XXLJOB源码分析-问题记录
源码分析:基于2.2.0版本来分析
目录
一.客户端实现
1. 实现SmartInitializingSingleton的接口后,当所有单例 bean 都初始化完成以后, Spring的IOC容器会回调该接口
2.在initJobHandlerMethodRepository这个方法中,会扫描带有@XxlJob标识的类。把jobHandler的名字与jobHandler的信息关联起来
3.然后会去调用父类XxlJobExecutor的start方法。重要的方法initEmbedServer
二.服务端xxl-job-admin实现
1.XxlJobScheduler入口中
2.JobRegistryMonitorHelper.getInstance().start()会开启一个守护线程,每隔30秒扫描xxl_job_registry,就是上面的客户端注册的信息,如果90秒中没有更新信息,就把注册记录给删除,同时清空对应执行器中的地址
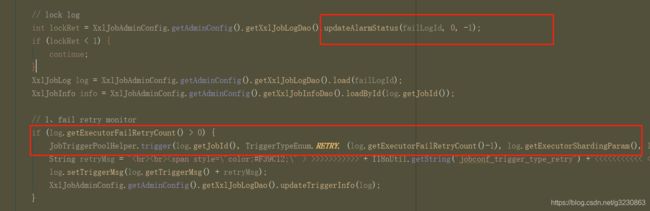
3.JobFailMonitorHelper.getInstance().start();会开启一个守护线程,每隔10秒扫描执行日志,如果配置了失败重试次数,把job的信息放到Job的线程池中进行执行,如果配置了预警邮箱,则发邮件通知
4.JobTriggerPoolHelper.toStart();XXL-JOb创建2个线程池 fastTriggerPool 与slowTriggerPool
5.JobScheduleHelper.getInstance().start(); 核心方法,定时扫描执行任务
6.最终通过控制台配置的路由策略进行调度,默认的是调用第一个地址,这里用了策略模式,默认的是获取地址的第一个
三.客户端执行
1.从之前客户端扫描XxlJob注解的jobHandler集合中根据name取出jobHandler信息,里面包括要执行的类与方法的信息
2.JobThread 从队列中取出刚刚存放的job信息,通过反射的模式来执行对应的方法
3.拿到结果后,会把结果方法一个队列中,TriggerCallbackThread会从这个队列中取到结果信息,然后调用HttpURLConnection工具类,调用xxl-job admin的api/callback接口,保存执行的日志结果,xxl-job admin也会根据这个日志来决定是否来失败重试
四.xxl-jobAdmin集群搭建
1.在host文件中修改映射地址: 127.0.0.1 jobadmin.com
2.配置nginx
3.修改客户端应用中xxljob的地址:
五.执行策略
1.第一个:取地址的第一个
2.轮询:根据调用的次数%地址的数量
3.一致性哈希
4.故障转移:发送心跳,找到第一个返回
5.最近最久未使用:使用了linkHashMap来实现
一.客户端实现
1. 实现SmartInitializingSingleton的接口后,当所有单例 bean 都初始化完成以后, Spring的IOC容器会回调该接口
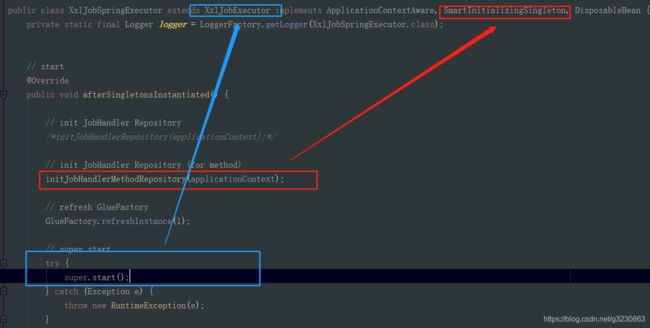
2.在initJobHandlerMethodRepository这个方法中,会扫描带有@XxlJob标识的类。把jobHandler的名字与jobHandler的信息关联起来
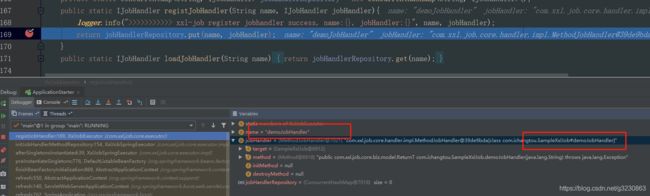
3.然后会去调用父类XxlJobExecutor的start方法。重要的方法initEmbedServer
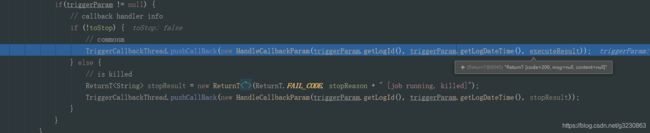
TriggerCallbackThread.getInstance().start(); 开启一个守护线程,如果发生错误,会进行重试
initEmbedServer 方法启动一个RPC Provider,如果不指定端口,默认情况下,会分配9999端口,如果9999端口被占用,会把端口号+1,比如1000,以此类推
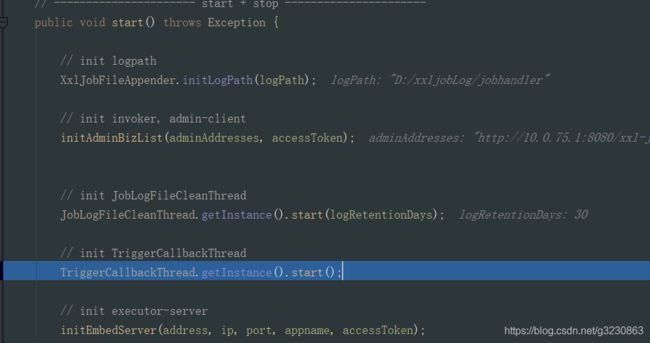
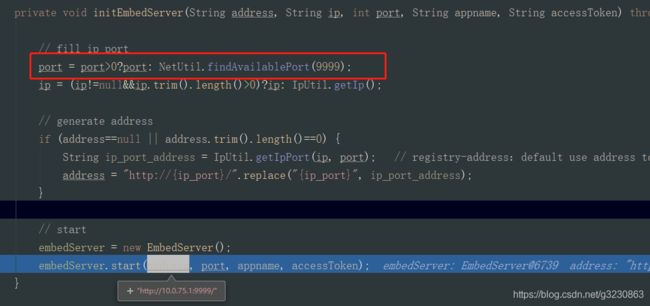
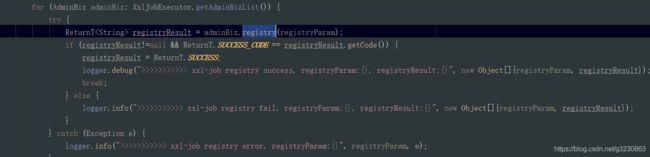
在里面会创建一个守护线程,客户端会调用接口 http://10.0.75.1:8080/xxl-job-admin/api/registry 每隔30秒进行注册。当返回200,则是注册成功,会往admin的数据库表中如果不存在,插入一条注册记录,存在就更新
xxl-job registry success, registryParam:RegistryParam{registryGroup='EXECUTOR', registryKey='xxl-job-test', registryValue='http://10.0.75.1:9999/'}, registryResult:ReturnT [code=200, msg=null, content=null]

![]()
![]()
二.服务端xxl-job-admin实现
1.XxlJobScheduler入口中

2.JobRegistryMonitorHelper.getInstance().start()会开启一个守护线程,每隔30秒扫描xxl_job_registry,就是上面的客户端注册的信息,如果90秒中没有更新信息,就把注册记录给删除,同时清空对应执行器中的地址
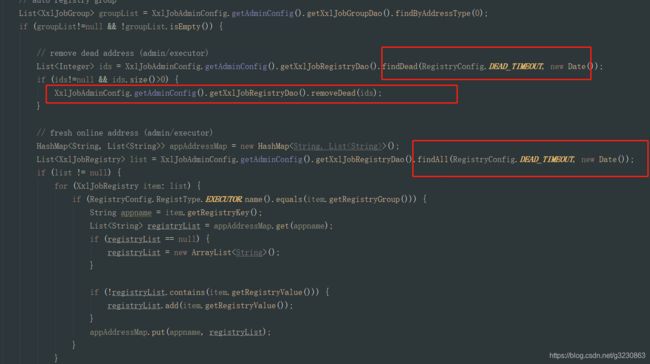
3.JobFailMonitorHelper.getInstance().start();会开启一个守护线程,每隔10秒扫描执行日志,如果配置了失败重试次数,把job的信息放到Job的线程池中进行执行,如果配置了预警邮箱,则发邮件通知
4.JobTriggerPoolHelper.toStart();XXL-JOb创建2个线程池 fastTriggerPool 与slowTriggerPool

5.JobScheduleHelper.getInstance().start(); 核心方法,定时扫描执行任务
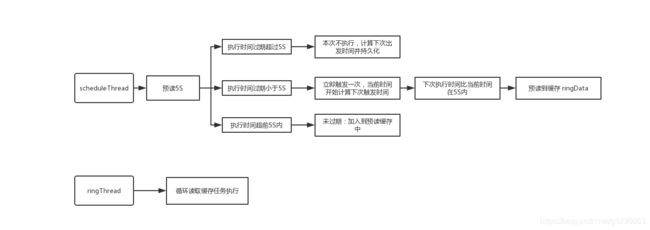
preparedStatement = conn.prepareStatement( "select * from xxl_job_lock where lock_name = 'schedule_lock' for update" );
首先利用for update语句进行获取任务的资格锁定,再去获取未来5秒内即将要执行的任务
(1) 第一个分支当前任务的触发时间已经超时5秒以上了,不在执行,直接计算下一次触发时间。
(2) 第二个分支为触发时间已满足,利用JobTriggerPoolHelper这个类进行任务调度,之后判断下一次执行时间如果在5秒内,进行此任务数据的缓存,处理逻辑与第三个分支一样。
核心方法是调用:JobTriggerPoolHelper.trigger(jobId, TriggerTypeEnum.CRON, -1, null, null, null);把任务加载到线程池中进行执行
try {
conn = XxlJobAdminConfig.getAdminConfig().getDataSource().getConnection();
connAutoCommit = conn.getAutoCommit();
conn.setAutoCommit(false);
preparedStatement = conn.prepareStatement( "select * from xxl_job_lock where lock_name = 'schedule_lock' for update" );
preparedStatement.execute();
// tx start
// 1、pre read
long nowTime = System.currentTimeMillis();
List scheduleList = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().scheduleJobQuery(nowTime + PRE_READ_MS, preReadCount);
if (scheduleList!=null && scheduleList.size()>0) {
// 2、push time-ring
for (XxlJobInfo jobInfo: scheduleList) {
// time-ring jump
if (nowTime > jobInfo.getTriggerNextTime() + PRE_READ_MS) {
// 2.1、trigger-expire > 5s:pass && make next-trigger-time
logger.warn(">>>>>>>>>>> xxl-job, schedule misfire, jobId = " + jobInfo.getId());
// fresh next
refreshNextValidTime(jobInfo, new Date());
} else if (nowTime > jobInfo.getTriggerNextTime()) {
// 2.2、trigger-expire < 5s:direct-trigger && make next-trigger-time
// 1、trigger
JobTriggerPoolHelper.trigger(jobInfo.getId(), TriggerTypeEnum.CRON, -1, null, null, null);
logger.debug(">>>>>>>>>>> xxl-job, schedule push trigger : jobId = " + jobInfo.getId() );
// 2、fresh next
refreshNextValidTime(jobInfo, new Date());
// next-trigger-time in 5s, pre-read again
if (jobInfo.getTriggerStatus()==1 && nowTime + PRE_READ_MS > jobInfo.getTriggerNextTime()) {
// 1、make ring second
int ringSecond = (int)((jobInfo.getTriggerNextTime()/1000)%60);
// 2、push time ring
pushTimeRing(ringSecond, jobInfo.getId());
// 3、fresh next
refreshNextValidTime(jobInfo, new Date(jobInfo.getTriggerNextTime()));
}
} else {
// 2.3、trigger-pre-read:time-ring trigger && make next-trigger-time
// 1、make ring second
int ringSecond = (int)((jobInfo.getTriggerNextTime()/1000)%60);
// 2、push time ring
pushTimeRing(ringSecond, jobInfo.getId());
// 3、fresh next
refreshNextValidTime(jobInfo, new Date(jobInfo.getTriggerNextTime()));
}
}
// 3、update trigger info
for (XxlJobInfo jobInfo: scheduleList) {
XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().scheduleUpdate(jobInfo);
}
} else {
preReadSuc = false;
}
// tx stop
} catch (Exception e) {
if (!scheduleThreadToStop) {
logger.error(">>>>>>>>>>> xxl-job, JobScheduleHelper#scheduleThread error:{}", e);
}
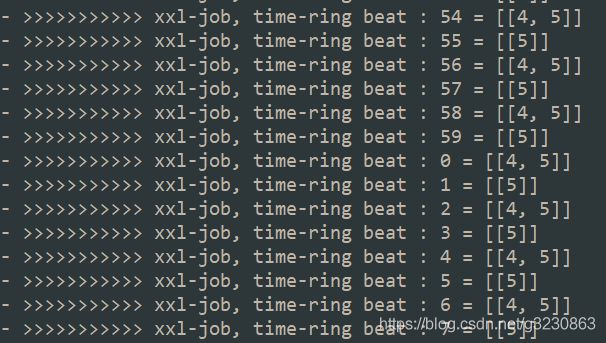
} 对于第二分支5秒内预加载任务,与第三分支,把每个定时任务都是放到一个环中,会计算出每秒要执行的任务,然后有一个守护线程读取环中数据,进行任务调度
时间轮的相关文章:
https://juejin.im/post/6844903954145361927
https://m.imooc.com/article/311069


6.最终通过控制台配置的路由策略进行调度,默认的是调用第一个地址,这里用了策略模式,默认的是获取地址的第一个
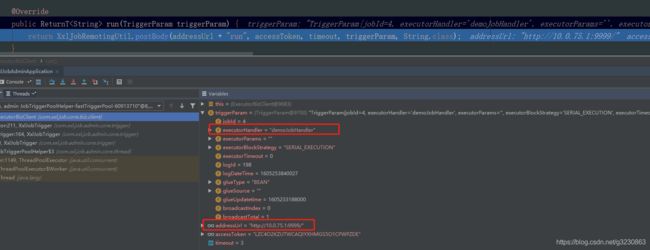
XxlJobTrigger.trigger方法-》XxlJobTrigger.trigger()-》processTrigger()方法进行调度

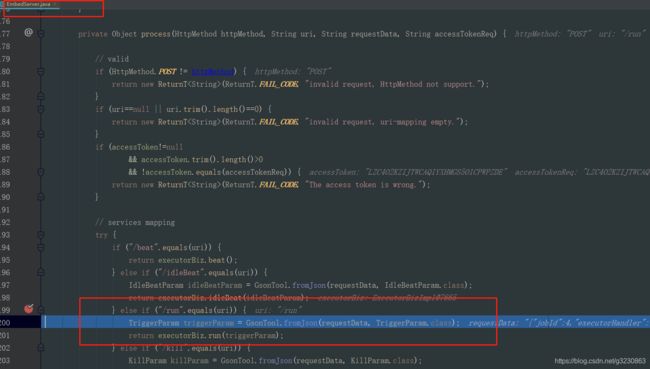
会使用HttpURLConnection发送Post请求http://10.0.75.1:9999/run到客户端,执行执行代码。
三.客户端执行
1.从之前客户端扫描XxlJob注解的jobHandler集合中根据name取出jobHandler信息,里面包括要执行的类与方法的信息


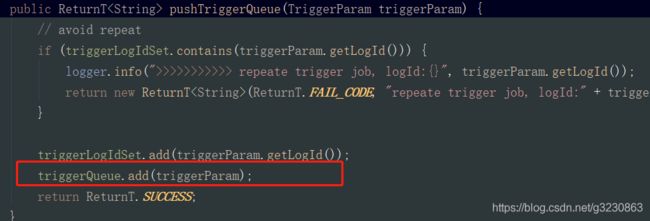
把要执行的job放到队列中
2.JobThread 从队列中取出刚刚存放的job信息,通过反射的模式来执行对应的方法
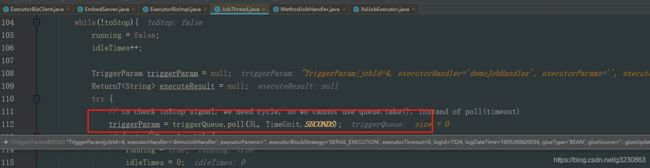

3.拿到结果后,会把结果方法一个队列中,TriggerCallbackThread会从这个队列中取到结果信息,然后调用HttpURLConnection工具类,调用xxl-job admin的api/callback接口,保存执行的日志结果,xxl-job admin也会根据这个日志来决定是否来失败重试


四.xxl-jobAdmin集群搭建

1.在host文件中修改映射地址: 127.0.0.1 jobadmin.com
2.配置nginx
#user nobody;
worker_processes 1;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
upstream jobadmin.com { #服务器集群名字
server 127.0.0.1:18080 weight=1;#服务器配置 weight是权重的意思,权重越大,分配的概率越大。
server 127.0.0.1:28080 weight=1;
}
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html;
proxy_pass http://jobadmin.com;
index index.html index.htm;
}
}
}3.修改客户端应用中xxljob的地址:
xxl.job.admin.addresses=http://jobadmin.com/xxl-job-admin五.执行策略
1.第一个:取地址的第一个

2.轮询:根据调用的次数%地址的数量
- 轮询策略是第一次随机找一台机器执行,后续执行会将索引加1取余
- 轮询策略依赖 addressList 的顺序,如果这个顺序变了,索引到下一次的机器可能不是期望的顺序
public class ExecutorRouteRound extends ExecutorRouter {
private static ConcurrentMap routeCountEachJob = new ConcurrentHashMap();
private static long CACHE_VALID_TIME = 0;
private static int count(int jobId) {
// cache clear
if (System.currentTimeMillis() > CACHE_VALID_TIME) {
routeCountEachJob.clear();
CACHE_VALID_TIME = System.currentTimeMillis() + 1000*60*60*24;
}
// count++
Integer count = routeCountEachJob.get(jobId);
count = (count==null || count>1000000)?(new Random().nextInt(100)):++count; // 初始化时主动Random一次,缓解首次压力
routeCountEachJob.put(jobId, count);
return count;
}
@Override
public ReturnT route(TriggerParam triggerParam, List addressList) {
String address = addressList.get(count(triggerParam.getJobId())%addressList.size());
return new ReturnT(address);
} 3.一致性哈希
一致性哈希可以查看这个,xxljob用到的是tailMap()方法,找到大于等于自己hash(key)的集合,如果找到就取最接近的一个。
https://blog.csdn.net/g3230863/article/details/109724696
https://www.yiibai.com/java/util/treemap_tailmap.html
public String hashJob(int jobId, List addressList) {
// ------A1------A2-------A3------
// -----------J1------------------
TreeMap addressRing = new TreeMap();
for (String address: addressList) {
for (int i = 0; i < VIRTUAL_NODE_NUM; i++) {
long addressHash = hash("SHARD-" + address + "-NODE-" + i);
addressRing.put(addressHash, address);
}
}
long jobHash = hash(String.valueOf(jobId));
SortedMap lastRing = addressRing.tailMap(jobHash);
if (!lastRing.isEmpty()) {
return lastRing.get(lastRing.firstKey());
}
return addressRing.firstEntry().getValue();
} 4.故障转移:发送心跳,找到第一个返回
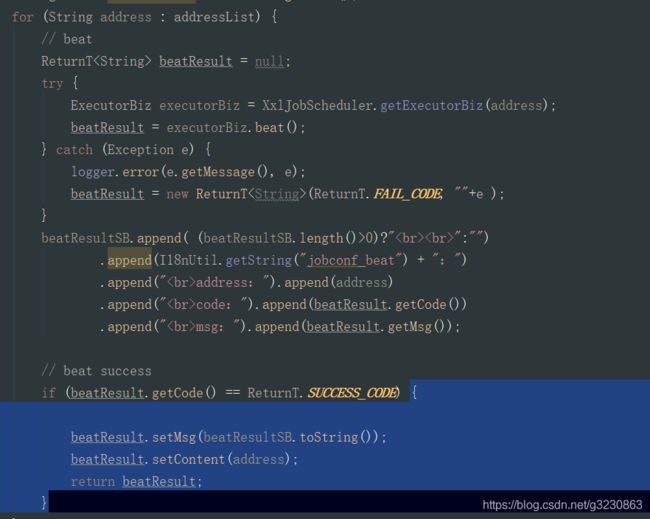
5.最近最久未使用:使用了linkHashMap来实现
LRU算法第一次执行会把所有地址加载进来并缓存,从第一个地址开始执行,即使 addressList 地址顺序变了也不影响次数
// init lru
LinkedHashMap lruItem = jobLRUMap.get(jobId);
if (lruItem == null) {
/**
* LinkedHashMap
* a、accessOrder:true=访问顺序排序(get/put时排序);false=插入顺序排期;
* b、removeEldestEntry:新增元素时将会调用,返回true时会删除最老元素;可封装LinkedHashMap并重写该方法,比如定义最大容量,超出是返回true即可实现固定长度的LRU算法;
*/
lruItem = new LinkedHashMap(16, 0.75f, true);
jobLRUMap.putIfAbsent(jobId, lruItem);
}
// put new
for (String address: addressList) {
if (!lruItem.containsKey(address)) {
lruItem.put(address, address);
}
} 
问题记录
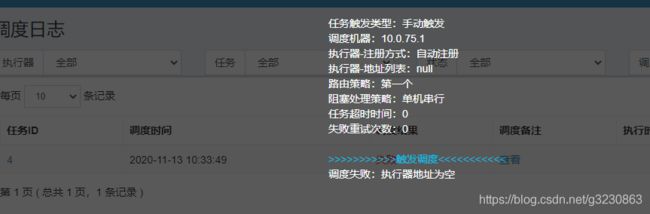
1.执行器地址为空的问题:
原因:没有在配置在对应的执行器下,执行任务,所以代码取到的执行器的地址是空的。

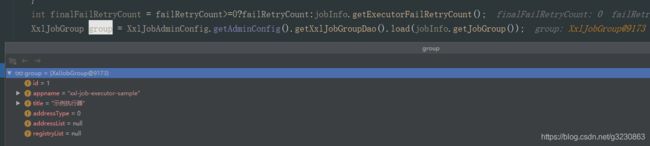
参考:https://www.cnblogs.com/jiangyang/p/11576931.html
https://www.cnblogs.com/guoyinli/p/11555035.html
https://blog.csdn.net/u012394095/article/details/79552533