Spark_7 SparkCore共享变量
共享变量
- 共享变量的概述
- 广播变量
-
- 广播变量概述及底层分析
- 广播变量的使用
- 广播变量应用场景举例
- 累加器
-
- 累加器概述
- 累加器的使用
- 系统累加器
- 自定义累加器
共享变量的概述
Spark 一个非常重要的特性就是共享变量。
默认情况下,如果在一个算子的函数中使用到了某个外部的变量,那么这个变量的值会被拷贝到每个 task 中,此时每个 task 只能操作自己的那份变量副本。如果多个 task 想要共享某个变量,那么这种方式是做不到的。
Spark 为此提供了两种共享变量,一种是 Broadcast Variable( 广播变量),另一种是 Accumulator( 累加变量)。 Broadcast Variable 会将用到的变量, 仅仅为每个节点拷贝一份, 即每个 Executor 拷贝一份, 更大的用途是优化性能,减少网络传输以及内存损耗。 Accumulator 则可以让多个 task 共同操作一份变量,主要可以进行累加操作。 Broadcast Variable 是共享读变量, task 不能去修改它,而 Accumulator 可以让多个 task 操作一个变量。
广播变量
广播变量概述及底层分析
广播变量允许编程者在每个 Executor 上保留外部数据的只读变量,而不是给每个任务发送一个副本。
在没有使用广播变量时,每个 task 都会保存一份它所使用的外部变量的副本, 当一个 Executor 上的多个task 都使用一个大型外部变量时, 对于 Executor 内存的消耗是非常大的。因此, 我们可以将大型外部变量封装为广播变量, 此时一个 Executor 保存一个变量副本,此Executor 上的所有 task 共用此变量, 不再是一个 task 单独保存一个副本, 这在一定程度上降低了 Spark 任务的内存占用。
Spark 还尝试使用高效的广播算法分发广播变量,以降低通信成本。
Spark 提供的 Broadcast Variable 是只读的,并且在每个 Executor 上只会有一个副本,而不会为每个 task 都拷贝一份副本,因此, 它的最大作用,就是减少变量到各个节点的网络传输消耗,以及在各个节点上的内存消耗。此外, Spark 内部也使用了高效的广播算法来减少网络消耗。
可以通过调用 SparkContext 的 broadcast()方法来针对每个变量创建广播变量。然后在算子的函数内,使用到广播变量时,每个 Executor 只会拷贝一份副本了,每个 task 可以使用广播变量的 value()方法获取值。
在任务运行时, Executor 并不获取广播变量,当 task 执行到使用广播变量的代码时,会向 Executor 的内存中请求广播变量;之后 Executor 会通过 BlockManager 向 Driver 拉取广播变量,然后提供给 task进行使用。
广播大变量是 Spark 中常用的基础优化方法, 通过减少内存占用实现任务执行性能的提升。
广播变量的使用
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个 Spark 操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,甚至是机器学习算法中的一个很大的特征向量,广播变量用起来都很顺手。 在多个并行操作中使用同一个变量,但是 Spark 会为每个任务分别发送。
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(35)
scala> broadcastVar.value
res33: Array[Int] = Array(1, 2, 3)
使用广播变量的过程如下:
(1) 通过对一个类型 T 的对象调用 SparkContext.broadcast 创建出一个 Broadcast[T]对象。任何可序列化的类型都可以这么实现。
(2) 通过 value 属性访问该对象的值(在 Java 中为 value()方法)。
(3) 变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)。
广播变量应用场景举例
Join的实现
//Join:commonJoin,BroadcastJoin()
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author Gru
* @create 2019-07-15-13:09
*/
object BroadCastApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("BroadCastApp").setMaster("local[2]")
val sc= new SparkContext(sparkConf)
broadCastJoin(sc)
Thread.sleep(20000)
sc.stop()
}
def commonJoin(sc: SparkContext) = {
val info1 = sc.parallelize(Array(("01","张三"),("02","李四")))
val info2 = sc.parallelize(Array(("01","清华","20"),
("03","北大","21"),("04","清华","25"))).map(x=>(x._1,x))
info1.join(info2).foreachPartition(print)
}
/**
* @param sc
* broadCastJoin也就是mapJoin
*
*/
def broadCastJoin(sc:SparkContext)={
/**
* 适用于有一份数据较小的连接情况
* 做法是直接把该小份数据直接全部加载到内存当中
* 按链接关键字建立索引。然后大份数据就作为 MapTask 的输入
* 对 map()方法的每次输入都去内存当中直接去匹配连接
* 然后把连接结果按 key 输出
* 这种方法要使用 hadoop中的 DistributedCache 把小份数据分布到各个计算节点
* 每个 maptask 执行任务的节点都需要加载该数据到内存,并且按连接关键字建立索引
*/
// 将info1作为小表传播出去;广播是要先到driver端的,所以要collect;Map好操作
val info1 = sc.parallelize(Array(("01","张三"),("02","李四"))).collectAsMap()
val info1Broadcast=sc.broadcast(info1)
//broadcast出去之后就不会再用join来实现
// 大表的数据读取出来一条就和广播出去的小表的记录做匹配
// 这种情况不会产生shuffle,性能更好,但是小表数据不能太多
val info2 = sc.parallelize(Array(("01","清华","20"),
("03","北大","21"),("04","清华","25"))).map(x=>(x._1,x))
info2.mapPartitions(x=>{
val BroadCastMap = info1Broadcast.value
for((key,value)<-x if(BroadCastMap.contains(key)))
yield (key,BroadCastMap.get(key).getOrElse(""),value._2)
}).foreach(println)
}
}
累加器
累加器概述
累加器用来对信息进行聚合,通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用driver中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响driver中的对应变量。 如果我们想实现所有分片处理时更新共享变量的功能,那么累加器可以实现我们想要的效果。
累加器( accumulator): Accumulator 是仅仅被相关操作累加的变量,因此可以在并行中被有效地支持。它们可用于实现计数器(如 MapReduce)或总和计数。
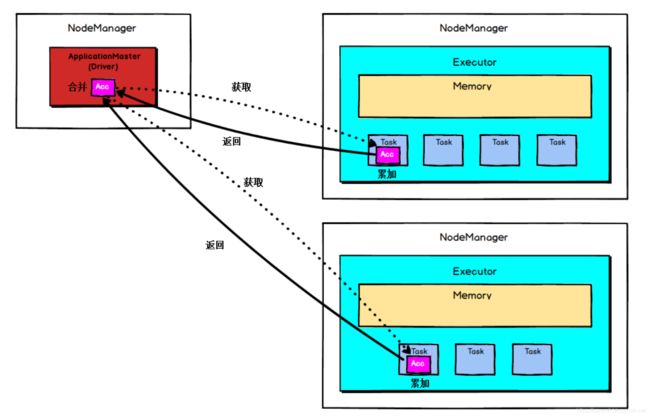
Accumulator 是存在于 Driver 端的, 集群上运行的 task 进行 Accumulator 的累加,随后把值发到 Driver 端,在 Driver 端汇总( Spark UI 在 SparkContext 创建时被创建,即在 Driver 端被创建,因此它可以读取 Accumulator 的数值), 由于 Accumulator存在于 Driver 端,从节点读取不到 Accumulator 的数值。
Spark 提供的 Accumulator 主要用于多个节点对一个变量进行共享性的操作。
Accumulator 只提供了累加的功能,但是却给我们提供了多个 task 对于同一个变量并行操作的功能,但是 task 只能对 Accumulator 进行累加操作,不能读取它的值,只有 Driver 程序可以读取 Accumulator 的值。
Accumulator的底层原理如图:
累加器的使用
累加器分为系统累加器和自定义的累加器
系统累加器
通过在驱动器中调用 SparkContext.accumulator(initialValue)方法,创建出存有初始值的累加器。返回值为 org.apache.spark.Accumulator[T] 对象,其中 T 是初始值 initialValue 的类型。 Spark 闭包里的执行器代码可以使用累加器的 += 方法(在 Java 中是 add)增加累加器的值。 驱动器程序可以调用累加器的 value 属性(在 Java 中使用 value()或 setValue())来访问累加器的值。
注意: 工作节点上的任务不能访问累加器的值。从这些任务的角度来看,累加器是一个只写变量。
对于要在行动操作中使用的累加器, Spark 只会把每个任务对各累加器的修改应用一次。因此,如果想要一个无论在失败还是重复计算时都绝对可靠的累加器,我们必须把它放在foreach() 这样的行动操作中。转化操作中累加器可能会发生不止一次更新。
针对一个输入的日志文件,如果我们想计算文件中所有空行的数量,我们可以编写以下程序:
scala> val notice = sc.textFile("./NOTICE")
notice: org.apache.spark.rdd.RDD[String] = ./NOTICE MapPartitionsRDD[40] at textFile at
:32
scala> val blanklines = sc.accumulator(0)
warning: there were two deprecation warnings; re-run with -deprecation for details
blanklines: org.apache.spark.Accumulator[Int] = 0
scala> val tmp = notice.flatMap(line => {
| if (line == "") {
| blanklines += 1
| }
| line.split(" ")
| })
tmp: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[41] at flatMap at :36
scala> tmp.count()
res31: Long = 3213
scala> blanklines.value
res32: Int = 171
自定义累加器
自定义累加器类型的功能在 1.X 版本中就已经提供了,但是使用起来比较麻烦,在 2.0版本后,累加器的易用性有了较大的改进,而且官方还提供了一个新的抽象类:AccumulatorV2 来提供更加友好的自定义类型累加器的实现方式。实现自定义类型累加器需要继承 AccumulatorV2 并至少覆写下例中出现的方法,下面这个累加器可以用于在程序运行过程中收集一些文本类信息,最终以 Set[String]的形式返回。
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.JavaConversions._
class LogAccumulator extends org.apache.spark.util.AccumulatorV2[String, java.util.Set[String]]
{
private val _logArray: java.util.Set[String] = new java.util.HashSet[String]()
override def isZero: Boolean = {
_logArray.isEmpty
}
override def reset(): Unit = {
_logArray.clear()
}
override def add(v: String): Unit = {
_logArray.add(v)
}
override def merge(other: org.apache.spark.util.AccumulatorV2[String, java.util.Set[String]]):
Unit = {
other match {
case o: LogAccumulator => _logArray.addAll(o.value)
}
}
override def value: java.util.Set[String] = {
java.util.Collections.unmodifiableSet(_logArray)
}
override def copy():org.apache.spark.util.AccumulatorV2[String, java.util.Set[String]] = {
val newAcc = new LogAccumulator()
_logArray.synchronized{
newAcc._logArray.addAll(_logArray)
}
newAcc
}
}
// 过滤掉带字母的
object LogAccumulator {
def main(args: Array[String]) {
val conf=new SparkConf().setAppName("LogAccumulator")
val sc=new SparkContext(conf)
val accum = new LogAccumulator
sc.register(accum, "logAccum")
val sum = sc.parallelize(Array("1", "2a", "3", "4b", "5", "6", "7cd", "8", "9"), 2).filter(line =>
{
val pattern = """^-?(\d+)"""
val flag = line.matches(pattern)
if (!flag) {
accum.add(line)
}
flag
}).map(_.toInt).reduce(_ + _)
println("sum: " + sum)
for (v <- accum.value) print(v + "")
println()
sc.stop()
}
}