《X86汇编-从实模式到保护模式》10. 32位x86处理器编程架构
文章目录
-
-
- 基本的工作模式
- 线性地址
- 现代处理器的结构和特点
-
- 流水线
- 高速缓存
- 乱序执行
- 寄存器重命名
- 分支目标预测
- 32 位模式的指令系统
-
- 寻址方式
- 汇编转机器码
- 32位 push 指令的变化
-
32 位的寄存器在 16 位的基础上进行了扩展:

为什么 8086 要采用分段?
因为:它有 20 根地址线,可以寻址 1MB 内存。但内部寄存器却是 16 位的,无法在程序中访问整个 1MB 内存。因此采用分段的形式将 16 位地址加工为 20 位的地址,即段地址 × 0x10 + 变址 = 20 位物理地址。
32位模式下依然采用分段模型:
32 位模型下,有 32 根地址线,内部寄存器也是 32 位的,因此完成可以访问整个 4 GB 内存,但 IA-32 架构的处理器是基于 8086 分段模型的,因此 32 位处理器依然采用分段模型。
平坦模型: 只能一个段,段基地址是 0x00000000,段长是 4GB,在这种情况下,可以视为不分段,即平坦模型。
在 16 位模式下,一个程序可以自由访问不属于它的内存,任意修改,这并不安全。
在 32 位模式下,处理器要求在加载内存时,先定义该程序所拥有的段,然后允许使用这些段。访问一个段时,处理器将进行违规访问的检查。
在 32 位模式下,传统的段寄存器,如 CS、SS、DS、ES,保存的不再是 16 位段基地址,而是段的选择子,称为段选择器。除此外,每个段寄存器还有一个不可见的部分,称为描述符高速缓存器,保存段的基地址和各种访问属性。
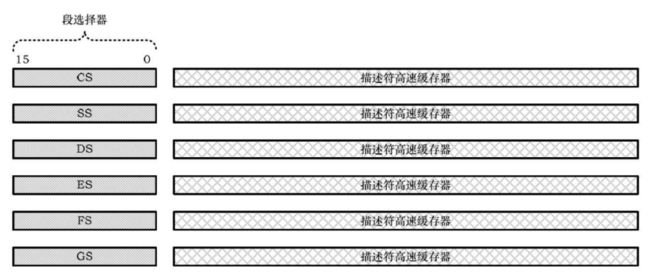
基本的工作模式
32 位的两种模式:
- 虚拟 8086 模式(V86 模式)
- 保护模式
8086 只有一种工作模式,即实模式。
注意:没有 32 位实模式这种说法,实模式的实质就是 8086 模式。
线性地址
在分段模型下,内存的分配是不定长的,程序大时,就分配一大块内存,小时分配一小块。程序终止后,处理器回收内存空间。时间长了后,内存空间就会碎片化,就会出现一种情况:内存虽有,但都是小块的,无法满足任务需求。
为了解决这个问题,因此 IA-32 处理器支持分页功能,分页功能将物理内存空间划分成逻辑上的页,页的大小是固定的,一般为 4KB,通过分页,可以简化内存管理。
当页功能开启时,段部件产生的地址就不再是物理地址了,而是线性地址,线性地址还要经页部件转换后,才是物理地址。
现代处理器的结构和特点
流水线
指令预处理队列: 当指令执行时,若总线总是空闲的(没有访问内存的操作),就可以在指令执行的同时预取指令提前译码,这可以加快程序的执行速度。
执行一条指令的过程:取指令、译码、访问操作数,接着进行具体的指令操作。
把一条指令的执行过程分解成若干个细小的步骤,并且分配给相应的内存单元来完成。各个单元的执行是独立的、并行的。也就是说各个步骤的执行在时间上就会重叠起来,这种执行指令的方法就是流水线(Pipe-Line)技术。
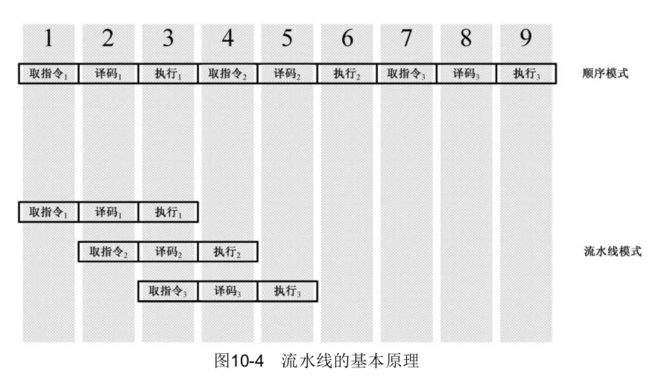
例如,一条指令的执行过程分解为取指令、译码、执行三个步骤,假定每个步骤花 1 个时钟周期。如图 10-4 所以,若采用顺序执行,则执行三条指令需要花费 9 个时钟周期。而采用三级流水线,则只需要 5 个时钟周期。
高速缓存
影响处理器速度的因素除了指令的执行过程外,另一个因素是存储器。寄存器的速度最快,因为使用了触发器,而触发器的工作速度是纳秒级。而硬盘的访问速度最慢,通常在毫秒级。
在这种情况下,因为需要等待内存和硬盘这样的慢速设备,处理器便无法全速运行。高速缓存是处理器与内存(DRAM)之间的一个静态存储器,容量较小,但速度可以与处理器匹配。
程序运行时的局部性规律:程序常常访问最近访问过的指令和数据,或者与它们相邻的指令和数据。例如一段循环语句,又或者是经常使用某个数据(像是 for 中的 i)。
利用程序运行时的局部性原理,可以把处理器正在访问和即将访问的指令和数据块从内存调入高速缓存中。此后,每当处理器要访问内存时,首先检索高速缓存。若存在,则直接获取,这就是命中(Hit),否则称为不中(miss)。在不中的情况下,处理器必须重新装载高速缓存,而不只是直接到内存中去取那个内容。
高速缓存的装载以块为单位,也就是要得到 X 的数据,那么 X 附近的数据也会一起被装载。为此,需要额外的时间来等待块从内存载入高速缓存,该过程中损失的时间称为不中惩时(miss penalty)。
乱序执行
为了实现流水线技术,需要将指令拆分成更小的可独立执行部分,即拆分成微操作。
add eax, ebx
; 这并不需要拆分,这已经一个微操作了
add eax, [mem]
; 可拆分两个微操作
; 1. 从内存(mem)中读取数据并保存到临时寄存器
; 2. 将 EAX 寄存器和临时寄存器中的数值相加
这里我当初有个疑惑,除了上面两步外,不应该有个 “3. 将相加结果写回 EAX 寄存器” 吗?
后来有前辈解惑:基本所有寄存器和寄存器的运算,都可以在 1 个时钟周期内完成,因此无须在分。
add [mem], eax
; 可拆分为三个微操作
; 1. 从内存中读取数据并保存到临时寄存器
; 2. 执行相加操作
; 3. 将相加的结果写回内存中
一旦将指令拆分成微操作,处理器就可以在必要的时候乱序执行程序。
mov eax, [mem1] ; 1. 读取 mem1 内存内容到临时寄存器
; 2. 将临时寄存器的内容赋值给 EAX
shl eax, 5 ; 在执行 shl 的同时,处理器可以提前从内存中读取 mem2 的内容。
; 若不命中,则进行罚时处理。
add eax, [mem2] ; 1. 读取 mem2 内存内容到临时寄存器
; 2. 将临时寄存器和 EAX 相加
mov [mem3], eax ; 1. 读入 mem3 内存内容到临时寄存器
; 2. 将 EAX 赋值给临时寄存器
; 3. 将相加结果(EAX)写回临时寄存器
寄存器重命名
mov eax, [mem1]
shl eax, 3
mov [mem2], eax
;----------------
mov eax, [mem3]
add eax, 2
mov [mem4], eax
以上两段代码,实际上互不相干。因此处理器为最后三条指令使用了另一个不同的临时寄存器,所以前面三条和后面三条可以并行执行。
在处理器内部,有大量的临时寄存器可使用,处理器可以重命名这些寄存器以代表一个逻辑寄存器,比如重命名为 EAX。
mov eax, [mem1] ; 假设 mem1 在 Cache 中
mov ebx, [mem2] ; 假设 mem3 不在 Cache 中
add ebx, eax
shl eax, 3 ; 使用一个临时寄存器保存 SHL 后的值(这个临时寄存器用来代表 EAX)(原 EAX 不变)
; 这样不用等待 ebx 和相加指令
; 等相加指令完成后,那个代表 EAX 的临时寄存器被写入到真正的 EAX 中,该过程称为引退
mov [mem3], eax
mov [mem4], ebx
所有通用寄存器、栈指针、标志、浮点寄存器,甚至段寄存器都有可能被重命名。
分支目标预测
- 必须清空流水线,从要转移到的目标位置处重新取指令放入流水线。
- 流水线越长,处理器在用错误的分支填充流水线时,浪费的时间越多。
- 分支目标预测技术核心问题:判断转移是否会发生。
- 在处理器内部,有个小容量的高速缓冲器,叫分支目标缓冲器(BTB)。
- 当处理器执行一条分支语句后,它会在 BTB 中记录当前指令的地址、分支目标的地址,以及本次分支预测的结果。
- 若预测失败,则清空流水线,同时刷新 BTB 中的记录。这个代价较大。
32 位模式的指令系统
寻址方式

汇编转机器码
https://blog.csdn.net/qq_43098197/article/details/126014926
感觉“操作数大小的指令前缀”讲的就是这块内容…
32位 push 指令的变化
push cs ; 0E
push ds ; 1E
push es ; 06
push fs ; 0F A0
push gs ; 0F A8
push ss ; 16
32 位模式下的 psuh 指令压入段寄存器有些特殊,在 16 位模式下,是先将 SP - 2,然后压入段寄存器,而 32 模式下,是先要将段寄存器用零扩展到 32 位,即高 16 位全为零,然后将 ESP - 4,再压入扩展到 32 位后的段寄存器。
其它略过…(因为我感觉其它简单,这小部分可能需要注意)