Python爬虫+flask框架+数据库ORM+数据分析+前端三件套
Pyu可视化爬虫
最近跟着课程学了一下py并且做了一个豆瓣top250电影的爬虫+flask网络框架+orm数据库框架+数据分析的小项目,用到的知识都很浅,做一下总结。
完成本项目大概需要以下几个步骤:
- 利用py爬虫技术爬取从豆瓣网站上爬取电影的基本信息。
- 将爬取到的数据存储到入数据库。
- 利用网络框架搭建后台服务
- 做好可视化的前端界面与后端进行交互
- 数据分析
下面详细的介绍一下各个部分的技术栈。
一、py爬虫
1、导入库
这些库我是用pycharm直接下载的。
import urllib.request#获取网页数据
from bs4 import BeautifulSoup#解析得到网页源码
import re #利用正则表达式对所需进行网页的捕获
import xlwt #excle操作
import sqlite3 #数据库操作
2、请求网页资源
def askUrl(url):
header={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/120.24.206.208"#键值对 发送头部信息 伪装浏览器
}
html=""
req = urllib.request.Request(url=url, headers=header)#get请求
#req = urllib.request.Request(url=url, headers=header,method='POST') post请求
try:
responce=urllib.request.urlopen(req)
html=responce.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
这里有几个注意的点,首先因为很多网页是不允许以爬虫的方式请求得到网页资源的,所以我们必须封装一些信息,来伪装为浏览器的形式,这个信息就利用header这个键值对保存,连同请求一并发给网页服务,至于这个header中的信息从何得知,我们就直接以浏览器访问网页使用开发者工具的形式找到请求标头中的User-Agent用户代理所对应的信息。如下图:

利用urlib库提供的Request将网页url和头部信息header封装好,利用urlopen进行网页请求访问(get请求),也可发送post请求,只需在url后加上/post以及在Request中的method参数设置为POST即可。
3、解析网页
#括号内是要查找的内容!!!!!正则表达式创建模式对象pattern
findlink=re.compile(r'') #生成正则表达式制定寻找规则 r是为了防止转义
findimg=re.compile(r',re.S)#re.S使的.号匹配所有换行符在内的字符
findname=re.compile(r'(.*)')#找到影片名
findscore=re.compile(r'')#找到影片评分
findpeople=re.compile(r'(\d*)人评价')#评论人数
findinq=re.compile(r'(.*)')#概述
findirector=re.compile(r'(.*)
'
,re.DOTALL)#导演和演员
#获取数据
def getData(baseurl):
datalist=[]
for i in range(0,10):
url=baseurl + str(i*25)#调用页面信息十次
html=askUrl(url)#保存获取的网页源码
#解析得到的网页源码
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):#div同时里面有一个class属性 形成列表
data=[]
# print(item)
#item是靓汤通过搜索关键字符得到的html块
item=str(item)#转为正则表达式要查找的字符串 得到想要的字符串
link=re.findall(findlink,item)[0]#第一个参数是正则表达式的模式对象parttern 第二个参数是被查找的字符串
data.append(link)
# print(link)
img=re.findall(findimg,item)[0]
data.append(img)
# print(img)
name=re.findall(findname,item)[0]
data.append(name)
# print(name)
score=re.findall(findscore,item)[0]
data.append(score)
# print(score)
people=re.findall(findpeople,item)[0]
data.append(people)
# print(people)
inq=re.findall(findinq,item)
if len(inq)!=0:
inq[0]=inq[0].replace('。','')
res=""
for i in inq:
res=res+i
data.append(res)
else:
data.append("")#留空
# print(inq)
html2=re.sub(r'\n','',item)#把换行符去掉!!!!!
director=re.findall(findirector,html2)[0]
director=director.replace("/","")
# print(director.strip())
data.append(director.strip())#去掉前面的空格
datalist.append(data)
return datalist#以列表的形式返回250部电影的信息
解析网页利用到的技术栈比较多。askUrl()请求网页资源的得到的不是真正的html源码,所以这时候我们就需要利用bs4库中的Beautifulsoup(靓汤)的html解析器来解析网页返回给我们的资源,使之变成我们能看懂的html源码。得到源码后,我们的目的是爬取html源码上的一些信息,并不是全部,所以这就要根据我们的需求去观察不同网页上的信息和规律,利用靓汤返回的soup的一系列定位方法(需要自己去了解)返回你所需要的html版块。但是我们的目的不是得到html代码,而是得到嵌套在html代码中的的信息。这个时候就要利用py提供的re库正则表达式来进行信息的提取。正则表达式:字符串表达式 判断字符是否符合一定的标准!!(re中正则表达式的使用建议自己去查)。
二、将数据存储数据库
我们这个项目使用的数据库是sqlite数据库,这是一种存储在一个单一的跨平台的磁盘文件,是一个及其轻量的数据库。
1、创建数据库
在pycharm中的步骤:
点击数据库->新建->数据源->sqlIte
2、连接数据库
import sqlite3
def saveData(datalist,savepath):
try:
conn=sqlite3.connect(savepath)#连接数据库 若没有该数据库将会在该目录自动生成一个sqlite数据库
c=conn.cursor()#获取一个游标
for data in datalist:
for i in range(len(data)):
if i == 3 or i == 4: # 整形和浮点型不变
continue
data[i]='"'+data[i]+'"'#匹配sql语句
sql='insert into Movie values(%s)'%(",".join(data))#一些列操作目的均是为了匹配sql语句
print(sql)
c.execute(sql)
conn.commit()
c.close()
conn.close()
except Exception as e:
print("出错了")
这种方式是sqlite库中的原生方法,使用sql语句对数据库进行操作。后面我会用到一个orm(对象关系映射)框架就不需要使用sql语句了。
3、将数据存入数据库
def main():
# savepath="豆瓣电影250.xls"
# saveData(datalist,savepath)
datalist = getData("https://movie.douban.com/top250?start=")
savepath="moviemessage.db"
saveData(datalist,savepath)
if __name__ == '__main__':
main()
# print("爬取完毕")
三、flask框架搭建后端服务
1、框架的基本使用
首先是要在pycharm中创建一个flask项目,或者手动导包,利用pip工具等。(pycharm巨方便)
from flask import Flask,render_template
import getDbData.getDbdata
app = Flask(__name__)#将框架导入该程序
@app.route('/')#路由解析,用户提供访问路径匹配对应的函数
def index(): # put application's code here
return render_template('index.html')
@app.route('/index')
def home(): # put application's code here
return index()
@app.route('/table')
def table():
list=getDbData.getDbdata.GetDate1()
return render_template('movieTable.html',list=list)
@app.route('/people')
def people():
peopllist=getDbData.getDbdata.GetData3()
return render_template('peopleTable.html',peopllist=peopllist)
@app.route('/score')
def score():
scorelist,counts=getDbData.getDbdata.GetDate2()
return render_template('scoreTabale.html',scorelist=scorelist,counts=counts)
@app.route('/relate')
def relate():
averagelist,scorelist=getDbData.getDbdata.GetData4()
return render_template('relateTable.html',averagelist=averagelist,scorelist=scorelist)
if __name__ == '__main__':
app.run()
flask是及其轻量化的一个python的web的网络框架,也及其容易上手,你并不需要去理解他的内部实现,只需要会使用即可。
如下是带有注释的代码:
from flask import Flask, render_template, request, url_for # 导入jinjia2
import datetime
#导入到了当前程序中
app = Flask(__name__)#将自身框架导入程序
#路由解析 通过用户访问路径 匹配相应的函数
# @app.route('/test')
# def hello_world(): # put application's code here
# return 'hello world'
# #通过访问路径获取字符串的参数
# @app.route('/test/')#相当于访问网址 网址的name后面可以直接赋给函数
# def get(name): # put application's code here
# return 'hello world%s'%name
#
#
# @app.route('/test/')#相当于访问网址 网址的name后面可以直接赋给函数
# def get(name): # put application's code here
# return 'hello world%d'%id
#返回用户渲染的页面文件
# @app.route('/')
# def index():
# return render_template("index.html")#内部jinjia2进行检查
#向页面传变量
#返回用户渲染的页面文件
# @app.route('/')
# def index():
# time=datetime.datetime.today()
# name=["dk","dosk","idokajn"]
# data={"姓名":"小王","年龄":18}
# return render_template("index.html",var=time,list=name,data=data)#内部jinjia2进行解析 内部会在前端页面把后端变量传进去
@app.route('/test')
def register():
return render_template('register/regist.html')
@app.route('/result',methods=['POST'])
def infor():
if request.method=='POST':#获取post得到的表单
result=request.form
return render_template('register/index2.html',result=result)#得到的表单是一个键值对
if __name__ == '__main__':
app.run()#执行程序驱动网络框架 不断监听5000端口
总体总结几个点:
-
app = Flask(name)是将将框架导入该程序,网页上呈现的网址都是由@app.route(‘路径’) 通过路由解析得到的。等于说一个路径一个网页
-
网页上呈现的内容是根据路由解析路径后紧跟的函数的返回值决定的。例如:返回一个字符串 hello world。
@app.route('/test') def register(): return render_template('hello world') if __name__ == '__main__': app.run()#执行程序驱动网络框架 不断监听5000端口网页返回如下图:
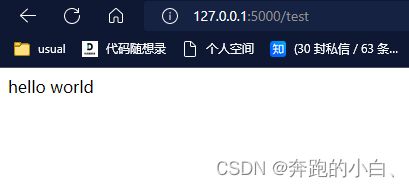
- 若要是呈现html文件则需要导入render_template包,其内部有一个jinjia2d的包,会自动识别html文件,函数 return render_template(‘xx.html’)即可在网页端展示html文件
2、前后端的交互
前端用的是那三件套,flask框架前后端交互的方式是通过函数的参数的传递
@app.route('/score')
def score():
scorelist,counts=getDbData.getDbdata.GetDate2()
return render_template('scoreTabale.html',scorelist=scorelist,counts=counts)
例如上面函数,函数内部得到了 scorelist和counts两个列表,通过render_template(),参数的传递可将让他们传入前端的html文件。这个地方特别注意,你所传入的参数名是任意的,也就是前端只会使用你所传入的参数名。
问题来了,到了前端,该使用后端传入的数据
xAxis: {
type: 'category',
{#jinjia2特定的解析后端数据的各式#}
data: {{ scorelist|tojson }}#此处是我们传进来的scorelist
},
yAxis: {
type: 'value'
},
series: [
{
name:'电影部数',
data: {{ counts }},#此处是我们传进来的counts
type: 'bar',
showBackground: true,
backgroundStyle: {
color: 'rgba(180, 180, 180, 0.2)'
}
如上图由于上述前端代码所用只需要一个列表,所以直接通过{{‘后端变量’}}的形式进行解析,内部还是通过jinjia2这个包进行解析的。
若向遍历列表,字典等,通过如下方式遍历:
{% for data in list %}
<li> {{ data }} li>
{% endfor %}#
记住一定要有for的结束语句。
3、从数据库数据的获取
后端的数据我都是通过从数据库中获取,然后将后端数据导入到前端进行呈现。
数据获取,我是通过python的一个数据库orm框架sqlalchemy。这个框架的好处在于不需要使用sql语句,具体怎么使用建议到:ORM Quick Start — SQLAlchemy 1.4 Documentation和(2条消息) sqlalchemy查询语句总结_王轩12的博客-CSDN博客_sqlalchemy sql语句学习,上手挺快的。
以下是我根据我的需求写的获取数据的接口:
# ORM 使用的类应该满足如下四个要求:
# • 继承自 declarative_base 对象。
# • 包含__tablename__ , 这是数据库中使用的表名。
# • 包含一个或多个属性,它们都是 Column 对象。
# • 确保一个或多个属性组成主键。
from sqlalchemy import Column,create_engine,Integer,String,Numeric,Boolean,func
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import Session
from sqlalchemy import select
#创建基类
Base=declarative_base()
class Movie(Base):
#表的名字
__tablename__='Movie'
#电影网址
movienet=Column(String(255))
#图片网址
impnet=Column(String(255),index=True)
#电影名称
moviename=Column(String(255),primary_key=True)#设置一个主键
#电影评分
moviescore=Column(Integer)
#点评人数
moviepeople=Column(Integer)
#电影概况
movieoview=Column(String(255))
#电影导演和演员
moviedirector=Column(String(255))
#得到所有的电影
def GetDate1():
list=[]
#创建一个引擎
engine=create_engine('sqlite:///moviemessage.db', encoding="utf-8")
#创建一个会话
session=Session(engine)
#创建查询语句
stmt=select(Movie)
#执行语句并且得到对象
for movie in session.scalars(stmt):
list.append(movie)
# print(movie)
return list
#得到不同评分的电影部数
def GetDate2():
scorelist=[]
counts=[]
#创建一个引擎
engine=create_engine('sqlite:///moviemessage.db', encoding="utf-8")
#创建一个会话
session=Session(engine)
#执行语句并且得到对象
res=session.query(Movie.moviescore,func.count(Movie.moviescore)).group_by(Movie.moviescore).all()
# print(res)
for x in res:
scorelist.append(x[0])
counts.append(x[1])
return scorelist,counts
#得到点评人数在不同段的电影部数
def GetData3():
coutslist=[]
#创建一个引擎
engine=create_engine('sqlite:///moviemessage.db', encoding="utf-8")
#创建一个会话
session=Session(engine)
#执行语句并且得到对象
res1 = session.query(Movie).filter(Movie.moviepeople>= 0,Movie.moviepeople<500000).count()
res2 = session.query(Movie).filter(Movie.moviepeople >= 500000, Movie.moviepeople < 1000000).count()
res3 = session.query(Movie).filter(Movie.moviepeople >= 1000000, Movie.moviepeople < 1500000).count()
res4 = session.query(Movie).filter(Movie.moviepeople >= 1500000, Movie.moviepeople < 2000000).count()
res5 = session.query(Movie).filter(Movie.moviepeople >= 2000000, Movie.moviepeople < 2500000).count()
res6 = session.query(Movie).filter(Movie.moviepeople >= 2500000, Movie.moviepeople < 3000000).count()
coutslist.append(res1)
coutslist.append(res2)
coutslist.append(res3)
coutslist.append(res4)
coutslist.append(res5)
coutslist.append(res6)
return coutslist
#得到电影评分和单个评分的平均点评人数
def GetData4():
#创建一个引擎
engine=create_engine('sqlite:///moviemessage.db', encoding="utf-8")
#创建一个会话
session=Session(engine)
averagelist=[]
scorelist,counts=GetDate2()
for i in range(0,len(scorelist)):
stmt=select(Movie).where(Movie.moviescore==scorelist[i])
temp=0
res=session.scalars(stmt)
sum=0
for x in res:
temp=temp+x.moviepeople
sum=sum+1
averagelist.append(int(temp/sum))
# print(averagelist)
return averagelist,scorelist
四、数据分析
这个的话极力推荐一个网站Echats:添加链接描述我也是看课才知道的,里面有很多数据分析的图模板,用来渲染前端,使得数据分析可视化,只需要在你的项目中导入一个echats.js文件,然后就可以去网站找到你所需要的数据分析图,进行修改,在前端进行呈现。网站上都有教程,这里也不多说。前端我也不是很会设计。
五、注意事项
- 创建flask项目的时候,有时候pycharm版本或者pip版本问题不能自动帮你导入flask框架包,这个时候需要你自己手动更新pip,然后进行包的下载。
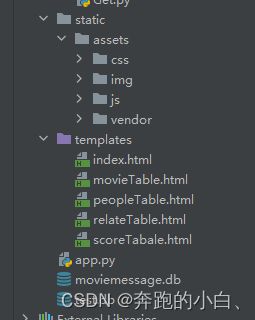
- flask项目中文件的存放路径有讲究,html文件要放在templates中,js,css,图片素材放在static文件中
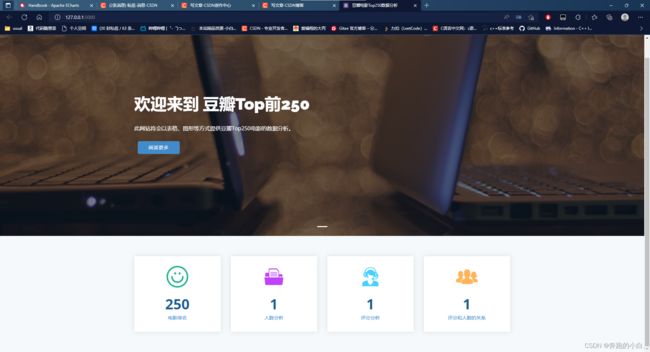
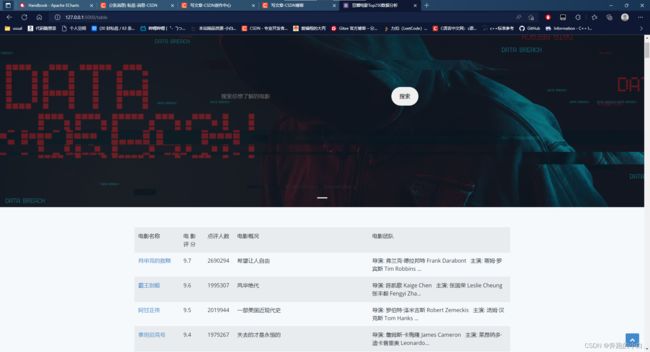
以上大概就这些,我做的demo是一个豆瓣250的爬虫数据分析,比较常见和经典。
五、效果展示: