带你读论文系列之计算机视觉--ResNet和ResNeXt
带你读论文系列之计算机视觉–ResNet和ResNeXt

ResNet 强!
ResNet发布于2015年,目前仍有大量CV任务用其作为backbone(尤其是顶会实验比较),而且当前很多网络都在使用残差模块。
Deep Residual Learning for Image Recognition
https://arxiv.org/abs/1512.03385
代码:
pytorch:https://github.com/fastai/fastai
tensorflow:https://github.com/tensorflow/models/tree/master/research/deeplab
网络中的亮点:
- 超深的网络结构(突破1000层)
- 提出Residual模块
- 使用Batch Normalization加速训练(丢弃Dropout)
引言
随着深度对于网络的重要性,出现了一个问题:学些更好的网络是否像堆叠更多的层一样容易?回答这个问题的一个障碍是梯度消失/爆炸这个众所周知的问题,它从一开始就阻碍了收敛。然而,这个问题通过标准初始化(normalized initialization),中间标准化层(intermediate normalization layers)和批量归一化(BN)在很大程度上已经解决,这使得数十层的网络能通过具有反向传播的随机梯度下降(SGD)开始收敛。(ResNet解决的不是梯度消失/爆炸问题)
当更深的网络能够开始收敛时,暴露了一个退化问题:随着网络深度的增加,准确率达到饱和,然后迅速下降。意外的是,这种退化不是由过拟合引起的,并且在适当的深度模型上添加更多的层会导致更高的训练误差。

在本文中,我们通过引入深度残差学习框架解决了退化问题。我们明确地让这些层拟合残差映射,而不是希望每几个堆叠的层直接拟合期望的底层映射。我们假设残差映射比原始的、未参考的映射更容易优化。在极端情况下,如果一个恒等映射是最优的,那么将残差置为零比通过一堆非线性层来拟合恒等映射更容易。
恒等快捷连接(Identity shortcut connections)既不增加额外的参数也不增加计算复杂度。
我们发现:1)我们极深的残差网络易于优化,但当深度增加时,对应的“简单”网络(简单堆叠层)表现出更高的训练误差;2)我们的深度残差网络可以从大大增加的深度中轻松获得准确性收益,生成的结果实质上比以前的网络更好。
残差表示。在图像识别中,VLAD是一种通过关于字典的残差向量进行编码的表示形式,Fisher矢量可以表示为VLAD的概率版本。它们都是图像检索和图像分类中强大的浅层表示。对于矢量量化,编码残差矢量被证明比编码原始矢量更有效。
在低级视觉和计算机图形学中,为了求解偏微分方程(PDE),广泛使用的Multigrid方法将系统重构为在多个尺度上的子问题,其中每个子问题负责较粗尺度和较细尺度的残差解。Multigrid的替代方法是层次化基础预处理,它依赖于表示两个尺度之间残差向量的变量。已经被证明这些求解器比不知道解的残差性质的标准求解器收敛得更快。这些方法表明,良好的重构或预处理可以简化优化。
残差学习
关于退化问题的反直觉现象激发了这种重构。如果添加的层可以被构建为恒等映射,更深模型的训练误差应该不大于它对应的更浅版本。退化问题表明求解器通过多个非线性层来近似恒等映射可能有困难。通过残差学习的重构,如果恒等映射是最优的,求解器可能简单地将多个非线性连接的权重推向零来接近恒等映射。
在实际情况下,恒等映射不太可能是最优的,但是我们的重构可能有助于对问题进行预处理。如果最优函数比零映射更接近于恒等映射,则求解器应该更容易找到关于恒等映射的抖动,而不是将该函数作为新函数来学习。我们通过实验显示学习的残差函数通常有更小的响应,表明恒等映射提供了合理的预处理。
恒等映射足以解决退化问题,因此Ws(1x1卷积)仅在匹配维度时使用。残差函数的形式是可变的。
ResNet引入残差网络结构(residual network),即在输入与输出之间(称为堆积层)引入一个前向反馈的shortcut connection,这有点类似与电路中的“短路”,也是文中提到identity mapping(恒等映射y=x)。原来的网络是学习输入到输出的映射H(x),而残差网络学习的是F(x)=H(x)−x。残差学习的结构如下图所示:
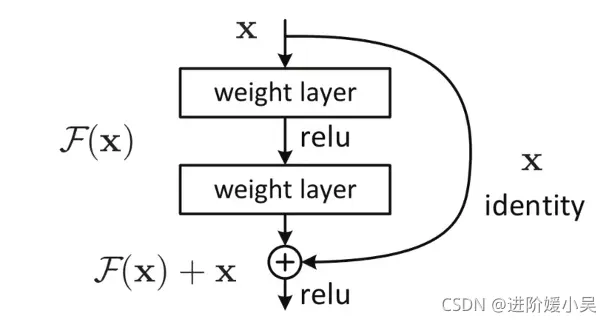
作者在文中提到:深层网络的训练误差一般比浅层网络更高;但是对一个浅层网络,添加多层恒等映射(y=x)变成一个深层网络,这样的深层网络却可以得到与浅层网络相等的训练误差。由此可以说明恒等映射的层比较好训练。
我们来假设:对于残差网络,当残差为0时,此时堆积层仅仅做了恒等映射,根据上面的结论,理论上网络性能至少不会下降。这也是作者的灵感来源,最终实验结果也证明,残差网络的效果确实非常明显。
但是为什么残差学习相对更容易?从直观上看残差学习需要学习的内容少,因为残差一般会比较小,学习难度小。另外我们可以从数学的角度来分析这个问题,首先残差单元可以表示为:
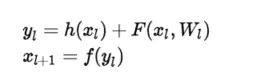
其中 x_{l} 和 x_{l+1} 分别表示的是第 l 个残差单元的输入和输出,注意每个残差单元一般包含多层结构。F 是残差函数,表示学习到的残差,而h表示恒等映射, f 是ReLU激活函数。基于上式,我们求得从浅层 l 到深层 L 的学习特征为:

利用链式规则,可以求得反向过程的梯度:

式子的第一个因子表示的损失函数到达 L 的梯度,小括号中的1表明短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。所以残差学习会更容易。
网络架构
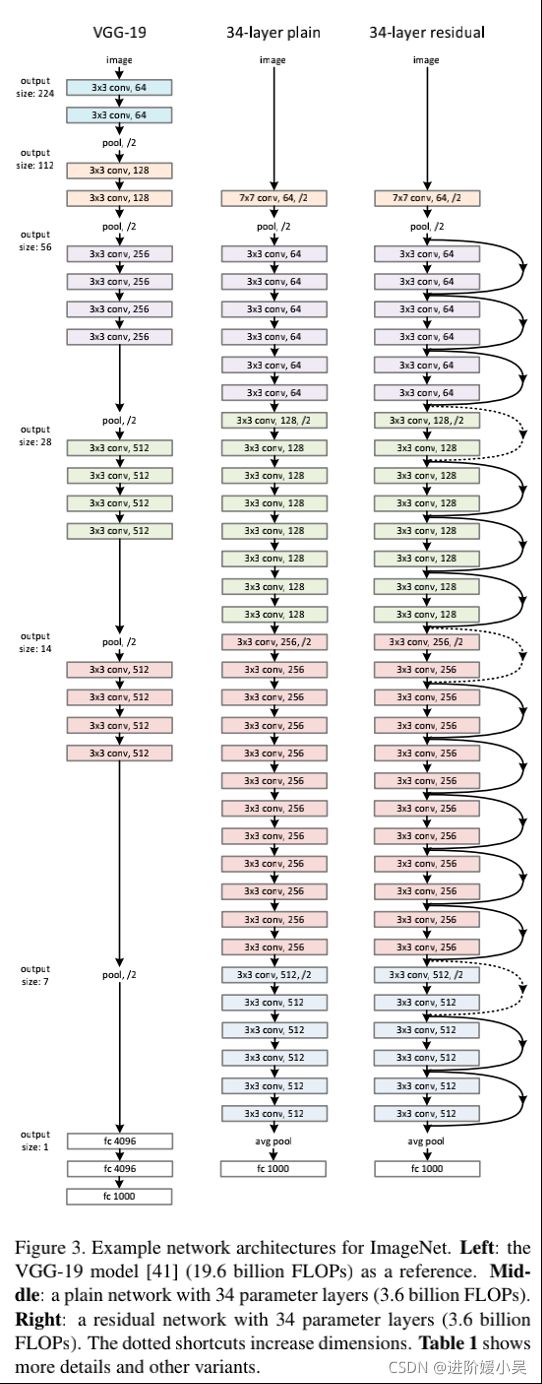
简单网络。卷积层主要有3×3的滤波器,并遵循两个简单的设计规则:(i)对于相同的输出特征图尺寸,层具有相同数量的滤波器;(ii)如果特征图尺寸减半,则滤波器数量加倍,以便保持每层的时间复杂度。我们通过步长为2的卷积层直接执行下采样。
我们的模型与VGG网络相比,有更少的滤波器和更低的复杂度。我们的34层基准有36亿FLOP(乘加),仅是VGG-19(196亿FLOP)的18%。
在每个卷积之后和激活之前,我们采用批量归一化(BN)。

ImageNet 的更深的残差函数 F。左图:ResNet-34 的积木块(在 56×56 特征图上),如下图所示。右图:ResNet-50/101/152 的“瓶颈”构建块。
图像被调整大小,其较短的边在 [256,480] 中随机采样以进行缩放。从图像或其水平翻转中随机采样 224×224 的裁剪,减去每个像素的平均值 。使用了标准颜色增强。我们在每次卷积之后和激活之前采用批量归一化(BN)。初始化权重并从头开始训练所有普通/残差网络。我们使用 SGD,mini-batch 大小为 256。学习率从 0.1 开始,当误差平稳时除以 10,模型最多训练 60×10的4 次迭代。我们使用 0.0001 的权重衰减和 0.9 的动量。我们不使用 dropout。
在测试中,为了进行比较研究,我们采用了标准的10-crop测试。为了获得最好的结果,我们采用完全卷积形式,并对多个尺度的分数进行平均(图像被调整为短边在{224,256,384,480,640})。


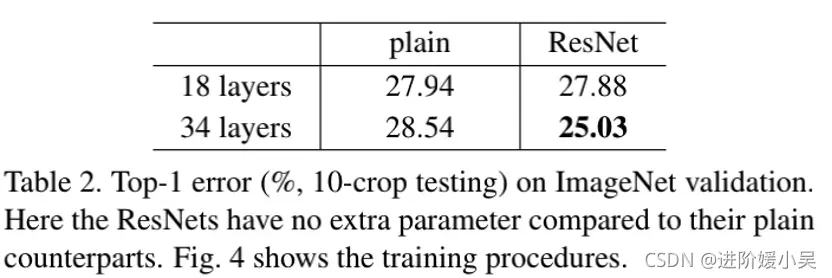
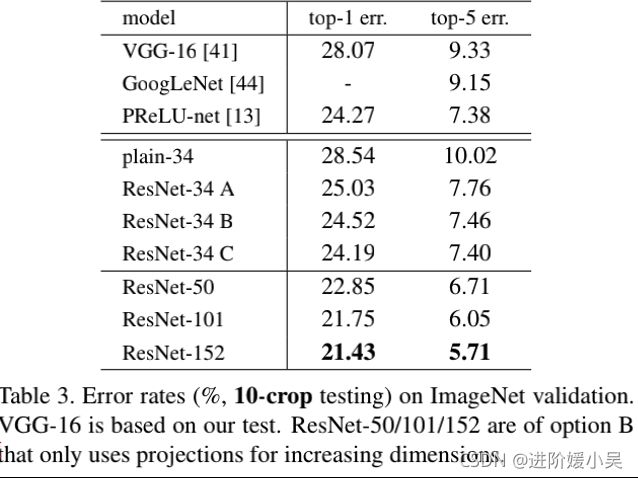

ImageNet验证集上的single-model结果的错误率(%)(测试集上的报告除外)。
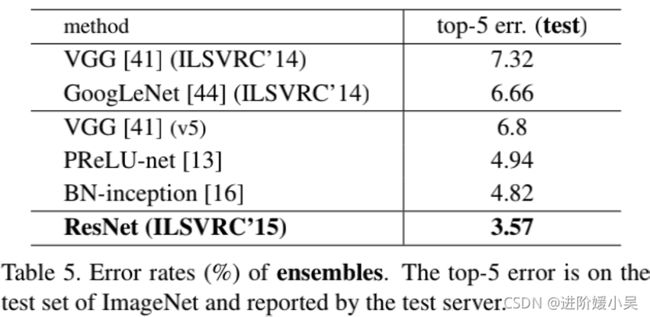
集合的错误率 (%)。top-5 错误在 ImageNet 的测试集上,由测试服务器报告。

在CIFAR-10上的训练。虚线表示训练误差,粗线表示测试误差。左边:普通网络。普通110的误差高于60%,没有显示。中:ResNets。右:有110层和1202层的ResNet。

CIFAR-10上各层响应的标准偏差(std)。响应是每个3×3层的输出,在BN之后和非线性之前。顶部:各层按其原始顺序显示。底部:响应按降序排列。
总结
1、当堆积层的输入x和输出y不同维度的时候,即f是一个从低维向高维的映射时,这个时候不能简单的添加恒等映射作为shortcut connection,需要加上一个线性投影Ws,等于一个连接矩阵,这种结构称为投影结构。
2、残差网络不仅可以运用到全连接层,还可以用到卷积层。
3、作者做了对比投影结构与恒等结构对实验结果的实验。发现投影结构对效果有细微提升,但是应该归功于投影连接增加的额外参数。
4、作者测试了1000层的残差网络,测试结果比110层更差,但是训练误差却与110层相似,造成这种现象应该是过拟合,对于小型的数据集,1000多层的网络属于杀鸡牛刀了,如果真的需要用到这么深的网络,可能需要更强的正则化。
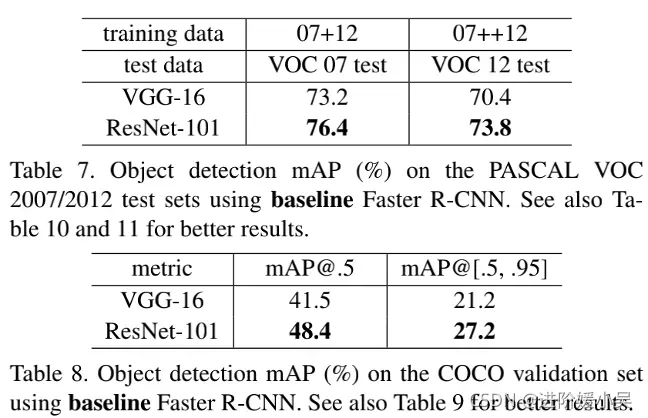
5、ResNet在目标分类上有了非常好的泛化性能,作者将它应用到目标检测领域,将Faster R-CNN的基础网络用VGG-16与ResNet-101对比,性能均有大幅提升。
带你读论文系列之计算机视觉–VGG
带你读论文系列之计算机视觉–AlexNet
ResNeXt
Aggregated Residual Transformations for Deep Neural Networks
https://arxiv.org/abs/1611.05431
代码和模型公布在
https://github.com/facebookresearch/ResNeXt
亮点
1.提出简洁、高度模块化的网络
2.主要特色是聚合变换
3.block都一致,超参数很少
4.cardinality 来衡量模型复杂度
5.ImageNet上发现,增加cardinality可提高网络性能且比增加深度和宽度更高效
6.ILSVRC第二名,5K 和COCO超越ResNet
前言
ResNet网络的升级版:ResNeXt。提出ResNeXt的主要原因在于:传统的要提高模型的准确率,都是加深或加宽网络,但是随着超参数数量的增加(比如channels数,filter size等等),网络设计的难度和计算开销也会增加。因此本文提出的 ResNeXt 结构可以在不增加参数复杂度的前提下提高准确率,同时还减少了超参数的数量(得益于子模块的拓扑结构)。
首先提到VGG,VGG主要采用堆叠网络来实现,之前的 ResNet 也借用了这样的思想。然后提到 Inception 系列网络,简单讲就是 split-transform-merge 的策略,但是 Inception 系列网络有个问题:网络的超参数设定的针对性比较强,当应用在别的数据集上时需要修改许多参数,因此可扩展性一般。
网络 ResNeXt,同时采用 VGG 堆叠的思想和 Inception 的 split-transform-merge 思想,但是可扩展性比较强,可以认为是在增加准确率的同时基本不改变或降低模型的复杂度。这里提到一个名词cardinality,原文的解释是the size of the set of transformations,如下图 Fig1 右边是 cardinality=32 的样子,这里注意每个被聚合的拓扑结构都是一样的(这也是和 Inception 的差别,减轻设计负担)。

附上原文比较核心的一句话,点明了增加 cardinality 比增加深度和宽度更有效,这句话的实验结果在后面有展示:

相关工作
1、多分支网络广泛应用;ResNets可以被认为是两个分支网络,其中一个分支是身份映射。深度神经决策森林是具有学习分裂函数的树模式多分支网络;深度网络决策树也是多分支结构multi-path有群众基础。
2、分组卷积有广泛应用;几乎没有证据表明分组卷积可提升网络性能。
3、模型压缩有广泛研究;本文不同于模型压缩,本文设计的结构自身就有很强的性能和低计算量。
4、模型集成是有效的提高精度的方法;本文模型并不是模型集成,因为各模块的训练是一起同时训练的,并不是独立的。
网络结构
列举了 ResNet-50 和 ResNeXt-50 的内部结构,另外最后两行说明二者之间的参数复杂度差别不大。
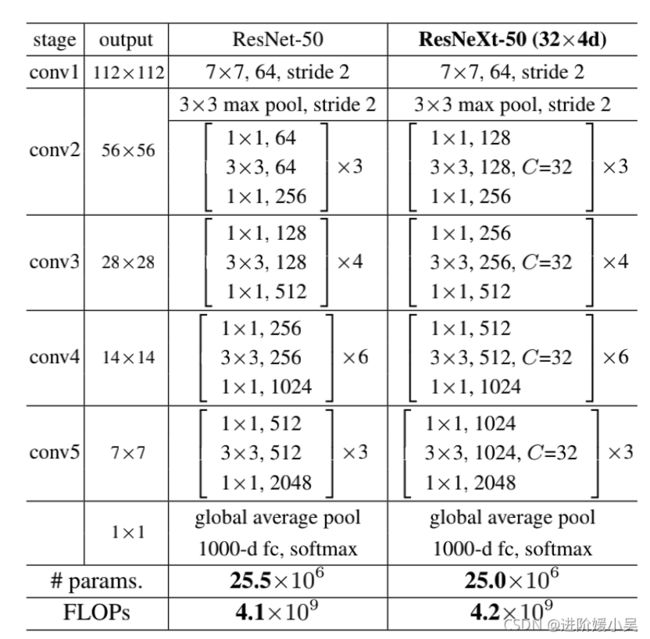
左)ResNet-50。(右)带有32×4d模板的ResNeXt-50(使用图3(c)中的重构)。括号内是残块的形状,括号外是舞台上堆叠的块数。“C=32”建议分组卷积有32个组。这两个模型之间的参数数量和FLOPs相似。
这些块具有相同的拓扑结构,并且受VGG/ResNet启发的两个简单规则的约束:(i)如果生成相同大小的空间图,则这些块共享相同的超参数(宽度和过滤器大小),以及(ii)每个当空间图按因子2下采样时,块的宽度乘以因子2。第二条规则确保计算复杂性,以FLOP(浮点运算,在#乘加),对于所有块大致相同。
3种不同不同的 ResNeXt blocks

ResNeXt的等效构建块。(a):聚合残差变换,与图1右侧相同。(b):等效于(a)的块,实现为早期串联。©:等效于(a,b),实现为分组卷积。加粗的符号突出了重新制定的变化。一层表示为(#输入通道,过滤器大小,#输出通道)。
fig3.a:aggregated residual transformations;
fig3.b:则采用两层卷积后 concatenate,再卷积,有点类似 Inception-ResNet,只不过这里的 paths 都是相同的拓扑结构;
fig 3.c:采用了一种更加精妙的实现,Group convolution分组卷积。
作者在文中明确说明这三种结构是严格等价的,并且用这三个结构做出来的结果一模一样,在本文中展示的是fig3.c的结果,因为fig3.c的结构比较简洁而且速度更快。

(左):聚合深度=2的转换。(右):一个等效的块,稍微宽一些
ResNeXt在不增加参数及计算量的情况提高了精度。
分组卷积
Group convolution 分组卷积,最早在AlexNet中出现,由于当时的硬件资源有限,训练AlexNet时卷积操作不能全部放在同一个GPU处理,因此作者把feature maps分给多个GPU分别进行处理,最后把多个GPU的结果进行融合。

有趣的是,分组卷积在当时可以说是一种工程上的妥协,因为今天能够简单训练的AlexNet。在当时很难训练, 显存不够,Hinton跟他的学生不得不把网络拆分到两张GTX590上面训练了一个礼拜,当然,两张GPU之间如何通信是相当复杂的,幸运的是今天tensorflow这些库帮我们做好了多GPU训练的通信问题。就这样Hinton和他的学生发明了分组卷积. 另他们没想到的是:分组卷积的思想影响比较深远,当前一些轻量级的SOTA(State Of The Art)网络,都用到了分组卷积的操作,以节省计算量。
疑问:如果分组卷积是分在不同GPU上的话,每个GPU的计算量就降低到 1/groups,但如果依然在同一个GPU上计算,最终整体的计算量是否不变?
实际上并不是这样的,Group convolution本身就大大减少了参数,比如当input_channel= 256, output_channel=256,kernel size=3x3:不做分组卷积的时候,分组卷积的参数为256x256x3x3。
当分组卷积的时候,比如说group=2,每个group的input_channel、output_channel=128,参数数量为2x128x128x3x3,为原来的1/2.
最后输出的feature maps通过concatenate的方式组合,而不是elementwise add. 如果放到两张GPU上运算,那么速度就提升了4倍.
实验结果
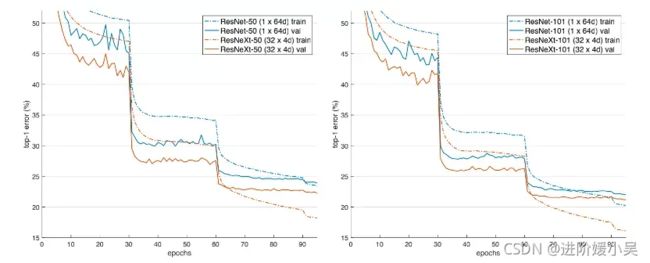
ImageNet-1K的训练曲线。(左):ResNet/ResNeXt-50,保留了复杂性(41亿FLOPs,2500万参数);(右)。保留复杂性的ResNet/ResNeXt-101(78亿FLOPs,4400万参数)。

在ImageNet-1K 上进行的消融实验。(顶部):保留复杂性的ResNet-50(41 亿FLOPs);(底部):保留复杂性的ResNet-101(78亿FLOPs)。误差率是在224×224像素的单一作物上评估的。

当FLOPs的数量增加到ResNet-101的2倍时,在ImageNet-1K上的比较。错误率是在224×224像素的单一作物上评估的。突出显示的因素是增加复杂性的因素。
总结:
- ResNeXt结合了inception与resnet的优点(其实还有分组卷积),既有残缺结构(便于训练)又对特征层进行了concat(对特征多角度理解)。这就类似于模型融合了,把具有不同优点模型融合在一起,效果的更好。
- 核心创新点就在于提出了 aggregrated transformations,用一种平行堆叠相同拓扑结构的blocks代替原来 ResNet 的三层卷积的block,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,超参数也减少了,便于模型移植。
参考文章:
https://www.jianshu.com/p/11f1a979b384
https://www.cnblogs.com/FLYMANJB/p/10126850.html
