文件IO_文件同步(附Linux-5.15.10内核源码分析)
目录
1.为什么要进行文件同步?
2.fsync函数介绍
2.1 fsync函数
2.2 fsync函数内核源码分析
2.3 fsync函数使用示例
3.fdatasync函数介绍
3.1 fdatasync函数
3.2 fdatasync函数内核源码分析
3.3 fdatasync函数使用示例
4.sync函数介绍
4.1 sync函数
4.2 sync函数使用示例
5.文件同步函数对比
1.为什么要进行文件同步?
在Linux系统中,文件系统通常使用缓冲区来提高文件读写性能。
当应用程序对文件进行写操作时,数据首先会被写入到内核的缓冲区中,而不是直接写入到磁盘。这样可以减少磁盘I/O的次数,提高文件读写的效率。
然而,这种缓冲机制也存在一个问题,就是当发生系统崩溃或意外的断电等情况时,还未写入磁盘的数据将会丢失,导致数据的不一致性或丢失。
为了避免这种情况的发生,需要通过文件同步来确保数据的持久性和一致性。
通过进行文件同步,可以确保以下几点:
- 数据持久性:通过将缓冲区中的数据写入到磁盘,可以避免由于系统崩溃或断电等意外情况导致数据丢失。
- 数据一致性:同步操作不仅会将文件数据写入磁盘,还会同步文件的元数据(如权限、所有权等)。这样可以确保文件系统中的数据与磁盘中的数据一致,避免数据损坏或不一致的情况。 系统稳定性:
通过定期进行文件同步,可以减少系统出现故障的可能性,提高系统的稳定性和可靠性。
需要注意的是,文件同步会引起一定的性能开销,因为它需要将数据写入磁盘。因此,在实际应用中,需要根据具体场景和需求权衡数据的持久性和性能之间的关系,选择合适的同步策略和时机。
2.fsync函数介绍
2.1 fsync函数
#include
int fsync(int fd); 函数简介:fsync函数是一个用于将文件数据及元数据同到磁盘的系统调用函数。的目的是确保文件的修改已经完全写入到磁盘中,以防止数据丢失或损坏。
函数参数:
fd:文件描述符,指向需要同步的文件。
函数返回值:
成功:返回0。
失败:返回-1,并设置errno。
2.2 fsync函数内核源码分析
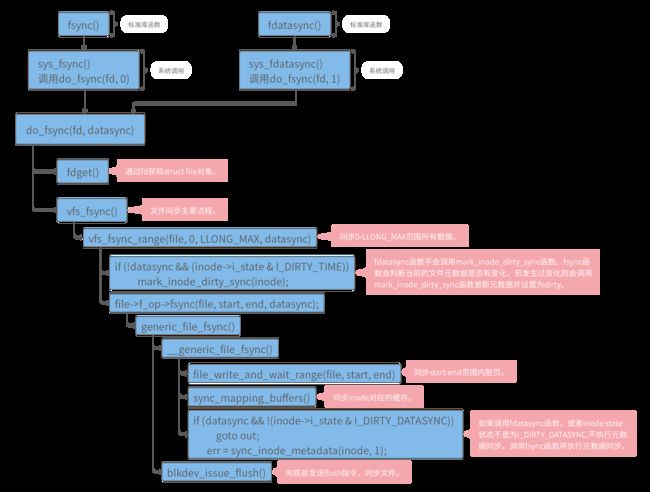
图 2-1 fsync函数内核源码调用流程
fsync和fdatasync内核调用核心流程差不多,执行完系统调用后,统一调用do_fsync函数,fsync和fdatasync函数调用do_fsync函数传递的datasync实参(只同步数据,不同步元数据)不一样,fsync函数datasync为1表示只同步数据,fsync函数datasync为0表示即同步数据也同步元数据。
fdatasync不会调用mark_inode_dirty_sync函数,fsync则会调用,该函数的作用是更新元数据为DIRTY状态,后续同步元数据将用到该状态。
file->f_op->fsync函数不同的文件系统实现方式不一样,如图2-1是以generic_file_fsync函数为例进行分析,generic_file_fsync会先同步数据,然后再判断是否满足同步元数据条件(fdatasync不同步元数据)再调用sync_inode_metadata函数进行元数据同步。
最后再调用blkdev_issue_flush函数通知底层同步文件。
2.3 fsync函数使用示例
int fsync_test(bool datasync) {
int fd = open(TEST_FILE, O_RDWR | O_CREAT | O_TRUNC, 0644);
if (fd == -1) {
perror("open error");
return -1;
}
write_len_data(fd, 10, 'c');
int ret = 0;
if (datasync) {
fdatasync(fd);
} else {
fsync(fd);
}
if (ret == -1) {
perror("fsync error");
close(fd);
return -1;
}
close(fd);
return 0;
}3.fdatasync函数介绍
3.1 fdatasync函数
#include
int fdatasync(int fd);
函数简介:fdatasync函数是一个用于将文件数据同步到磁盘的系统调用函数,与fsync函数类似。它会将文件的数据部分(不包括元数据)同步到磁盘,以确保文件的修改已经完全写入到磁盘中。 fdatasync函数与fsync函数的区别在于,fdatasync只同步文件的数据部分,而不同步文件的元数据(如权限、所有权等)。
由于不涉及元数据的同步,fdatasync相比fsync可以更快地完成操作。
函数参数:
fd:文件描述符,指向需要同步的文件。
函数返回值:
成功:返回0。
失败:返回-1,并设置errno。
3.2 fdatasync函数内核源码分析
参考fysnc函数内核源码分析。
3.3 fdatasync函数使用示例
参考fsync函数使用示例。
4.sync函数介绍
4.1 sync函数
#include
void sync(void);
函数简介:sync函数是一个文件系统同步函数,用于将文件系统缓冲区中的数据写入到磁盘,并确保所有挂载的文件系统都已同步。
函数参数:
无
函数返回值:
无
sync函数通常在以下情况下使用:
- 在关机之前,调用sync函数可以确保所有数据都已写入磁盘,避免数据丢失或损坏。
- 在进行重要操作(如升级操作)之前,调用sync函数可以确保数据的持久性,以防止操作过程中发生意外情况。
- 在性能测试或基准测试中,调用sync函数可以确保每次测试之间的数据一致性,并避免测试结果受到缓冲区数据的影响。
4.2 sync函数使用示例
void sync_test() {
sync();
}5.文件同步函数对比
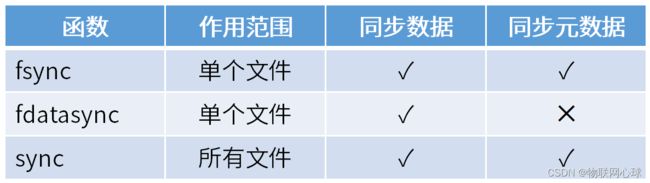
表 5-1 文件同步函数对比