Kafka 架构-图文讲解
Kafka是一个开源的、分布式的、可分区的、可复制的基于日志提交的发布订阅消息系统。它具备以下特点:
1. 消息持久化: 为了从大数据中获取有价值的信息,任何信息的丢失都是负担不起的。Kafka使用了O(1)的磁盘结构设计,这样做即便是在要存储大体积的数据时也是可以提供稳定的性能。使用Kafka时,message会被存储并且会被复制以防止数据丢失。
2. 高吞吐量: 设计是工作在普通的硬件设施上多个客户端能够每秒处理几百兆的数据量。
3. 分布式: Kafka Broker的中心化集群支持消息分区,而consumer采用分布式进行消费。
4. 多种Client支持: Kafka很容易与其它平台进行支持,例如:Java、.NET、PHP、Ruby、Python。
5. 实时: 消息由producer产生后立即对consumer可见。这个特性对于基于事件的系统是很关键的。
下面就来对Kafka架构做一个简单的说明:
Kafka各组件说明
Topic 与 Broker
partition log
partition distribution
Broker
Topic
Producer
Consumer
Kafka 提供的保障
架构图
Kafka各组件说明
Broker
每个kafka server称为一个Broker,多个borker组成kafka cluster。
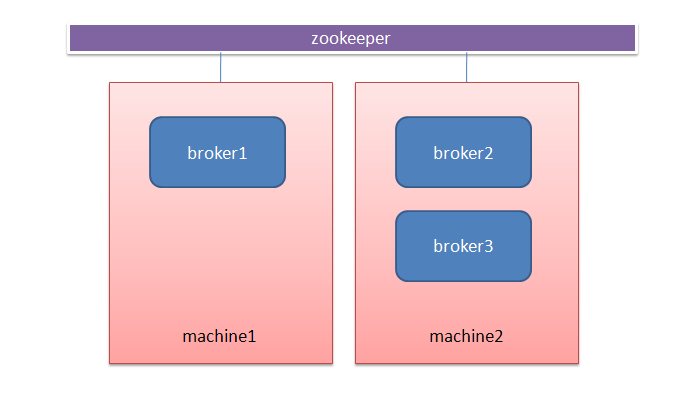
一个机器上可以部署一个或者多个Broker,这多个Broker连接到相同的ZooKeeper就组成了Kafka集群。
Topic
Kafka是一个发布订阅消息系统,它的逻辑结构如下:
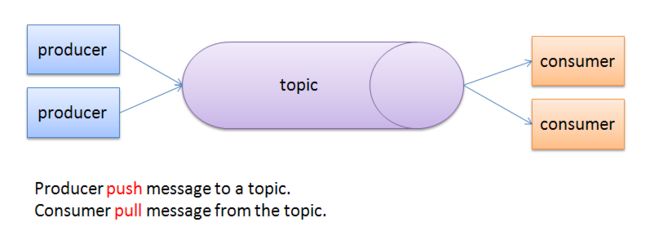
Topic 就是消息类别名,一个topic中通常放置一类消息。每个topic都有一个或者多个订阅者,也就是消息的消费者consumer。
Producer将消息推送到topic,由订阅该topic的consumer从topic中拉取消息。
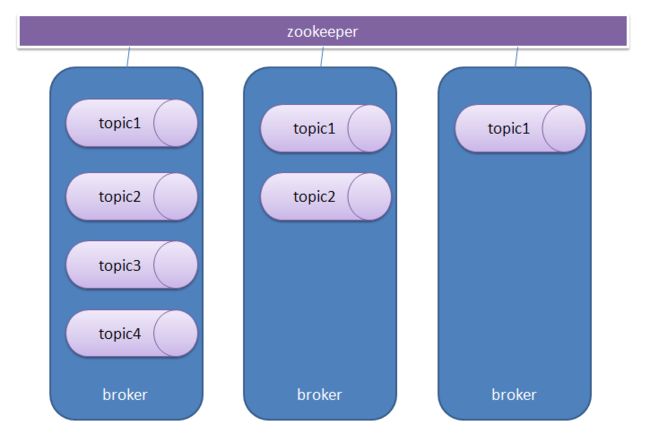
Topic 与broker
一个Broker上可以创建一个或者多个Topic。同一个topic可以在同一集群下的多个Broker中分布。
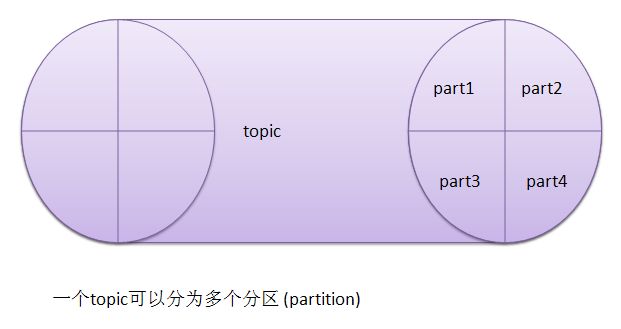
Partition log
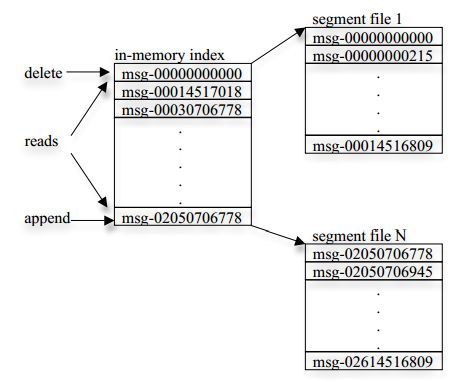
Kafka会为每个topic维护了多个分区(partition),每个分区会映射到一个逻辑的日志(log)文件:
每当一个message被发布到一个topic上的一个partition,broker应会将该message追加到这个逻辑log文件的最后一个segment上。这些segments 会被flush到磁盘上。Flush时可以按照时间来进行,也可以按照message 数来执行。
每个partition都是一个有序的、不可变的结构化的提交日志记录的序列。在每个partition中每一条日志记录都会被分配一个序号——通常称为offset,offset在partition内是唯一的。论点逻辑文件会被化分为多个文件segment(每个segment的大小一样的)。
Broker集群将会保留所有已发布的message records,不管这些消息是否已被消费。保留时间依赖于一个可配的保留周期。例如:如果设置了保留策略是2day,那么每一条消息发布两天内是被保留的,在这个2day的保留时间内,消息是可以被消费的。过期后不再保留。
Partition distribution
日志分区是分布式的存在于一个kafka集群的多个broker上。每个partition会被复制多份存在于不同的broker上。这样做是为了容灾。具体会复制几份,会复制到哪些broker上,都是可以配置的。经过相关的复制策略后,每个topic在每个broker上会驻留一到多个partition。如图:

对于同一个partition,它所在任何一个broker,都有能扮演两种角色:leader、follower。
看上面的例子。红色的代表是一个leader。
对于topic1的4个partition:
Part 1的leader是broker1,followers是broker2\3。
Part2的leader是broker2,followers是broker1\4。
Part3的leader是broker3,followers是broker1\3。
Part4的leader是broker4,followers是broker2\3。
对于topic2的3个partition:
Part1的leader是broker1,followers是broker2。
Part2的leader是broker2,followers是broker3。
Part3的leader是broker3,followers是broker4。
对于topic2的4个partition:
Part 1的leader是broker4,followers是broker1\2\3。
Part2的leader是broker2,followers是broker1\3\4。
Part3的leader是broker3,followers是broker1\2\4。
Part4的leader是broker1,followers是broker2\3\4。
下面是一个真实的例子:

图中的partition 0 的leader是broker 2,它有3个replicas:2,1,3。
In-Sync Replica:在同步中,也就是有哪些broker正处理同步中。partition 0的ISR是2,1,3,说明了3个replica都是正常状态。如果有一个broker down,那么它就不会在ISR中出现。
之后把broker1停止后:

每个partition的Leader的用于处理到该partition的读写请求的。
每个partition的followers是用于异步的从它的leader中复制数据的。
Kafka会动态维护一个与Leader保持一致的同步副本(in-sync replicas (ISR))集合,并且会将最新的同步副本(ISR )集合持久化到zookeeper。如果leader出现问题了,就会从该partition的followers中选举一个作为新的leader。
所以呢,在一个kafka集群中,每个broker通常会扮演两个角色:在一个partition中扮演leader,在其它的partition中扮演followers。Leader是最繁忙的,要处理读写请求。这样将leader均分到不同的broker上,目的自然是要确保负载均衡。
Producer
Producer作为消息的生产者,在生产完消息后需要将消息投送到指定的目的地(某个topic的某个partition)。Producer可以根据指定选择partition的算法或者是随机方式来选择发布消息到哪个partition。
Consumer
在Kafka中,同样有consumer group的概念,它是逻辑上将一些consumer分组。因为每个kafka consumer是一个进程。所以一个consumer group中的consumers将可能是由分布在不同机器上的不同的进程组成的。Topic中的每一条消息可以被多个consumer group消费,然而每个consumer group内只能有一个consumer来消费该消息。所以,如果想要一条消息被多个consumer消费,那么这些consumer就必须是在不同的consumer group中。所以也可以理解为consumer group才是topic在逻辑上的订阅者。
每个consumer可以订阅多个topic。
每个consumer会保留它读取到某个partition的offset。而consumer 是通过zookeeper来保留offset的。
Kafka提供的保障
1、如果producer往特定的partition发送消息时,会按照先后顺序存储,也就是说如果发送顺序是message1、message2、message3。那么这三个消息在partition log中的记录的offset就是 message1_offset < message2_offset < message3_offset。
2、consumer也是有序的浏览log中的记录。
3、如果一个topic指定了replication factor为N,那么就允许有N-1个Broker出错。
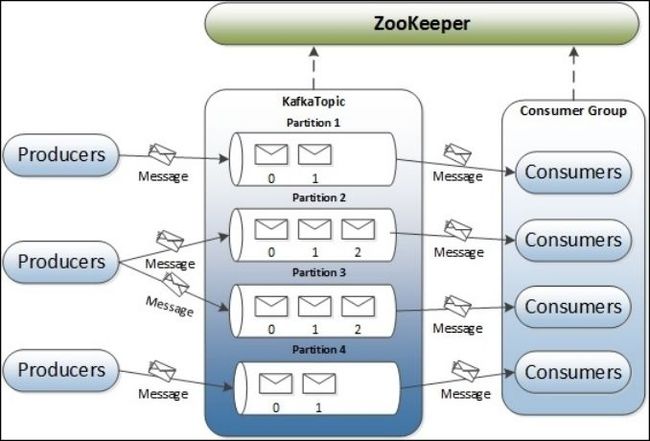
架构图
对上述各组件介绍后,现在就应该可以很容易的理解Kafka的架构图:
转自:
https://www.cnblogs.com/seaspring/p/6138080.html
陛下...看完奏折,点个赞再走吧!
推荐阅读
技术:前后端分离--整套解决方案
技术:Java面试必备技能
技术:docker私有仓库搭建,证书认证,鉴权管理
技术:如何成功抢到回家的火车票!
技术:Linux 命令行快捷键
技术:超详细黑苹果安装图文教程送EFI配置合集及系统
技术:恐怖的广告推送。其实,我们每天都在“裸奔”!
技术:如果我不说,你能看出这个主播不是真人吗?
技术:IaaS,PaaS和SaaS,QPS,RT和TPS,PV,UV和IP到底是什么意思?
技术:项目多环境切换——Maven Profile
工具:如何通过技术手段 “干掉” 视频APP里讨厌广告?
工具:通过技术手段 “干掉” 视频APP里讨厌的广告之(腾讯视频)
博主12年java开发经验,现从事智能语音工作的研发,关注微信公众号与博主进行技术交流!更过干货资源等你来拿!
