SparkCore 共享变量(十一)
共享变量详解
新的一天,新的一篇,天天开心,篇篇收货。最近了大厂裁员,资本游戏频现,元宇宙越来越火,就业压力和失业风险齐头并进,让我们本就不富裕的生活雪上加霜。前段时间去深圳出差,在飞机上看到一句话送给大家,“如同每个时代,都会出现击鼓传花的资本游戏,但是大家都信心满满,认为自己不会是最后倒霉的那个”,以此共勉我们心向光明,脚踏实地。

一、概述
Spark的一个重要特性就是共享变量。默认情况下,如果在一个算子的函数中使用到某个外部的变量,那么这个变量的值会被拷贝到每个task中。此时每个task都只能操作自己的变量副本,如果多个task想要共享某个变量,那么这种方式是无法实现的。使用广播变量,每个executor的内存中,只驻留一份变量副本,而不是对每个task都传输一次变量,省去了很多的网络传输,对性能的提升有很大的帮助,而且通过高效的广播算法来减少传输代价,也避免了多地方维护不一致的风险。通常,当传递给 Spark 操作(例如 map 或 reduce)的函数在远程集群节点上执行时,它会处理函数中使用的所有变量的单独副本。这些变量被复制到每台机器上,对远程机器上的变量的更新不会传播回驱动程序。支持跨任务的通用读写共享变量将是低效的。因此,Spark 提供了两种有限类型的共享变量:广播变量和累加器。
二、广播变量
2.1、广播变量
广播变量通俗点说就是在每个executor缓存一份只读数据,供该executor下的所有任务使用。,这样就能保证不是每一个Task都需要缓存这样的一份数据。广播变量允许程序在每台机器上缓存一个只读变量,而不是随任务一起传送它的副本。例如,它们可用于以有效的方式为每个节点提供大型输入数据集的副本。 Spark 还尝试使用有效的广播算法来分发广播变量以降低通信成本。Spark 操作通过一组阶段执行,由分布式“洗牌”操作分隔。 Spark 自动广播每个阶段内任务所需的公共数据。以这种方式广播的数据以序列化形式缓存并在运行每个任务之前反序列化。这意味着显式创建广播变量仅在跨多个阶段的任务需要相同数据或以反序列化形式缓存数据很重要时才有用,如下图,一目了然。
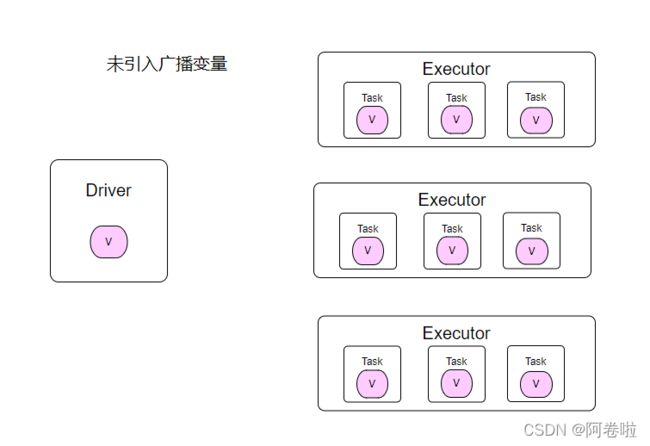
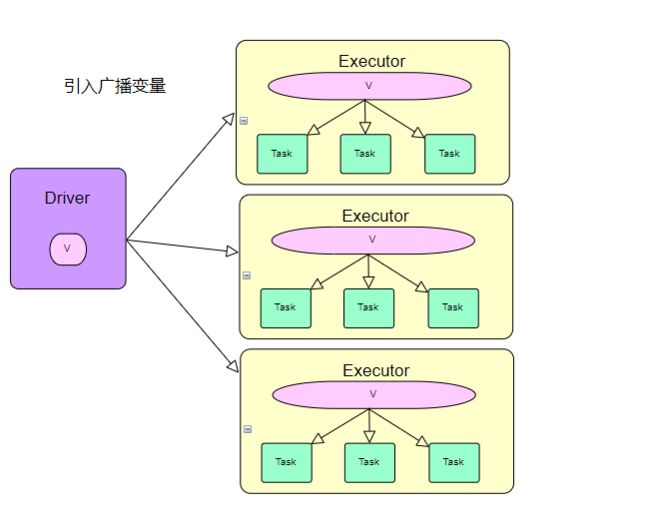
2.2、引入背景
前面提过,Spark 会自动把闭包中所有引用到的变量发送到工作节点上。虽然这很方便,但也很低效。原因有二:首先,默认的任务发射机制是专门为小任务进行优化的;其次,事实上你可能会在多个并行操作中使用同一个变量,但是Spark 会为每个操作分别发送。举个例子,假设要写一个Spark 程序,我们有一个区县地名,我们让他们加上他们的前缀,我们就需要维护一个所有省市下的区县Map,Spark会随着集群的大小将该任务分配给每个节点的多个Cpu去计算,我们就需要把这个Map分配给每一个CPU,假设一个节点32核,就需要有32个这样的Map,相当于同样的数据存储了32份,这样就是一种浪费,虽然我们国家省市Map可能也就是M级别的数据量,但是我们扩展到地球、银河系,那样数据将是毁灭式的,一个任务还没有开始计算,就已经被这些变量给撑满了。故,引入广播变量,在开始计算时候,我们现将这些共享数据发送到每个节点,仅缓存一份在内存,其他Task需要时候,直接在内存里面取,因为是内存级别的操作,速度也是可靠的。
2.3、使用方法
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("BOKE")
val sc = new SparkContext(conf)
val products = List(("北京", "朝阳", "海淀", "昌平", "..."), ("深圳", "南山", "坪山"), ("上海", "黄埔", "普陀", "静安"))
// 初始化广播变量
val BD: Broadcast[List[Product]] = sc.broadcast(products)
// 广播变量取值
val value: List[Product] = BD.value
println(value.mkString(",")) //(北京,朝阳,海淀,昌平,...),(深圳,南山,坪山),(上海,黄埔,普陀,静安)
2.3、注意点
- 广播的变量必须进行序列化,如果是自定义的类,需要实现Serializable接口(至于为什么要序列化,涉及到I/O发送,欢迎自行阅读spark官网,此处不做解释)此处说的实现序列化接口,不单单是广播的类需要实现,如果该类中包含其他类,那么其他类也同样需要实现序列化接口
- 如果传递的类本身不支持序列化,那么需要用一个包装类包装一下,并且包装类要实现Serializable接口。
- 应用广播变量的时候,难免遇见广播的内容需要更新(比如缓存的实时更新),但是广播变量不支持实时更新,所以只能手动停掉,然后重新赋值。BD.unpersist(blocking),blocking参数的意义是阻塞,在删除广播变量值的之前,先进行线程阻塞,防止在删除的过程中,还会被引用。
- 广播变量的复制以及修改是针对Driver端,这也是广播值需要序列化的原因。
三、累加器
累加器是分布式共享只写变量, 我们在每个executor均可以在累加器变量进行累加,作用在executor,我们可以在driver直接拿到结果,累加器理解起来很简单,就是实现共享加减作用,在分布式下操作同一变量。我们可以直接使用官方提供的最简单的RDD+/-计算,但是在特定的情况下,并不能解决我们的问题,所以我们也可以自定义累加器。
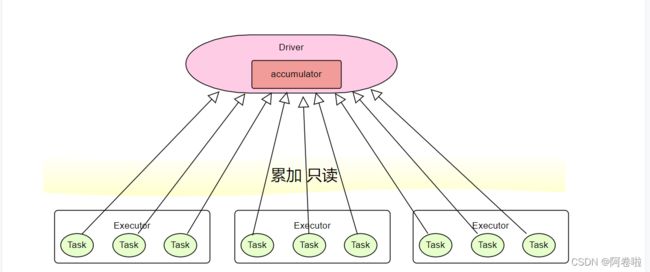
3.1、简单累加器
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("example")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
val acc: LongAccumulator = sc.longAccumulator("sum")
rdd.foreach(num => acc.add(1L))
println(acc.value) // 4
3.2、自定义累加器
这里我们自定义累加器实现一个WordCount的功能,自定义累加器需要继承AccumulatorV2类,定义累加数据类型,以及实现isZero、copy、reset、add、mergevalue方法。
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("example")
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.makeRDD(List("hello", "spark", "scala", "spark"), 2)
val myAcc = new MyAccumulator()
sc.register(myAcc)
rdd.foreach(
data=>myAcc.add(data)
)
println(myAcc.value)
}
class MyAccumulator extends AccumulatorV2[String,mutable.Map[String, Int]] {
private val wcMap: mutable.Map[String, Int] = mutable.Map[String, Int]()
// 初始值
override def isZero: Boolean = {
wcMap.isEmpty
}
override def copy(): AccumulatorV2[String, mutable.Map[String, Int]] = {
this
}
// 重置累加器
override def reset(): Unit = {
wcMap.clear()
}
// 累加
override def add(v: String): Unit = {
val i: Int = wcMap.getOrElse(v, 0) + 1
wcMap.update(v,i)
}
// 数据合并
override def merge(other: AccumulatorV2[String, mutable.Map[String, Int]]): Unit = {
other.value.foreach{
case (word,v)=>{
var newValue:Int = this.wcMap.getOrElse(word, 0)+v
this.wcMap.update(word,newValue)
}
}
}
// 获取累加数据结果
override def value: mutable.Map[String, Int] = {
this.wcMap
}
}
关于SparkCore的三大数据类型,现在我们已经描述完了,那咱们就下篇见啦,拜了个拜。
