pandas 笔记:pivot_table 数据透视表
1 基本使用方法
pandas.pivot_table(
data,
values=None,
index=None,
columns=None,
aggfunc='mean',
fill_value=None,
margins=False,
dropna=True,
margins_name='All',
observed=False,
sort=True)
2 主要参数
| data | DataFrame |
| values | 要进行聚合的列 |
| index | 在数据透视表索引(index)上进行分组的键 |
| columns | 在数据透视表列(column)上进行分组的键 |
| agg_func | 聚合方式 |
| fill_value | 缺省值的填充方式,默认为NAN |
| margins | 默认为False,设置为True之后,会计算一个总的value值 |
3 使用方法
3.0 导入数据
import pandas as pd
# Visual Python: Data Analysis > File
vp_df = pd.read_csv('https://raw.githubusercontent.com/visualpython/visualpython/main/visualpython/data/sample_csv/tips.csv')
import seaborn as sns
import numpy as np
vp_df.head()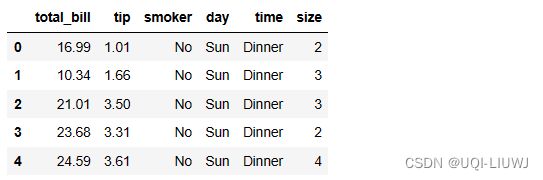
3.1 基本使用
vp_df.pivot_table(index='day',
columns='time',
values='total_bill')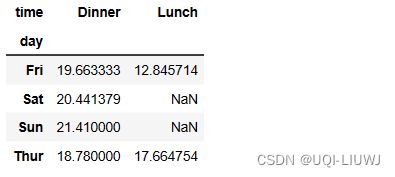
3.2 index
- aggfunc默认按平均值聚合,values默认只显示可以按平均值聚合的数据
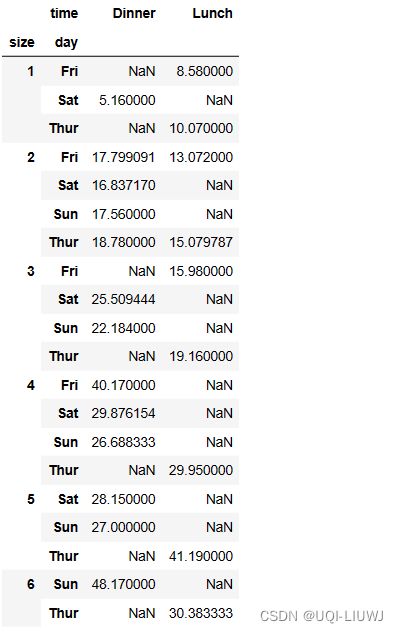
index为一列名字的效果如3.1所示,多列的话,效果如下
vp_df.pivot_table(index=['day','size'],
columns='time',
values='total_bill')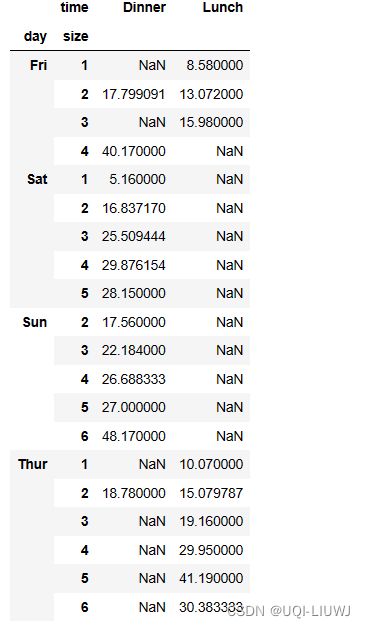
顺序不同,效果也不同
3.3 values
筛选需要显示的列
values 中一个元素的结果和3.1一样,如果是多个元素,那就是一个value的透视表之后接另一个:
vp_df.pivot_table(index='day',
columns='time',
values=['total_bill','size'])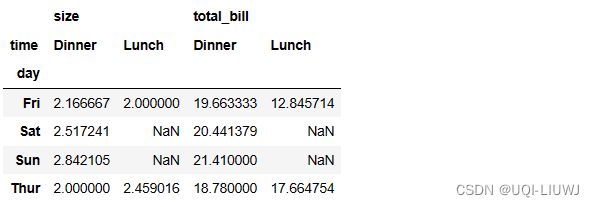
3.4 columns
列索引
columns中一个元素的结果和3.1一样,如果是多个元素,那就是
vp_df.pivot_table(index='day',
columns=['time','size'],
values='total_bill')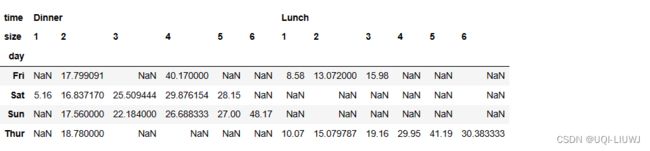
3.5 aggfunc
聚合方式,默认为求平均
vp_df.pivot_table(index='day',
columns='time',
values='total_bill',
aggfunc=sum)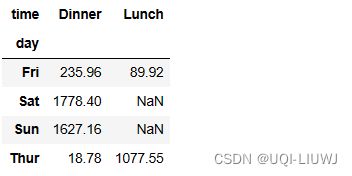
3.5.1 不同的列不同的聚合方式
vp_df.pivot_table(index='day',
columns='time',
values=['total_bill','size'],
aggfunc={'total_bill':sum,'size':min},
margins=True)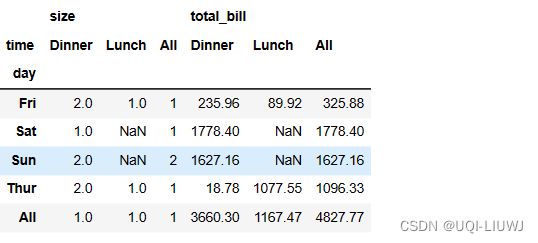
3.5 fill_value
vp_df.pivot_table(index='day',
columns='time',
values='total_bill',
fill_value='Not a Num')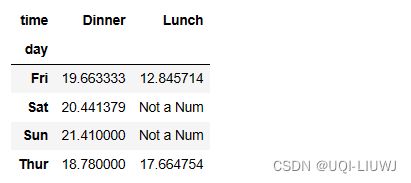
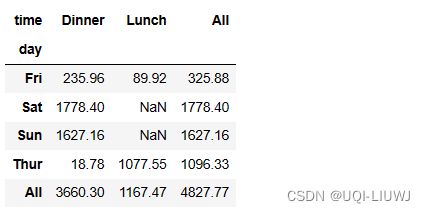
3.6 margins
vp_df.pivot_table(index='day',
columns='time',
values='total_bill',
aggfunc=sum,
margins=True)