python 多任务详解
- 1、线程
-
- ① 函数方式创建线程
- ② 自定义类创建线程
- 2、队列
-
- ① 普通队列 Queue
- ② 堆栈 LifoQueue
- ③ 优先级 PriorityQueue
- 3、互斥锁
- 4、进程
-
- ① 函数方式创建进程
- ② 类方式创建进程
- ③ 进程中的队列
- ④ 进程间通信
- 5、 线程与进程区别
-
- ① 线程共享全局变量,进程不共享
- ② 所有的线程都在同一个进程中
- ③ 线程开销小,但不利于资源的管理和保护,进程相反
- 6、进程池
-
- ① 案例1:
- ② 进程池间通信
-
- 案例1:
- 7、协程(微线程)
-
- ① greenlet
- ② gevent
- 8、异步
-
- ① ascynio
- ② aiohttp
1、线程
线程是进程的一个实体,是cpu调度和分派的基本单位。
Python中的线程是轻量级执行单元,可以在同一进程中并发执行。Python中的线程由threading模块提供支持。线程的创建可以通过直接实例化Thread类或者继承Thread类并重写run()方法来实现。
import threading # 导入线程包
def f_a(): # 创建函数a
pass
thread_1 = threading.Thread(target=f_a,args=(),kwargs={}) # 创建线程
thread_1.start() # 开始执行线程
① 函数方式创建线程
简单创建线程测试
import threading
import time
def task_1(print1):
while 1:
print(print1)
time.sleep(1)
print1 = "woshi 1111111111"
thread_1 = threading.Thread(target=task_1,args=(print1,)) # 通过 args/kwargs传入元组/字典进行传参
thread_1.start()
while 1:
print("hello")
time.sleep(1)

② 自定义类创建线程
import threading # 导入线程包
class C_1(threading.Thread): # 自定义 并继承threading.Thread类
def run(self): # 添加run()方法,start()自动调用该方法
pass
thread_1 = C_1()
thread_1.start() # 此处调用thread_1.run()方法并不能生成线程
2、队列
Python中的队列是一种数据结构,用于在多个线程之间安全地传递数据。队列的实现可以使用queue模块提供的类。
import queue
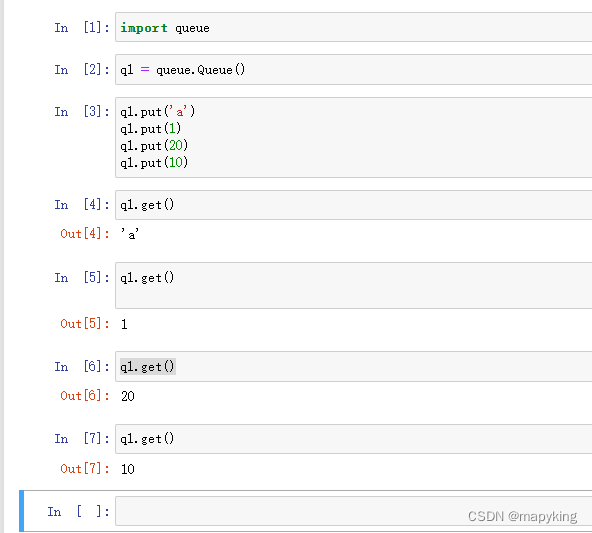
① 普通队列 Queue
先进先出
import queue
q1 = queue.Queue()
q1.put('xxx')
q1.get() # 如果当前队列没有数据 则会堵塞
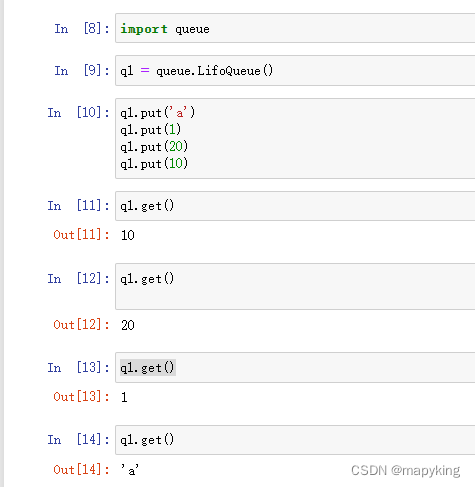
② 堆栈 LifoQueue
后进先出
import queue
q1 = queue.LifoQueue()
q1.put('xxx')
q1.get() # 如果当前队列没有数据 则会堵塞
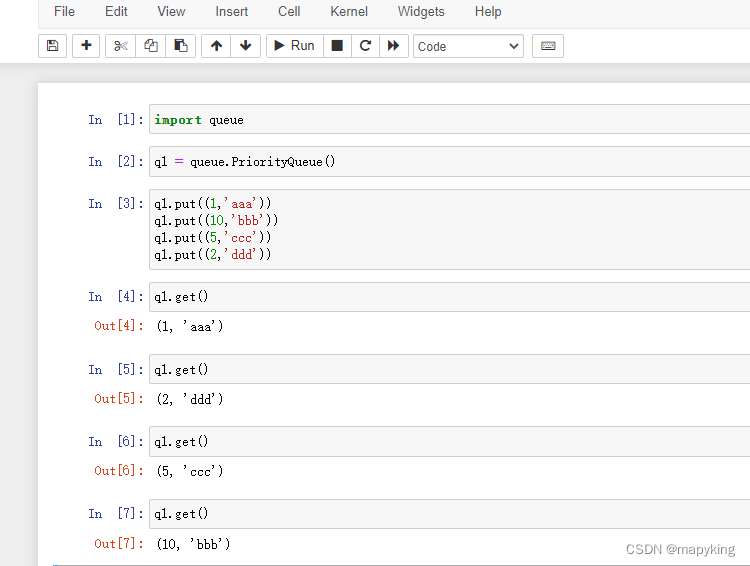
③ 优先级 PriorityQueue
import queue
q1 = queue.PriorityQueue()
q1.put((1,'xxx')) # 参数需要为元组,第一个元素表示优先级,数字越小优先级越高,第二个元素表示数据
q1.get() # 如果当前队列没有数据 则会堵塞
3、互斥锁
互斥锁用于控制多个线程之间对共享资源的访问。互斥锁可以确保在任何时刻只有一个线程可以访问共享资源,从而避免了多个线程同时修改共享资源而导致的数据竞争和不一致问题。Python中的互斥锁可以使用threading模块提供的Lock类来实现。在使用互斥锁时,需要首先获取锁,然后访问共享资源,最后释放锁。如果在获取锁时发现锁已经被其他线程占用,则当前线程会被阻塞,直到锁被释放为止。
mutex = threading.Lock() # 创建锁
mutex.acquire() # 上锁
# xxxxxx # 上锁代码
mutex.release() # 释放锁,同一锁被释放前,不能再次上锁
4、进程
指在操作系统中正在运行的代码+所需系统资源实例称之为进程。
Python 通过 multiprocessing 模块来支持多进程编程,可以使用该模块创建、管理和控制多个进程。
① 函数方式创建进程
import multiprocessing # 导入进程包
def p_a(): # 创建函数a
pass
process_1 = multiprocessing.Process(target=p_a,args=(),kwargs={}) # 创建子进程
process_1.start() # 启动子进程
② 类方式创建进程
import multiprocessing # 导入进程包
class Process1(multiprocessing.Process): # 自定义 并继承multiprocessing.Process类
def run(self): # 添加run()方法,start()自动调用该方法
pass
process_1 = Process1()
process_1.start()
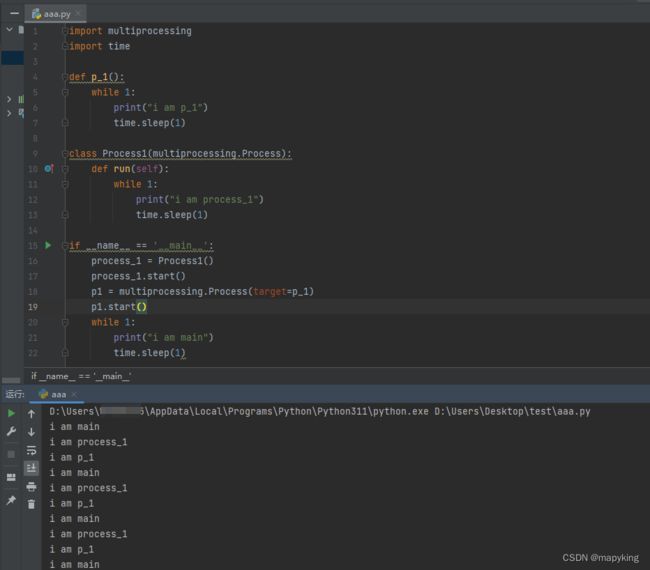
import multiprocessing
import time
def p_1():
while 1:
print("i am p_1")
time.sleep(1)
class Process1(multiprocessing.Process):
def run(self):
while 1:
print("i am process_1")
time.sleep(1)
if __name__ == '__main__':
process_1 = Process1()
process_1.start()
p1 = multiprocessing.Process(target=p_1)
p1.start()
while 1:
print("i am main")
time.sleep(1)
③ 进程中的队列
在multiprocessing模块中,队列(Queue)是一种用于在多个进程之间安全地传递数据的数据结构。队列的实现可以使用multiprocessing模块提供的Queue类。与Python中的线程队列类似,multiprocessing中的队列也提供了线程安全的入队和出队操作,可以安全地在多个进程之间共享。需要注意的是,在使用multiprocessing中的队列时,由于不同进程之间的内存空间是相互独立的,因此需要使用特殊的进程锁(Lock)来确保数据的同步和正确性。
import multiprocessing
p_q = multiprocessing.Queue(x) # 创建一个进程队列p_q,最多可以接收x条put
p_q.put("aaa")
p_q.full() # 判断队列是否满,返回True/False
p_q.empty() # 判断队列是为空,返回True/False
p_q.get()
import multiprocessing
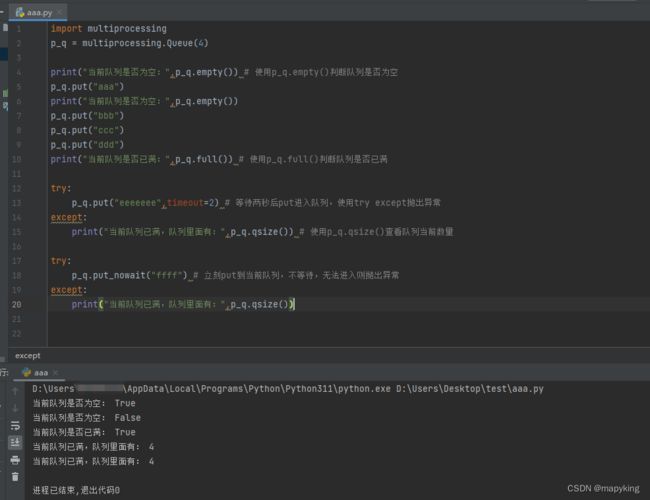
p_q = multiprocessing.Queue(4)
print("当前队列是否为空:",p_q.empty()) # 使用p_q.empty()判断队列是否为空
p_q.put("aaa")
print("当前队列是否为空:",p_q.empty())
p_q.put("bbb")
p_q.put("ccc")
p_q.put("ddd")
print("当前队列是否已满:",p_q.full()) # 使用p_q.full()判断队列是否已满
try:
p_q.put("eeeeeee",timeout=2) # 等待两秒后put进入队列,使用try except抛出异常
except:
print("当前队列已满,队列里面有:",p_q.qsize()) # 使用p_q.qsize()查看队列当前数量
try:
p_q.put_nowait("ffff") # 立刻put到当前队列,不等待,无法进入则抛出异常
except:
print("当前队列已满,队列里面有:",p_q.qsize())
④ 进程间通信
案例1:进程间通信有管道、socket、队列等方法,此处演示队列方法
import multiprocessing
import time
def task1(q):
for i in ["aa","bbb","cc","dd","eeeeee"]:
q.put(i)
print(i,'已进入队列')
time.sleep(1)
def task2(q):
while 1:
if not q.empty():
qi = q.get()
print("已从队列取出",qi)
time.sleep(1)
else:
break
if __name__ == '__main__':
q = multiprocessing.Queue()
p1 = multiprocessing.Process(target=task1,args=(q,))
p2 = multiprocessing.Process(target=task2, args=(q,))
p1.start()
p2.start()

5、 线程与进程区别
进程跟线程,都可以完成多任务
进程:一台电脑上登录多个QQ
线程:一个QQ中打开多个聊天窗口
① 线程共享全局变量,进程不共享
当一个进程结束时,不会对另一个进程产生影响
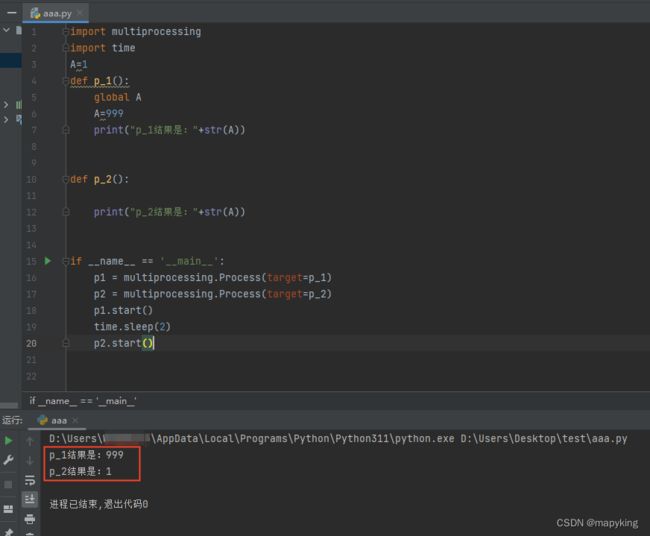
import multiprocessing
import time
A=1
def p_1():
global A
A=999
print("p_1结果是:"+str(A))
def p_2():
print("p_2结果是:"+str(A))
if __name__ == '__main__':
p1 = multiprocessing.Process(target=p_1)
p2 = multiprocessing.Process(target=p_2)
p1.start()
time.sleep(2)
p2.start()
此处A=999并没有传入p_2()
② 所有的线程都在同一个进程中
③ 线程开销小,但不利于资源的管理和保护,进程相反
6、进程池
由于进程创建跟关闭的开销大,可以使用进程池来让进程 “重复利用”
# 主进程
import multiprocessing
pool = multiprocessing.Pool(x) # 创建进程池,表示最多有x个进程同时运行
def p(num):
pass
# 往进程池中新增子进程,池满则等待前面进程结束后再往池里新增
for i in range(10):
pool.apply_async(p,(i,))
pool.close() # 关闭进程池
pool.join() # 主进程不会等待子进程结束再结束,需要添加pool.join()等待子进程全部结束后,先回收结束的子进程资源再开始主进程往下运行
① 案例1:
这个案例说明,从进程pid可以看出,进程可以重复利用,不需要重新新建进程与关闭进程
import multiprocessing
import time
import os
def p(num):
print("现在执行的是子进程",num)
print("子进程号是:",os.getpid())
time.sleep(1)
if __name__ == "__main__":
print("主进程号是:",os.getpid())
pool = multiprocessing.Pool(2)
for i in ['AA','BB','CC','DD','EE','ff']:
pool.apply_async(p,(i,))
pool.close()
pool.join()
print("主进程 {} 结束".format(os.getpid()))

② 进程池间通信
使用进程池中的queue
案例1:
import multiprocessing
q = multiprocessing.Manager().Queue() # 使用进程池中的queue
import multiprocessing
import os
import time
def task1(queue):
print("我是子进程1,进程号是:",os.getpid())
for i in ['AA','BB','CC','DD','EE','ff']:
queue.put(i)
print("从队列插入:",i)
time.sleep(2)
def task2(queue):
print("我是子进程2,进程号是:",os.getpid())
while 1:
try:
print("从队列取出:",queue.get(timeout=3))
time.sleep(1)
except multiprocessing.TimeoutError:
print("Queue is empty for 5 seconds, exiting...")
break
if __name__ == "__main__":
print("我是主进程,进程号是:",os.getpid())
pool_queue = multiprocessing.Manager().Queue() # 创建进程池队列
pool = multiprocessing.Pool(2) # 创建进程池
pool.apply_async(task1,(pool_queue,)) # 将task1加入进程池
time.sleep(1)
pool.apply_async(task2,(pool_queue,)) # 将task2加入进程池
pool.close()
pool.join()
print("主进程 {} 结束".format(os.getpid()))

7、协程(微线程)
协程是一种用户态的轻量级线程,它可以在单线程内实现多任务并发执行。在 Python 中,协程是通过 asyncio greenlet与gevent模块来实现的(但它们的实现方式不同,greenlet 是一个基于 C 语言实现的库,它提供了一种称为“微线程”的机制,可以在单个线程中运行多个协程,从而实现协程调度。它需要手动切换协程(gevent不用),即需要程序员显式地调用 greenlet.switch() 方法来切换到下一个协程。而 asyncio 是 Python 标准库中自带的异步 I/O 框架,它通过事件循环和协程来实现异步编程。它提供了类似于 greenlet 的协程机制,但是自动进行协程调度,即不需要程序员手动切换协程。总的来说,asyncio 更加高级和易用,而 greenlet 则更加底层和灵活)。使用协程可以提高程序的并发性能,避免线程切换的开销,同时还可以避免出现线程安全问题。
① greenlet
pip3 install greenlet
import greenlet
import time
def task1():
while 1:
print("我是协程1")
gr2.switch()
time.sleep(1)
def task2():
while 1:
print("我是协程2")
gr1.switch()
time.sleep(1)
gr1 = greenlet.greenlet(task1)
gr2 = greenlet.greenlet(task2)
gr1.switch()
② gevent
gevent 可以自动切换协程任务,当一个任务用到耗时操作时自动进行切换,以此实现多任务
pip3 install gevent
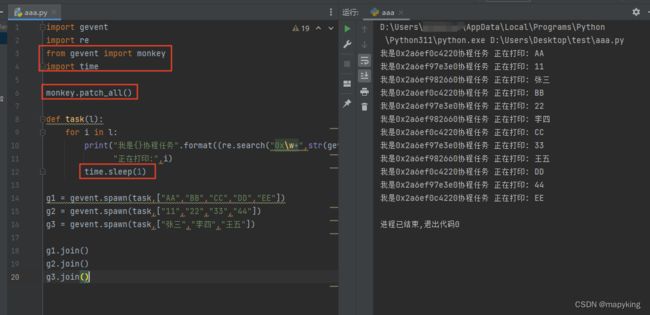
import gevent
import re
def task(l):
for i in l:
print("我是{}协程任务".format((re.search("0x\w+",str(gevent.getcurrent()))).group(0)),
"正在打印:",i)
gevent.sleep(1)
g1 = gevent.spawn(task,["AA","BB","CC","DD","EE"])
g2 = gevent.spawn(task,["11","22","33","44"])
g3 = gevent.spawn(task,["张三","李四","王五"])
g1.join()
g2.join()
g3.join()
#gevent.joinall([g1,g2,g3]) 等价以上三行

此处发现只能用gevent.sleep(1)进行耗时,time.sleep(1)无法生效,则可以导入monkey包解决
8、异步
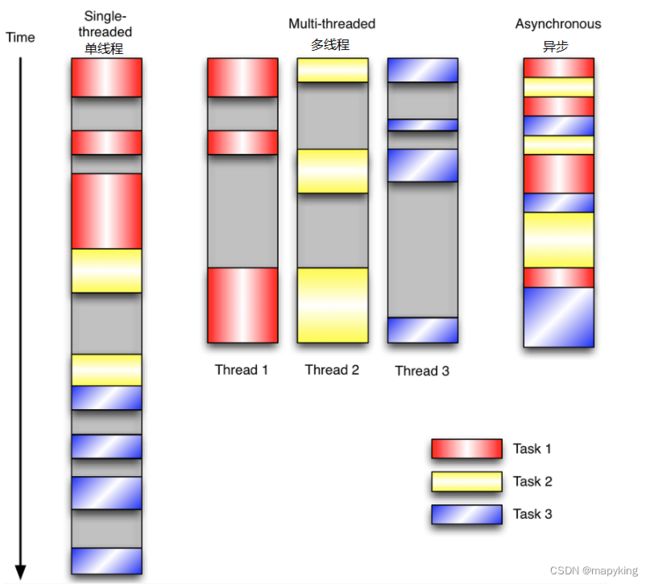
上图很好的说明了异步,在多线程例如
① task1在做下载数据的任务时,下载过程的“等待窗口期”可以执行别的task2、task3任务,
② 爬虫request发送请求到服务器,等待数据返回到客户端,也需要一个“等待窗口期”,这个时间段也可以执行task2、task3任务
① ascynio
python3.7+自带模块,底层实际只有一个线程,只适合I/O相关操作的代码,asyncio的核心是事件循环(event loop),它是一个无限循环,负责处理所有的异步任务。在事件循环中,可以注册多个协程作为异步任务,然后通过异步I/O操作(如网络请求、文件读写等)来切换协程的执行。
正常跑任务需要十多秒

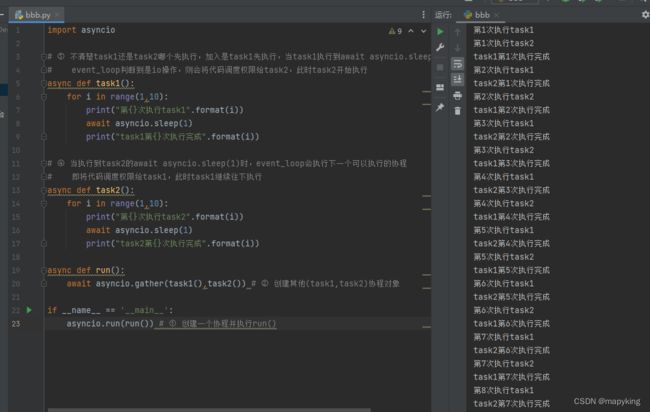
import asyncio
# ③ 不清楚task1还是task2哪个先执行,加入是task1先执行,当task1执行到await asyncio.sleep(1)时,
# event_loop判断到是io操作,则会将代码调度权限给task2,此时task2开始执行
async def task1():
for i in range(1,10):
print("第{}次执行task1".format(i))
await asyncio.sleep(1)
print("task1第{}次执行完成".format(i))
# ④ 当执行到task2的await asyncio.sleep(1)时,event_loop会执行下一个可以执行的协程
# 即将代码调度权限给task1,此时task1继续往下执行
async def task2():
for i in range(1,10):
print("第{}次执行task2".format(i))
await asyncio.sleep(1)
print("task2第{}次执行完成".format(i))
async def run():
await asyncio.gather(task1(),task2()) # ② 创建其他(task1,task2)协程对象
if __name__ == '__main__':
asyncio.run(run()) # ① 创建一个协程并执行run()
使用create_task可以获取更多任务的信息
例如task.result()获取返回值
import asyncio
import time
async def task1():
for i in range(1,5):
print("第{}次执行task1".format(i))
await asyncio.sleep(1)
print("task1第{}次执行完成".format(i))
return "task1 success"
async def task2():
for i in range(1,5):
print("第{}次执行task2".format(i))
await asyncio.sleep(1)
print("task2第{}次执行完成".format(i))
return "task2 success"
async def run():
# await asyncio.gather(task1(),task2())
t1 = asyncio.create_task(task1())
t2 = asyncio.create_task(task2())
await asyncio.wait([t1,t2])
print(t1.result())
print(t2.result())
if __name__ == '__main__':
print(time.time())
asyncio.run(run())
print(time.time())
② aiohttp
pip3 install aiohttp
aiohttp和asyncio是Python中的两个不同的库,它们分别用于处理异步HTTP请求和异步I/O操作。aiohttp是一个基于asyncio的HTTP客户端和服务器库。它提供了简单易用的API,用于发送HTTP请求和处理HTTP响应。aiohttp库使用asyncio提供的协程和异步I/O操作来实现非阻塞的HTTP请求和响应处理。
官方文档:https://docs.aiohttp.org/en/stable/
import asyncio
import time
import aiohttp
async def task1(baidu):
b_starttime = time.time()
async with aiohttp.ClientSession() as session:
async with session.get(baidu) as response:
responseResult = await response.text()
print(responseResult)
b_endtime = time.time()
print("访问百度时间:",b_endtime-b_starttime)
async def task2(jingdong):
jd_starttime = time.time()
async with aiohttp.ClientSession() as session:
async with session.get(jingdong) as response:
responseResult = await response.text()
print(responseResult)
jd_endtime = time.time()
print("访问京东时间:", jd_endtime - jd_starttime)
async def run():
# await asyncio.gather(task1(),task2())
t1 = asyncio.create_task(task1(baidu))
t2 = asyncio.create_task(task2(jingdong))
await asyncio.wait([t1,t2])
if __name__ == '__main__':
baidu = "https://www.baidu.com/"
jingdong = "https://www.jd.com/"
主程序开始时间 = time.time()
asyncio.run(run())
主程序结束时间 = time.time()
print("耗时:",主程序结束时间-主程序开始时间)