在shell中使用hiveSQL的注意事项
概述
hive是数据分析人员常用的工具之一。实际工作中,使用hive基本都是在linux shell环境下。运行hiveSQL的方式有以下几种。
1.hive 交互式命令行
即在shell环境下直接使用hive命令,当屏幕下方出现hive>时,就进入了hive的环境,如下图所示。在>后面就可以写hiveSQL查询我们需要的数据,注意语句之间用英文分号隔开。通常适合于语句较短,需要快速查询或者对大段SQL进行语法调试的情况。
![]()
2.hive -e方式
hive -e "待执行sql"。这种方式允许我们在引号中写入需要执行的SQL语句。通常适合于语句较长的情况。这种方式也是在需要进行任务调度时采用的最直接方式,此时可以结合shell定义可变参数(如日期),再结合调度系统就可以实现脚本自动化。
3.hive -f方式
这种方式类似于前一种,区别把待执行sql预先写入到一个文件,采用hive -f sql文件来执行。在任务调度时也可以采用,但由于需要跨文件处理,相对而言,hive -e更为直接。
以上我们总结了hiveSQL常见的运行方式。下面再来看一些实际使用时一些可能会忽略的点。为方便讨论,我们构造以下数据,测试表名为test_0102。

hive -e遇到竖线分割时,要加多个转义符
先来看交互式命令行的方式。
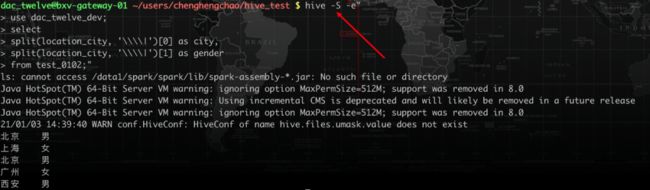
假设我们要取出每个用户的城市和性别,使用split函数,可能会采用以下写法:
select
split(location_city, '|')[0] as city,
split(location_city, '|')[1] as gender
from test_0102;
结果如下图所示。
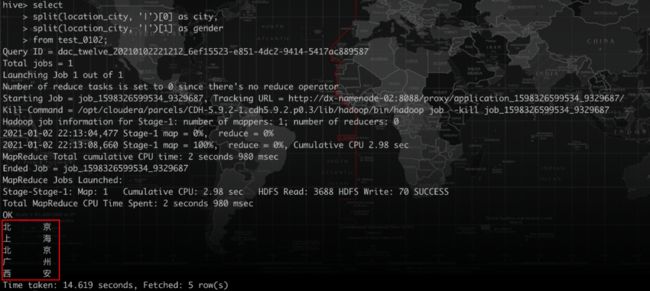
显然结果不是我们想要的,这是因为竖线比较特殊。我们加上转义符再来看下。
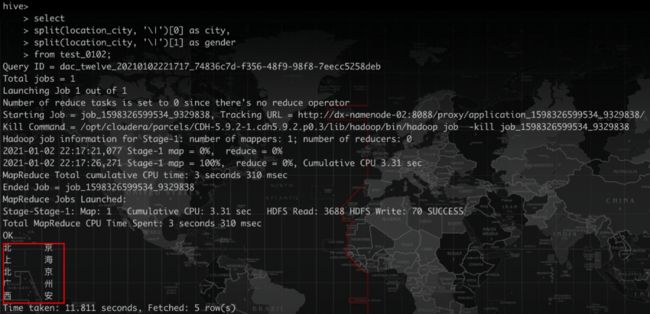
结果并未发生变化,不符合预期。如果再加一个转义符。

可以看到这样才最终得到了我们想要的结果。这是因为:第一个转义符是从 hive -> MapReduce 过程的转义第二个转义符是 MapReduce 编译时的转义。
再来看使用hive -e的方式执行。如果直接用两个转义符,输出的结果仍然是把单字分隔开。

所以我们再加一个转义符,看到正确分割出了结果,如下图所示。
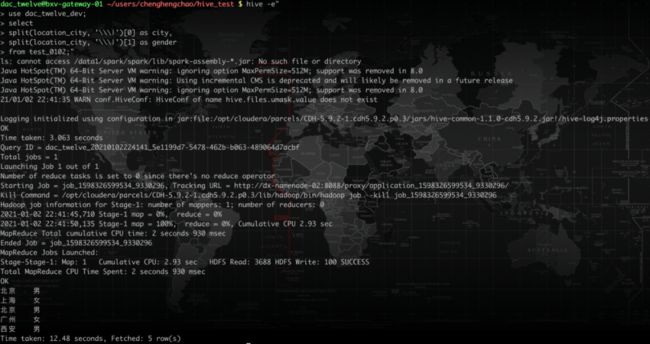
这是因为从shell到hive多了一步转义。因此需多加一个转义符。实际上,如果使用四个转义符,结果依然正确。个人认为实际中我们可以不用过多关注每一步转义到底因为什么,但当遇到正则表达式或者split时,要多多留心特殊字符。最好用一个简单例子测试一下,避免数据不符合预期。下面这个链接对转义有比较深入分析,建议仔细阅读。
参考链接:https://blog.csdn.net/lt793843439/article/details/91492088
相应的,如果遇到双竖线的情况,对每一个竖线则需要分别转义。例如我们要将上面数据中skills一列分割出来。相应写法如下
hive命令行:每一个竖线两个转义符
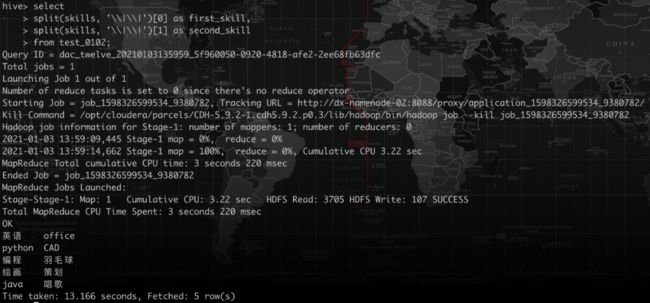
hive -e:每一个竖线三个转义符(四个也行)

hive -e 生成结果文件时,文件名要和重定向符放在一行
hive -e执行hiveSQL时,可以采用重定向符(>)把查询结果写入文件。
hive -e"
use dac_twelve_dev;
select
split(location_city, '\\\|')[0] as city,
split(location_city, '\\\|')[1] as gender
from test_0102;" > test_0102.txt
cat test_0102.txt
北京 男
上海 女
北京 男
广州 女
西安 男
需要注意的是,结尾的双引号,重定向符号,结果文件文件名和要放在同一行。否则则可能不能如期生成结果文件。如下面几种方式所示。
#第一种
hive -e"
your SQL
" >
test_0102.txt
#第二种
hive -e"
your SQL"
>
test_0102.txt
#第三种
hive -e"
your SQL"
> test_0102.txt
上面的三种方式,第一种会报错:-bash: syntax error near unexpected token `newline。第二种会在屏幕上打印结果后报相同的错,第三种会在屏幕上打印结果不报错,但最终结果文件没有数据。
shell中执行hiveSQL打印SQL时注意星号
在调度中运行hiveSQL时,一般会使用shell脚本文件。脚本中先定义好时间变量,再定义SQL语句,最后使用hive -e方式执行SQL。类似于下面这样:
yesterday=`date -d "now -1 day" +%Y-%m-%d`
hql="
select * from xxt_able where ds='${yesterday}'
"
echo $hql#错误的写法,正确的是echo "$hql"
hive -e $hql > result.txt
这里需要注意的是如果定义的hql语句中有*号(等特殊符号),为了在echo打印时能够正常输出,以便于我们核查时间变量是否被正确替换。需要用"$hql" 而不要使用$hql。否则在打印的时候,*号会被当做shell的通配符,把当前路径下所有的文件名称都打印出来。同样也会hive在运行时报错。如下面代码和结果所示。*在打印时被替换为了当前路径下所有的文件。


关于hive执行时的其他选项
-S选项屏蔽mapreduce日志
执行hiveSQL时,如果需要执行MapReduce过程,屏幕上会出现类似于map=100%,reduce=33%这样的提示,如果任务比较复杂,日志长度也会相应增加。虽然能便于我们了解任务进度,但有时我们也会想把它屏蔽掉。使用hive -S -e "sql语句"的方式,以Silent mode运行hive,就可以实现这样的目,此时屏幕上只会有hive启动的日志,而不会有mapreduce过程的日志。
-v选项打印出实际执行的SQL
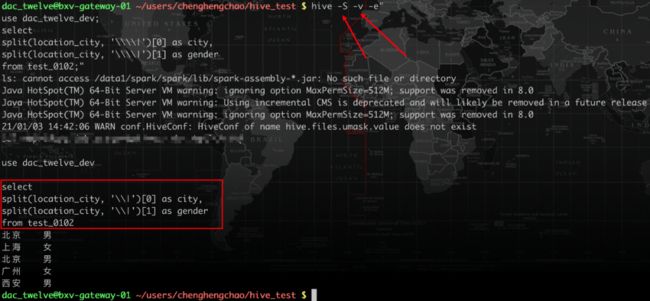
这个选项可以用于前面提到的任务调度时,验证实际执行的详细SQL。假设我们提前定义好yesterday变量,-v选项会将变量值打印出来,也就替代了echo "$hql"的方式。(这里SQL报错了,我们为了演示变量,引用了表中不存在的ds字段)

hive执行结果显示表头
set hive.cli.print.header=true;默认hive查询的结果时没有列名(表头)的,如果想要在结果中显示,可以在sql语句前加上这个选项,就可以显示列名了。
hive关闭严格模式
set hive.mapred.mode=nonstrict;hive执行模式有严格和非严格之分。通常,hive严格模式禁止三种查询:
1.对于分区表,必须指定分区,否则会报错No parttion predicate found for Alias xxx Table xxx.
2.使用了order by,则必须使用limit。提示信息为In strict mode,if ORDER BY is specified ,LIMIT must also be specifiied.
3.禁止笛卡尔积查询。提示信息为:In strict mode, cartesian product is not allowed.
使用这个设置关闭严格模式,可以使查询更灵活。
小结
本文总结了实际工作中使用hive的一些容易被忽略的注意事项。包括转义符,*号等特殊字符,结果文件生成,以及一些有用的选项和设置。此外,使用hive -h能看到其他的一些hive选项。掌握它们能够避免不必要的麻烦,起到事半功倍的效果。后台回复"hive"获取本文pdf版本。

推荐阅读:
SQL查询中笛卡尔积的巧妙使用(文末福利)
SQL中这些与NULL有关的细节,你知道吗?
关于Left join,你可能不知道这些......