最通俗的方法让你搞懂spring缓存机制
目录
简介:
Spring 缓存的抽象机制
Spring 缓存使用过程
通过注解声明缓存
通过配置集成缓存
总结
简介:
缓存(Cache)技术在互联网系统的开发过程中得到了非常广泛的应用。当系统出现性能瓶颈时,很多场景都可以使用缓存技术来重构业务处理流程,从而获取性能的提升。缓存的实现可以有很多方案,业界也诞生了一批优秀的缓存工具,例如 EhCache、Guava、Caffeine、Redis、Hazelcast 等。
因为这些缓存工具在设计和实现上的差异性,开发人员在使用它们时的一大痛点就是需要基于不同的缓存工具来进行定制化的开发。那么,对于缓存工具来说,有没有可能实现一种统一的使用方式呢?
答案是肯定的,以我们今天要讲的 Spring 开源框架为例,从 Spring 3.1 开始,Spring 就为开发人员提供了一款非常好用的缓存组件。今天的内容将围绕这款 Spring 内置的缓存组件展开讨论,我们将详细讲解该组件的功能特性和使用方法。
但在这之前,我们有必要对 Spring 缓存组件背后的抽象机制进行分析。正是这种抽象机制,体现了 Spring 框架的设计理念,并为技术人员提供了良好的开发友好性。
Spring 缓存的抽象机制
Spring 缓存组件的核心优势在于设计并实现了一个抽象层,从而为开发人员提供了一套完整而统一的缓存使用 API。
从上图中,我们可以看到,Spring 缓存中的抽象层对主流的缓存工具都进行了集成和整合。这样,开发人员就可以通过 Spring 提供的统一 API 来使用所有缓存工具,就像是在使用某个单独的缓存工具一样。这是 Spring 缓存提供的一个抽象维度。
另一方面,在开发模式上,基于 Spring 缓存组件,开发人员不需要像以前一样使用各种自定义的方法切面,也不用再把缓存相关代码注解嵌入到业务流程中。Spring 使用代理机制为那些添加了缓存注解的方法自动启用缓存机制。

Spring 缓存所提供的抽象机制还为开发人员提供了足够的扩展性。本质上,Spring 缓存的底层也是需要借助其他缓存工具来实现的,而上层则以统一 API 的编程模型暴露给开发人员。基于这种统一的编程模型,开发人员也可以实现自定义的缓存。

Spring 缓存使用过程
在需要启用缓存的目标对象上,Spring 为我们提供了两种控制粒度,一种是类,另一种是类上的方法。
而我们在使用 Spring 缓存时,也涉及两方面的开发工作,一方面是通过注解在具体的方法上声明缓存,另一方面则是配置 Spring 对缓存的支持。

接下来,我们看一下如何通过注解来声明缓存,以及如何通过配置来集成缓存。
通过注解声明缓存
我们要介绍的第一个注解是 @Cacheable。正如前面所提到的,Spring 缓存有两种控制粒度。因此,@Cacheable 注解可以同时标注在类或类的方法上。一般而言,我都建议你使用方法级别的控制粒度,但如果你想让类中的所有方法都支持缓存,那么就可以把该注解添加到类上。

对于 @Cacheable 注解而言,最基本的使用方式是设置它的 value 和 key 这两个属性。其中 value 属性就是缓存的名称,而讲到 key 属性,我们首先需要明确 Spring 缓存使用过程中非常核心的一个概念,即缓存键。开发人员可以根据 Spring 提供的一个 root 对象来生成缓存键。通过该 root 对象我们可以获取到方法调用所涉及的一组元数据。

现在假设我们需要为如下所示的业务方法添加缓存机制:
public User findUserById(Long id)
那么基于 root 对象,我们就可以生成对应的缓存键 key,具体的代码如下所示。这样,我们就可以根据传入的参数 ID 值来确定具体的缓存键值。假设 ID 为 1,那么 key 就是“user1”。
key = "'user'.concat(#args[0].toString())"
讲到这里,你可能会问,我们一定要手工设置缓存键吗?如果没有设置缓存键会怎么样呢?事实上,如果我们没有指定 key 属性,那么 Spring 会自动生成键。默认的 key 生成策略是通过 KeyGenerator 生成的,KeyGenerator 接口定义如下。
public interface KeyGenerator {
Object generate(Object target, Method method, Object... params);
}
Spring 生成默认键是有一定的策略的,如果方法传入参数为空,那么缓存键就简单设置为 0;如果参数的个数为 1,那么键值就是这个参数本身的值;而如果有多个参数的话,则计算所有这些参数的哈希值作为键值。

介绍完缓存键的生成策略,让我们回到 @Cacheable 注解。我们把 value 属性和 key 属性结合在一起,就可以使用 @Cacheable 注解了,示例代码如下:
@Cacheable(value = "user", key = "'user'.concat(#id.toString())")
public User findUserById(Long id) {
System.out.println("findUserById query from db, id: " + id);
return userMap.get(id);
}
可以看到,这里我们把针对这个 findUserById() 方法的缓存名称设置为“user”,key 为类似“user1”这样的属性。
有时候,我们并不一定需要对方法的所有返回值都进行缓存,而是希望有条件地进行缓存。@Cacheable 注解的 condition 属性就适合这种场景。condition 属性的使用方式如下所示,这里通过一个 SpEL 表达式指定了只会缓存那些 ID 为奇数的 User 对象。
@Cacheable(value = "user", key = "'user'.concat(#id.toString())",condition="# id%2==1")
关于 @Cacheable 注解所能使用的三个主要属性,我们可以参考表 2 做一些总结。
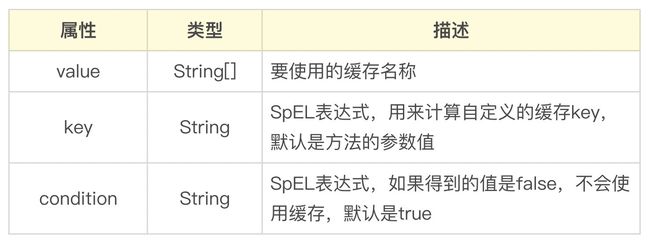
了解了 @Cacheable 注解之后,我们接着来讨论 @CachePut 注解。显然,从命名上看,该注解适合于执行更新操作的方法。当我们把 @CachePut 注解添加到某一个方法上时,相当于就是再次调用该方法的执行逻辑,然后把新的执行结果替换到原有缓存中的缓存值。
@CachePut 注解所包含的属性与 @Cacheable 注解完全一致。所以,我们可以在如下所示的 update() 方法上添加这个注解。
@CachePut(value = "user", key = "'user'.concat(#user.id.toString())")
public User update(User user) {
System.out.println("update db, user: " + user.toString());
userMap.put(user.getId(), user);
return user;
}
可以看到,我们指定了同一个缓存名称“user”以及相同的 key 值。这样,每次执行这个方法,都会使用新的 User 对象替换原有缓存中的老 User 对象。
Spring 缓存提供的最后一个常用注解是 @CacheEvict。从命名上,我们也不难想到该注解的作用就是用来清除缓存元素。和 @CachePut 注解一样,@CacheEvict 可以指定的属性也包括 value、key 和 condition。
但因为清除缓存的操作可能涉及多个元素,所以 @CacheEvict 注解额外提供了一个 allEntries 属性用来指定是否需要清除缓存中的所有元素。接下来,我们可以看一下使用 @CacheEvict 注解的代码示例:
@CacheEvict(value = "user", key = "'user'.concat(#id.toString())")
public void remove(Long id) {
System.out.println("remove from db, id: " + id);
userMap.remove(id);
}
可以看到,在删除一个 User 对象的同时,我们使用 @CacheEvict 注解清除了该对象的缓存值。
最后,我们也有必要提一下 Spring 框架中的 @Caching 注解,这是一个复合注解,实际上就是 @Cacheable、@CachePut 和 @CacheEvict 这三个注解的组合,这一注解的使用示例如下所示:
@Caching(cacheable = @Cacheable("cache1"), evict = { @CacheEvict("cache2"),
@CacheEvict(value = "cache3", allEntries = true) })
通过前面内容的介绍,我们能发现 Spring 缓存的使用方式非常简单。开发人员通常只需要使用固定的几个注解就能满足日常开发需要,这都要归功于 Spring 框架具备的强大抽象和集成能力。
通过配置集成缓存
说到集成,我们还有一个核心问题没有解答,也就是开发人员如何使用 Spring 缓存提供的各种缓存工具呢?
这就需要引入 CacheManager。
CacheManager 是 Spring 中用来统一管理各种缓存工具的接口。目前,Spring 已经内置了一大批主流的缓存实现工具,这些工具都统一通过 CacheManager 进行管理。CacheManager 的类层结构如下图所示:

可以看到,除了基于 Java API 的 ConcurrentMapCacheManager 之外,EhCache、Redis、Caffeine、Guava 等都已经被整合进了 Spring 框架。
显然,不同的缓存工具特性是不一样的,所以对于不同的 CacheManager 实现,我们都需要设置对应的配置项。以 EhCache 为例,我们可以在类路径上创建一个 ehcache.xml 配置文件,并设置如下配置项:
这里我们设置了 EhCache 的常规属性,并针对“user”这个缓存指定了它的内存中最大缓存对象数、缓存对象失效前允许存活时间等属性。然后,在 Spring Boot 应用程序的 application.yml 配置文件中,我们也需要把当前使用的缓存类型设置为 ehcache,并指定对应的配置文件地址。
spring:
cache:
type: ehcache
ehcache:
config: classpath:ehcache.xml
而如果你使用的是 Caffeine,那么可以使用如下代码所示的配置方法。在代码中,我们针对“user”缓存对象创建了一个 CaffeineCache,并把它注册到 CacheManager 中。
@Configuration
public class CacheConfig {
@Bean
public CacheManager cacheManager() {
SimpleCacheManager manager = new SimpleCacheManager();
ArrayList caches = new ArrayList<>();
caches.add(new CaffeineCache(“user”,
Caffeine
.newBuilder()
.recordStats()
.expireAfterWrite(60, TimeUnit.SECONDS)
.maximumSize(100)
.build())
);
manager.setCaches(caches);
return manager;
}
}
总结
在使用 Spring 框架时,缓存是一个常常被忽视但又值得我们深入学习的功能组件。我们首先讲到了 Spring 这一开源框架提供的一套针对缓存的抽象机制。在市面上多种不同类型的缓存实现工具中,Spring 的这一机制给我们以统一的 API 来使用各种缓存工具提供了便利。
之后,我们以 Spring 中的三个常见注解:@Cacheable、@CachePut 以及 @CacheEvict 为例,展示了 Spring 提供的强大的注解功能。基于 Spring 的注解功能,我们可以在任意类和方法上嵌入缓存机制,开发工作简捷而高效,要做的只是基于 CacheManager 组件完成针对不同缓存工具的配置而已。
如果觉得本文对你有帮助,欢迎点赞,欢迎关注我,如果有补充欢迎评论交流,我将努力创作更多更好的文章。