,这样可以获取内存硬盘使用的参照值,百分比,然后进行报警。这是为比较喜欢看到的。这里佛系找个参数体验一下报警吧!比如实例运行状态,连接数?这实例连接数也很小,就演示一下:
以mysql_global_status_threads_connected为例:
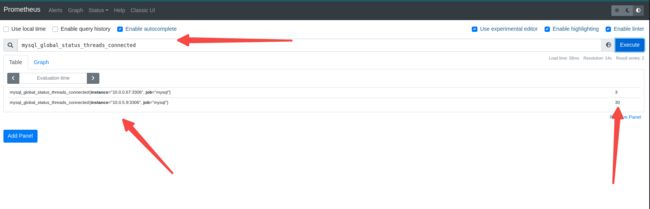
cat mysql-alert.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: mysql-exporter-rule
namespace: monitoring
spec:
groups:
- name: mysql-alert
rules:
- alert: MySQL Status # 告警名称
expr: up == 0
for: 5s # 满足告警条件持续时间多久后,才会发送告警
annotations: # 解析项,详细解释告警信息
summary: "{{$labels.instance}}: MySQL has stop !!!"
value: "{{$value}}"
alertname: "MySQL数据库停止运行"
description: "检测MySQL数据库运行状态"
message: 当前数据库实例{{$labels.instance}}已经停止运行,请及时处理
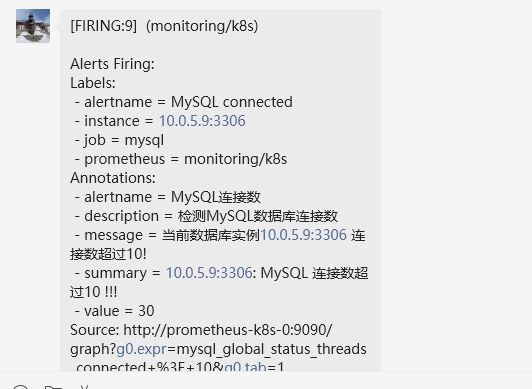
- alert: MySQL connected # 告警名称
expr: mysql_global_status_threads_connected > 10
for: 5s # 满足告警条件持续时间多久后,才会发送告警
annotations: # 解析项,详细解释告警信息
summary: "{{$labels.instance}}: MySQL 连接数超过10 !!!"
value: "{{$value}}"
alertname: "MySQL连接数"
description: "检测MySQL数据库连接数"
message: 当前数据库实例{{$labels.instance}} 连接数超过10!
注意:这里其实是个坑**up == 0 ,其实应该mysql_up==0,**否则会收到很多 ==0的报警在这个alert下!
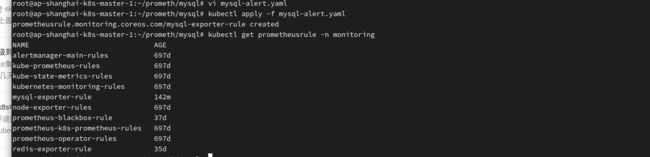
apply创建alert:
kubectl apply -f mysql-alert.yaml
kubectl get prometheusrule -n monitoring
grafana监控:
https://grafana.com/grafana/dashboards/搜索mysql 模板:
直接默认第一个了7362模板其实应该:
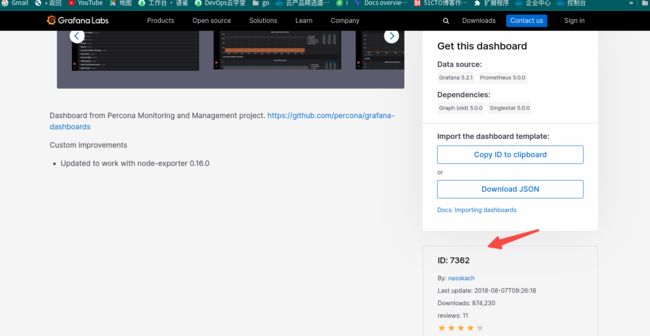
grafana import 7362模板:
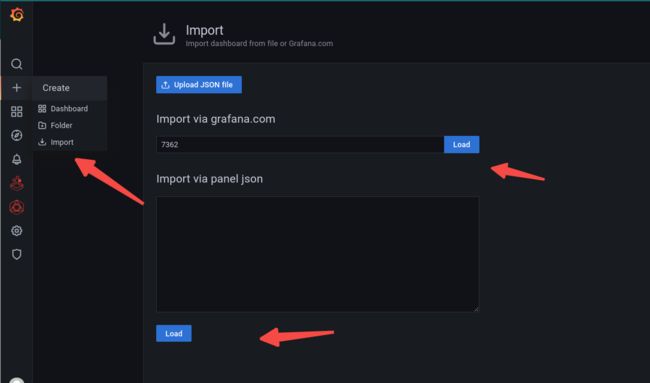
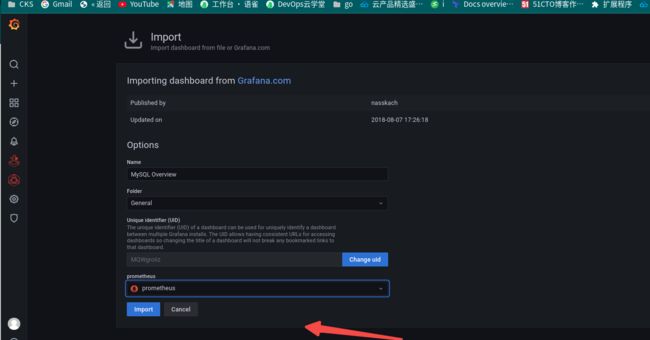
目测是这样的:
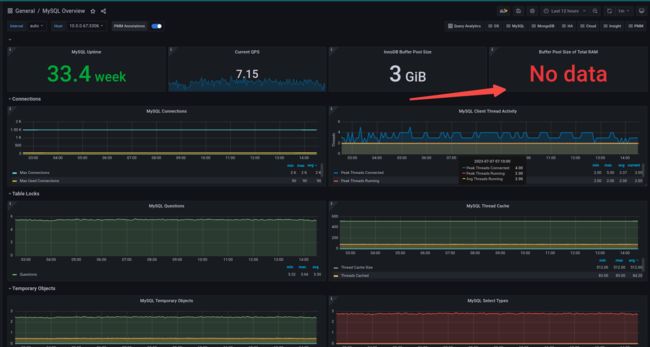
Buffer Pool Size of Total RAM没有数据,也没有办法:毕竟针对的是搭建在node上面的exporter跟node指标一起使用的:
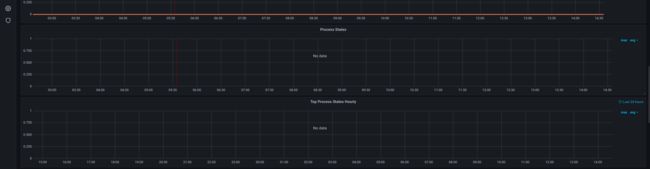
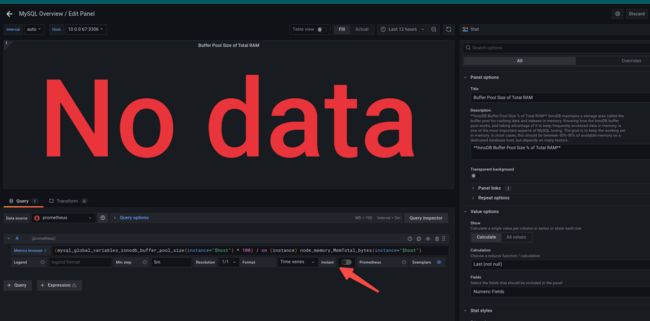 但是Process这里应该是可以显示的?
但是Process这里应该是可以显示的?
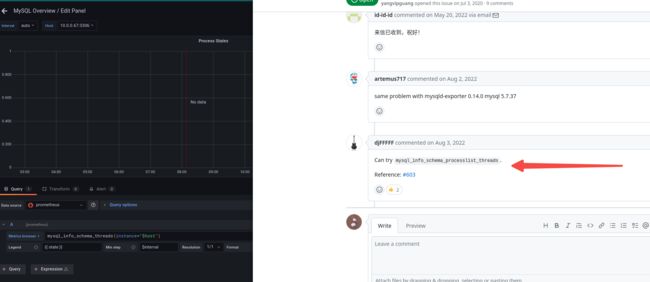
edit图表参照https://github.com/prometheus/mysqld_exporter/issues/487 修改
mysql_info_schema_threads 为mysql_info_schema_processlist_threads :
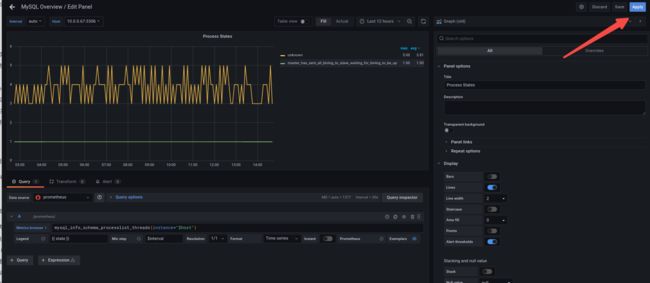
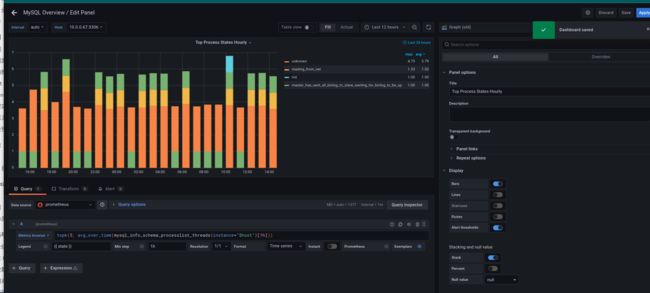
注意save保存模板!
mysql 基本就先这样了有所制约,不能实现自己想要实现的完美展示!
Mongodb监控
mongodb个人不是多么熟悉,网上也没有多实例的例子,这里就简单演示一下单实例的监控流程!直接参照腾讯云文档:MongoDB Exporter 接入
正式第一步应该是创建Mongodb监控可读账号,参照这里的流程:
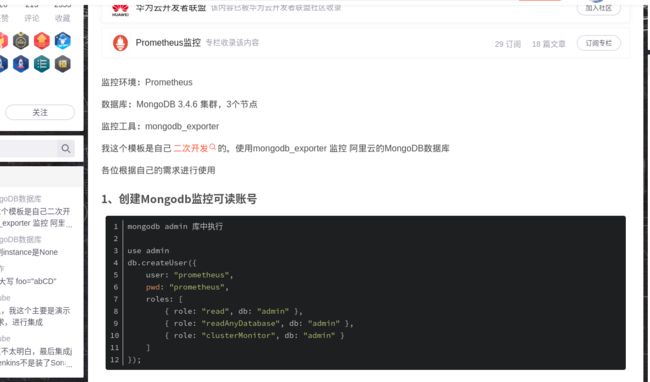
由于我这里只是演示,直接用了云mongo数据库的管理员账号密码。这里在生产环境是不推荐的!
使用 Secret 管理 MongoDB 连接串
cat mongo-secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: mongodb-secret-develop
namespace: monitoring
type: Opaque
stringData:
datasource: "mongodb://mongouser:[email protected]:27017,10.0.4.103:27017,10.0.4.85:27017/admin?ssl=false" # 对应连接URI
apply 创建mongo secret:
kubectl apply -f mongo-secret.yaml

部署 MongoDB Exporter
cat mongo-exporter.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: mongodb-exporter # 根据业务需要调整成对应的名称,建议加上 MongoDB 实例的信息
name: mongodb-exporter # 根据业务需要调整成对应的名称,建议加上 MongoDB 实例的信息
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
k8s-app: mongodb-exporter # 根据业务需要调整成对应的名称,建议加上 MongoDB 实例的信息
template:
metadata:
labels:
k8s-app: mongodb-exporter # 根据业务需要调整成对应的名称,建议加上 MongoDB 实例的信息
spec:
containers:
- args:
- --collect-all
- --compatible-mode
- --no-mongodb.direct-connect
env:
- name: MONGODB_URI
valueFrom:
secretKeyRef:
name: mongodb-secret-develop
key: datasource
image: percona/mongodb_exporter:0.39.0
imagePullPolicy: IfNotPresent
name: mongodb-exporter
ports:
- containerPort: 9216
name: http-metirc # 这个名称在配置抓取任务的时候需要
securityContext:
privileged: false
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
imagePullSecrets:
- name: qcloudregistrykey
restartPolicy: Always
schedulerName: default-scheduler
securityContext: { }
terminationGracePeriodSeconds: 30
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: mongodb-exporter
name: mongodb-exporter
namespace: monitoring
spec:
type: ClusterIP
ports:
- name: http-metirc
port: 9216
protocol: TCP
targetPort: 9216
selector:
k8s-app: mongodb-exporter
apply 创建mongo-exporter:
kubectl apply -f mongo-exporter.yaml

root@ap-shanghai-k8s-master-1:~/prometh/mongo# kubectl get svc -n monitoring|grep mongo
mongo-exporter ClusterIP 172.22.253.214 9206/TCP 25s
root@ap-shanghai-k8s-master-1:~/prometh/mongo# kubectl get pods -n monitoring|grep mongo
mongodb-exporter-7b7689dfc4-cdqsr 1/1 Running 0 6m47s

修改Prometheus 自动发现配置:
additional-configs添加如下配置,参照上一步中redis的类似配置:
- job_name: 'mongo-exporter'
scrape_interval: 60s
metrics_path: /metrics
static_configs:
- targets:
- 10.0.4.88:27017
- 10.0.4.103:27017
- 10.0.4.85:27017
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: mongodb-exporter.monitoring.svc:9216
重载prometheus配置:

登陆prometheus 控制台查看metrics:
点击登陆prometheus控制台查看Status Targets:
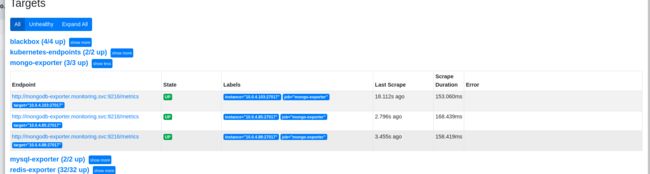
报警alert:
mongo的监控参数不太熟悉。google搜到了一个网站:
mongodb_exporter 参考借用了一下:
mongodb_up 服务状态
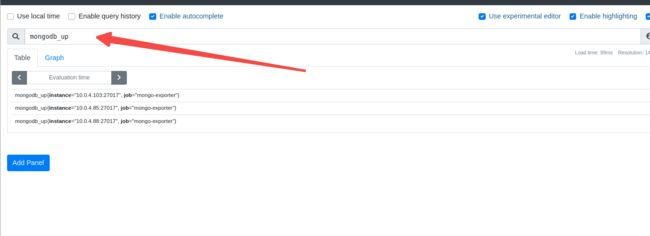
**mongodb_ss_connections{conn_type=“current”} ** 客户端连接数
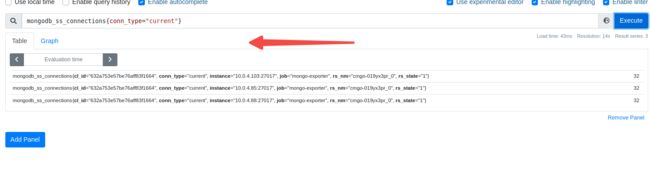
cat mongodb-alert.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: mongodb-exporter-rule
namespace: monitoring
spec:
groups:
- name: mongodb-alert
rules:
- alert: mongodb Status # 告警名称
expr: mongodb_up == 0
for: 5s # 满足告警条件持续时间多久后,才会发送告警
annotations: # 解析项,详细解释告警信息
summary: "{{$labels.instance}}: mongodb has stop !!!"
value: "{{$value}}"
alertname: "mongodb数据库停止运行"
description: "检测mongodb数据库运行状态"
message: 当前数据库实例{{$labels.instance}}已经停止运行,请及时处理
- alert: mongodb connected # 告警名称
expr: mongodb_ss_connections{conn_type="current"} > 10
for: 5s # 满足告警条件持续时间多久后,才会发送告警
annotations: # 解析项,详细解释告警信息
summary: "{{$labels.instance}}: mongodb 连接数超过10 !!!"
value: "{{$value}}"
alertname: "mongodb连接数"
description: "检测mongodb数据库连接数"
message: 当前数据库实例{{$labels.instance}} 连接数超过10!
kubectl apply -f mongodb-alert.yaml
kubectl get prometheusrule -n monitoring
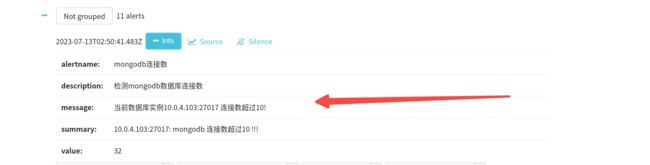
报警会是必出的,因为我这连接数肯定三大于10的!就直接到alertmanager上面看一眼了:
grafana监控
grafana官方网站搜索mongodb模板,最终选择了14997模板:
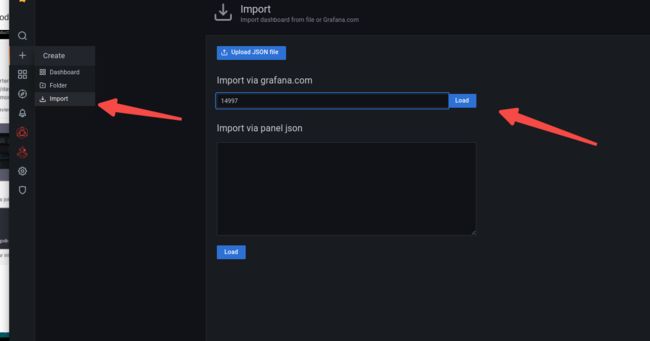
grafana导入模板:
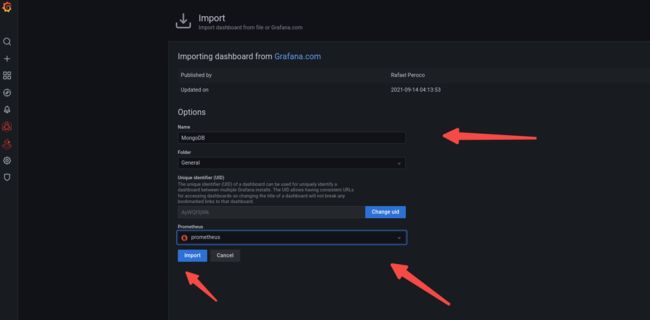
import配置:
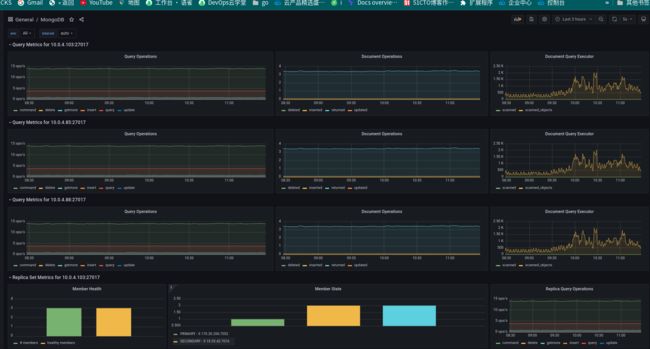
监控展示页面如下:
当然了还有许多模板可以借鉴参考:
忘了模板ID了…
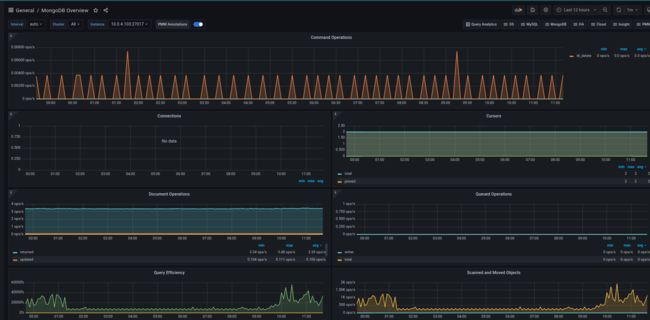
不能正常显示的图表,可以自定义去修改查看参数!
Elastic监控
elasticsearch也没有发现可以单个exporter监控多个elasticsearch的方法,也跟风问了一下chatgpt:
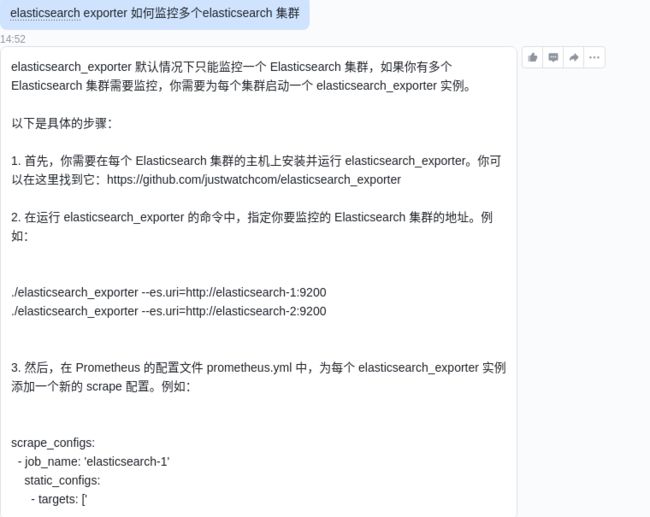
老老实实的单实例体验一下吧:
部署elasticsearch_exporter
cat elasticsearch-exporter.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: elasticsearch-exporter # 根据业务需要调整成对应的名称,建议加上 MongoDB 实例的信息
name: elasticsearch-exporter # 根据业务需要调整成对应的名称,建议加上 MongoDB 实例的信息
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
k8s-app: elasticsearch-exporter # 根据业务需要调整成对应的名称,建议加上 MongoDB 实例的信息
template:
metadata:
labels:
k8s-app: elasticsearch-exporter # 根据业务需要调整成对应的名称,建议加上 MongoDB 实例的信息
spec:
containers:
- args:
- '--es.uri=http://elastic:[email protected]:9200'
- '--es.all'
- '--es.indices'
- '--es.indices_settings'
- '--es.indices_mappings'
- '--es.shards'
- '--es.snapshots'
- '--es.timeout=30s'
image: quay.io/prometheuscommunity/elasticsearch-exporter:latest
imagePullPolicy: IfNotPresent
name: elasticsearch-exporter
ports:
- containerPort: 9114
name: http-metirc # 这个名称在配置抓取任务的时候需要
securityContext:
privileged: false
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
imagePullSecrets:
- name: qcloudregistrykey
restartPolicy: Always
schedulerName: default-scheduler
securityContext: { }
terminationGracePeriodSeconds: 30
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: elasticsearch-exporter
name: elasticsearch-exporter
namespace: monitoring
spec:
type: ClusterIP
ports:
- name: http-metirc
port: 9114
protocol: TCP
targetPort: 9114
selector:
k8s-app: elasticsearch-exporter
apply创建 elasticsearch exporter:Process
kubectl apply -f elasticsearch-exporter.yaml
等待服务running:
kubectl get pods -n monitoring|grep elas
kubectl get svc -n monitoring|grep elas

测试curl 一下metics:
curl 172.22.253.106:9114/metrics
修改Prometheus 自动发现配置:
additional-configs添加如下配置,参照上一步中redis的类似配置:
- job_name: 'elasticsearch-exporter' # To get metrics about the mysql exporter’s targets'
scrape_interval: 60s
metrics_path: /metrics
static_configs:
- targets:
- 10.0.4.145:9200
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
# The mysqld_exporter host:port
replacement: elasticsearch-exporter.monitoring.svc:9114
prometheus 重新加载配置:
curl -X POST http://172.22.3.15:9090/-/reload
curl -X POST http://172.22.1.204:9090/-/reload

登陆prometheus 控制台查看metrics:
登陆prometheus 查看Targets:

查看出现了各种elastic参数指标:
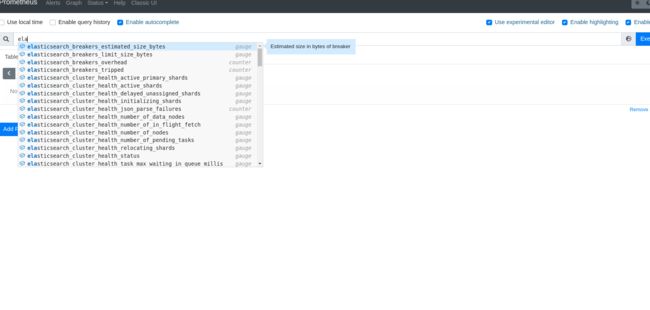
报警alert:
告警规则随手抄了一个:
参照:k8s容器中通过Prometheus Operator部署Elasticsearch Exporter监控Elasticsearch
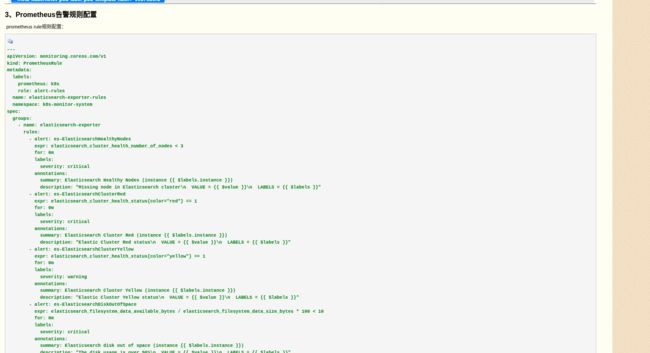
只修改了一下namespace:
---
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: es-cluster-rules
namespace: monitoring
spec:
groups:
- name: elasticsearch-exporter
rules:
- alert: es-ElasticsearchHealthyNodes
expr: elasticsearch_cluster_health_number_of_nodes < 3
for: 0m
labels:
severity: critical
annotations:
summary: Elasticsearch Healthy Nodes (instance {{ $labels.instance }})
description: "Missing node in Elasticsearch cluster\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: es-ElasticsearchClusterRed
expr: elasticsearch_cluster_health_status{color="red"} == 1
for: 0m
labels:
severity: critical
annotations:
summary: Elasticsearch Cluster Red (instance {{ $labels.instance }})
description: "Elastic Cluster Red status\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: es-ElasticsearchClusterYellow
expr: elasticsearch_cluster_health_status{color="yellow"} == 1
for: 0m
labels:
severity: warning
annotations:
summary: Elasticsearch Cluster Yellow (instance {{ $labels.instance }})
description: "Elastic Cluster Yellow status\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: es-ElasticsearchDiskOutOfSpace
expr: elasticsearch_filesystem_data_available_bytes / elasticsearch_filesystem_data_size_bytes * 100 < 10
for: 0m
labels:
severity: critical
annotations:
summary: Elasticsearch disk out of space (instance {{ $labels.instance }})
description: "The disk usage is over 90%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: es-ElasticsearchHeapUsageTooHigh
expr: (elasticsearch_jvm_memory_used_bytes{area="heap"} / elasticsearch_jvm_memory_max_bytes{area="heap"}) * 100 > 90
for: 2m
labels:
severity: critical
annotations:
summary: Elasticsearch Heap Usage Too High (instance {{ $labels.instance }})
description: "The heap usage is over 90%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: es-ElasticsearchHealthyDataNodes
expr: elasticsearch_cluster_health_number_of_data_nodes < 3
for: 0m
labels:
severity: critical
annotations:
summary: Elasticsearch Healthy Data Nodes (instance {{ $labels.instance }})
description: "Missing data node in Elasticsearch cluster\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
为了体现报警,elasticsearch_cluster_health_number_of_nodes < 3 。我这里节点只有2个(测试环境,腾讯云elastic服务)当然了这里应该根据实际情况编写报警规则!我这里就是一个2节点集群!
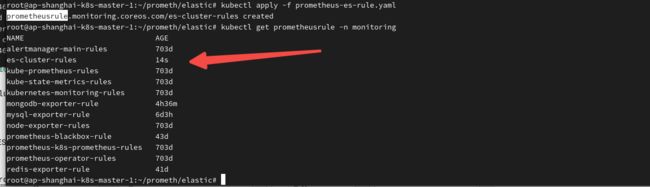
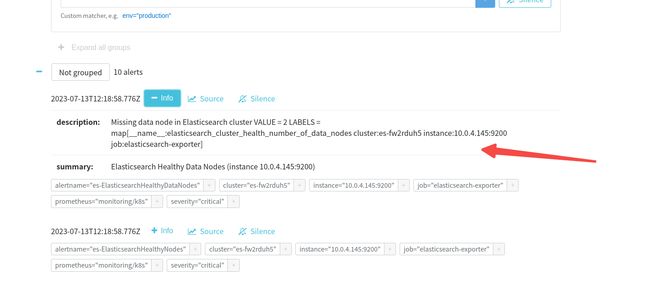
grafana监控:
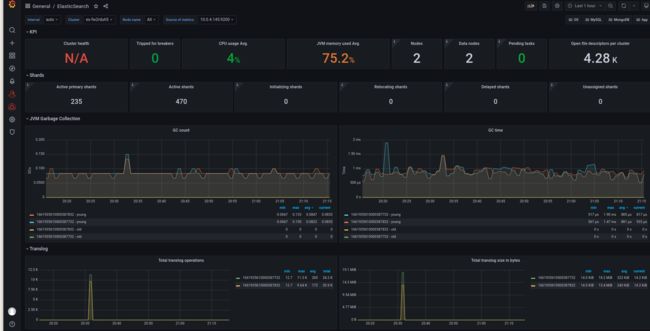
7752模板导入一下会看着舒服一点:
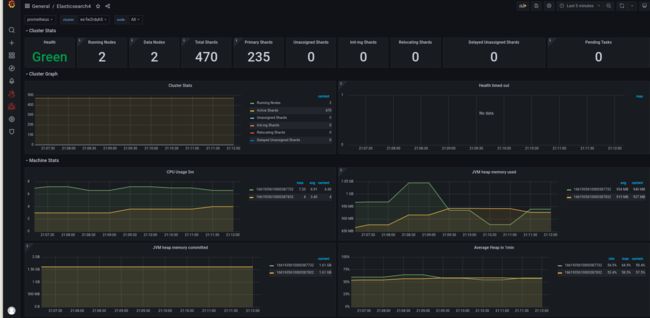
exporter就先到这里了…
总结
- exporter对于云服务的监控还是很不完美,毕竟每家都有自己的护城河。
- 自动发现多实例这样的借助consul 阿波罗这样的会简单一些。
- aws可以借助cloudwatch这样的导入模板到grafana中。
- 还是希望能将类似腾讯云云监控中的这些指标采集到prometheus中,但是这过程应该还很遥远
- grafana出图 prometheus查询语法这些东西有时间的好好研究一下。
- 报警有必要进行分级别,收敛配置一下!