redis 跳跃表、字典、压缩列表、快速列表
redis 跳跃表、字典、压缩列表、快速列表
1. 跳跃表
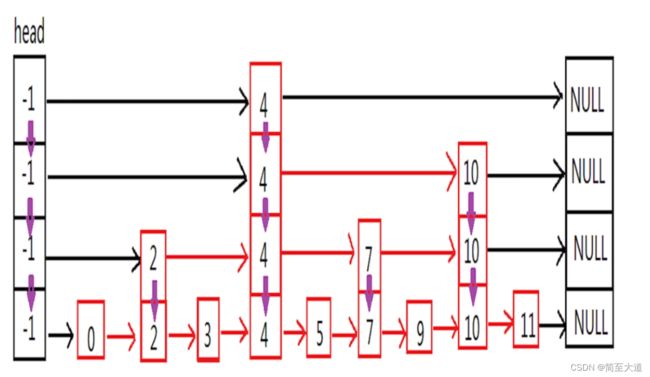
跳跃表是有序集合的底层实现。就是将有序集合的部分节点进行分层。每一层都是有序集合,并且层次越高,节点数量就越少。最底层的包含所有节点数据。典型的空间换时间。
Redis中的跳跃表(Skip List)是一种数据结构,用于实现有序集合(Sorted Set)。它是一种有序的、分层的链表结构,可以提供快速的插入、删除和查找操作。
跳跃表通过在链表中添加多级索引来加速查找操作,使得在有序集合中的元素可以更快地被定位。每一级索引称为一个层,具有一定的间隔。跳跃表中的每个节点包含了一个值和多个指针,指向下一级的节点。
跳跃表的插入、删除和查找操作都具有较好的平均时间复杂度,接近于O(log N),其中N是有序集合的元素数量。相比于传统的有序链表或平衡二叉树,跳跃表的实现更加简单,且具有较好的性能。
在Redis中,跳跃表主要用于实现有序集合数据类型,通过跳跃表可以高效地支持元素的按照分数(score)进行排序和检索。跳跃表中的每个节点都包含一个元素的值和分数,元素按照分数进行有序存储。跳跃表还支持按照索引范围获取一定区间的元素,如获取分数在指定范围内的元素。
需要注意的是,跳跃表在插入和删除操作时,可能会进行索引调整和层级重构的操作,以保持跳跃表的平衡性和性能。这些操作在维护有序集合时是透明执行的,对用户来说是不可见的。
空间换时间
跳跃表通过在链表中添加多级索引来提高查找的效率,从而牺牲了一定的空间复杂度以换取更快的查询速度。通过添加索引层,跳跃表可以跳过一些节点,直接到达目标节点的附近,从而减少了查找的时间复杂度。
在跳跃表中,节点的数量和索引层数量之间存在着平衡。更多的索引层可以提高查找的效率,但会增加索引层的空间占用。因此,跳跃表的空间复杂度会随着索引层数的增加而增加,但相对于传统的有序链表或平衡树结构,跳跃表的空间占用仍然相对较小。
通过空间换时间的策略,跳跃表可以在较低的时间复杂度内实现插入、删除和查找操作。它在大多数情况下能够提供接近O(log N)的平均时间复杂度,其中N是元素的数量。这使得跳跃表成为一种高效的有序集合实现方式。
需要注意的是,跳跃表的空间复杂度O(n)可能会比其他数据结构稍高,特别是当需要添加大量索引层时。因此,在应用中选择使用跳跃表时,需要根据具体的需求和资源限制进行权衡和评估。
跳跃表的随机函数
跳跃表中的随机函数用于决定节点是否升级到更高层级的索引,以平衡跳跃表的结构和提高查询效率。
在跳跃表(Skip List)中,随机函数用于决定节点是否升级到更高层级的索引。跳跃表的多级索引结构是通过层级之间的指针链接实现的,而随机函数的作用是控制节点在哪些层级上存在索引。
具体来说,随机函数在插入新节点时被用来决定节点是否升级到更高层级。当新节点被插入到跳跃表中时,根据设定的概率阈值,随机函数生成一个随机数。如果随机数满足升级条件,即在概率阈值内,那么新节点将被插入到更高层级的索引中。
通过随机函数来决定节点是否升级到更高层级的索引,可以确保跳跃表的平衡性和性能。如果没有随机函数,所有节点都会被插入到最高层级的索引中,这将导致跳跃表的查询性能下降。
通过随机函数的引入,跳跃表可以在插入新节点时动态地决定节点的层级分布,使得节点在不同层级上的分布更加均匀,提高了查询效率。同时,通过调整随机函数的概率阈值,还可以对跳跃表的结构进行灵活的控制,以适应不同数据集和查询模式的需求。
跳跃表和b+树对比
在一般情况下,B+树相对于跳跃表来说更加占用空间。
B+树是一种平衡树结构,每个节点包含多个键和对应的子节点,叶子节点形成有序链表。B+树的每个节点都需要存储键和子节点的信息,以及一些管理结构和指针。相对于链表结构的跳跃表,B+树在每个节点上存储的数据量更多,所以通常会占用更多的存储空间。
跳跃表在每个节点中只需要存储值和指向下一级节点的指针,而B+树的节点需要存储键、值和子节点的指针。此外,B+树的节点结构相对复杂,可能包含额外的管理信息(如节点的层级、父节点的指针等),这也会占用一定的空间。
虽然跳跃表需要额外的索引层来提供快速的查找,但是它相对于B+树来说在整体结构和节点的存储上更加简单,所以通常情况下跳跃表相对更加节省空间。
需要根据具体的应用场景和需求选择适合的数据结构。如果空间占用是一个关键因素,而查询效率相对次要,可以考虑使用跳跃表。如果查询效率是首要考虑的因素,并且可以承担更高的空间占用,可以选择B+树。
2.字典
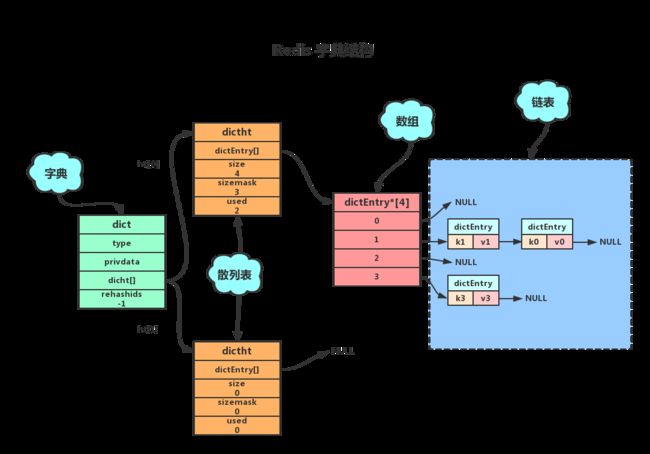
Redis 的字典是一种高效的键值对存储结构,用于实现 Redis 中的多个功能,提供快速的查找和插入操作,并支持动态扩容和冲突处理。
Redis的字典(Dictionary)是一种用于存储键值对的数据结构。它在 Redis 中被广泛应用,用于实现 Redis 的核心数据结构之一——哈希表。
字典的作用是提供高效的键值对存储和查找。在 Redis 中,字典被用于实现键的存储和索引,它是实现 Redis 数据库中键值对存储和快速访问的重要组件。
字典的特点包括:
- 高效的查找和插入操作:字典使用哈希表作为底层实现,通过哈希算法将键映射到哈希表的索引位置,从而实现快速的查找和插入操作。平均情况下,字典的查找和插入操作的时间复杂度为 O(1)。
- 动态扩容:字典的大小是可以动态调整的,当字典的负载因子达到一定阈值时,会自动触发扩容操作,重新调整哈希表的大小,以保证字典的性能和空间效率。
- 冲突处理:由于哈希算法不可避免地会出现键的冲突(多个键映射到同一个哈希表索引位置),字典使用链地址法(拉链法)来解决冲突。具体来说,每个哈希表索引位置上维护一个链表,将映射到同一索引的键值对链接在一起。
在 Redis 中,字典被广泛应用于多个功能的实现,例如:
- 实现 Redis 的键空间:Redis 数据库中的所有键以及与之对应的值都存储在字典中。
- 哈希类型的底层实现:Redis 的哈希类型使用字典来存储键值对,实现了快速的字段查找和插入操作。
- 命令的实现:Redis 的命令字典用于存储命令名称和对应的命令处理函数。
字典的实现
Redis的字典是通过哈希表实现的,哈希表使用数组存储键值对,通过哈希函数计算键的索引位置,使用线性探测法解决冲突,支持动态扩容。这种实现方式使得Redis的字典具有快速的查找和插入操作,并能够处理大量的键值对。
哈希表是一种基于哈希函数的数据结构,它通过将键映射到哈希表的索引位置来实现快速的查找和插入操作。在Redis中,哈希表被用作字典的底层实现。
Redis的哈希表采用开放地址法(Open Addressing)来解决键的冲突。具体实现上,Redis使用的是线性探测法(Linear Probing),当发生冲突时,会按照一定的步长依次探测哈希表的下一个位置,直到找到一个空槽来存储键值对。
下面是Redis哈希表的主要组成部分:
-
哈希表数组:Redis的哈希表由一个数组构成,每个数组元素称为哈希表节点(Hash Table Node)。每个节点存储了一个键值对,包括键和值的指针。
-
哈希函数:Redis使用一种双重哈希函数(Double Hashing)来计算键的哈希值,并将哈希值映射到数组的索引位置。
-
冲突解决:当多个键映射到同一个索引位置时,发生了冲突。Redis使用线性探测法来解决冲突,即依次检查下一个位置,直到找到一个空槽。

-
动态扩容:当哈希表的负载因子超过一定阈值时,Redis会触发扩容操作,重新分配更大的数组,并将现有的键值对重新插入到新的哈希表中。这样可以保持哈希表的性能和空间效率。
3.压缩列表

压缩列表通过紧凑的存储方式、分层结构和数据压缩技术实现了高效的存储和表示方式。它在 Redis 中被广泛应用于列表和有序集合的存储,以及相关操作的实现。压缩列表的设计使得 Redis 可以在较小的内存占用下存储大量的元素,提供了高效的数据结构支持。
压缩列表(Compressed List)是 Redis 中用于存储和表示列表和有序集合的一种数据结构。它采用紧凑的方式存储多个元素,通过连续的内存块来减少存储空间的占用。
压缩列表的实现方式相对简单,下面是它的主要特点和实现原理:
- 紧凑存储:压缩列表将多个元素紧凑地存储在一块连续的内存区域中,避免了元素之间的指针开销,从而减少了存储空间的占用。
- 有序性:压缩列表中的元素按照插入顺序排列,并且支持按照元素的位置索引进行快速访问。
- 灵活的数据类型支持:压缩列表可以用于存储列表(List)和有序集合(Sorted Set)两种数据类型。它可以存储不同类型的元素,例如整数、浮点数和字节数组等。
- 分层结构:压缩列表可以分为多个层级,每个层级包含一系列连续的节点。每个节点包含一个字节数组来存储元素数据,并带有一些控制信息,如元素长度和编码方式。
- 数据压缩:为了进一步减少存储空间的占用,压缩列表使用不同的编码方式来表示不同长度的元素。根据元素的长度,可以选择使用整型编码、字节数组编码或者整型浮点数编码。
压缩列表优缺点
压缩列表在存储空间效率和插入/删除操作的性能上具有优势。然而,在随机访问和遍历操作方面可能存在一些开销。因此,在选择数据结构时,需要根据具体的使用场景和需求来权衡压缩列表的优缺点。
优点:
- 紧凑的存储形式:压缩列表采用紧凑的存储方式,通过连续的内存块存储多个元素,避免了指针开销,减少了存储空间的占用。
- 快速的插入和删除操作:由于数据的紧凑存储形式,压缩列表在插入和删除操作上表现出色。它可以在常数时间内进行这些操作,而不会受到内存分配和指针调整的开销。
- 有序性和快速的索引访问:压缩列表中的元素按照插入顺序排列,并且支持按照位置索引进行快速访问。通过偏移量计算,可以在常数时间内访问特定位置的元素。
- 简单的实现和高效的内存管理:相对于其他数据结构,压缩列表的实现相对简单,减少了额外的数据结构开销。此外,它还能有效地利用内存,因为它不需要为每个元素分配独立的节点。
缺点:
- 随机访问开销:虽然压缩列表支持按照位置索引进行快速访问,但对于大型列表,随机访问的性能会受到限制。这是因为压缩列表不具备像数组那样的连续内存访问特性,而是通过偏移量进行跳跃式访问。
- 遍历开销:由于压缩列表是紧凑存储的,遍历整个列表的开销相对较高。如果需要频繁地进行遍历操作,可能会影响性能。
- 更新操作的复杂性:对于较大的压缩列表,插入和删除操作可能涉及到数据的移动和内存的重新分配,这会带来一定的复杂性和开销。
4.快速列表
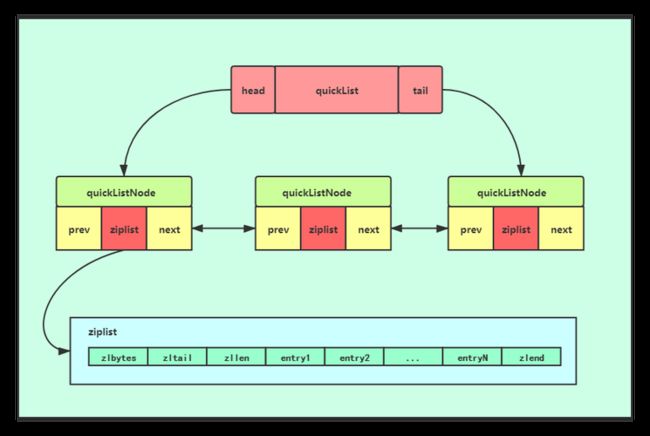
快速列表(Quicklist)是 Redis 中用于存储和表示列表的一种数据结构。它是为了解决 Redis 列表在插入和删除操作上的性能问题而引入的一种优化数据结构。
快速列表的设计思想是将一个列表分割成多个小的压缩列表片段,每个片段称为一个节点(Node)。每个节点都是一个压缩列表,使用压缩列表的紧凑存储方式来存储多个元素。
快速列表的实现方式如下:
- 链表结构:快速列表是由多个节点(Node)组成的双向链表。每个节点表示一个压缩列表片段。
- 压缩列表片段:每个节点是一个压缩列表,它使用紧凑的方式存储多个元素。压缩列表片段的大小可以根据需要进行调整,以平衡内存占用和操作性能。
- 节点指针:每个节点都有一个前向指针和一个后向指针,用于将所有节点连接成一个双向链表。
快速列表在列表操作中的性能表现如下:
- 在头部和尾部插入和删除操作上,快速列表可以在常数时间内完成,因为只需要操作链表的指针,无需移动其他元素。
- 在中间位置的插入和删除操作上,快速列表的性能可能受到影响,因为需要找到插入或删除位置所在的节点,然后对节点中的压缩列表进行修改。
快速列表的优势在于它将大型列表分割成多个小的压缩列表片段,从而在插入和删除操作上提供了较好的性能。它可以同时兼顾内存占用和操作效率。通过链表结构,快速列表还支持在头部和尾部进行快速的插入和删除操作。
表的性能可能受到影响,因为需要找到插入或删除位置所在的节点,然后对节点中的压缩列表进行修改。
快速列表的优势在于它将大型列表分割成多个小的压缩列表片段,从而在插入和删除操作上提供了较好的性能。它可以同时兼顾内存占用和操作效率。通过链表结构,快速列表还支持在头部和尾部进行快速的插入和删除操作。
需要注意的是,快速列表主要针对 Redis 中的列表数据类型进行了优化,不适用于其他数据结构。它是 Redis 在列表操作上的一种优化策略,提供了更好的性能和内存管理。